一種用于語言學習的虛擬現實設備系統及方法與流程
本發明涉及虛擬現實設備系統及方法,尤其涉及一種基于語言學習的虛擬現實設備系統及方法。
背景技術:
在全球一體化和知識經濟的背景下,除掌握自己的母語以外,越來越多的人們希望掌握一門外語。英語作為一種世界主流官方語言,對英語的掌握更是一直受到學校、家長及學生的重視。隨著英語課程改革的不斷推進,英語的學習從注重對純語言技能的學習,過渡到重點發展學生綜合語言運用能力;同時,評價方式也由只看重考試成績,向培養學生獨立自主學習意識,滿足不同學習需要為重點的方向轉變。也就是說,教育界更關注的英語學習目的是:能夠順暢的用英語進行交流與溝通。
然而,大量的調查結果顯示,即使學校、家長及學生都逐漸意識到了英語口語的重要性,實際上大多數學生對自己的英語口語水平不滿意,缺乏表達自信。這種明顯的口語輸出障礙,極大的制約了英語作為一種交際語言所能發揮的交際作用。一些學生對英語口語活動感到焦慮,缺乏必要的興趣和參與積極性,是受到多種原因影響的,例如:1)學校的大班課堂教學多以雙語教學為主,2)教學過程多注重強調語法與知識點的教與學,3)課外無法得到及時的復習和鞏固,4)學生家長口語不好的情況較多,不能很好的進行課后溝通輔導,5)青春期的學生在意他人對自己的看法,羞于或怯于表達自己,過多的依賴語言的輸入等。
目前,英語口語學習的最大瓶頸在于缺乏逼真的語言學習環境和相應的社交活動。人們流利的說話能力不是從直接教授和句法形成的訓練中獲得的,而是在有意義的互動交流活動中自然習得的。因此,借鑒于加拿大法語浸入式教學的成功模式,中國本土化的語言浸入式教學模式引起了教育界、語言學、心理學等領域的共同關注。以“習得論”為基礎的浸入式英語教學模式,摒棄了傳統的英語教學法,通過大量創設語言環境,通過習得和實踐獲得語言能力。多年的研究結果表明,在這種給予大量且適當的情境及語言環境的教育模式下,學生的聽說機會會大大提高,也更容易自然而然的習得并應用第二語言。
愛因斯坦曾說過:“興趣是最好的老師”。沉浸式教學的逼真性讓學生仿佛身臨其境,誘發學生的好奇心和學習動力;交互性讓學生更多的產生交際興趣,讓學生有話說、想說話,積極主動的掌握語言能力。學生在模擬的真實情境中視覺聽覺全方位投入,能夠產生極大的滿足感與成就感。
另外,語言交際(包含聽與說)的困難很多時候是由于自己不正確的語音造成的。發音是語言學習的基礎,早在19世紀,著名的語言學家saussure就指出:發音作為傳達信息和思想的工具,是語言的基礎。著名語言學家a.g.gimson(1978)有一句名言,“不管說何種語言,我們必須具備該語言的全部語音知識,而50%~90%的語法和1%的詞匯量可以說是夠用的了“。因此,在對第二語言的習得及應用中,良好的語音知識對于幫助學生記憶和積累語言能力,建立良性的語言習得機制,培養聽、說能力的及語言交際能力的有著至關重要的作用。
然而目前多數的英語學習設備例如點讀筆,學習機,網上視頻聊天等都由于都無法營造一個全沉浸式的語言學習環境,從而使得學習效果大打折扣。
技術實現要素:
針對上述方案的缺點,本發明利用虛擬現實技術搭建一整套用于語言學習的沉浸式系統,提高語言學習的效率和效果。
本發明技術方案是:一種用于語言學習的虛擬現實設備系統,包括語音輸入模塊、顯示模塊以及音頻播放模塊,
所述語音輸入模塊用于語音的輸入;
所述顯示模塊用于學習內容的播放,用戶根據學習內容進行發音;
所述音頻外放模塊用于根據用戶輸入的語音進行音頻的輸出。
優選的,所述語音輸入模塊包括麥克風陣列、麥克風陣列驅動模塊以及麥克風音頻數據解析模塊,所述麥克風陣列用于語音音頻的輸入;所述麥克風陣列驅動模塊用于麥克風陣列以及外接設備的驅動;所述麥克風音頻數據解析模塊用于根據麥克風陣列以及外接設備的數據協議將其解析為包含實際信息的數據結構。
優選的,所述顯示模塊包括語言學習模塊以及虛擬現實渲染模塊,所述語言學習模塊用于教學內容的存儲及播放,所述虛擬現實渲染模塊用于播放畫面的渲染。
優選的,還包括音頻系統服務模塊,所述音頻系統服務模塊用于維護麥克風陣列的生命周期,將解析后的數據結構傳輸給語言學習模塊,同時也接收來自語言學習模塊的下發指令并發送給麥克風陣列。
優選的,還包括光學模塊,所述光學模塊用于放大顯示器的尺寸,增加用戶視覺市場角,提高用戶的視覺體驗的沉浸感。
一種麥克風音頻數據解析的方法,所述方法包括:
根據設備類型獲取相應的數據解析模塊;
如果設備類型表明設備為自定義協議設備,則讀取擴展解析協議模塊;
如果是系統標準協議則根據協議版本號獲取數據解析模塊中對應版本的解析實例;
遍歷讀取的字節數組,尋找字段頭,將解析數值放入數據結構中;
如果已經解析到字節數組尾部,判斷當前是否解析完成,如果已經完成則等待下一組數據,如果未解析完成,則將這部分字節放入下一組數據中繼續處理。
本發明的有益效果是:利用虛擬現實技術搭建了一整套用于語言學習的沉浸式系統,仿真出一個供學習者學習的虛擬環境系統,提高語言學習的效率和效果;對系統進行了模塊化設計,可兼容更多的硬件設計邏輯,例如更改了麥克風陣列的硬件輸入,可直接修改麥克風陣列驅動模塊即可,而需要兼容新的引擎架構則只需要修改語言學習模塊即可。
附圖說明
下面結合附圖和具體實施方式對本發明作進一步詳細的說明。
圖1是本發明實施例的整體框架示意圖。
圖2是本發明實施例中麥克風陣列驅動模塊流程示意圖;
圖3是本發明實施例中麥克風音頻數據解析模塊流程示意圖;
圖4是本發明實施例中音頻系統服務模塊流程示意圖;
圖5是本發明實施例中語言學習模塊流程示意圖;
圖6是本發明實施例中虛擬現實渲染模塊流程示意圖。
具體實施方式
以下結合附圖,對本發明的技術方案作進一步的描述,但本發明并不限于這些實施例。
一種用于語言學習的虛擬現實設備系統,包括語音輸入模塊、顯示模塊以及音頻播放模塊,所述語音輸入模塊用于語音的輸入;所述顯示模塊用于學習內容的播放,用戶根據學習內容進行發音;所述音頻外放模塊用于根據用戶輸入的語音進行音頻的輸出。
具體的,所述語音輸入模塊包括麥克風陣列、麥克風陣列驅動模塊以及麥克風音頻數據解析模塊,所述麥克風陣列用于語音音頻的輸入;所述麥克風陣列驅動模塊用于麥克風陣列以及外接設備的驅動;所述麥克風音頻數據解析模塊用于根據麥克風陣列以及外接設備的數據協議將其解析為包含實際信息的數據結構。
具體的,所述顯示模塊包括語言學習模塊以及虛擬現實渲染模塊,所述語言學習模塊用于教學內容的存儲及播放,所述虛擬現實渲染模塊用于播放畫面的渲染。
進一步的,還包括音頻系統服務模塊,所述音頻系統服務模塊用于維護麥克風陣列的生命周期,將解析后的數據結構傳輸給語言學習模塊,同時也接收來自語言學習模塊的下發指令并發送給麥克風陣列。
進一步的,還包括光學模塊,所述光學模塊用于放大顯示模塊的尺寸,增加用戶視覺市場角,提高用戶的視覺體驗的沉浸感。
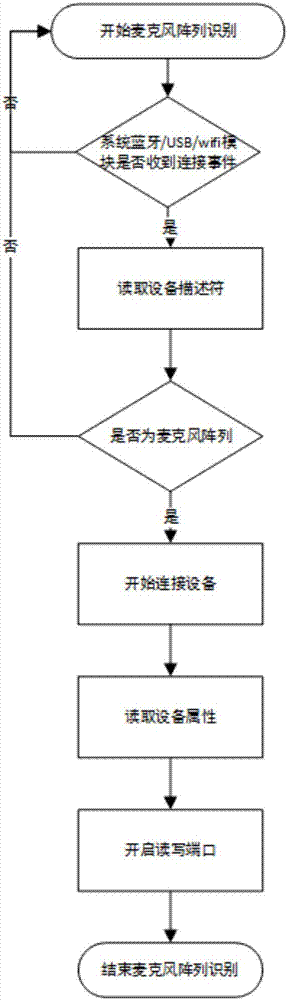
結合附圖2,麥克風陣列驅動模塊負責在系統中利用多種連接方式識別,連接和讀寫麥克風陣列音頻設備。連接方式包含:藍牙,usb和無線網絡,因此在不同連接驅動之上構建麥克風陣列驅動模塊,負責識別設備類型和協議版本,連接/斷開設備,讀寫數據等基本設備操作。
步驟1:系統的藍牙/usb/wifi收到設備連接事件;
步驟2:通過讀取設備描述符決定是否為麥克風陣列音頻設備;
步驟3:確定是麥克風設備后,執行連接操作;
步驟4:讀取設備屬性信息,包括廠商,設備子類型和協議版本信息;
步驟5:開啟讀寫端口,建立輪詢數據線程;
步驟6:將數據上報給麥克風音頻數據解析模塊。
結合附圖3,麥克風音頻數據解析模塊負責根據設備類型解析設備上報的數據為麥克風陣列數據結構。其中數據解析模塊分為標準協議模塊和自定義協議模塊,標準協議模塊為系統定義的標準麥克風音頻數據協議,只要麥克風音頻設備按標準數據協議上報數據就能被正確解析,而自定義協議為麥克分音頻設備自身設定,為了兼容這類設備,在解析擴展中可支持這類麥克風設備數據解析流程:
步驟1:根據設備類型獲取相應的數據解析模塊;
步驟2:如果設備類型表明設備為自定義協議設備,則讀取擴展解析協議模塊;
步驟3:如果是系統標準協議則根據協議版本號獲取數據解析模塊中對應版本的解析實例;
步驟4:遍歷讀取的字節數組,尋找字段頭,將解析數值放入數據結構中;
步驟5:如果已經解析到字節數組尾部,判斷當前是否解析完成,如果已經完成則等待下一組數據,如果未解析完成,則將這部分字節放入下一組數據中繼續處理。
結合附圖4,音頻系統服務模塊位于應用和底層驅動之間,在系統中運行高優先級系統服務來建立驅動到應用的數據通道,其中系統服務的主要功能有,維護麥克風陣列設備的生命周期,將解析后的數據結構通過sdkapi接口傳輸給語言學習模塊,同時也接收來自語言學習模塊的下發指令并發送到驅動層發送給麥克風陣列設備。
音頻系統服務層數據傳輸流程:
步驟1:通過驅動層獲取當前連接的麥克風陣列設備列表;
步驟2:根據sdkapi啟動來自麥克風陣列設備列表的某個設備,創建數據消息隊列;
步驟3:讀取來自數據解析模塊解析后的麥克風數據結構體;
步驟4:如果該結構體時間戳小于最后一組數據的時間戳,認為是亂序數據而直接拋棄;
步驟5:如數據時間戳正常,將解析數據結構體拷貝一份到服務層共享內存中,供語言學習模塊直接讀取;
步驟6:通知語言學習模塊有新數據上報,回調其接口;
步驟7:等待下一組解析數據結構體。
結合附圖5,語言學習模塊以插件的形式內嵌在應用中,為了支持不同類型的應用,語言學習模塊在核心邏輯基礎上封裝了androidapi,unity插件,unreal插件,讓應用和游戲都能夠獲取麥克風音頻數據并且能夠給設備寫回指令數據。
獲取麥克風音頻數據流程:
步驟1:向音頻系統服務模塊注冊服務;
步驟2:如果注冊成功,獲取當前連接設備列表;
步驟3:選擇要讀取數據的設備,設置監聽器;
步驟4:監聽器等待數據信號,如果存在新數據,監聽器回調監聽方法,監聽方法參數中帶有麥克風陣列數據結構體;
步驟5:開發者利用結構體中的數據改變應用的訓練狀態;
步驟6:回到步驟4,繼續等待數據。
虛擬現實渲染服務模塊
結合附圖6,麥克風陣列數據需要作用于虛擬現實場景中才能獲得訓練效果,為了支持開發者開發沉浸式語言學習課程內容,系統中提供了渲染服務層提供虛擬現實渲染api和相應的開發工具幫助開發者開發內容。
虛擬現實渲染流程如下:
步驟1:通過sdkapi接口獲得應用的場景模型的數據和資源,這些模型數據通常為模型頂點數據,紋理資源等;
步驟2:準備開始畫面新一幀的渲染;
步驟3:將模型/場景/ui數據通過語言學習模塊同步給系統渲染層;
步驟4:在每一個渲染幀的回調中更新一次麥克風陣列數據,讓數據作用于應用中的場景或模型中,并且將更新后的結果提交給系統渲染層;
步驟5:讀取系統九軸傳感器數據,九軸傳感器安裝于人體,用于檢測人體姿態數據;
步驟6:傳感器融合算法對采集的傳感器數據進行融合,得到當前的姿態矩陣;
步驟7:將姿態矩陣作用到系統渲染服務層中的相機上,更新視角方向;
步驟8:執行圖形渲染矩陣計算,并將結果提交給gpu渲染。
本文中所描述的具體實施例僅僅是對本發明精神作舉例說明。本發明所屬技術領域的技術人員可以對所描述的具體實施例做各種各樣的修改或補充或采用類似的方式替代,但并不會偏離本發明的精神或者超越所附權利要求書所定義的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!