用于確定至少一個行為參數的方法與流程
本發明總體上涉及一種用于確定佩戴者的至少一個行為參數以便設計這個佩戴者的眼鏡架的眼科鏡片的方法。
背景技術:
適合于佩戴者以及所選眼鏡架的眼科鏡片的設計和制造目前需要眼鏡師進行一項或多項測量。
眼鏡師進行的這些測量通常由于佩戴者的反常行為而存在偏差。確切地,眼鏡師的店鋪環境通常與佩戴者的日常生活環境并且因此與日常使用條件迥然不同。另外,眼鏡師所執行的這些測量必須非常快速地執行。
因此,眼鏡師所執行的測量是不精確的,因為這些測量是在反常條件下進行的。
用于在眼鏡師店鋪外進行測量并且允許通過互聯網來購買多副眼鏡的系統也是已知的。
這些系統因此允許在更接近佩戴者的日常生活的條件下進行測量。
然而,這些已知的系統僅可以測量幾何-形態學參數,如瞳距值。這些已知系統不能夠確定佩戴者的行為參數,即與佩戴者的視覺行為有關的參數,例如像閱讀距離或眼睛-頭部系數。
這些行為參數的確定更復雜并且相關聯的測量目前僅是眼鏡師能做到的。
技術實現要素:
為了彌補現有技術的上述缺點,本發明提供了一種用于確定佩戴者的至少一個行為參數的新方法,借助于該方法能夠在對該佩戴者而言自然的條件下精確地確定這個參數。
更具體地,根據本發明,提供了一種用于確定佩戴者的至少一個行為參數以便設計用于這位佩戴者的眼鏡架的眼科鏡片的方法,該方法包括以下步驟:
a)采集與該佩戴者的頭部的第一三維表示相對應的第一數據集,
b)根據這個數據集來確定該佩戴者的頭部的至少三個具體點的相對空間位置,
c)采集與該佩戴者的頭部在自然姿勢下的第二表示相對應的第二數據集,該第二表示包括該佩戴者的頭部的這三個具體點中的每一個具體點的至少一張圖像,
d)在步驟b)的所述第二表示中標識該佩戴者的頭部的所述具體點中的每一個具體點的圖像,在步驟b)中已經確定這些具體點的相對空間位置,
e)根據這個標識來推導出與在所述第二表示的確定過程中該佩戴者的頭部的位置和/或取向有關的信息,
f)根據步驟e)中所推導出的信息(并且能夠根據所述第二表示)來確定該佩戴者的所述行為參數。
因此,能夠在行為參數的確定過程中考慮佩戴者的頭部在這個自然姿勢下的位置和/或取向。
示例性行為參數是佩戴者的頭部體態(例如由降低角和/或傾側角所限定的)。在以下描述中給出了多個其他實例。
每個數據集可以包括存儲在不同文件中的數據。一個數據集可以例如包含與存儲在另一文件中的圖像和元數據相對應的一個文件的數據。
以下是根據本發明的方法的其他非限制性且有利的特征:
-在步驟a)中,借助于用于捕捉三維圖像的第一裝置來采集該佩戴者的頭部的至少一張三維圖像,這張三維圖像接著構成該佩戴者的頭部的所述第一表示;
-在步驟a)中采集了該佩戴者的頭部的一系列第一三維圖像,并且在步驟b)中借助于統計分析、根據該佩戴者的頭部的、其相對位置在該系列第一三維圖像中最穩定的這些點來確定所述具體點;
-在步驟a)中,使用用于捕捉二維圖像的第一裝置來采集該佩戴者的頭部在不同的頭部姿勢下的一系列第一二維圖像,這個系列第一圖像構成了該佩戴者的頭部的所述第一表示,并且針對每個所捕捉到的第一圖像,確定該佩戴者的頭部相對于該第一圖像捕捉裝置的相應位置和/或取向;
-在步驟c)中,使用與該第一圖像捕捉裝置不同的第二圖像捕捉裝置來捕捉該佩戴者的頭部的至少一張第二二維圖像,該佩戴者的頭部的所述至少一張第二二維圖像構成了該佩戴者的頭部的所述第二表示,并且,在步驟e)中,所述系列第一圖像中的、最接近所述第二圖像的第一圖像是與在步驟c)中所捕捉到的該第二圖像相關聯的,并且使用在這個最接近的第一圖像的捕捉過程中該佩戴者的頭部的位置和/或取向來標識在所述第二圖像的捕捉過程中該佩戴者的頭部相對于所述第二圖像捕捉裝置的位置和/或取向;
-在步驟a)和/或在步驟c)中,存儲包括該佩戴者的頭部的所述第一和第二表示的所述數據集,這些表示是預先確定的;
-在步驟c)中,在該佩戴者在其環境中的一個或多個習慣活動過程中確定該佩戴者的頭部的該第二表示;
-該佩戴者的習慣活動是以下活動中的一項:
-閱讀不同介質,
-在書桌上工作,
-開車,
-練習運動,
-烹飪,
-控制游戲操作臺,
-坐下休息,
-看電視,
-演奏樂器;
-在步驟c)中,使用第二圖像捕捉裝置來捕捉該佩戴者的頭部的至少一張第二二維圖像,該佩戴者的頭部的所述至少一張第二二維圖像構成了該佩戴者的頭部的所述第二表示;
-在步驟c)中,借助于用于捕捉三維圖像的第二裝置來采集該佩戴者的頭部的至少一張第二三維圖像,所述第二三維圖像構成了該佩戴者的頭部的所述第二表示;
-在步驟c)中,采集該佩戴者的頭部的一系列第二二維或三維圖像,并且在步驟f)中,根據這一系列中的所述第二圖像的統計處理來確定該佩戴者的所述行為參數;
-在步驟c)中,在該佩戴者正將其目光注視在視覺目標上時采集該佩戴者的頭部的這一系列第二圖像,在每張第二圖像的捕捉過程中確定這個視覺目標相對于該第二圖像捕捉裝置的位置;
-執行校準所述用于捕捉二維或三維圖像的第二裝置的步驟,在該步驟中,用這個第二圖像捕捉裝置來捕捉專用標準物體的圖像;
-在所述第二二維或三維圖像的捕捉過程中確定所述第二圖像捕捉裝置的空間位置和/或取向,并且從其中確定與在這張第二圖像的捕捉過程中該佩戴者的頭部的空間位置和/或取向有關的信息;
-在步驟d)之前的步驟中,將在步驟b)中所捕捉的每張第二二維或三維圖像傳輸至至少一個信息處理服務器并且與該佩戴者的標識符相對應地存儲;
-傳輸至該服務器的每張捕捉到的第二圖像是與在步驟a)中已經確定的該佩戴者的頭部的那些具體點相關聯的,所述圖像與該佩戴者的所述標識符相對應地被存儲在該服務器上;
-在步驟e)中,在所述第二表示的確定過程中該佩戴者的頭部的位置和/或取向以計算方式被確定為該佩戴者的頭部的、使得該佩戴者的頭部的這三個具體點具有這三個具體點的圖像在所述第二表示中被標識出的坐標的位置和/或取向;
-步驟f)中所確定的行為參數是以下各項中的一項:
-閱讀距離,
-眼睛與頭部的角移動的比率,
-所討論的習慣活動所采取的靜態或動態姿勢,
-與每個注視方向、眼睛與著眼點之間的距離相關聯的工作視景,
-上述行為參數的變化,
-佩戴者的眼鏡架在其面部上的位置;
-在步驟a)中,由專門驗光的人而非該佩戴者、和/或使用專用于驗光的裝置來采集該佩戴者的頭部的第一表示,而在步驟c)中,由該佩戴者自己負責采集該佩戴者的頭部的第二表示而無需專門驗光的人介入和/或使用常見裝置;并且,
-在步驟b)中,該佩戴者的頭部的這三個具體點是與該佩戴者的頭部上所佩戴的配件相關聯的,并且它們在與這個配件相關聯的參考系中的相對位置是已知的。
附圖說明
以下通過非限制性示例給出的關于附圖的描述將清楚地闡釋本發明的本質以及其可被實施的方式。
在附圖中:
-圖1是示意性地示出了根據本發明的方法的框圖,
-圖2示意性地示出了該方法的步驟a)的一個可能實現方式。
具體實施方式
本發明涉及一種用于確定佩戴者的至少一個行為參數以便設計這個佩戴者的眼鏡架的眼科鏡片的方法。
這個行為參數尤其可以是以下各項中的一項:
-閱讀距離,即,佩戴者的眼睛與帶有閱讀文本的介質或佩戴者的目光所注視的視覺目標所間隔的距離,
-眼睛與頭的角移動的比率,即,佩戴者的眼睛沿所確定方向的移動幅度與這只眼睛在閱讀任務過程中的最大移動幅度的比率,又稱為眼睛-頭部系數,
-針對所討論的習慣活動所采取頭部和/或身體姿勢,即,頭部和/或身體在與佩戴者目光所注視的視覺目標相關聯的參考系中的位置和/或取向,
-與每個注視方向、眼睛與著眼點之間的距離相關聯的工作視景,
-上述參數之一的變化,
-佩戴者的眼鏡架在其面部上的位置。
根據本發明,該方法包括以下步驟:
a)采集與該佩戴者的頭部的第一三維表示相對應的第一數據集(圖1中的框100),
b)根據這個數據集來確定該佩戴者的頭部的至少三個具體點的相對空間位置(圖1中的框200),
c)采集與該佩戴者的頭部在自然姿勢下的第二表示相對應的第二數據集,該第二表示包括該佩戴者的頭部的這三個具體點中的每一個具體點的至少一張圖像(圖1中的框300),
d)在步驟b)的所述第二表示中標識該佩戴者的頭部的所述具體點中的每一個具體點的圖像,在步驟b)中已經確定這些具體點的相對空間位置(圖1中的框400),
e)根據這個標識來推導出與在所述第二表示的確定過程中該佩戴者的頭部的位置和/或取向有關的信息(圖1中的框500),
f)根據所述第二表示以及步驟e)中所推導出的信息來確定該佩戴者的所述行為參數(圖1中的框600)。
優選地,在步驟a)中,由專門驗光的人而非該佩戴者、和/或使用專用于驗光的裝置來采集該佩戴者的頭部的第一表示,而在步驟c)中,由該佩戴者自己負責采集該佩戴者的頭部的第二表示而無需專門驗光的人介入和/或使用常見裝置。
因此能夠將對佩戴者的頭部的第一表示和第二表示的確定分離開。
該佩戴者的頭部的第一表示可以在眼鏡師處通過其所擁有的專用裝置并且在與眼鏡師的工作場所相關聯的具體條件下(特別是在佩戴者定位、專用于該測量的照明、測量裝置以及短時間方面)進行確定。相反,該佩戴者的頭部的第二表示優選地是由佩戴者自己在其環境中使用常用的測量裝置(如照相機、攝像機或攝像頭)來確定的,那么他可能花費的時間比專門進行這種確定的眼鏡師多得多。
另外,在確定每個表示包括用圖像捕捉裝置來采集一張或多張圖像的情況下,應理解的是,與該第一表示的采集相關聯的第一圖像捕捉裝置和與該第二表示的采集相關聯的第二圖像捕捉裝置是不同的。
同樣,當這兩個步驟之一包括簡單地檢索與佩戴者的頭部的第一和/或第二表示相對應的數據集時,每個數據集優選地包含與用不同的第一和第二圖像捕捉裝置預先捕捉的一張或多張二維或三維圖像相對應的數字數據。
因此,在實踐中,根據本發明的一個優選的可能的實現方式,該方法的步驟是按以下方式整體執行的。
佩戴者去拜訪眼鏡師并且選擇眼鏡架。佩戴者接著可以選擇無個性化的眼科鏡片。
優選地,當場并且接著例如使用立體攝像機或例如3-D掃描儀來執行進行三維測量的步驟a)。眼鏡師還可以檢索例如與預先進行的測量相對應的預先存在的數據集。這個數據集也可以可選地傳輸給佩戴者。
在步驟b)中,在所采集數據的傳輸之后,在眼鏡師或遠程技術中心生成該佩戴者的頭部的三維模型。
為了將旨在裝配在由佩戴者所選中的鏡架中的眼科鏡片個性化,眼鏡師要求佩戴者拍下或錄下其處于不同的日常情形下的照片或視頻。
為此,佩戴者使用暢銷的測量裝置,如照相機、電影攝影機、集成在智能手機中的攝像機、平板或TV屏、攝像頭、Kinect模塊等。
優選地,佩戴者通過對專用標準物進行成像來校準該測量裝置。
他進行一個或多個系列的日常測量。佩戴者拍下其在以下日常情形下的照片:在工作、閱讀、他在放松(看電視、玩游戲等)、或者特定活動(烹飪、運動、音樂、駕駛等)過程中。
可以將這一系列測量重復多次。
所有所采集的數據被傳輸給眼鏡師或遠程計算中心以進行處理。
佩戴者的頭部的三維模型與佩戴者在其日常例程期間所收集的數據的關聯允許對其統計地進行處理以便從中提取以下行為參數:如:
-固定距離
-工作視景
-鏡架的當前位置。
這些行為參數用來將旨在用于佩戴者的眼科鏡片進行個性化。它們允許對標準眼科鏡片進行修改,以便使之與佩戴者的需要盡可能最好地匹配。還能夠對在眼鏡師處已經確定的多個行為參數進行加權。
現在將詳細討論根據本發明的方法的各個步驟。
步驟a)
因此,在實踐中,步驟a)優選地是由專門驗光的人,例如眼鏡師、或者在裝配有專用于驗光的裝置并且連接至信息處理裝置上的自助終端上執行。
步驟a)的目的在于進行測量,從而允許生成佩戴者的至少頭部的三維模型。還可以確定佩戴者的身體的局部或完整的三維模型。例如,佩戴者的胸部的模型可以根據通過確定胸部的兩個具體點(即,肩峰,被稱為胸骨柄和劍突突起)的位置來生成。
胸骨柄指代胸骨的頂部,鎖骨連接至其上。劍突突起是位于胸骨底端處的骨質或軟骨結構。因此能夠確定頭部相對于胸部的位置。
如下文所解釋的,在步驟b)中生成了這個三維模型。
這個測量步驟可以用不同的方式執行。
根據步驟a)的第一實施例,借助于用于捕捉三維圖像的第一裝置來采集該佩戴者的頭部的至少一張三維圖像,這張三維圖像接著構成該佩戴者的頭部的所述第一表示。
用于捕捉三維圖像的第一裝置例如是三維掃描儀、或用于捕捉立體圖像的裝置,該裝置包括至少兩個設備,該至少兩個設備用于捕捉同時記錄佩戴者的頭部在兩個圖像捕捉平面中的兩張二維圖像,這兩個平面是相對于該佩戴者的頭部不同定向的。在這種情況下,每張三維圖像包括至少兩張二維圖像以及與這兩個圖像捕捉設備的相對位置有關的信息。
用于捕捉三維圖像的第一裝置可以尤其是基于結構光技術。
這個第一捕捉裝置于是包括用于在圖像捕捉裝置記錄個人的頭部的一張或多張二維圖像時將結構光(例如包括圖案,如moiré圖案)投射到個人的頭部上的裝置。
由于該圖案是已知的,所以這些圖像的處理允許確定該三維表示。
優選地,能夠設想的是,采集一系列第一三維圖像,這個系列構成佩戴者的頭部的第一表示。
該佩戴者在此優選地是光著頭部的,即他的頭部沒有光學設備,如眼鏡架或眼科鏡片。
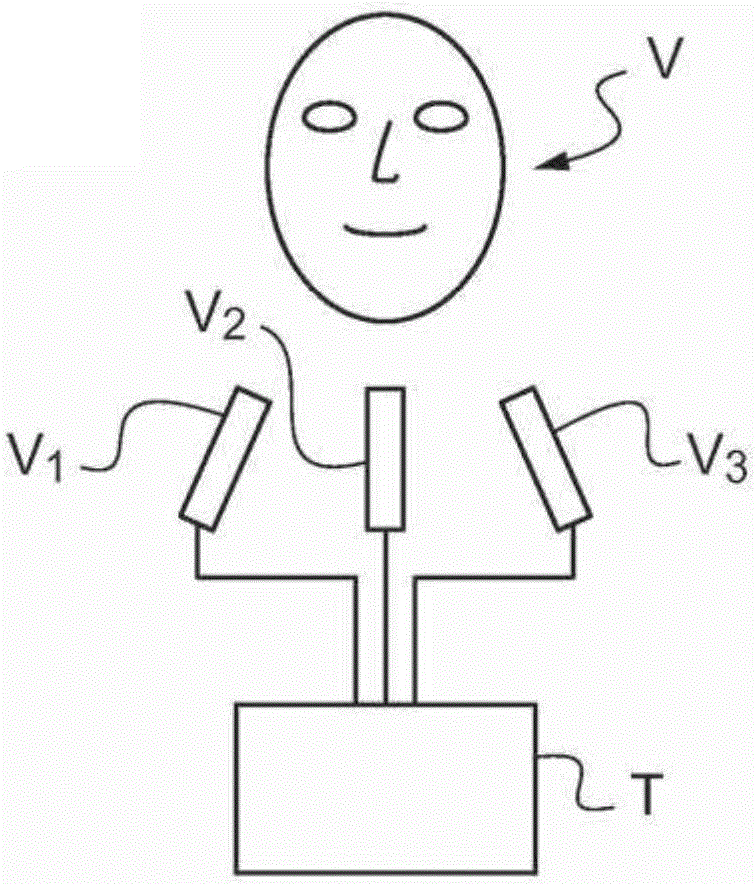
在實踐中,為了實施步驟a),可以使用圖2中所示的裝置。
圖2示出了用于對佩戴者的頭部的面部V進行測量的系統。這個系統尤其包括n個攝像機Vi(在圖1所示的實施例中n=3)以及連接至這n個攝像機Vi中的每一者上的處理裝置T。
處理裝置T例如是基于基于微處理器的架構。在這樣的系統中,該微處理器執行被存儲在與該微處理器相關聯的存儲器中的程序的指令,以便實施多種處理方法,如下文所介紹的那些方法。
例如,另外該處理裝置包括屏幕、用戶接口(例如鍵盤或鼠標)、以及電子存儲設備,例如硬盤。這些部件連接至該微處理器上并且以該微處理器執行專用指令來由該微處理器進行控制。
這些攝像機Vi是使用標準物并且相對于彼此來校準的,這意味著,在成像平面中(佩戴者將其面部定位在其中),這n個攝像機Vi采集表示該佩戴者的面部的同一個區的多張圖像。
每個攝像機Vi采集在時刻t1、…、tm相應地拍下的一連串二維圖像Ii(t1)、…、Ii(tm)。
根據步驟a)的第二實施例,在步驟a)中,使用用于捕捉二維圖像的第一裝置來采集該佩戴者的頭部在不同的頭部姿勢下的一系列第一二維圖像,這個系列第一二維圖像構成了該佩戴者的頭部的所述第一表示,并且針對每個所捕捉到的第一二維圖像,確定該佩戴者的頭部相對于該第一圖像捕捉裝置的相應位置和/或取向。
在這種情況下,所討論的問題是一系列第一非立體圖像:該第一圖像捕捉裝置在給定時刻t捕捉佩戴者的頭部的單張二維圖像。
確切地,能夠設想將具有設定幾何特征的配件放在佩戴者的頭部上。例如,所討論的問題可能是所選的鏡架或者并非所選鏡架的鏡架,后一鏡架優選地具有比所選鏡架更大的尺寸,從而使得佩戴者的注視不被該鏡架的邊緣限制。
該鏡架優選地配備有精確定位系統,該精確定位系統旨在允許佩戴者的頭部的空間位置根據配備有該定位系統的佩戴者頭部的捕捉圖像確定。這個精確定位系統在文件FR 2914173的第7頁第5行至第10頁第8行中進行了詳細描述。因此將不在此處對此進行詳細描述。
此精確定位系統具有預先確定的幾何特征,這些幾何特征允許在與圖像捕捉裝置相關聯的參考系中從該佩戴者頭部的捕捉圖像(此定位系統出現在該圖像中)確定該佩戴者頭部的空間位置和取向。因此,此精確定位系統允許在與圖像捕捉裝置相關聯的參考系中確定與佩戴者的頭部相關聯的參考系的位置和取向。
佩戴者的頭部可以直接配備有精確定位系統。
根據步驟a)的第三實施例,存儲包括該佩戴者的頭部的所述第一表示的所述數據集,該表示是預先確定的。步驟a)于是不包括圖像捕捉步驟。問題在于,檢索預先已經確定的數字文件。
這個數據集可以尤其包含與三維圖像相對應的數據(所述數據是預先被捕捉到的(例如使用三維掃描儀或用于捕捉立體圖像的裝置))、或與預先捕捉到的一系列二維圖像相對應的數據。在后一種情況下,該數據集還包含與對應于每張二維圖像的數據相關聯的、與在這張圖像的捕捉過程中佩戴者的頭部相對于第一圖像捕捉裝置的位置和/或取向有關的信息。
步驟b)
根據這個數據集來確定該佩戴者的頭部的至少三個具體點的相對空間位置。
優選地,確定了該佩戴者的頭部的至少四個具體點的相對空間位置。
這個步驟對應于同該佩戴者的頭部相關聯的三維參考系的建立。這個三維參考系是空間絕對參照系、或者是與佩戴者的環境相關聯的參考系、而不與該第一圖像捕捉裝置相關聯。
該佩戴者的頭部的所述三個具體點可以是直接位于該佩戴者的頭部上的具體點。
于是優選地問題是面部的預先限定的形態學點:例如嘴唇的合縫、鼻翼末端、佩戴者的每只眼睛的眼角(眼睛的內眼角和外眼角)、眉毛、或上顎的牙齒。
無論步驟a)的實施例怎樣,在步驟a)中建立的數據集為此目的都被存儲在信息處理服務器中,該信息處理服務器可以可選地包括以上所描述的處理裝置T。該信息處理服務器可以位于眼鏡師處或遠程地位于遠程計算中心中。在后一種情況下,該數據集被傳輸至該遠程信息處理服務器。
在實踐中,在步驟b)中,執行了識別在步驟a)中所捕捉到的每張圖像或在步驟a)中檢索到的數據集中的這些具體點中每個具體點的圖像的步驟。
具體而言,在以下情況下,在步驟a)中采集了該佩戴者的頭部的一系列第一三維圖像,接著在步驟b)中借助于統計分析、根據該佩戴者的頭部的、其相對位置在該系列第一三維圖像中最穩定的這些點來確定所述具體點。這個統計分析尤其可以包括確定佩戴者的頭部的統計模型。
例如,在步驟a)中借助于用于捕捉立體圖像的裝置來捕捉佩戴者的頭部的三維圖像的情況下,可以在步驟b)中實施以下子步驟。該信息處理服務器在此包括以上所描述的處理裝置T。在此通過處理裝置T的微處理器、基于存儲在與該微處理器相關聯的存儲器中的指令來實施以下所描述的子步驟中的每一個子步驟,由該微處理器處理的數據(如由攝像機拍攝的圖像或不同模型中的特征點的坐標)也被存儲在這個存儲器中或由另一個裝置(如硬盤)存儲。還可以設想本領域技術人員已知的任何其他實施裝置。數據例如可以通過虛擬化服務器群的管理程序來處理。
在第一子步驟中,在每張圖像Ii(tj)中,確定所討論圖像中所示的面部的多個具體點。用Qi,j(1)、…、Qi,j(p)表示在圖像Ii(tj)中確定的、與該面部的p個特征點相對應的p個點。該處理裝置接著例如將所討論的圖像中的這些特征點中每個特征點的(二維)坐標存儲在存儲器中。
這些特征點例如是使用面部識別算法、在此使用“主動外觀模型”算法(例如,關于這個主題參見T.F.庫特(T.F.Cootes)、G.J.愛德華茲(G.J.Edwards)、C.J.泰勒(C.J.Taylor)在IEEE Transactions on Pattern Analysis and Machine Intelligence 23(6):681,2011中的文章“Active appearance models(主動外觀模型)”)來確定的。
接下來執行第二子步驟,在該步驟中將每個系列圖像I1(tj)、…、In(tj)的、即由n個攝像機Vi在給定時刻tj拍攝的每組n張圖像的特征點進行關聯,以便針對每個系列圖像獲得面部的三維模型,即面部的特征點的一組位置,所述位置是由三維坐標定義的。
更精確地,針對面部的每個特征點K并且針對每個系列圖像I1(tj)、…、In(tj)(與在時刻tj拍攝的圖像相對應),使用這些圖像中的點Q1,j(k)、…、Qn,j(k)的坐標來評估在時刻tj時面部的特征點k所位于的這個點Pk(tj)的三維坐標,例如是通過使用對極幾何(并且借助于攝像機Vi的上述校準)。
在此應注意,由于佩戴者的面部是可移動且可變形的,所以在先前獲得的(在時刻tj由這個點集Pk(tj)定義的)三維模型根據所討論的時刻tj而變化。
接下來,執行第三子步驟,在該子步驟中將在前一個步驟中所獲得的每個三維模型相對于參考模型進行調整。
例如,與時刻t1相關聯的三維模型在該第三子步驟的第一次迭代中被用作參考模型。作為變體,在該第二子步驟中所獲得的另一個三維模型在該第三子步驟的第一次迭代中可以被用作參考模型。
針對每個三維模型(與在時刻tj捕捉到的圖像相關聯),在此通過將所討論的三維模型的點云在空間中的進行平移和旋轉而將所討論的三維模型的點云與該參考三維模型的點云之間的歐幾里德距離(Euclidean distance)最小化來執行該調整步驟。
因此,如果該參考模型的點用R1、…、Rp表示(對于如已經指示的第一迭次代,使用與時刻t1相關聯的模型,即Rk=Pk(t1),其中k的范圍從1到p),因此尋求變換F,使得將該參考模型的點云Rk與所討論的模型在變換后的點云之間的歐幾里德距離最小化(由平移和旋轉組成),即,該變換將以下項最小化:
其中d是這兩個點之間的(歐幾里德)距離。
經調整的模型(即,調整后)的點將用P’k(tj)表示:
P’k(tj)=F(Pk(tj))。
經調整的模型(或者等效地,變換F)的這些點例如通過迭代最近點(ICP)算法來確定-(關于該主題,例如參見F.Pomerleau、F.Colas、R.Siegwart和S.Magnenat在Autonomous Robots 34(3)中的文章“Comparing ICP Variants on Real-World Data Sets(比較現實世界數據集的ICP變異),第133-148頁,2013年4月”)。
接著基于這些經調整的模型來執行構建由點集Sk形成的統計模型的第四子步驟,每個經調整的模型是由點P’k(tj)形成的。更精確地,基于該面部的給定特征點k在不同圖像捕捉時刻t1、..、tm所位于的點P’k(t1)、…、P’k(tm)來構建該統計模型的每個點Sk。
針對面部的每個特征點k,統計模型的點Sk例如被定義為在這些不同的經調整的模型中的對應點P’k(t1)、…、P’k(tm)的質心。
作為變體,可以拒絕異常點:為了定義Sk,重新確定這些點P’k(tj)的質心,而不考慮距離第一經計算的質心(基于m個點P’k(tj)計算出的質心)太遠的點、例如被定位成距第一經計算的質心的距離超過閾值的那些點。在此提出了在所計算出第一質心處分布這各個點的距離時使用平均值加上兩個標準偏差作為閾值。
作為變體,統計模型的點Sk可以是這些點P’k(t1)、…、P’k(tm)用例如與以下各項有關的系數進行加權后的質心:
-調整后的點的殘余誤差(即,在調整之后所討論的點P’k(tj)與相關聯的參考點Rk之間的歐幾里德距離);
-在該第二子步驟中在識別面部的具體點的過程中確定的誤差系數(某些點的識別可能或多或少取決于面部的位置)。
而且,在此提出了在該統計模型中僅使用不確定性很低的點Sk。由按照以上指示所確定的點Sk與這些經調整的模型中的不同相應點P’k(tj)之間的距離形成的分布的平均值和兩倍的標準偏差的總和例如被用作不確定性的測量值(對于k的每個值)。
在剩余的處理中,僅使用這種不確定性測量值低于預定閾值的點Sk。如果這個條件不允許選擇三個點,則使用具有最小不確定性測量值的三個點。
這允許選擇經處理的面部的最穩定和最具特征的具體點,并且因此提高模型的穩健性,從而允許該模型提供穩定且精確的計量參考系。
作為變體,可以允許用戶(例如眼鏡師)選擇(通過交互式選擇,例如借助于處理裝置T的屏幕和用戶接口)最具代表性的點Sk、或者對每個點Sk提供加權。
根據另一個變體,可以在該統計模型中使用所有點Sk,每個點Sk是根據m個經調整的模型的m個相應點P’k(tj)來確定的。
在該第四子步驟的第一次迭代中獲得的統計模型可以用作計量學參考系。然而,還能夠將調整誤差最小化,如現在將解釋的。
在這種情況下,在隨后的第五子步驟中,確定第三和第四子步驟的新迭代是否是必要的。為此,例如計算出與針對在該第四子步驟中所使用的點集Sk獲得的不確定性測量值的平均值相等的優值函數。
如果在第五子步驟中確定第三和第四子步驟的新迭代必須實施(例如,由于剛剛計算出的優值函數高于預先限定的閾值并且由于還沒有達到預定迭代次數),則該方法這一次使用在第四子步驟的上一次迭代中獲得的統計模型作為參考模型來重復該第三子步驟。因此,針對不確定性低的點Sk使用Rk=Sk來實施第三子步驟。
如果在該第五子步驟中確定該第三和第四子步驟的新迭代是不必要的(例如由于剛剛計算出的優值函數小于或等于預先限定的閾值或者由于已經達到預定迭代次數),則能夠使用所獲得的上一個統計模型。
因此,在使用用于捕捉立體圖像的第一裝置的情況下,根據在步驟a)中所捕捉到的佩戴者的頭部的一系列三維第一圖像的統計分析來確定與該佩戴者的頭部相關聯的至少三個具體點Sk。
該佩戴者的頭部的這些具體點還可以包括間接位于該佩戴者的頭部上的具體點。
在佩戴者的頭部裝備有配件的情況下,所討論的問題是與這個配件相關聯的至少三個點。
在后一種情況下,該配件的這三個具體點的相對位置由于構造是在與這個配件相關聯的參考系中已知的。
接著可以根據圖像識別算法、通過考慮對這三個點的相對位置由于構造而存在的限制因素更容易地標識該配件的這三個具體點。確切地,這些具體點是可容易標識的,因為它們具有非常可識別的形狀以及對比度特征,并且因為其相對位置是固定的。
步驟c)
在實踐中,步驟c)優選地是由佩戴者在家或在其日常環境中-辦公室、車里等-并且使用常見的圖像捕捉裝置來執行的。
步驟c)的目的在于,在佩戴者處于自然姿勢(即,不受限姿勢)時進行測量。
優選地,在步驟c)中,在該佩戴者在其環境中的一個或多個習慣活動過程中確定該佩戴者的頭部的該第二表示。
更精確地,該佩戴者的習慣活動尤其可以是以下活動中的一項:
-閱讀不同介質,
-在書桌上工作,
-開車,
-練習運動,
-烹飪,
-控制游戲操作臺,
-坐下休息,
-看電視,
-演奏樂器。
這個測量步驟可以用不同的方式執行。
根據步驟c)的第一實施例,在步驟c)中,借助于用于捕捉三維圖像的第二裝置來采集該佩戴者的頭部的至少一張第二三維圖像,該第二裝置是與該第一圖像捕捉裝置不同的,所述第二三維圖像構成了該佩戴者的頭部的所述第二表示。
用于捕捉三維圖像的第二裝置例如是三維掃描儀、或用于捕捉立體圖像的裝置,該裝置包括至少兩個設備,該至少兩個設備用于捕捉同時記錄佩戴者的頭部在兩個圖像捕捉平面中的兩張二維圖像,這兩個平面是相對于該佩戴者的頭部不同定向的。在這種情況下,每張三維圖像包括至少兩張二維圖像以及與這兩個圖像捕捉設備的相對位置有關的信息。
這個裝置尤其可以是“Kinect”,其操作原理在文件US20100118123中進行了描述。
優選地能夠設想采集多張三維圖像。
該佩戴者在此優選地是光著頭部的,即他的頭部沒有光學設備,如眼鏡架或眼科鏡片。
根據步驟c)的第二實施例,使用與該第一圖像捕捉裝置不同的第二圖像捕捉裝置來捕捉該佩戴者的頭部的至少一張第二二維圖像,該佩戴者的頭部的所述至少一張第二二維圖像構成了該佩戴者的頭部的所述第二表示。
優選地,根據步驟c)的第三實施例,使用用于捕捉二維圖像的第二裝置來采集該佩戴者的頭部在不同的頭部姿勢下的一系列第二二維圖像,這一系列第二圖像構成了該佩戴者的頭部的所述第二表示,并且針對每個所捕捉到的第二圖像,確定該佩戴者的頭部相對于該第二圖像捕捉裝置的相應位置和/或取向。
如參照步驟a)所描述的,為此目的,能夠設想將具有設定幾何特征的配件放在佩戴者的頭部上。例如,所選擇的眼鏡架或并非被選擇的鏡架的問題可能在于,該并非被選擇的鏡架優選地具有比所選擇的鏡架更大的尺寸,從而使得佩戴者的注視不被鏡架的邊緣限制。
該鏡架優選地配備有精確定位系統,該精確定位系統旨在允許佩戴者的頭部的空間位置根據配備有該定位系統的佩戴者頭部的捕捉圖像確定。這個精確定位系統在文件FR 2914173的第7頁第5行至第10頁第8行中進行了詳細描述。因此將不在此處對此進行詳細描述。
此精確定位系統具有預先確定的幾何特征,這些幾何特征允許在與圖像捕捉裝置相關聯的參考系中從該佩戴者頭部的捕捉圖像(此定位系統出現在該圖像中)確定該佩戴者頭部的空間位置和取向。因此,此精確定位系統允許在與圖像捕捉裝置相關聯的參考系中確定與佩戴者的頭部相關聯的參考系的位置和取向。
佩戴者的頭部可以直接配備有精確定位系統。
根據步驟c)的這個第三實施例的一個變體,在該佩戴者正將其目光注視在視覺目標上時采集該佩戴者的頭部的這一系列第二圖像,在每張第二圖像的捕捉過程中確定這個視覺目標相對于該第二圖像捕捉裝置的位置。
這可以例如借助于用于跟蹤注視方向的裝置(如眼睛跟蹤器)來完成。
這樣的眼睛跟蹤器例如被集成在某些手機中并且因此是大多數消費者容易使用的。
在眼鏡師處或在佩戴者的家里可以執行校準該眼睛跟蹤器的在先步驟。
作為變體,還能夠提供的是使這個目標具有相對于在步驟c)中所使用的第二圖像捕捉裝置的已知預定位置。這尤其在當這個第二圖像捕捉裝置被集成在顯示屏中或在起碼相對于顯示該目標的顯示屏具有固定和預定位置時是這種情況。
通過使用給予佩戴者的指令,還能夠請求佩戴者將圖像捕捉裝置放在精確位置上,例如放在佩戴者看到的儀表盤或電視或屏幕上。
而且,無論步驟c)的實施實施例怎樣,在所述第二二維或三維圖像的捕捉過程中確定所述第二圖像捕捉裝置的空間位置和/或取向,并且從其中確定與在這張第二圖像的捕捉過程中該佩戴者的頭部的空間位置和/或取向有關的信息。
為此,能夠提供執行校準所述用于捕捉二維或三維圖像的第二裝置的步驟,在該步驟中,用這個第二圖像捕捉裝置來捕捉專用標準物體的圖像。
這個標準物體例如是包含測試圖案、例如具有已知尺寸的黑白棋盤的圖像。這個標準物體被放在佩戴者的工作距離處,例如放在佩戴者所使用的閱讀介質(書、計算機屏幕、平板等)上。通過使用佩戴者所使用的第二圖像捕捉裝置來捕捉這個標準物體的圖像。
這個標準物體可以通過手機、尤其智能手機上的應用而被顯示。這個手機還可以用來傳輸數據集并且允許這些數據集與佩戴者的標識符相關聯。
這個手機的應用尤其可以用來通過將該電話放置成面向計算機的攝像頭來校準這個攝像頭。通過將手機和計算機放置成“面對面”、更精確地“屏幕對屏幕”,其對應的攝像機可以校準彼此。該計算機和手機的捕捉裝置可以識別彼此(商標和模型)。
還能夠通過拍下手機的應用顯示的測試圖案來確定照相機的特征。
隨后,這允許通過處理該標準物體的這張圖像來確定該第二圖像捕捉裝置相對于這個標準物體并且因此相對于閱讀介質的位置和取向。
而且,針對每張捕捉到的第二圖像,優選地記錄與在步驟c)中所使用的第二圖像捕捉裝置的配置有關的信息。例如,問題在于,給出這個裝置的物鏡的焦距、光圈等。根據所捕捉到的第二圖像中呈現的信息,這個信息允許確定在捕捉所討論的第二圖像的時刻佩戴者與該第二圖像捕捉裝置之間的距離、和/或目標與該第二圖像捕捉裝置之間的距離。
而且,該第二圖像捕捉裝置可以包括測量裝置,例如像陀螺儀、通常出現在裝備有照相機的手機中,該測量裝置可以允許確定該第二圖像捕捉裝置的空間取向。還記錄了在捕捉圖像過程中由這些測量裝置所進行的測量。
總體上,與該第二圖像的捕捉有關的所有信息以與這個第二圖像相關聯地被存儲。
根據步驟c)的第四實施例,存儲包括該佩戴者的頭部的所述第二表示的所述數據集,該表示是預先確定的。
這個數據集尤其可以包含與預先捕捉到的一張或多張三維或二維圖像相對應的數據。在多張二維圖像的情況下,該數據集還包含與對應于每張二維圖像的數據相關聯的、與這張圖像的捕捉過程中佩戴者的頭部相對于第二圖像捕捉裝置的位置和/或取向有關的信息。
在實踐中,如上文所描述的,步驟c)是在與步驟a)不同的地方執行的。
無論步驟c)的實施例怎樣,在步驟c)中建立的數據集被傳輸并存儲在信息處理服務器中,該信息處理服務器可以可選地包括以上所描述的處理裝置T。
優選地,在步驟d)之前的步驟中,設想到將在步驟a)中所捕捉的每張第一二維或三維圖像傳輸至信息處理服務器并且與該佩戴者的標識符相對應地進行存儲。該標識符可以是與佩戴者或與該佩戴者的這件設備相關聯的。表達“一件設備”尤其被理解為意指舊的或新選擇的鏡架。
在執行步驟b)之后,三個確定的具體點也被傳輸至該信息處理服務器并且與這個標識符相對應地進行存儲。
以相同方式,將在步驟c)中所捕捉的每張第二二維或三維圖像傳輸至信息處理服務器并且與該佩戴者的這個標識符相對應地進行存儲。
因此,被傳輸至該服務器的每張捕捉到的第二圖像可以是與在步驟a)中已經確定的佩戴者的頭部的這些具體點相關聯的,所述圖像與該佩戴者的所述標識符相對應地存儲在該服務器上。
步驟d)
在步驟d)中,在步驟b)的所述第二表示中標識該佩戴者的頭部的所述具體點中的每一個具體點的圖像,在步驟b)中已經確定這些具體點的相對空間位置。
于是問題在于執行圖像識別,這可以例如借助于面部識別算法、在此借助于“主動外觀模型”算法(例如,關于這個主題參見T.F.庫特(T.F.Cootes)、G.J.愛德華茲(G.J.Edwards)、C.J.泰勒(C.J.Taylor)在IEEE Transactions on Pattern Analysis and Machine Intelligence 23(6):681,2011中的文章“Active appearance models(主動外觀模型)”)來確定的。
步驟e)
在步驟e)中,根據這個標識來推導出與在所述第二表示的確定過程中該佩戴者的頭部的位置和/或取向有關的信息。
為此目的,尋求在捕捉第二表示的第二圖像過程中或者在確定相應數據集中所包含的數據的過程中、與佩戴者的頭部相關聯并且由步驟b)中所標識的這三個具體點所限定的參考系的位置和/或取向。
因此,在步驟e)中,根據在步驟d)中執行的標識以及在步驟b)中確定的佩戴者的頭部的這三個具體點的相對空間位置來推導出與在所述第二表示的確定過程中該佩戴者的頭部的位置和/或取向有關的所述信息。
總體上,在步驟e)中,在所述第二表示的確定過程中該佩戴者的頭部的位置和/或取向被確定為該佩戴者的頭部的、使得該佩戴者的頭部的這三個具體點具有這三個具體點的圖像在所述第二表示中被標識出的坐標的位置和/或取向。問題在于,優化佩戴者的頭部的參考系的位置和取向的計算,該參考系是由步驟b)中標識的這三個具體點所限定的。
事實上,問題在于,將在步驟b)中確定的佩戴者的頭部的三維參考系投影到每張第二圖像中,以便確定該佩戴者的頭部在捕捉這張第二圖像的時刻在與第二圖像捕捉裝置相關聯的參考系中的位置和/或取向。
出于這個目的,可以使用1995年3月由丹尼爾·F·德芒東(Daniel F.DeMenthon)和拉里·S·戴維斯(Larry S.Davis)出版的被稱為“PostIt方法”的方法。該方法允許根據物體的單一二維圖像和三維模型來找到該物體的位置和/或取向。
這些方法的實現方式要求找到該二維物體與三維模型之間的至少4個對應點。
該方法可以分為兩個步驟。第一步驟對應于:將該三維模型投影到該二維圖像中并且確定轉動矩陣和平移向量,從而允許使該模型的這些具體點與在這些二維第二圖像中標識的這些具體點的圖像重合。
該第二步驟是使用比例縮放因子來提高該第一步驟中執行的投影的精度的迭代步驟。
根據另一個簡化的可能性,例如在以下情況下:
-在步驟a)中,捕捉一系列第一二維圖像并且針對每張捕捉到的第一圖像,確定佩戴者的頭部相對于該第一圖像捕捉裝置的相應位置和/或取向;
-在步驟c)中,使用與該第一圖像捕捉裝置不同的第二圖像捕捉裝置,捕捉該佩戴者的頭部的至少一張第二二維圖像,構成該佩戴者的頭部的所述第二表示,
接著在步驟e)中,所述系列第一圖像中的、最接近所述第二圖像的第一圖像是與在步驟c)中所捕捉到的該第二圖像相關聯的,并且用在這個最接近的第一圖像的捕捉過程中該佩戴者的頭部的位置和/或取向來標識在所述第二圖像的捕捉過程中該佩戴者的頭部相對于所述第二圖像捕捉裝置的位置和/或取向。
為此,確定該系列第一圖像中的每張第一圖像的具體點與所討論的第二圖像的相應具體點之間的歐幾里德距離的平均值。
該系列第一圖像中的、使得這個平均值最低的那張第一圖像是與步驟c)中捕捉到的第二圖像相關聯的。而且,借助于集成到該第二圖像捕捉裝置中的測量裝置(陀螺儀)可以確定該第二圖像捕捉裝置在空間絕對參考系中的位置和/或取向,于是能夠推導出佩戴者的頭部在這樣的空間絕對參考系中的位置和/或取向。
步驟f)
在步驟f)中,根據所述第二表示以及在步驟e)中所推導出的信息來確定佩戴者的所述行為參數。
為此,在這種情況下,其中在步驟c)中,采集佩戴者的頭部的一系列第二圖像,在步驟f)中,根據這一系列中的所述第二圖像的統計處理來確定佩戴者的所述行為參數;應注意,借助于步驟b)中佩戴者的頭部的參考系的構建以及步驟e)中佩戴者的頭部的位置和/或取向的隨后確定,這是可能的。執行步驟f)的確定同時考慮這個位置和/或這個取向。
例如,在佩戴者在從屏幕視覺閱讀任務過程中并且借助于牢固地緊固至這個屏幕上的第二圖像捕捉裝置執行步驟c)的情況下,能夠在步驟e)中針對佩戴者的頭部的每張第二圖像來確定該圖像捕捉裝置與該佩戴者之間的距離。與在閱讀介質攜帶了圖像捕捉裝置時可以認為這個距離等于閱讀距離。
還能夠根據步驟c)所捕捉到的第二圖像以及步驟e)中確定的佩戴者的頭部的位置和/或取向來推導出這個閱讀距離。
這可以用各種方式、通過處理佩戴者裝備精確定位系統時所捕捉到的圖像、或者使用在校準該第二圖像捕捉裝置的在先步驟中生成的數據、或者使用與在該圖像捕捉過程中這個第二裝置的配置(特別是焦距)有關的信息來完成。
該閱讀距離于是可以被確定為針對這一系列第二圖像中的第二圖像的全部或一些圖像所確定的閱讀距離的算術平均值。
所尋求的行為參數還可以包括眼睛-頭部系數,即,佩戴者的眼睛沿所確定方向的移動幅度與這只眼睛在視近任務、例如閱讀任務過程中的最大移動幅度的比率。
在此背景下,如上文所描述執行的步驟a)和b)用于確定佩戴者的參考姿勢。
步驟c)和e)也如上文所描述的執行。
另外,在步驟c)中,將佩戴者置于他執行預先定義的閱讀任務的情境中。
此閱讀任務涉及根據所討論的語言從左到右或者從右到左閱讀至少一個包括多行(例如,4行或5行)的段落。
觀察到,佩戴者在他進行閱讀并且尤其是當他換頁時采用越來越自然的位置。
因此,優選地,使用包括多頁的文本,并且更具體地,利用與所閱讀的最后幾頁相對應的捕捉圖像。
因此該文本是其位置在任何給定時刻相對于介質是已知的目標。因此,這個位置在與該第二圖像捕捉裝置(例如是智能手機)相關聯的參考系中是已知的。
在步驟c)中,然后,針對目標的與在該第一工作距離時的各個注視方向相對應的各個位置,使用該第二圖像捕捉裝置捕捉佩戴者的頭部的圖像。
根據所捕捉的這些第二圖像,例如信息處理服務器的處理裝置確定佩戴者的至少一只眼睛的轉動中心CRO在與佩戴者的頭部相關聯的參考系中的位置。這種確定的原理本身是已知的,并且例如描述于文獻FR 2914173中,其英文等效物為文獻US 20100128220。
作為變體,可以例如通過眼鏡師所進行的測量來預先確定眼睛轉動中心在與佩戴者的頭部相關聯的參考系中的位置、佩戴者的眼睛的瞳孔的位置、以及佩戴者的眼睛的半徑。
它們可以集成到所述第二圖像的數據集中并且構成用于校準該第二圖像捕捉裝置的參數。
在步驟d)中,在步驟b)的所述第二表示中標識該佩戴者的頭部的所述具體點中的每一個具體點的圖像,在步驟b)中已經確定這些具體點的相對空間位置,并且在步驟e)中,根據這個標識來推導出與在所述第二表示的確定過程中該佩戴者的頭部的位置和/或取向有關的信息。
在實踐中,在步驟e)中,針對每張捕捉到的第二圖像來確定佩戴者的頭部的姿勢。
還能夠說,在每次圖像捕捉過程中在與佩戴者頭部相關聯的參考系中佩戴者的注視方向為將此轉動中心與在圖像捕捉期間在其相應位置上的目標連接的直線。
佩戴者的眼睛在閱讀任務過程中的角移動幅度是在步驟f)中根據所述第二表示以及在步驟e)推導出的信息被推導為在給定的、尤其水平或豎直平面中間隔最遠的兩個注視方向之間的角間距。這相當于將所捕捉到的第二圖像中的佩戴者的頭部的所有姿勢與這個參考進行比較。
由于顯示在介質上并由佩戴者閱讀的文本的尺寸、以及佩戴者的閱讀距離(即,佩戴者的雙眼與此文本之間的距離)是已知的,每只眼睛的最大角移動幅度于是被確定為佩戴者所看到的文本在所討論的水平方向上或豎直方向上的角度范圍。
通過用每只眼睛的最大角移動幅度除以每只眼睛的角移動幅度,從中推斷出被稱為眼睛-頭部系數的系數,該系數是佩戴者在閱讀任務期間的行為的特征。
此系數對佩戴者在閱讀任務期間移動他的雙眼或頭部的傾向進行量化。還有可能將眼睛的平均角移動幅度確定為佩戴者的左眼和右眼的角移動的平均值。然后,有可能從中推導出眼睛-頭部平均系數。
所討論的習慣活動所采用的靜態或動態姿勢例如與頭部相對于與佩戴者的所討論的活動(閱讀介質、樂器、車輛儀表盤等)相關聯的元素的取向相對應。
與每個注視方向、眼睛與著眼點之間的距離相關聯的工作視景可以根據如上文所描述而確定的注視方向來確定,而同時改變兩次捕捉第二圖像之間的工具距離,例如閱讀距離。將所捕捉到的這系列的第二二維或三維圖像進行統計處理還允許推導出表征上述行為參數的變化的量。
小的變化確保了行為參數的確表征了佩戴者。大的變化可以指佩戴者可能難以被這個參數表征。
因此,具有小的變化的行為參數將有利地在設計旨在用于佩戴者的眼科鏡片時加以考慮,而具有大的變化的行為參數在設計該眼科鏡片時將不被考慮。
最后,所確定的行為參數可以是佩戴者的眼鏡架在其面部上的位置。
確切地,能夠確定,鏡架的突出點(由標識的具體點組成)在佩戴者的頭部的參考系中的位置。因此,在佩戴者的頭部的這個參考系中可以確定眼鏡架的位置。
這個位置例如可以包括佩戴者的鏡架腿和耳朵的相對位置、和/或鏡架的鏡圈相對于佩戴者的瞳孔的位置、和/或鏡架的鼻梁相對于佩戴者的鼻子的位置。鏡架的鼻梁的位置可以沿豎直方向確定、與佩戴者的鼻子高度相對應、并且在深度方面與鏡片-眼睛距離相對應。
- 還沒有人留言評論。精彩留言會獲得點贊!