一種用于對話交互系統(tǒng)的數(shù)據(jù)處理方法及裝置與流程
本發(fā)明涉及人機(jī)交互技術(shù)領(lǐng)域,具體地說,涉及一種用于對話交互系統(tǒng)的數(shù)據(jù)處理方法及裝置。
背景技術(shù):
隨著科學(xué)技術(shù)的不斷發(fā)展,信息技術(shù)、計(jì)算機(jī)技術(shù)以及人工智能技術(shù)的引入,機(jī)器人的研究已經(jīng)逐步走出工業(yè)領(lǐng)域,逐漸擴(kuò)展到了醫(yī)療、保健、家庭、娛樂以及服務(wù)行業(yè)等領(lǐng)域。而人們對于機(jī)器人的要求也從簡單重復(fù)的機(jī)械動作提升為具有擬人問答、自主性及與其他機(jī)器人進(jìn)行交互的智能機(jī)器人,人機(jī)交互也就成為決定智能機(jī)器人發(fā)展的重要因素。
對話交互系統(tǒng)作為人機(jī)交互系統(tǒng)中的核心模塊,在人機(jī)交互系統(tǒng)中扮演著舉足輕重的角色。在日常的人機(jī)交互過程中,用戶與機(jī)器人之間的對話交互占據(jù)了絕大多數(shù)的比例。因此,對話交互系統(tǒng)的好壞直接關(guān)系到智能機(jī)器人產(chǎn)品的用戶體驗(yàn),進(jìn)而影響用戶的去留,如何提升智能機(jī)器人的對話交互能力則是亟待解決的問題。
技術(shù)實(shí)現(xiàn)要素:
為解決上述問題,本發(fā)明提供了一種用于對話交互系統(tǒng)的數(shù)據(jù)處理方法,其包括:
交互數(shù)據(jù)獲取步驟,獲取用戶輸入的對話交互數(shù)據(jù);
對話模型結(jié)果生成步驟,對所述對話交互數(shù)據(jù)進(jìn)行解析,將解析結(jié)果輸入到預(yù)設(shè)對話生成模型中,得到對話模型結(jié)果,其中,所述對話生成模型是基于NRM以及增強(qiáng)學(xué)習(xí)算法構(gòu)建的;
反饋數(shù)據(jù)輸出步驟,根據(jù)所述對話模型結(jié)果生成相應(yīng)的反饋數(shù)據(jù)并輸出。
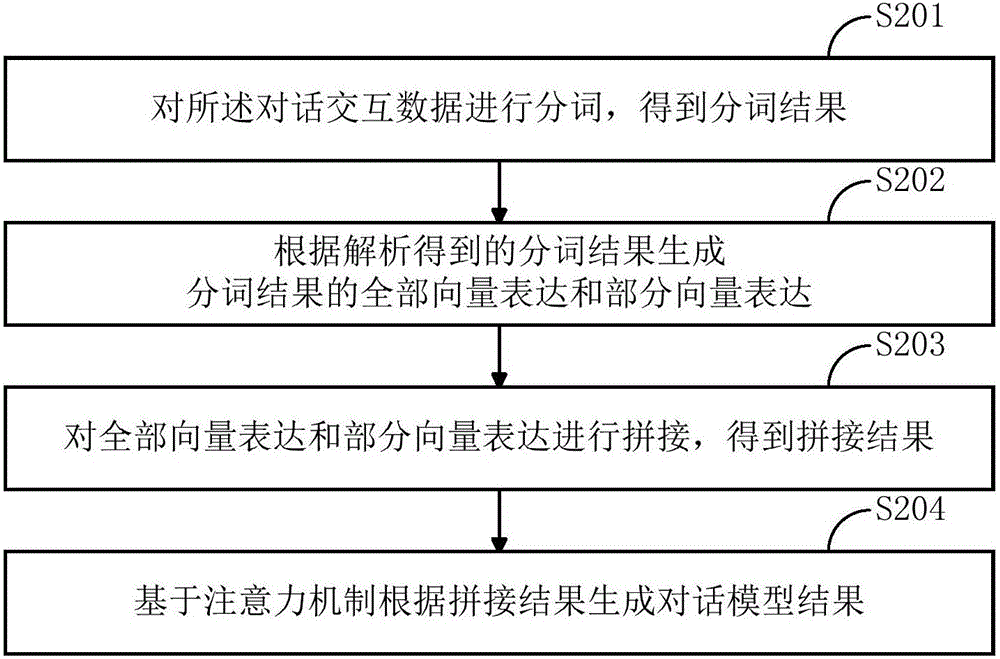
根據(jù)本發(fā)明的一個實(shí)施例,所述預(yù)設(shè)對話生成模型包括編碼層和解碼層,其中,所述編碼層用于根據(jù)解析得到的分詞結(jié)果生成所述分詞結(jié)果的全部向量表達(dá)和部分向量表達(dá),并對所述全部向量表達(dá)和部分向量表達(dá)進(jìn)行拼接,得到拼接結(jié)果,所述解碼層用于基于注意力機(jī)制根據(jù)所述拼接結(jié)果生成所述對話模型結(jié)果。
根據(jù)本發(fā)明的一個實(shí)施例,所述解碼層基于增強(qiáng)學(xué)習(xí)算法的神經(jīng)網(wǎng)絡(luò)進(jìn)行對話模型結(jié)果的生成。
根據(jù)本發(fā)明的一個實(shí)施例,在所述增強(qiáng)學(xué)習(xí)算法中,將MMI函數(shù)作為獎勵函數(shù)。
根據(jù)本發(fā)明的一個實(shí)施例,所述方法還包括:
模型修正步驟,獲取所述用戶針對所述反饋數(shù)據(jù)的輸入數(shù)據(jù),并根據(jù)所述輸入數(shù)據(jù)對所述預(yù)設(shè)對話生成模型進(jìn)行修正。
本發(fā)明還提供了一種用于對話交互系統(tǒng)的數(shù)據(jù)處理裝置,其包括:
交互數(shù)據(jù)獲取模塊,其用于獲取用戶輸入的對話交互數(shù)據(jù);
對話模型結(jié)果生成模塊,其用于對所述對話交互數(shù)據(jù)進(jìn)行解析,將解析結(jié)果輸入到預(yù)設(shè)對話生成模型中,得到對話模型結(jié)果,其中,所述對話生成模型是基于NRM以及增強(qiáng)學(xué)習(xí)算法構(gòu)建的;
反饋數(shù)據(jù)輸出模塊,其用于根據(jù)所述對話模型結(jié)果生成相應(yīng)的反饋數(shù)據(jù)并輸出。
根據(jù)本發(fā)明的一個實(shí)施例,所述預(yù)設(shè)對話生成模型包括編碼層和解碼層,其中,所述編碼層配置為根據(jù)解析得到的分詞結(jié)果生成所述分詞結(jié)果的全部向量表達(dá)和部分向量表達(dá),并對所述全部向量表達(dá)和部分向量表達(dá)進(jìn)行拼接,得到拼接結(jié)果,所述解碼層配置為基于注意力機(jī)制根據(jù)所述拼接結(jié)果生成所述對話模型結(jié)果。
根據(jù)本發(fā)明的一個實(shí)施例,所述解碼層配置為基于增強(qiáng)學(xué)習(xí)算法的神經(jīng)網(wǎng)絡(luò)進(jìn)行反饋數(shù)據(jù)的生成。
根據(jù)本發(fā)明的一個實(shí)施例,在所述增強(qiáng)學(xué)習(xí)算法中,將MMI函數(shù)作為獎勵函數(shù)。
根據(jù)本發(fā)明的一個實(shí)施例,所述裝置還包括:
模型修正模塊,其用于獲取所述用戶針對所述反饋數(shù)據(jù)的輸入數(shù)據(jù),并根據(jù)所述輸入數(shù)據(jù)對所述預(yù)設(shè)對話生成模型進(jìn)行修正。
相較于現(xiàn)有方法,本發(fā)明所提供的用于對話交互系統(tǒng)的數(shù)據(jù)處理方法能夠基于用戶的提問,生成更合理的答案,同時(shí),本方法還能夠解決當(dāng)前基于MLE目標(biāo)函數(shù)的編碼層-解碼層框架的對話生成模型生成的反饋結(jié)果較為保守的問題,這樣也就使得最終生成并輸出給用戶的反饋數(shù)據(jù)更加人性化和貼合實(shí)際交互場景,從而提高了對話交互系統(tǒng)的用戶體驗(yàn)。
此外,本方法還能夠通過對目標(biāo)函數(shù)的自定義,來使得對話交互系統(tǒng)與用戶之間的對話交互過程根據(jù)更加具有趣味性、多樣性、交互性和持續(xù)性,這有助于提高對話交互系統(tǒng)的用戶粘度。
本發(fā)明的其它特征和優(yōu)點(diǎn)將在隨后的說明書中闡述,并且,部分地從說明書中變得顯而易見,或者通過實(shí)施本發(fā)明而了解。本發(fā)明的目的和其他優(yōu)點(diǎn)可通過在說明書、權(quán)利要求書以及附圖中所特別指出的結(jié)構(gòu)來實(shí)現(xiàn)和獲得。
附圖說明
為了更清楚地說明本發(fā)明實(shí)施例或現(xiàn)有技術(shù)中的技術(shù)方案,下面將對實(shí)施例或現(xiàn)有技術(shù)描述中所需要的附圖做簡單的介紹:
圖1是根據(jù)本發(fā)明一個實(shí)施例的用于對話交互系統(tǒng)的數(shù)據(jù)處理方法的實(shí)現(xiàn)流程示意圖;
圖2是根據(jù)本發(fā)明一個實(shí)施例的對話模型結(jié)果生成步驟的具體實(shí)現(xiàn)流程示意圖;
圖3是根據(jù)本發(fā)明一個實(shí)施例的對話生成模型的結(jié)構(gòu)示意圖;
圖4是根據(jù)本發(fā)明一個實(shí)施例的用于對話交互系統(tǒng)的數(shù)據(jù)處理裝置的結(jié)構(gòu)示意圖。
具體實(shí)施方式
以下將結(jié)合附圖及實(shí)施例來詳細(xì)說明本發(fā)明的實(shí)施方式,借此對本發(fā)明如何應(yīng)用技術(shù)手段來解決技術(shù)問題,并達(dá)成技術(shù)效果的實(shí)現(xiàn)過程能充分理解并據(jù)以實(shí)施。需要說明的是,只要不構(gòu)成沖突,本發(fā)明中的各個實(shí)施例以及各實(shí)施例中的各個特征可以相互結(jié)合,所形成的技術(shù)方案均在本發(fā)明的保護(hù)范圍之內(nèi)。
同時(shí),在以下說明中,出于解釋的目的而闡述了許多具體細(xì)節(jié),以提供對本發(fā)明實(shí)施例的徹底理解。然而,對本領(lǐng)域的技術(shù)人員來說顯而易見的是,本發(fā)明可以不用這里的具體細(xì)節(jié)或者所描述的特定方式來實(shí)施。
另外,在附圖的流程圖示出的步驟可以在諸如一組計(jì)算機(jī)可執(zhí)行指令的計(jì)算機(jī)系統(tǒng)中執(zhí)行,并且,雖然在流程圖中示出了邏輯順序,但是在某些情況下,可以以不同于此處的順序執(zhí)行所示出或描述的步驟。
對話交互系統(tǒng)處理的數(shù)據(jù)對象主要包括用戶問題和答案。依據(jù)用戶問題的所屬數(shù)據(jù)領(lǐng)域,對話交互系統(tǒng)通常可分為面向限定域的問答系統(tǒng)、面向開放域的問答系統(tǒng)、以及面向常用問題集的對話交互系統(tǒng)。依據(jù)答案的不同數(shù)據(jù)來源,對話交互系統(tǒng)可劃分為基于結(jié)構(gòu)化數(shù)據(jù)的對話交互系統(tǒng)、基于自由文本的對話交互系統(tǒng)、以及基于問答對的對話交互系統(tǒng)。
此外,按照答案的生成反饋機(jī)制劃分,對話交互系統(tǒng)還可以分為基于檢索式的對話交互系統(tǒng)和基于生成式的對話交互系統(tǒng)。其中,檢索式對話交互系統(tǒng)是從已經(jīng)存在的語料中查找與問題信息最佳匹配的答案信息,檢索式對話交互系統(tǒng)得到的答案信息的準(zhǔn)確度較高但適應(yīng)性較差。與之相反,生成式對話交互系統(tǒng)的答案信息是通過大量的語料和機(jī)器學(xué)習(xí)算法解析得到,生成式對話交互系統(tǒng)所得到的答案信息具有很好的系統(tǒng)適應(yīng)性但目前尚無法保證較高的準(zhǔn)確率。
針對現(xiàn)有技術(shù)中所存在的上述問題,本實(shí)施例提供了一種用于對話交互系統(tǒng)的數(shù)據(jù)處理方法。
為了更加清楚地闡述本實(shí)施例所提供的用于對話交互系統(tǒng)的數(shù)據(jù)處理方法的實(shí)現(xiàn)原理、實(shí)現(xiàn)過程以及優(yōu)點(diǎn),以下結(jié)合圖1所示實(shí)現(xiàn)流程示意圖來對該方法作進(jìn)一步地說明。
如圖1所示,本實(shí)施例所提供的用于對話交互系統(tǒng)的數(shù)據(jù)處理方法首先在步驟S101中獲取用戶輸入的對話交互數(shù)據(jù)。需要指出的是,根據(jù)實(shí)際需要,該方法在步驟S101中所獲取到的對話交互數(shù)據(jù)既可以是利用音頻采集設(shè)備(例如麥克風(fēng)等)所采集到的語音交互數(shù)據(jù),也可以是利用文本采集設(shè)備(例如鍵盤等)所采集到的文本交互數(shù)據(jù),本發(fā)明不限于此。
在得到上述對話交互數(shù)據(jù)后,該方法會在步驟S102中對上述對話交互數(shù)據(jù)進(jìn)行解析,從而得到解析結(jié)果。最后,該方法會在步驟S103中將步驟S102中所得到的解析結(jié)果輸入到預(yù)設(shè)對話生成模型中,從而由該對話生成模型根據(jù)上述解析結(jié)果來生成相應(yīng)的對話模型結(jié)果。
為了克服現(xiàn)有的檢索式對話生成系統(tǒng)生成答案信息準(zhǔn)確度差的問題,本實(shí)施例中,該方法在步驟S103中所采用了基于NRM以及增強(qiáng)學(xué)習(xí)算法構(gòu)建的預(yù)設(shè)對話生成模型。
圖2示出了本實(shí)施例中對對話交互數(shù)據(jù)進(jìn)行解析以及利用對話生成模型生成相應(yīng)的對話模型結(jié)果的具體實(shí)現(xiàn)流程示意圖,圖3示出了本實(shí)施例中對話生成模型的結(jié)構(gòu)示意圖,以下結(jié)合圖2和圖3來進(jìn)行進(jìn)一步的闡述。
如圖2所示,該方法對上述對話交互數(shù)據(jù)進(jìn)行解析時(shí),優(yōu)選地在步驟S201中對上述對話交互數(shù)據(jù)進(jìn)行分詞處理,從而得到對話交互數(shù)據(jù)的分詞結(jié)果。需要指出的是,在本發(fā)明的不同實(shí)施例中,根據(jù)實(shí)際需要,該方法在對對話交互數(shù)據(jù)進(jìn)行分詞處理時(shí),既可以采用基于字符串匹配的方式,也可以采用基于統(tǒng)計(jì)以及機(jī)器學(xué)習(xí)的方式,抑或是采用其他合理方式,本發(fā)明不限于此。
在得到對話交互數(shù)據(jù)的分析結(jié)果后,該方法會在步驟S202中根據(jù)步驟S201中所得到的分詞結(jié)果來利用預(yù)設(shè)對話生成模型生成上述分詞結(jié)果的全部向量表達(dá)和部分向量表達(dá)。
本實(shí)施例中,該方法所使用的對話生成模型包括有編碼層和解碼層。其中,編碼層和解碼層均采用了RNN模型。不同于傳統(tǒng)的FNN(Feed-forward Neural Networks,前向反饋神經(jīng)網(wǎng)絡(luò))模型,RNN模型引入了定向循環(huán),其能夠處理那些輸入之間前后關(guān)聯(lián)的問題。
傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)模型是從輸入層到隱含層再到輸出層,層與層之間是全連接的,每層之間的節(jié)點(diǎn)是無連接的。但是這種普通的神經(jīng)網(wǎng)絡(luò)對于很多問題卻無能無力。例如,你要預(yù)測句子的下一個單詞是什么,一般需要用到前面的單詞,因?yàn)橐粋€句子中前后單詞并不是獨(dú)立的。
近年來,深度神經(jīng)網(wǎng)絡(luò)在諸如圖像分類、語音識別等任務(wù)上被深入探索并取得了突出的效果,表現(xiàn)出了優(yōu)異的表示學(xué)習(xí)能力。與此同時(shí),通過深度神經(jīng)網(wǎng)絡(luò)對語言學(xué)習(xí)表示已逐漸成為一個新的研究趨勢。
然而,由于人類語言的靈活多變以及語義信息的復(fù)雜抽象,使得深度神經(jīng)網(wǎng)絡(luò)模型在語言表示學(xué)習(xí)上的應(yīng)用面臨比在圖像、語音更大的挑戰(zhàn)。其一,相比于語音和圖像,語言是非自然信號,完全是人類文明進(jìn)程中,由大腦產(chǎn)生和處理的符號系統(tǒng),是人類文明智慧的高度體現(xiàn),語言的變化性和靈活度遠(yuǎn)遠(yuǎn)超過圖像和語音信號。其二,圖像和語音具有明確的數(shù)學(xué)表示,例如灰度圖像為數(shù)學(xué)上的數(shù)值矩陣,而且其表示的最小粒度元素都有確定的物理意義,圖像像素的每個點(diǎn)的值表示一定的灰度色彩值。
因此本實(shí)施例所提供的方法采用了NRM結(jié)合RNN神經(jīng)網(wǎng)絡(luò)來進(jìn)行分析,RNN之所以稱為循環(huán)神經(jīng)網(wǎng)路,是因?yàn)橐粋€序列當(dāng)前的輸出與前面的輸出也有關(guān)。具體地表現(xiàn)形式為網(wǎng)絡(luò)會對前面的信息進(jìn)行記憶并應(yīng)用于當(dāng)前輸出的計(jì)算中,即隱藏層之間的節(jié)點(diǎn)不再無連接而是有連接的,并且隱藏層的輸入不僅包括輸入層的輸出還包括上一時(shí)刻隱藏層的輸出。理論上,RNN能夠?qū)θ魏伍L度的序列數(shù)據(jù)進(jìn)行處理。
如圖3所示,本實(shí)施例中,編碼層的輸入層Input X中各個神經(jīng)元的輸入數(shù)據(jù)為分詞結(jié)果中的各個分詞,例如xi表示分詞結(jié)果中的第i個分詞。編碼層的隱藏層Layer H中各個神經(jīng)元優(yōu)選地為一個非線性的函數(shù)(例如logistic function,一般采用LSTM/GRU核),對于隱藏層中的第i個神經(jīng)元hi來說,該神經(jīng)元的輸入為hi-1和xi。本實(shí)施例中,編碼層的隱藏層的輸出為一個對解析結(jié)果的全部向量表達(dá)。
本實(shí)施例中,基于NRM,編碼層采用了混合機(jī)制,具體地,與隱藏層Layer H類似的,神經(jīng)元層Layer G中各個神經(jīng)元優(yōu)選地為一個非線性的函數(shù),對于其中的第i個神經(jīng)元gi來說,該神經(jīng)元的輸入為xi和gi-1。該神經(jīng)元層Layer G的輸出為一個對解析結(jié)果的部分向量表達(dá)。
從上述描述中可以看出,本實(shí)施例中,編碼層通過采用混合機(jī)制來根據(jù)步驟S201的分析結(jié)果得到對應(yīng)的向量表達(dá),這種方式不僅能夠?qū)崿F(xiàn)對用戶所輸入的對話交互數(shù)據(jù)的全部把握,同時(shí)還能夠充分保留對話交互數(shù)據(jù)的細(xì)節(jié)信息,這樣也就為最終所生成的反饋數(shù)據(jù)的準(zhǔn)確度以及適用度提供了基礎(chǔ)。
如圖2和圖3所示,本實(shí)施例中,在得到上述分析結(jié)果的全部向量表達(dá)和部分向量表達(dá)后,該方法會在步驟S203中對上述分析結(jié)果的全部向量表達(dá)和部分向量表達(dá)進(jìn)行拼接,從而得到拼接結(jié)果。
在得到拼接結(jié)果后,該方法會在步驟S204中由解碼層來根據(jù)步驟S203中所得到的拼接結(jié)果生成對話模型結(jié)果。具體地,本實(shí)施例中,基于NRM,解碼層優(yōu)選地采用基于注意力機(jī)制的方式來根據(jù)步驟S203中所得到的拼接結(jié)果生成相應(yīng)的對話模型結(jié)果。
綜上,NRM在編碼部分采用一種混合機(jī)制,從而使編碼得到中間表示的序列不僅能夠?qū)崿F(xiàn)用戶語句信息的整體把握,同時(shí)還能充分保留句子的細(xì)節(jié)信息。并且在解碼部分采用了注意力機(jī)制,從而使生成模型可以相對容易的掌握問答過程中的復(fù)雜交互模式。
進(jìn)一步,本實(shí)施例中,解碼層采用基于增強(qiáng)學(xué)習(xí)算法的循環(huán)神經(jīng)網(wǎng)路來生成對話模型結(jié)果。增強(qiáng)學(xué)習(xí)是一種與監(jiān)督學(xué)習(xí)、非監(jiān)督學(xué)習(xí)不同的學(xué)習(xí)方法,它能夠解決類似下棋中要做一系列的決策才能確定最終結(jié)果的問題,而這正是監(jiān)督學(xué)習(xí)和非監(jiān)督學(xué)習(xí)所解決不了的。
增強(qiáng)學(xué)習(xí)由智能體agent和環(huán)境environment兩部份組成,其包含了幾大元素,即狀態(tài)集state(即所有可能出現(xiàn)的狀態(tài),對應(yīng)于下棋問題中棋子的位置集合)、行動集action(即所有可能的行動,對應(yīng)于下棋問題中棋子的落子方案)、決策函數(shù)(即在某個狀態(tài)state生成某一個行動action的過程)和獎勵函數(shù)reward function(即用來獎勵行動的目標(biāo)函數(shù))。這樣,智能體agent的整個決策過程就是類似于“狀態(tài)-(行動)-狀態(tài)-(行動)-狀態(tài)-…”的流程。
對于現(xiàn)有的增強(qiáng)學(xué)習(xí)算法來說,其通常采用最大似然函數(shù)的負(fù)對數(shù)來作為目標(biāo)函數(shù)。最大似然估計(jì)(MLE)知識選擇使觀察到的數(shù)據(jù)即(即解碼層輸出變長的句子)出現(xiàn)概率最大的參數(shù)(即編碼層-解碼層里的參數(shù))的值。然而,現(xiàn)有的這種增強(qiáng)學(xué)習(xí)算法容易導(dǎo)致所得到的針對于問題信息的答案信息偏保守。即,在給定一個問題信息的情況下,采用最大似然函數(shù)的負(fù)對數(shù)作為目標(biāo)函數(shù)的增強(qiáng)學(xué)習(xí)算法往往容易生成一個偏保守的答案信息,該答案信息不容易出現(xiàn)語義上的錯誤,但同時(shí)也沒有實(shí)際上的意義。
例如,對于“來上學(xué)頭疼感冒了”的問題信息,采用最大似然函數(shù)的負(fù)對數(shù)作為目標(biāo)函數(shù)的增強(qiáng)學(xué)習(xí)算法通常會得到諸如“我正在閉關(guān)修煉中,稍后我們再愉快地玩耍”。
針對上述問題,本實(shí)施例所提供的方法在步驟S204中基于增強(qiáng)學(xué)習(xí)根據(jù)步驟S203中所得到的結(jié)果生成相應(yīng)的對話模型結(jié)果時(shí),其目標(biāo)函數(shù)采用了最大互信息(MMI)函數(shù)。與基于MLE目標(biāo)函數(shù)不同的是,基于MMI函數(shù)的增強(qiáng)學(xué)習(xí)算法能夠建立輸入句子與輸出句子之間的互信息。
如圖3所示,本實(shí)施例中,解碼層作為一個智能體,解碼層中的參數(shù)作為決策policy,Layer Y中的每一個神經(jīng)元作為一個state,各個神經(jīng)元的輸出數(shù)據(jù)作為行動action,獎勵函數(shù)為MMI函數(shù)。需要指出的是,在本發(fā)明的其他本實(shí)施例中,獎勵函數(shù)也可以增加為更多目標(biāo)函數(shù)的線性組合,以此實(shí)現(xiàn)對話生成模型的不同功能目的。
本實(shí)施例中,解碼層優(yōu)選地包括三層神經(jīng)元結(jié)構(gòu),其中,輸入層Layer C的每個神經(jīng)元會接收上述拼接結(jié)果中的對應(yīng)向量。需要指出的是,本實(shí)施例中,輸入層Layer C的每個神經(jīng)元所接收的向量是不相同的。
Layer H作為解碼層的隱藏層,其第i個神經(jīng)元的輸入為(si-1,yi-1,ci),輸出為si。其中,si-1表示隱藏層中第i-1個神經(jīng)元的輸出,yi-1表示輸出層中第i-1個神經(jīng)元的輸出,ci表示輸入層中第i個神經(jīng)元的輸出。
Output Y作為解碼層的輸出層,其第i個神經(jīng)元的輸入為(si,yi-1,ci),輸出為yi。該輸出層的輸出數(shù)據(jù)也就是整個對話生成模型根據(jù)解析結(jié)果所生成的對話模型結(jié)果,該結(jié)果可以用(y1,y2,…yT’)表示。其中,yi為對話模型結(jié)果中的第i個詞。本實(shí)施例中,輸出層優(yōu)選地采用softmax非線性函數(shù)來實(shí)現(xiàn)。當(dāng)然,在本發(fā)明的其他實(shí)施例中,輸出層還可以其他合理的函數(shù)來實(shí)現(xiàn),本發(fā)明不限于此。
再次如圖1所示,本實(shí)施例中,在得到對話模型結(jié)果后,該方法會在步驟S104中根據(jù)步驟S103所得到的對話模型結(jié)果來生成相應(yīng)的反饋數(shù)據(jù)并輸出。需要指出的是,在本發(fā)明的不同實(shí)施例中,根據(jù)實(shí)際需要,該方法在步驟S104中所生成的反饋數(shù)據(jù)可以采用不同的呈現(xiàn)形式(例如文本、語音、肢體動作或圖像等),本發(fā)明不限于此。
例如,對于用戶輸入的對話交互數(shù)據(jù)“來上學(xué)頭疼感冒了”,該方法在步驟S104中根據(jù)步驟S103中所得到的對話模型結(jié)果可以生成輸入“我也是頭疼了”的語音反饋數(shù)據(jù)。
再例如,對于用戶輸入的對話交互數(shù)據(jù)“每年元旦都來高燒”,現(xiàn)有的數(shù)據(jù)處理方法通常會得到諸如“每年元旦都去醫(yī)院看病”,而本實(shí)施例所提供的方法通過在編碼層添加隱藏層Layer H和/或Layer G,從而使得對話交互系統(tǒng)能夠更加準(zhǔn)確地解析上述對話交互數(shù)據(jù)的語義,進(jìn)而可以生成諸如“祝你早日康復(fù),身體健康”。
需要指出的是,本實(shí)施例中,為了使得對話交互系統(tǒng)能夠與用戶更好地進(jìn)行交互,該方法還可以對上述預(yù)設(shè)對話生成模型進(jìn)行修正。具體地,如圖1所示,該方法會在步驟S105中獲取用戶針對上述反饋數(shù)據(jù)的輸入數(shù)據(jù),并根據(jù)該輸入數(shù)據(jù)來對預(yù)設(shè)對話生成模型進(jìn)行修正。
從上述描述中可以看出,相較于現(xiàn)有方法,本實(shí)施例所提供的用于對話交互系統(tǒng)的數(shù)據(jù)處理方法能夠使得變長的句子能夠被神經(jīng)網(wǎng)絡(luò)較好的表達(dá)。同時(shí),本方法還能夠解決當(dāng)前基于MLE目標(biāo)函數(shù)的編碼層-解碼層框架的對話生成模型生成的反饋結(jié)果較為保守的問題,這樣也就使得最終生成并輸出給用戶的反饋數(shù)據(jù)更加人性化和貼合實(shí)際交互場景,從而提高了對話交互系統(tǒng)的用戶體驗(yàn)。
此外,本方法還能夠通過對目標(biāo)函數(shù)的自定義,來使得對話交互系統(tǒng)與用戶之間的對話交互過程根據(jù)更加具有趣味性、多樣性、交互性和持續(xù)性,這有助于提高對話交互系統(tǒng)的用戶粘度。
本發(fā)明還提供了一種用于對話交互系統(tǒng)的數(shù)據(jù)處理裝置,圖4示出了本實(shí)施例中該數(shù)據(jù)處理裝置的結(jié)構(gòu)示意圖。
如圖4所示,本實(shí)施例所提供的用于對話交互系統(tǒng)的數(shù)據(jù)處理裝置優(yōu)選地包括:交互數(shù)據(jù)獲取模塊401、對話模型生成模塊402、反饋數(shù)據(jù)輸出模塊403以及模型修正模塊404。其中,交互數(shù)據(jù)獲取模塊401用于獲取用戶輸入的對話交互數(shù)據(jù)。需要指出的是,根據(jù)實(shí)際需要獲取的對話交互數(shù)據(jù)的形式的不同,交互數(shù)據(jù)獲取模塊401可以采用不同的電路或設(shè)備來實(shí)現(xiàn),本發(fā)明不限于此。例如,交互數(shù)據(jù)獲取模塊401可以通過音頻采集設(shè)備(例如麥克風(fēng)等)來實(shí)現(xiàn),以采集相應(yīng)的語音交互數(shù)據(jù);交互數(shù)據(jù)獲取模塊401還可以文本采集設(shè)備(例如鍵盤等)來實(shí)現(xiàn),以采集相應(yīng)的文本交互數(shù)據(jù)。
在得到對話交互數(shù)據(jù)后,交互數(shù)據(jù)獲取模塊401會將上述對話交互數(shù)據(jù)傳輸至對話模型結(jié)果生成模塊402。對話模型結(jié)果生成模塊402會對接收到的對話交互數(shù)據(jù)進(jìn)行解析,并根據(jù)解析結(jié)果來利用預(yù)設(shè)對話生成模塊生成相應(yīng)的對話模型結(jié)果。
對話模型結(jié)果生成模塊402會將自身生成的對話模型結(jié)果傳輸至反饋數(shù)據(jù)輸出模塊403,以由反饋數(shù)據(jù)輸出模塊403根據(jù)上述對話模型結(jié)果生成相應(yīng)的反饋數(shù)據(jù)并輸出。
本實(shí)施例中,為了使得對話交互系統(tǒng)能夠與用戶更好地進(jìn)行交互,該數(shù)據(jù)處理裝置還可以利用模型修正模塊404對上述預(yù)設(shè)對話生成模型進(jìn)行修正。具體地,模型修正模塊404會獲取用戶針對上述反饋數(shù)據(jù)的輸入數(shù)據(jù),并根據(jù)該輸入數(shù)據(jù)來對預(yù)設(shè)對話生成模型進(jìn)行修正。
需要指出的是,本實(shí)施例中,對話模型結(jié)果生成模塊402、反饋數(shù)據(jù)輸出模塊403以及模型修正模塊404實(shí)現(xiàn)其各自功能的具體原理以及流程與上述圖1中步驟S102至步驟S105所闡述的內(nèi)容類似,故在此不再對話模型結(jié)果生成模塊402、反饋數(shù)據(jù)輸出模塊403以及模型修正模塊404的相關(guān)內(nèi)容進(jìn)行贅述。
應(yīng)該理解的是,本發(fā)明所公開的實(shí)施例不限于這里所公開的特定結(jié)構(gòu)或處理步驟,而應(yīng)當(dāng)延伸到相關(guān)領(lǐng)域的普通技術(shù)人員所理解的這些特征的等同替代。還應(yīng)當(dāng)理解的是,在此使用的術(shù)語僅用于描述特定實(shí)施例的目的,而并不意味著限制。
說明書中提到的“一個實(shí)施例”或“實(shí)施例”意指結(jié)合實(shí)施例描述的特定特征、結(jié)構(gòu)或特性包括在本發(fā)明的至少一個實(shí)施例中。因此,說明書通篇各個地方出現(xiàn)的短語“一個實(shí)施例”或“實(shí)施例”并不一定均指同一個實(shí)施例。
雖然上述示例用于說明本發(fā)明在一個或多個應(yīng)用中的原理,但對于本領(lǐng)域的技術(shù)人員來說,在不背離本發(fā)明的原理和思想的情況下,明顯可以在形式上、用法及實(shí)施的細(xì)節(jié)上作各種修改而不用付出創(chuàng)造性勞動。因此,本發(fā)明由所附的權(quán)利要求書來限定。
- 還沒有人留言評論。精彩留言會獲得點(diǎn)贊!
- 視頻處理方法、裝置和系統(tǒng)及數(shù)據(jù)處理方法和裝置與流程
- 一種基于AutoCAD圖庫聯(lián)動及數(shù)據(jù)集成式地下管線數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- 一種查找價(jià)值用戶的數(shù)據(jù)處理方法和系統(tǒng)與流程
- 數(shù)據(jù)處理系統(tǒng)及其操作方法與流程
- 一種多通道圓偏振熒光光譜儀的制造方法與工藝
- 圖像數(shù)據(jù)處理系統(tǒng)、紋理貼圖壓縮和產(chǎn)生全景視頻的方法與流程
- 一種電子數(shù)據(jù)處理方法及裝置與流程
- 基于電網(wǎng)狀態(tài)監(jiān)測系統(tǒng)的數(shù)據(jù)處理分析方法和系統(tǒng)與流程
- 一種流數(shù)據(jù)的實(shí)時(shí)分析處理方法及系統(tǒng)與流程
- 網(wǎng)站數(shù)據(jù)處理方法、裝置及系統(tǒng)與流程
- 視頻數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- 終端的數(shù)據(jù)處理方法、裝置和系統(tǒng)與流程
- 數(shù)據(jù)處理方法、裝置、系統(tǒng)和存儲介質(zhì)與流程
- 數(shù)據(jù)處理方法、裝置以及系統(tǒng)與流程
- 元件數(shù)據(jù)處理裝置、元件數(shù)據(jù)處理方法及元件安裝系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置以及網(wǎng)絡(luò)系統(tǒng)與制造工藝
- 一種圖像數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- LTE系統(tǒng)中的數(shù)據(jù)處理裝置的制造方法
- 數(shù)據(jù)處理系統(tǒng)及方法與制造工藝
- 數(shù)據(jù)交互處理方法及裝置與流程
- 一種數(shù)據(jù)交互處理方法及裝置與流程
- 數(shù)據(jù)交互處理方法及裝置與流程
- 實(shí)現(xiàn)數(shù)據(jù)處理的交互方法及裝置與流程
- 一種用戶交互數(shù)據(jù)的處理方法、裝置及系統(tǒng)與流程
- 交互數(shù)據(jù)的處理方法及裝置與流程
- 一種產(chǎn)品與數(shù)據(jù)處理的交互方法與流程
- 非聯(lián)網(wǎng)數(shù)據(jù)處理裝置、非聯(lián)網(wǎng)數(shù)據(jù)交互系統(tǒng)的制作方法
- 一種用于智能機(jī)器人的交互數(shù)據(jù)處理方法與流程
- 與離線玩家交互的數(shù)據(jù)處理方法、裝置及服務(wù)器與流程
- 一種輪胎的數(shù)據(jù)處理的終端的制造方法與工藝
- 數(shù)據(jù)處理方法、裝置、系統(tǒng)和存儲介質(zhì)與流程
- 數(shù)據(jù)處理方法、裝置以及系統(tǒng)與流程
- 元件數(shù)據(jù)處理裝置、元件數(shù)據(jù)處理方法及元件安裝系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置以及網(wǎng)絡(luò)系統(tǒng)與制造工藝
- LTE系統(tǒng)中的數(shù)據(jù)處理裝置的制造方法
- 一種數(shù)據(jù)處理方法、系統(tǒng)、服務(wù)器和客戶端與制造工藝
- 一種數(shù)據(jù)處理方法及系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- 終端的數(shù)據(jù)處理方法、裝置和系統(tǒng)與流程
- 數(shù)據(jù)處理方法、裝置、系統(tǒng)和存儲介質(zhì)與流程
- 數(shù)據(jù)處理方法、裝置以及系統(tǒng)與流程
- 元件數(shù)據(jù)處理裝置、元件數(shù)據(jù)處理方法及元件安裝系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- LTE系統(tǒng)中的數(shù)據(jù)處理裝置的制造方法
- 一種數(shù)據(jù)處理方法、系統(tǒng)、服務(wù)器和客戶端與制造工藝
- 一種數(shù)據(jù)處理方法及系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- 一種導(dǎo)航數(shù)據(jù)處理方法及其系統(tǒng)與制造工藝
- 視頻數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- 終端的數(shù)據(jù)處理方法、裝置和系統(tǒng)與流程
- 數(shù)據(jù)處理方法、裝置、系統(tǒng)和存儲介質(zhì)與流程
- 數(shù)據(jù)處理方法、裝置以及系統(tǒng)與流程
- 元件數(shù)據(jù)處理裝置、元件數(shù)據(jù)處理方法及元件安裝系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- 一種圖像數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- LTE系統(tǒng)中的數(shù)據(jù)處理裝置的制造方法
- 數(shù)據(jù)處理系統(tǒng)及方法與制造工藝
- 一種數(shù)據(jù)處理方法、系統(tǒng)、服務(wù)器和客戶端與制造工藝
- 一種圖像數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- 數(shù)據(jù)處理系統(tǒng)及方法與制造工藝
- 一種數(shù)據(jù)處理方法、系統(tǒng)、服務(wù)器和客戶端與制造工藝
- 數(shù)據(jù)處理方法及數(shù)據(jù)處理系統(tǒng)與制造工藝
- 數(shù)據(jù)查詢服務(wù)器的數(shù)據(jù)處理方法及裝置、數(shù)據(jù)處理系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法及系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- 一種導(dǎo)航數(shù)據(jù)處理方法及其系統(tǒng)與制造工藝
- 數(shù)據(jù)處理方法及裝置、分類器訓(xùn)練方法及系統(tǒng)與制造工藝
- 分體式視頻采集顯示系統(tǒng)的數(shù)據(jù)處理及無線視頻發(fā)射模塊的制造方法與工藝
- 數(shù)據(jù)查詢服務(wù)器的數(shù)據(jù)處理方法及裝置、數(shù)據(jù)處理系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理方法、裝置及系統(tǒng)與制造工藝
- 一種導(dǎo)航數(shù)據(jù)處理方法及其系統(tǒng)與制造工藝
- 數(shù)據(jù)處理方法及裝置、分類器訓(xùn)練方法及系統(tǒng)與制造工藝
- 分體式視頻采集顯示系統(tǒng)的數(shù)據(jù)處理及無線視頻發(fā)射模塊的制造方法與工藝
- 一種在線售票系統(tǒng)中的數(shù)據(jù)處理方法和在線售票系統(tǒng)與制造工藝
- 一種數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- 終端跌落數(shù)據(jù)處理系統(tǒng)的制造方法與工藝
- 一種游戲角色行為數(shù)據(jù)處理方法及系統(tǒng)與制造工藝
- 適配器及數(shù)據(jù)處理系統(tǒng)的制作方法