一種音頻數(shù)據(jù)的自動增益控制方法與裝置與流程
本發(fā)明涉及音頻信號處理技術(shù),尤其涉及一種音頻數(shù)據(jù)的自動增益控制方法及裝置。
背景技術(shù):
在語音信號處理過程中,不同音頻信號的音量強度往往是不一樣的,且伴隨有噪聲,但作為用戶,期望與每個人之間的通話都是相同的音量強度而不通過音量鍵的控制來實現(xiàn),提升用戶體驗。現(xiàn)有的自動增益控制方法通過分析出音頻信號中的語音部分和噪聲部分,分別對這兩部分進(jìn)行增益控制。
現(xiàn)有的自動增益控制方法都是通過時域分析來區(qū)分語音與噪聲,這種區(qū)分方法的局限性較大,無法有效地區(qū)分語音和噪聲的特征,往往會把語音識別為噪聲,或者將噪聲識別為語音,造成錯誤地對音頻信號進(jìn)行增益控制。例如,在人工耳蝸/助聽器設(shè)備中,若錯誤地將噪聲進(jìn)行放大,對使用者的體驗是非常差的,甚至?xí)斐墒褂谜邍?yán)重的不舒適感。
技術(shù)實現(xiàn)要素:
針對上述問題,本發(fā)明的目的在于提供一種音頻數(shù)據(jù)的自動增益控制方法與裝置,能夠精確有效地區(qū)分音頻數(shù)據(jù)中的語音部分和噪聲部分,并分別對其進(jìn)行增益控制,極大地提高了用戶的舒適度。
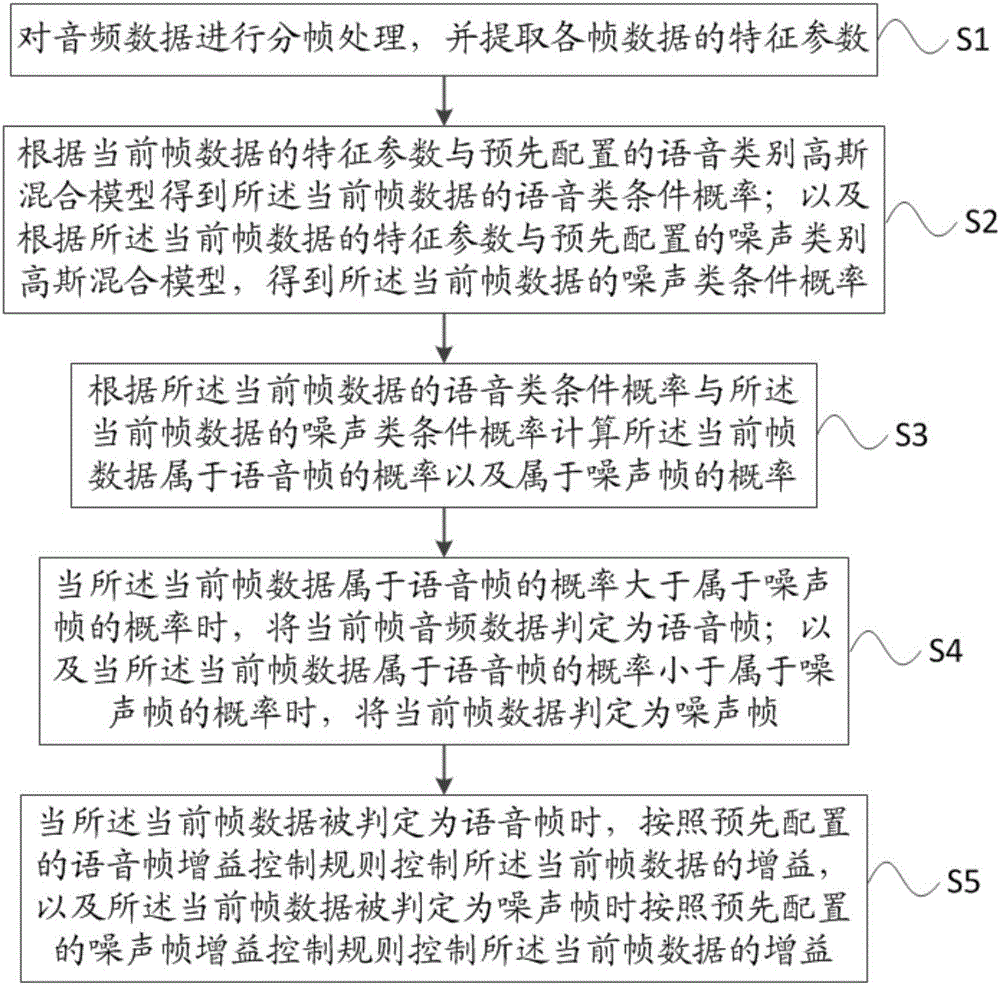
為了實現(xiàn)上述目的,本發(fā)明一方面提供了一種音頻數(shù)據(jù)的自動增益控制方法,包括:
對音頻數(shù)據(jù)進(jìn)行分幀處理,并提取各幀數(shù)據(jù)的特征參數(shù);
根據(jù)當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的語音類別高斯混合模型得到所述當(dāng)前幀數(shù)據(jù)的語音類條件概率;以及根據(jù)所述當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的噪聲類別高斯混合模型,得到所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率;
根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率;
當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率大于屬于噪聲幀的概率時,將當(dāng)前幀音頻數(shù)據(jù)判定為語音幀;以及當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率小于屬于噪聲幀的概率時,將當(dāng)前幀數(shù)據(jù)判定為噪聲幀;
當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益。
優(yōu)選地,所述音頻數(shù)據(jù)的自動增益控制方法還包括構(gòu)建語音類別高斯混合模型的步驟以及構(gòu)建噪聲類別高斯混合模型的步驟;
所述構(gòu)建語音類別高斯混合模型的步驟具體包括:
通過與所述音頻數(shù)據(jù)相同的處理方法,對語音樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
根據(jù)K-means算法將所述語音樣本數(shù)據(jù)的特征參數(shù)劃分為若干個語音類別;
獲取每個語音類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
通過EM算法對每個語音類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到語音類別高斯混合模型;
所述構(gòu)建噪聲類別高斯混合模型的步驟具體包括:
通過與所述音頻數(shù)據(jù)相同的處理方法,對噪聲樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
根據(jù)K-means算法將所述噪聲樣本數(shù)據(jù)的特征參數(shù)劃分為若干個噪聲類別;
獲取每個噪聲類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
通過EM算法對每個噪聲類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到噪聲類別高斯混合模型。
優(yōu)選地,所述根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率,包括:
根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率p(xT/Y1)與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率p(xT/Y2)結(jié)合貝葉斯公式,計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的后驗概率p’(Y1/xT)以及屬于噪聲幀的后驗概率p’(Y2/xT);
根據(jù)p(Y1/xT)=α1·p(Y1/xT-W+1)+…αW-1·p(Y1/xT-1)+αW·p'(Y1/xT)計算p(Y1/xT);
根據(jù)p(Y2/xT)=α1·p(Y2/xT-W+1)+…αW-1·p(Y2/xT-1)+αW·p'(Y2/xT)計算p(Y2/xT);
其中,
T是所述當(dāng)前幀數(shù)據(jù)在所述音頻數(shù)據(jù)中的幀序號;XT為所述當(dāng)前幀數(shù)據(jù)的特征參數(shù);T-W+1是所述當(dāng)前幀數(shù)據(jù)的前W幀的幀序號;W與σ為預(yù)設(shè)值。
優(yōu)選地,對所述音頻數(shù)據(jù)進(jìn)行分幀處理后得到的任意相鄰的兩幀數(shù)據(jù)具有重疊的部分。
優(yōu)選地,所述當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,包括:
當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,獲取所述當(dāng)前幀數(shù)據(jù)的時域能量并計算預(yù)設(shè)的期望能量值與所述時域能量的比值,將所述當(dāng)前幀數(shù)據(jù)的各數(shù)據(jù)點乘以所述比值以放大或縮小所述當(dāng)前幀數(shù)據(jù);
當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時,保持所述當(dāng)前幀數(shù)據(jù)不變。
本發(fā)明實施例另一方面還提供一種音頻數(shù)據(jù)的自動增益控制裝置,包括:
預(yù)處理模塊,用于對音頻數(shù)據(jù)進(jìn)行分幀處理,并提取各幀數(shù)據(jù)的特征參數(shù);
第一概率獲取模塊,用于根據(jù)當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的語音類別高斯混合模型得到所述當(dāng)前幀數(shù)據(jù)的語音類條件概率;以及根據(jù)所述當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的噪聲類別高斯混合模型,得到所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率;
第二概率獲取模塊,用于根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率;
判定模塊,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率大于屬于噪聲幀的概率時,將當(dāng)前幀音頻數(shù)據(jù)判定為語音幀;以及當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率小于屬于噪聲幀的概率時,將當(dāng)前幀數(shù)據(jù)判定為噪聲幀;
增益控制模塊,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益。
優(yōu)選地,所述音頻數(shù)據(jù)的自動增益控制裝置還包括第一模型構(gòu)建模塊以及第二模型構(gòu)建模塊;
所述第一模型構(gòu)建模塊包括:
第一預(yù)處理單元,用于通過與所述音頻數(shù)據(jù)相同的處理方法,對語音樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
第一分類單元,用于根據(jù)K-means算法將所述語音樣本數(shù)據(jù)的特征參數(shù)劃分為若干個語音類別;
第一初始參數(shù)獲取單元,用于獲取每個語音類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
第一模型優(yōu)化單元,用于通過EM算法對每個語音類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到語音類別高斯混合模型;
所述第二模型構(gòu)建模塊包括:
第二預(yù)處理單元,用于通過與所述音頻數(shù)據(jù)相同的處理方法,對噪聲樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
第二分類單元,用于根據(jù)K-means算法將所述噪聲樣本數(shù)據(jù)的特征參數(shù)劃分為若干個噪聲類別;
第二初始參數(shù)獲取單元,用于獲取每個噪聲類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
第二模型優(yōu)化單元,用于通過EM算法對每個噪聲類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到噪聲類別高斯混合模型。
優(yōu)選地,所述第二概率獲取模塊包括:
后驗概率獲取單元,用于根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率p(xT/Y1)與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率p(xT/Y2)結(jié)合貝葉斯公式,計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的后驗概率p’(Y1/xT)以及屬于噪聲幀的后驗概率p’(Y2/xT);
概率加權(quán)平滑單元,用于
根據(jù)p(Y1/xT)=α1·p(Y1/xT-W+1)+…αW-1·p(Y1/xT-1)+αW·p'(Y1/xT)計算p(Y1/xT);以及用于
根據(jù)p(Y2/xT)=α1·p(Y2/xT-W+1)+…αW-1·p(Y2/xT-1)+αW·p'(Y2/xT)計算p(Y2/xT);
其中,
T是所述當(dāng)前幀數(shù)據(jù)在所述音頻數(shù)據(jù)中的幀序號;XT為所述當(dāng)前幀數(shù)據(jù)的特征參數(shù);T-W+1是所述當(dāng)前幀數(shù)據(jù)的前W幀的幀序號;W與σ為預(yù)設(shè)值。
優(yōu)選地,對所述音頻數(shù)據(jù)進(jìn)行分幀處理后得到的任意相鄰的兩幀數(shù)據(jù)具有重疊的部分。
優(yōu)選地,所述增益控制模塊包括:
第一增益控制單元,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,獲取所述當(dāng)前幀數(shù)據(jù)的時域能量并計算預(yù)設(shè)的期望能量值與所述時域能量的比值,將所述當(dāng)前幀數(shù)據(jù)的各數(shù)據(jù)點乘以所述比值以放大或縮小所述當(dāng)前幀數(shù)據(jù);
第二增益控制單元,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時,保持所述當(dāng)前幀數(shù)據(jù)不變。
相對于現(xiàn)有技術(shù),本發(fā)明實施例的有益效果在于:本發(fā)明實施例提供了一種音頻數(shù)據(jù)自動增益控制方法與裝置,其中方法包括:對音頻數(shù)據(jù)進(jìn)行分幀處理,并提取各幀數(shù)據(jù)的特征參數(shù);根據(jù)當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的語音類別高斯混合模型得到所述當(dāng)前幀數(shù)據(jù)的語音類條件概率;以及根據(jù)所述當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的噪聲類別高斯混合模型,得到所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率;根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率;當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率大于屬于噪聲幀的概率時,將當(dāng)前幀音頻數(shù)據(jù)判定為語音幀;以及當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率小于屬于噪聲幀的概率時,將當(dāng)前幀數(shù)據(jù)判定為噪聲幀;當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益。在語音實時通信中,由于使用環(huán)境的多樣性,噪聲是隨著環(huán)境的變化而變換的,本發(fā)明實施例通過引入高斯混合模型,非常準(zhǔn)確地判斷出當(dāng)前幀是語音段還是噪聲段,并且分別對語音段和噪聲端進(jìn)行增益控制,實現(xiàn)自動增益控制,避免錯誤地將噪聲進(jìn)行放大。本發(fā)明技術(shù)方案極大地提高了語音與噪聲的識別水平,并依此進(jìn)行自動增益控制,有效改善了使用者的體驗。
附圖說明
為了更清楚地說明本發(fā)明的技術(shù)方案,下面將對實施方式中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發(fā)明的一些實施方式,對于本領(lǐng)域普通技術(shù)人員來講,在不付出創(chuàng)造性勞動的前提下,還可以根據(jù)這些附圖獲得其他的附圖。
圖1是本發(fā)明實施例提供的一種音頻數(shù)據(jù)的自動增益控制方法的流程示意圖;
圖2是本發(fā)明實施例提供的一種音頻數(shù)據(jù)的自動增益控制裝置的結(jié)構(gòu)框圖。
具體實施方式
下面將結(jié)合本發(fā)明實施例中的附圖,對本發(fā)明實施例中的技術(shù)方案進(jìn)行清楚、完整地描述,顯然,所描述的實施例僅僅是本發(fā)明一部分實施例,而不是全部的實施例。基于本發(fā)明中的實施例,本領(lǐng)域普通技術(shù)人員在沒有做出創(chuàng)造性勞動前提下所獲得的所有其他實施例,都屬于本發(fā)明保護的范圍。
請參閱圖1,其是本發(fā)明實施例提供的一種音頻數(shù)據(jù)的自動增益控制方法的流程示意圖,包括:
S1,對音頻數(shù)據(jù)進(jìn)行分幀處理,并提取各幀數(shù)據(jù)的特征參數(shù);
優(yōu)選地,對所述音頻數(shù)據(jù)進(jìn)行分幀處理后得到的任意相鄰的兩幀數(shù)據(jù)具有重疊的部分。分幀雖然可以采用連續(xù)分段的方法,但采用交疊分段的方法可以使幀與幀之間平滑過渡,保持其連續(xù)性。前一幀和后一幀的交疊部分稱為幀移,幀移與幀長的比值優(yōu)選為0~1/2。
提取特征參數(shù)的方法可以采用MFCC(Mel頻率倒譜系數(shù))算法、LPC(線性預(yù)測分析)算法、LPL(線性預(yù)測分析)算法等。
S2,根據(jù)當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的語音類別高斯混合模型得到所述當(dāng)前幀數(shù)據(jù)的語音類條件概率;以及根據(jù)所述當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的噪聲類別高斯混合模型,得到所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率;
S3,根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率;
S4,當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率大于屬于噪聲幀的概率時,將當(dāng)前幀音頻數(shù)據(jù)判定為語音幀;以及當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率小于屬于噪聲幀的概率時,將當(dāng)前幀數(shù)據(jù)判定為噪聲幀;
需要說明的是,當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率與屬于噪聲幀的概率相等時,可以根據(jù)預(yù)先設(shè)定將當(dāng)前幀數(shù)據(jù)判定為語音幀或者噪聲幀,這一點本領(lǐng)域技術(shù)人員應(yīng)當(dāng)能夠理解。
S5,當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益。
在語音實時通信中,由于使用環(huán)境的多樣性,噪聲是隨著環(huán)境的變化而變換的,本發(fā)明實施例通過引入高斯混合模型,非常準(zhǔn)確地判斷出當(dāng)前幀是語音段還是噪聲段,并且分別對語音段和噪聲端進(jìn)行增益控制,實現(xiàn)自動增益控制,避免錯誤地將噪聲進(jìn)行放大。本發(fā)明技術(shù)方案極大地提高了語音與噪聲的識別水平,并依此進(jìn)行自動增益控制,有效改善了使用者的體驗。
優(yōu)選地,所述音頻數(shù)據(jù)的自動增益控制方法還包括構(gòu)建語音類別高斯混合模型的步驟以及構(gòu)建噪聲類別高斯混合模型的步驟;
所述構(gòu)建語音類別高斯混合模型的步驟具體包括:
通過與所述音頻數(shù)據(jù)相同的處理方法,對語音樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
根據(jù)K-means算法將所述語音樣本數(shù)據(jù)的特征參數(shù)劃分為若干個語音類別;
獲取每個語音類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
通過EM算法(期望最大值算法)對每個語音類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到語音類別高斯混合模型;
所述構(gòu)建噪聲類別高斯混合模型的步驟具體包括:
通過與所述音頻數(shù)據(jù)相同的處理方法,對噪聲樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
根據(jù)K-means算法將所述噪聲樣本數(shù)據(jù)的特征參數(shù)劃分為若干個噪聲類別;
獲取每個噪聲類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
通過EM算法對每個噪聲類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到噪聲類別高斯混合模型。
通過以上的步驟可以構(gòu)建出語音類別高斯混合模型與噪聲類別高斯混合模型。由于構(gòu)建出語音類別高斯混合模型與噪聲類別高斯混合模型的步驟是基本一致的,因此以下以構(gòu)建出語音類別高斯混合模型為例進(jìn)行具體說明。
1、假設(shè)將所述語音樣本數(shù)據(jù)分割為m幀數(shù)據(jù),根據(jù)K-means算法將所述語音樣本數(shù)據(jù)的特征參數(shù)劃分為K個語音類別,即語音類別高斯混合模型由K個高斯子模型構(gòu)成。
2、對于第k個高斯子模型,可以得到其初始均值和初始協(xié)方差并且設(shè)定任意一個高斯子模型的初始權(quán)重
3、對第k個高斯子模型的均值μk、協(xié)方差Σk、權(quán)重ωk進(jìn)行迭代優(yōu)化:
其中,t為迭代次數(shù),t大于或等于0;為標(biāo)準(zhǔn)高斯函數(shù);xi表示第i幀語音樣本數(shù)據(jù)的特征參數(shù)。
4、假設(shè)在t=t1時EM算法穩(wěn)定了,則可以將賦給ωk,將賦給μk,將賦給Ck,從而得到語音類別高斯混合模型:
將當(dāng)前幀數(shù)據(jù)的特征參數(shù)xT代入語音類別高斯混合模型p(x/Y1)可以得到當(dāng)前幀數(shù)據(jù)的語音類條件概率p(xT/Y1)。
同理,可以得到噪聲類別高斯混合模型p(x/Y2);將當(dāng)前幀數(shù)據(jù)的特征參數(shù)xT代入噪聲類別高斯混合模型p(x/Y2)可以得到當(dāng)前幀數(shù)據(jù)的噪聲類條件概率p(xT/Y2)。需要說明的是,噪聲類別高斯混合模型與語音類別高斯混合模型在形式上是相同的,都是屬于高斯混合模型,但具體各自包含的高斯子模型的個數(shù)以及具體的參數(shù)都可能不同,這一點本領(lǐng)域技術(shù)人員應(yīng)當(dāng)能夠理解。
作為對本發(fā)明實施例的進(jìn)一步改進(jìn),在步驟S3中,所述根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率,包括:
S31,根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率p(xT/Y1)與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率p(xT/Y2)結(jié)合貝葉斯公式,計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的后驗概率p’(Y1/xT)以及屬于噪聲幀的后驗概率p’(Y2/xT);
具體地,根據(jù)貝葉斯公式,所述當(dāng)前幀數(shù)據(jù)屬于語音幀的后驗概率為
所述當(dāng)前幀數(shù)據(jù)屬于噪聲幀的后驗概率為
p(Y1)為語音類別的先驗概率,p(Y2)為噪聲類別的先驗概率。因為實際應(yīng)用場景中,噪聲和語音的出現(xiàn)概率是無法估計的,故可以設(shè)置p(Y1)=p(Y2)為相等,因而p’(Y1/xT)和p’(Y2/xT)變換為:
S32,根據(jù)p(Y1/xT)=α1·p(Y1/xT-W+1)+…αW-1·p(Y1/xT-1)+αW·p'(Y1/xT)計算p(Y1/xT);以及,
根據(jù)p(Y2/xT)=α1·p(Y2/xT-W+1)+…αW-1·p(Y2/xT-1)+αW·p'(Y2/xT)計算p(Y2/xT);
其中,
T是所述當(dāng)前幀數(shù)據(jù)在所述音頻數(shù)據(jù)中的幀序號;xT為所述當(dāng)前幀數(shù)據(jù)的特征參數(shù);T-W+1是所述當(dāng)前幀數(shù)據(jù)的前W幀的幀序號;W與σ為預(yù)設(shè)值。
p(Y1/xT)為p’(Y1/xT)經(jīng)過加權(quán)平滑后得到的概率;同理,p(Y2/xT)為p’(Y1/xT)經(jīng)過加權(quán)平滑后得到的概率。W代表加權(quán)平滑的窗口寬度。
α1~αw為加權(quán)系數(shù)。從αj的表達(dá)式可知,α1~αw服從高斯分布且α1+...+αw-1+αw=1。在α1~αw中,αw為最大值。即當(dāng)前幀數(shù)據(jù)的后驗概率的加權(quán)系數(shù)最大。
原則上根據(jù)p’(Y1/xT)和p’(Y2/xT)的大小可以判定所述當(dāng)前幀數(shù)據(jù)屬于語音幀還是噪聲幀,但語音或噪聲通常都是連續(xù)的多幀,加權(quán)平滑可以使識別結(jié)果過渡更平穩(wěn),防止一些異常突變結(jié)果。
優(yōu)選地,在步驟S5中,所述當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,包括:
當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,獲取所述當(dāng)前幀數(shù)據(jù)的時域能量并計算預(yù)設(shè)的期望能量值與所述時域能量的比值,將所述當(dāng)前幀數(shù)據(jù)的各數(shù)據(jù)點乘以所述比值以放大或縮小所述當(dāng)前幀數(shù)據(jù);
當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時,保持所述當(dāng)前幀數(shù)據(jù)不變。
當(dāng)所述比值大于1時,代表所述時域能量達(dá)不到所述期望能量值,需要對當(dāng)前幀數(shù)據(jù)進(jìn)行放大;當(dāng)所述比值小于1時,代表所述時域能量超過所述期望能量值,需要進(jìn)行縮小。
通過步驟S5可以根據(jù)語音幀的時域能量對語音幀進(jìn)行放大或者縮小,達(dá)到自動增益控制效果,同時噪聲幀則保持不變,避免錯誤地對噪聲幀進(jìn)行放大。
需要說明的是,以上只是語音幀增益控制規(guī)則與噪聲幀增益控制規(guī)則的其中一種實施方式,目的是實現(xiàn)自動對語音幀進(jìn)行增益放大或縮小,同時避免對噪聲幀進(jìn)行了放大操作,其他實施的方式例如將噪聲幀的增益進(jìn)行壓縮也是可選的。
為了執(zhí)行上述的音頻數(shù)據(jù)的自動增益控制方法,本發(fā)明實施例還提供了一種音頻數(shù)據(jù)的自動增益控制裝置。如圖2所示,其是本發(fā)明實施例提供的一種音頻數(shù)據(jù)的自動增益控制裝置的結(jié)構(gòu)框圖。所述音頻數(shù)據(jù)的自動增益控制裝置,包括:
預(yù)處理模塊1,用于對音頻數(shù)據(jù)進(jìn)行分幀處理,并提取各幀數(shù)據(jù)的特征參數(shù);
第一概率獲取模塊2,用于根據(jù)當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的語音類別高斯混合模型得到所述當(dāng)前幀數(shù)據(jù)的語音類條件概率;以及根據(jù)所述當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的噪聲類別高斯混合模型,得到所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率;
第二概率獲取模塊3,用于根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率;
判定模塊4,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率大于屬于噪聲幀的概率時,將當(dāng)前幀音頻數(shù)據(jù)判定為語音幀;以及當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率小于屬于噪聲幀的概率時,將當(dāng)前幀數(shù)據(jù)判定為噪聲幀;
增益控制模塊5,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益。
優(yōu)選地,所述音頻數(shù)據(jù)的自動增益控制裝置還包括第一模型構(gòu)建模塊以及第二模型構(gòu)建模塊;
所述第一模型構(gòu)建模塊包括:
第一預(yù)處理單元,用于通過與所述音頻數(shù)據(jù)相同的處理方法,對語音樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
第一分類單元,用于根據(jù)K-means算法將所述語音樣本數(shù)據(jù)的特征參數(shù)劃分為若干個語音類別;
第一初始參數(shù)獲取單元,用于獲取每個語音類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
第一模型優(yōu)化單元,用于通過EM算法對每個語音類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到語音類別高斯混合模型;
所述第二模型構(gòu)建模塊包括:
第二預(yù)處理單元,用于通過與所述音頻數(shù)據(jù)相同的處理方法,對噪聲樣本數(shù)據(jù)進(jìn)行分幀處理并提取各幀數(shù)據(jù)的特征參數(shù);
第二分類單元,用于根據(jù)K-means算法將所述噪聲樣本數(shù)據(jù)的特征參數(shù)劃分為若干個噪聲類別;
第二初始參數(shù)獲取單元,用于獲取每個噪聲類別所對應(yīng)的高斯子模型的初始權(quán)重、初始均值以及初始協(xié)方差;
第二模型優(yōu)化單元,用于通過EM算法對每個噪聲類別所對應(yīng)的高斯子模型的權(quán)重、均值以及協(xié)方差進(jìn)行迭代優(yōu)化,得到噪聲類別高斯混合模型。
優(yōu)選地,所述第二概率獲取模塊3包括:
后驗概率獲取單元,用于根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率p(xT/Y1)與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率p(xT/Y2)結(jié)合貝葉斯公式,計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的后驗概率p’(Y1/xT)以及屬于噪聲幀的后驗概率p’(Y2/xT);
概率加權(quán)平滑單元,用于
根據(jù)p(Y1/xT)=α1·p(Y1/xT-W+1)+…αW-1·p(Y1/xT-1)+αW·p'(Y1/xT)計算p(Y1/xT);以及用于
根據(jù)p(Y2/xT)=α1·p(Y2/xT-W+1)+…αW-1·p(Y2/xT-1)+αW·p'(Y2/xT)計算p(Y2/xT);
其中,
T是所述當(dāng)前幀數(shù)據(jù)在所述音頻數(shù)據(jù)中的幀序號;XT為所述當(dāng)前幀數(shù)據(jù)的特征參數(shù);T-W+1是所述當(dāng)前幀數(shù)據(jù)的前W幀的幀序號;W與σ為預(yù)設(shè)值。
優(yōu)選地,對所述音頻數(shù)據(jù)進(jìn)行分幀處理后得到的任意相鄰的兩幀數(shù)據(jù)具有重疊的部分。
優(yōu)選地,所述增益控制模塊5包括:
第一增益控制單元,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,獲取所述當(dāng)前幀數(shù)據(jù)的時域能量并計算預(yù)設(shè)的期望能量值與所述時域能量的比值,將所述當(dāng)前幀數(shù)據(jù)的各數(shù)據(jù)點乘以所述比值以放大或縮小所述當(dāng)前幀數(shù)據(jù);
第二增益控制單元,用于當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時,保持所述當(dāng)前幀數(shù)據(jù)不變。
需要說明的是,本發(fā)明實施例提供的一種音頻數(shù)據(jù)的自動增益控制裝置用于執(zhí)行上述的音頻數(shù)據(jù)的自動增益控制方法,兩者的有益效果以及工作原理一一對應(yīng),因而不再贅述。
相對于現(xiàn)有技術(shù),本發(fā)明實施例的有益效果在于:本發(fā)明實施例提供了一種音頻數(shù)據(jù)自動增益控制方法與裝置,其中方法包括:對音頻數(shù)據(jù)進(jìn)行分幀處理,并提取各幀數(shù)據(jù)的特征參數(shù);根據(jù)當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的語音類別高斯混合模型得到所述當(dāng)前幀數(shù)據(jù)的語音類條件概率;以及根據(jù)所述當(dāng)前幀數(shù)據(jù)的特征參數(shù)與預(yù)先配置的噪聲類別高斯混合模型,得到所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率;根據(jù)所述當(dāng)前幀數(shù)據(jù)的語音類條件概率與所述當(dāng)前幀數(shù)據(jù)的噪聲類條件概率計算所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率以及屬于噪聲幀的概率;當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率大于屬于噪聲幀的概率時,將當(dāng)前幀音頻數(shù)據(jù)判定為語音幀;以及當(dāng)所述當(dāng)前幀數(shù)據(jù)屬于語音幀的概率小于屬于噪聲幀的概率時,將當(dāng)前幀數(shù)據(jù)判定為噪聲幀;當(dāng)所述當(dāng)前幀數(shù)據(jù)被判定為語音幀時,按照預(yù)先配置的語音幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益,以及所述當(dāng)前幀數(shù)據(jù)被判定為噪聲幀時按照預(yù)先配置的噪聲幀增益控制規(guī)則控制所述當(dāng)前幀數(shù)據(jù)的增益。在語音實時通信中,由于使用環(huán)境的多樣性,噪聲是隨著環(huán)境的變化而變換的,本發(fā)明實施例通過引入高斯混合模型,非常準(zhǔn)確地判斷出當(dāng)前幀是語音段還是噪聲段,并且分別對語音段和噪聲端進(jìn)行增益控制,實現(xiàn)自動增益控制,避免錯誤地將噪聲進(jìn)行放大。本發(fā)明技術(shù)方案極大地提高了語音與噪聲的識別水平,并依此進(jìn)行自動增益控制,有效改善了使用者的體驗。
以上所揭露的僅為本發(fā)明一種較佳實施例而已,當(dāng)然不能以此來限定本發(fā)明之權(quán)利范圍,本領(lǐng)域普通技術(shù)人員可以理解實現(xiàn)上述實施例的全部或部分流程,并依本發(fā)明權(quán)利要求所作的等同變化,仍屬于發(fā)明所涵蓋的范圍。
本領(lǐng)域普通技術(shù)人員可以理解實現(xiàn)上述實施例方法中的全部或部分流程,是可以通過計算機程序來指令相關(guān)的硬件來完成,所述的程序可存儲于一計算機可讀取存儲介質(zhì)中,該程序在執(zhí)行時,可包括如上述各方法的實施例的流程。其中,所述的存儲介質(zhì)可為磁碟、光盤、只讀存儲記憶體(Read-Only Memory,ROM)或隨機存儲記憶體(Random Access Memory,RAM)等。
- 還沒有人留言評論。精彩留言會獲得點贊!