基于高斯過程輸出后濾波的語音轉(zhuǎn)換方法與流程
本發(fā)明涉及語音轉(zhuǎn)換技術(shù),屬于語音識別與合成領(lǐng)域,特別是一種基于高斯過程輸出后濾波的語音轉(zhuǎn)換方法。
背景技術(shù):
語音轉(zhuǎn)換技術(shù)是語音信號處理領(lǐng)域近年來新興的研究分支,涵蓋了語音識別和語音合成等領(lǐng)域的內(nèi)容,擬在保持語義內(nèi)容不變的情況下,通過改變一個特定說話人(被稱為源說話人)的話音個性特征,使他(或她)說的話被聽者認為是另一個特定說話人(被稱為目標說話人)說的話。語音轉(zhuǎn)換的主要任務(wù)包括提取代表說話人個性的特征參數(shù)并進行數(shù)學(xué)變換,然后將變換后的參數(shù)重構(gòu)成語音。在這過程中,既要保持重構(gòu)語音的聽覺質(zhì)量,又要兼顧轉(zhuǎn)換后的個性特征是否準確。
經(jīng)過多年的發(fā)展,語音轉(zhuǎn)換領(lǐng)域已經(jīng)涌現(xiàn)出一些高效實用的算法,其中以高斯混合模型為代表的統(tǒng)計轉(zhuǎn)換方法目前已儼然成為了該領(lǐng)域公認的標準。但是這類算法亦存在某些弊端,例如:由于高斯混合模型自身模型參數(shù)的原因,使得轉(zhuǎn)換后的譜參數(shù)過于平滑,導(dǎo)致不能準確地得到目標預(yù)測參數(shù)值,從而不能達到準確的轉(zhuǎn)換效果。
針對上述問題,目前已存在一些應(yīng)對方案。例如,基于最大后驗概率的GMM轉(zhuǎn)換算法,考慮采用最大后驗概率自適應(yīng)地構(gòu)造轉(zhuǎn)換函數(shù),來解決轉(zhuǎn)換后譜參數(shù)過平滑的問題;基于最大似然估計的GMM轉(zhuǎn)換算法,考慮通過引入全局方差的概念解決過平滑問題。
技術(shù)實現(xiàn)要素:
本發(fā)明要解決的技術(shù)問題為:通過高斯過程對源與目標參數(shù)進行訓(xùn)練得到映射函數(shù)關(guān)系,再對高斯過程預(yù)測輸出值進一步聯(lián)合優(yōu)化,得到較為準確的目標預(yù)測輸出值,實現(xiàn)高質(zhì)量語音轉(zhuǎn)換。
本發(fā)明采取的技術(shù)方案具體為:基于高斯過程輸出后濾波的語音轉(zhuǎn)換方法,包括以下步驟:
(1)采用語音分析模型對原始語音進行分析,得到原始語音的參數(shù);
(2)從上述分析得到的參數(shù)中提取與音素相關(guān)的特征參數(shù)集合;
(3)對原始語音和目標語音的特征參數(shù)集合進行參數(shù)對齊操作;
(4)將對齊的特征參數(shù)集合利用高斯過程進行訓(xùn)練得到原始語音與目標語音的映射關(guān)系;
(5)輸入待轉(zhuǎn)換源語音的特征參數(shù),通過步驟(4)得到的映射關(guān)系得到目標語音的特征參數(shù)預(yù)測值;
(6)利用高斯過程對目標語音的特征參數(shù)預(yù)測值進行最大似然估計,并計算目標語音特征參數(shù)預(yù)測值的方差的高斯分布;
(7)對最大似然估計結(jié)果和方差的高斯分布結(jié)果進行聯(lián)合最優(yōu)化,得到最佳目標語音特征參數(shù)預(yù)測值,最后用語音合成模型合成目標語音。
本發(fā)明中,步驟(1)~(4)為訓(xùn)練階段,步驟(5)~(7)為轉(zhuǎn)換階段。高斯過程是一個隨機過程,可以完全由兩個統(tǒng)計參數(shù)確定,結(jié)構(gòu)簡單,通過高斯過程得到源與目標參數(shù)的映射關(guān)系,進而可實現(xiàn)語音轉(zhuǎn)換。基于高斯過程的進行語音轉(zhuǎn)換,一方面,高斯過程的非參數(shù)特性減少了模型參數(shù)的自由度,另一方面高斯過程具有較好的非線性映射能力,從而可以緩解過擬合的問題,避免轉(zhuǎn)換后的譜參數(shù)過于平滑。
具體的,本發(fā)明步驟(1)中,采用語音分析模型對原始語音進行的分析包括:
1.1對原始語音進行固定時長的分幀,用自相關(guān)法對其基音頻率進行估計;
1.2在濁音信號部分設(shè)置一個最大濁音頻率分量,用來劃分諧波成分和隨機成分的主能量區(qū)域;再利用最小二乘算法估計得到離散的諧波幅度值和相位值。
語音分析模型為現(xiàn)有技術(shù),其可將語音信號模擬為可用于轉(zhuǎn)換的特征參數(shù),本發(fā)明可采用諧波隨機模型,該模型將語音信號模擬為大量基頻諧波正弦信號和噪聲分量,對基頻諧波正弦信號作進一步分析,得到適用于轉(zhuǎn)換的語音信號特征參數(shù)。
自相關(guān)法為現(xiàn)有算法,是語音信號基音頻率提取算法中較為經(jīng)典且具有代表性的方法。
步驟(2)中,從步驟(1)中得到的參數(shù)包括原始語音的離散的諧波幅度值和相位值,從上述離散的諧波幅度值中提取與音素有關(guān),即適用于語音轉(zhuǎn)換任務(wù)的特征參數(shù)集合,包括步驟:
2.1對離散的諧波幅度值求取平方值;
2.2根據(jù)功率譜密度函數(shù)和自相關(guān)函數(shù)的一一對應(yīng)關(guān)系,得到關(guān)于線性預(yù)測系數(shù)的托普里茨矩陣方程,求解該矩陣方程得到線性預(yù)測系數(shù);
2.3將線性預(yù)測系數(shù)轉(zhuǎn)換為目標倒譜系數(shù),并求得原始語音的基音頻率;
2.4得到包含原始語音倒譜系數(shù)和基因頻率參數(shù)的特征參數(shù)集合。
步驟(3)中,對原始語音和目標語音的特征參數(shù)集合進行參數(shù)對齊操作的對其準則為:對于兩個不等長的特征參數(shù)序列,利用動態(tài)規(guī)劃的思想將其中一者的時間軸非線性的映射到另一者的時間軸上,從而實現(xiàn)一一對應(yīng)的匹配關(guān)系;在特征參數(shù)集合的對齊過程中,通過迭代優(yōu)化一個預(yù)設(shè)的累積失真函數(shù),并限制搜索區(qū)域,最終獲得時間規(guī)整函數(shù)。
搜索區(qū)域是根據(jù)第i幀源語音信號矢量和第j幀目標語音信號矢量之間的距離測度,規(guī)定的一個平行四邊形作為限制條件;時間規(guī)整函數(shù)是關(guān)于源與目標語音幀特征矢量之間距離測度最小的規(guī)整函數(shù),以保證語音之間存在最大的聲學(xué)相似特性。
步驟(4)中所述得到原始語音與目標語音特征參數(shù)映射關(guān)系的方法包括以下步驟:
4.4從步驟(2)得到的特征參數(shù)矩陣中提取原語音參數(shù)矩陣中的所有參數(shù)將其作為輸入,目標參數(shù)矩陣中的其中一維數(shù)值作為輸出,通過高斯過程訓(xùn)練兩者之間的映射關(guān)系;
源與目標的參數(shù)類型及數(shù)量皆相同,目標參數(shù)矩陣與源語音參數(shù)矩陣求解過程一致。各維參數(shù)是目標語音各幀特征參數(shù)中所有同一維組成的數(shù)據(jù)(即相同維不同幀所組成的數(shù)據(jù))。
4.2依次選擇目標參數(shù)矩陣中的其他各維數(shù)值作為輸出,得到原始語音參數(shù)矩陣中參數(shù)與目標語音參數(shù)矩陣中各維數(shù)值之間的映射關(guān)系。
步驟(5)中,對于待轉(zhuǎn)換源語音,處理過程包括步驟:
5.1對待轉(zhuǎn)換源語音依次按步驟(1)、(2)、(3)進行分析處理,得到待轉(zhuǎn)換源語音的特征參數(shù);
5.2利用步驟(4)得到的映射關(guān)系,將步驟5.1得到的待轉(zhuǎn)換源語音的特征參數(shù),映射為目標語音的特征參數(shù),即得到目標語音的特征參數(shù)預(yù)測值,進一步得到相應(yīng)的特征參數(shù)矩陣。
步驟(6)包括如下步驟:
6.1利用高斯過程對步驟5.2所得目標語音特征參數(shù)矩陣中的各維特征參數(shù)進行最大似然估計;
6.2計算步驟6.1所得的目標語音各維特征參數(shù)的方差,并求取其方差的高斯分布。
步驟(7)包括如下步驟:
7.1構(gòu)建步驟6.1所得最大似然估計值和步驟6.2所得方差的高斯分布的聯(lián)合函數(shù),并對該聯(lián)合函數(shù)進行最優(yōu)化,實現(xiàn)對高斯過程預(yù)測輸出的后濾波,得到最佳目標預(yù)測值,重構(gòu)目標語音的特征參數(shù)矩陣;
7.2基于上述重構(gòu)的特征參數(shù)矩陣和目標語音的基音頻率,利用語音合成模型轉(zhuǎn)換為目標語音。
有益效果:
本發(fā)明充分考慮了造成轉(zhuǎn)換后譜參數(shù)過于平滑問題的原因,結(jié)合高斯過程對轉(zhuǎn)換后的預(yù)測譜參數(shù)輸出值進行進一步聯(lián)合優(yōu)化,實現(xiàn)了高斯過程輸出的后濾波,可達到高質(zhì)量的語音轉(zhuǎn)換效果。
附圖說明
圖1所示為本發(fā)明使用高斯過程的映射關(guān)系示意圖;
圖2所示為本發(fā)明的訓(xùn)練階段流程示意圖;
圖3所示為本發(fā)明轉(zhuǎn)換階段流程示意圖。
具體實施方式
以下結(jié)合附圖和具體實施例進一步描述。
參考圖1,本發(fā)明基于高斯過程輸出后濾波的高質(zhì)量語音轉(zhuǎn)換方法,針對源和目標的平行數(shù)據(jù),利用高斯過程建立源與目標之間的映射關(guān)系,通過該映射關(guān)系得到目標預(yù)測輸出值,利用高斯過程對該輸出值進行最大似然估計,并建立輸出值的方差的高斯分布。對最大似然估計和方差的高斯分布進行聯(lián)合最優(yōu)化,得到目標參數(shù)值完成對高斯過程輸出的后濾波,實現(xiàn)高質(zhì)量的語音轉(zhuǎn)換效果;具體包括如下步驟:
(1)采用語音分析模型對原始語音進行分析,得到原始語音的參數(shù);
(2)從分析得到的參數(shù)中提取與音素相關(guān)的特征參數(shù)集合;
(3)對原始語音和目標語音的特征參數(shù)集合進行參數(shù)對齊操作;
(4)將對齊的特征參數(shù)集合利用高斯過程進行訓(xùn)練得到原始語音與目標語音的映射關(guān)系;
(5)輸入待轉(zhuǎn)換源語音的特征參數(shù),通過步驟(4)得到的映射關(guān)系得到目標語音的特征參數(shù)預(yù)測值;
(6)利用高斯過程對目標語音的特征參數(shù)預(yù)測值進行最大似然估計,并計算目標語音特征參數(shù)預(yù)測值的方差的高斯分布;
(7)對最大似然估計結(jié)果和方差的高斯分布結(jié)果進行聯(lián)合最優(yōu)化,得到最佳目標語音特征參數(shù)預(yù)測值,最后用語音合成模型合成目標語音。
上述步驟中,步驟(1)~(4)為訓(xùn)練步驟,步驟(5)~(7)為轉(zhuǎn)換步驟。高斯過程是一個隨機過程,可以完全由兩個統(tǒng)計參數(shù)確定,結(jié)構(gòu)簡單,通過高斯過程得到源與目標參數(shù)的映射關(guān)系,可以有效解決高斯混合模型造成的過擬合問題,另外對高斯過程預(yù)測輸出進行進一步聯(lián)合優(yōu)化可有效解決過平滑問題。
本發(fā)明的提出是針對高斯混合模型在語音轉(zhuǎn)換中存在的問題,有兩個關(guān)鍵點:一是通過高斯過程訓(xùn)練源參數(shù)與目標參數(shù)各維數(shù)之間的映射關(guān)系,二是對高斯過程輸出的目標預(yù)測值進行進一步分析,求其最大似然估計和方差的高斯分布,建立兩者之間的聯(lián)合函數(shù)并進行聯(lián)合最優(yōu)化,實現(xiàn)高斯過程輸出的后濾波,得到更為準確的預(yù)測輸出值,實現(xiàn)高質(zhì)量語音轉(zhuǎn)換。
再次參考圖1,其中N是用于訓(xùn)練的特征參數(shù)的幀數(shù),D為特征參數(shù)的維數(shù)。又設(shè)X,X’分別表示訓(xùn)練時的兩個不同輸入,X*表示轉(zhuǎn)換階段的輸入,y表示輸出,則高斯過程可以完全由均值和協(xié)方差兩個統(tǒng)計參數(shù)確定,即
y~GP(m(x),κ(X,X′)) (1)
其中為協(xié)方差函數(shù),m(x)為均值函數(shù),由于m(x)和κ(X,X′)中含有未知超參數(shù)σ和l,因此使用前需要對高斯過程進行訓(xùn)練,通過最大邊緣相似度得到超參數(shù)σ和l,高斯過程訓(xùn)練完成后即可通過訓(xùn)練數(shù)據(jù)和測試輸入進行預(yù)測得到測試輸出,假設(shè)高斯過程預(yù)測輸出值為y*,測試輸出y*的后驗概率分布為P(y*|X,y,X*),即:
得:
v[y*]=κ(X*,X*)-κ(X*,X)κ(X,X)-1κ(X,X*) (4)
其中,式(2)中的符號Ψ表示高斯分布函數(shù),式(3)中表示高斯分布均值,式(4)中v[y*]表示高斯分布方差。
本發(fā)明的創(chuàng)新之處在于:對高斯過程的預(yù)測輸出值進行后濾波,以解決預(yù)測輸出參數(shù)過平滑問題,具體為:
通過上式得到高斯分布的預(yù)測輸出值,計算其最大似然估計和方差的高斯分布,并進行聯(lián)合最優(yōu)化,得到目標參數(shù)值完成對高斯過程輸出的后濾波,實現(xiàn)高質(zhì)量的語音轉(zhuǎn)換效果;具體包括如下步驟:
高斯過程預(yù)測輸出值y*的最大似然估計函數(shù)為P(y*),預(yù)測輸出值y*的方差為v(y*),其高斯分布為P(v(y*)),其聯(lián)合對數(shù)似然函數(shù)為
其中w為測試幀數(shù),是常數(shù)。求得聯(lián)合對數(shù)似然函數(shù)的最大值
即得到目標預(yù)測值。
本發(fā)明進行語音轉(zhuǎn)換的具體流程為,
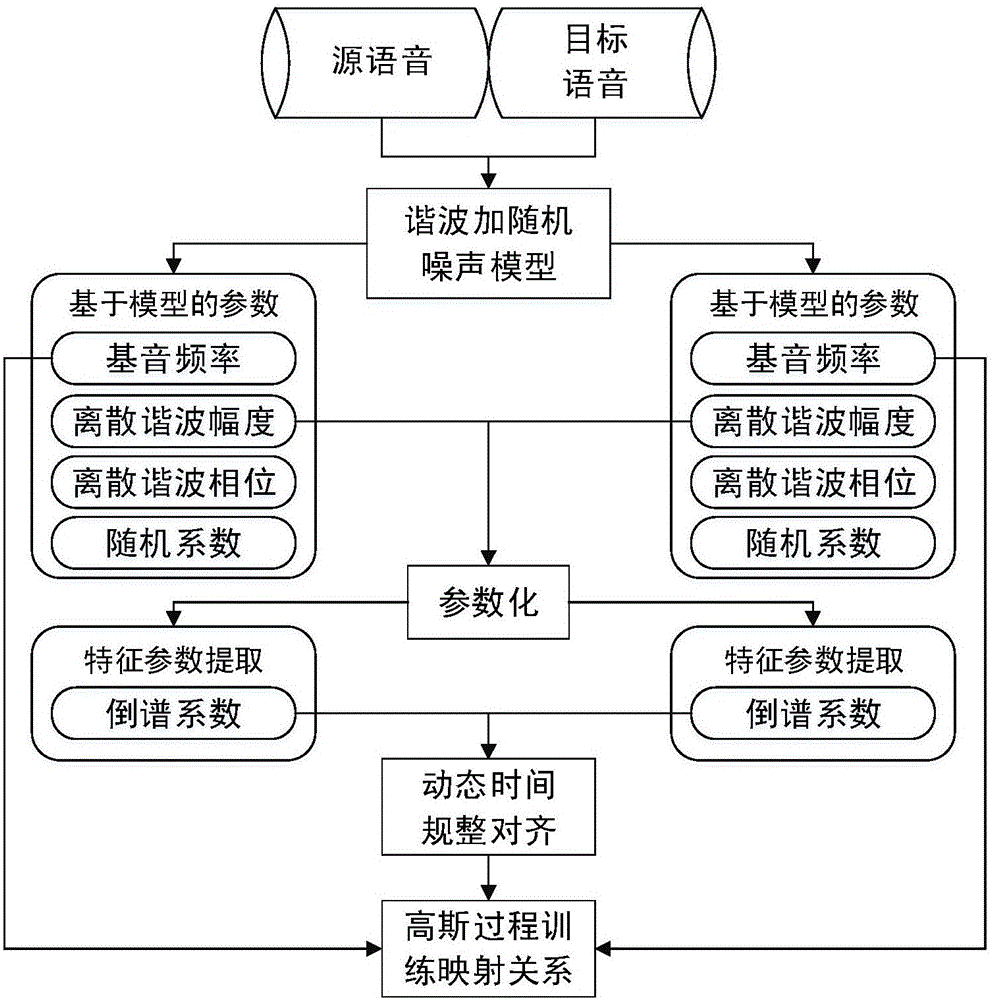
如圖2所示為訓(xùn)練階段流程:
①通過語音分析模型的分析,獲得訓(xùn)練階段源與目標特征參數(shù)序列;
②將源和目標的特征參數(shù)集合通過動態(tài)時間規(guī)整算法進行對齊,使得對齊后的參數(shù)集合符合平行數(shù)據(jù)的要求;
③利用高斯過程對源與目標的特征參數(shù)進行訓(xùn)練,得到兩者之間的映射關(guān)系;
如圖3為轉(zhuǎn)換階段流程:
①通過語音分析模型的分析,獲得轉(zhuǎn)換階段源特征參數(shù)序列;
②在給定特征參數(shù)序列以及訓(xùn)練得到的映射關(guān)系的基礎(chǔ)上,預(yù)測轉(zhuǎn)換語音的特征參數(shù);
③對得到的轉(zhuǎn)換語音特征參數(shù)利用公式(5)和(6)進行聯(lián)合優(yōu)化,進一步輸出準確預(yù)測值,并合成轉(zhuǎn)換語音。
實施例
在訓(xùn)練階段:
①源和目標人的語音通過諧波加隨機模型進行分解,得到基音頻率軌跡和諧波聲道譜參數(shù)的幅度值和相位值。具體細節(jié)描述如下:
a.對語音信號進行分幀,幀長30ms,幀重疊間隔15ms。
b.在每幀中,用自相關(guān)法估計基頻,若該幀為清音幀,則設(shè)置基頻等于零。
c.對于濁音幀(即基頻不為零的幀),假設(shè)其語音信號可以由一系列的正弦波疊加而成:
式中L為正弦波的個數(shù),n為一幀語音中包含的樣點數(shù),{Cl}為正弦波的復(fù)幅度。令sh表示sh(n)在一幀內(nèi)的樣點所組成的矢量,則(7)式可以改寫成:
其中,矩陣B由公式(7)中改寫而成,ω0為基音頻率,列數(shù)表示一幀內(nèi)一個采樣點所組成的矢量,行數(shù)表示一幀內(nèi)總采樣點數(shù),x表示語音信號疊加時的幅度值。C*L的上標“*”表示共軛的意思。
通過最小二乘算法可以確定以上的{Cl}:
其中s(n)是真實語音信號,w(n)是窗函數(shù),一般取漢明窗。ε表示誤差。將窗函數(shù)也改寫成矩陣形式W:
則最優(yōu)的x可以這樣得到:
式中,xopt表示語音信號疊加時幅度的最優(yōu)值,上標H表示共軛復(fù)轉(zhuǎn)置,由于(BHWHW)是一個托普里茨矩陣(Toeplitz Matrix),因此可以用萊文森-杜賓(Levinson-Dubin)快速算法對其進行求解,s為真實語音信號s(n)在一幀的范圍內(nèi)的樣點所組成的矢量。
d.得到了{Cl},則諧波幅度A和相位值如下:
②由于原始諧波加噪聲模型參數(shù)維數(shù)較高,不便于后續(xù)計算,因此必須對其進行降維。由于基頻軌跡是一維參數(shù),因此,降維的主要對象是聲道幅度譜參數(shù)和相位參數(shù)。同時,降維的目標是將聲道參數(shù)轉(zhuǎn)化為經(jīng)典的線性預(yù)測參數(shù),進而產(chǎn)生適用于語音轉(zhuǎn)換系統(tǒng)的倒譜系數(shù)。求解步驟如下:
a.分別求取離散的M個幅度值A(chǔ)m的平方,并將其認為是離散功率譜的采樣值P(ωm)。
b.根據(jù)帕斯卡定律,功率譜密度函數(shù)和自相關(guān)函數(shù)是一對傅立葉變換對,則采用自相關(guān)函數(shù)表示其關(guān)系即為:式(13)即為關(guān)于線性預(yù)測系數(shù)的托普里茨矩陣方程,我們可以通過求解以下矩陣方程得到對線性預(yù)測參數(shù)系數(shù)的初步估值:
其中a1,a2,…,ap是p階線性預(yù)測參數(shù)系數(shù),R0~RP分別表示為前p個整數(shù)離散點上的自相關(guān)函數(shù)值。
c.通過線性預(yù)測分析得到的合成濾波器的系統(tǒng)函數(shù)為H(z),其沖激相應(yīng)為h(n):
其中{ai}為線性預(yù)測系數(shù),p為線性預(yù)測系數(shù)(LPC)的階數(shù),z表示數(shù)學(xué)中z變換的自變量。
下面求h(n)的倒譜首先根據(jù)同態(tài)處理法得到:
因為H(z)是最小相位的,即在單位圓內(nèi)是解析的,所以可以展開成級數(shù)形式,即:
也就是說的逆變換是存在的,設(shè)將式(16)兩邊同時對z-1求導(dǎo):
得到:
令式(18)等號兩邊z的各次冪前系數(shù)分別相等,得到和ai之間的遞推關(guān)系:
按式(19)~(21)可直接從預(yù)測系數(shù){ai}求得倒譜系數(shù)
③通過步驟②得到的源和目標的倒譜系數(shù)參數(shù),用動態(tài)時間規(guī)整算法進行對齊。所謂的“對齊”是指:使得對應(yīng)的源和目標的倒譜系數(shù)在設(shè)定的失真準則上具有最小的失真距離。這樣做的目的是:使得源和目標的特征序列在參數(shù)的層面上關(guān)聯(lián),便于后續(xù)統(tǒng)計模型學(xué)習(xí)其中的映射規(guī)律。動態(tài)時間規(guī)整算法步驟簡要概述如下:
對于同一個語句的發(fā)音,假定源說話人的聲學(xué)個性特征參數(shù)序列為而目標說話人的特征參數(shù)序列為且Nx≠Ny。設(shè)定源說話人的特征參數(shù)序列為參考模板,則動態(tài)時間規(guī)整算法就是要尋找時間規(guī)整函數(shù)使得目標特征序列的時間軸ny非線性地映射到源特征參數(shù)序列的時間軸nx,從而使得總的累積失真量最小,在數(shù)學(xué)上累積失真函數(shù)可以表示為:
其中表示第ny幀的目標說話人特征參數(shù)和第幀源說話人特征參數(shù)之間的某種測度距離。
時間規(guī)整函數(shù)是關(guān)于源與目標語音幀特征矢量之間距離測度最小的規(guī)整函數(shù),以保證語音之間存在最大的聲學(xué)相似特性。在動態(tài)時間規(guī)整的規(guī)整過程中,規(guī)整函數(shù)是要滿足以下的約束條件的,有邊界條件和連續(xù)性條件分別為:
動態(tài)時間規(guī)整是一種最優(yōu)化算法,它把一個N階段決策過程化為N個單階段的決策過程,也就是轉(zhuǎn)化為逐一做出決策的N個子問題,以便簡化計算。動態(tài)時間規(guī)整的過程一般是從最后一個階段開始進行,也即它是一個逆序過程,其遞推過程可以表示為:
其中,g(ny,nx)是為了ny,nx的取值滿足時間規(guī)整函數(shù)的約束條件,D函數(shù)表示累計失真函數(shù),d函數(shù)表示點與點之間的失真函數(shù)。
④訓(xùn)練高斯過程求其超參數(shù):高斯過程可完全由二階統(tǒng)計量確定,即均值和方差,假設(shè)均值函數(shù)為m(x),方差函數(shù)為κ(X,X′),高斯過程可表示為:
y~GP(m(x),κ(X,X′)) (26)
其中我們假設(shè)均值m(x)為0,方差κ(X,X′)為:
上式中包含未知超參數(shù)σ和l,因此通過訓(xùn)練數(shù)據(jù)對其高斯過程進行訓(xùn)練,計算σ和l的值。
將動態(tài)時間規(guī)整對齊后的源和目標特征參數(shù)作為高斯過程訓(xùn)練數(shù)據(jù),得到兩者之間的映射關(guān)系。
在轉(zhuǎn)換階段:
①待轉(zhuǎn)換的源語音用諧波隨機模型進行分析,得到基音頻率軌跡和諧波聲道譜參數(shù)的幅度值和相位值,該過程和訓(xùn)練階段中的第一步相同。
②和訓(xùn)練階段一樣,將諧波加噪聲模型參數(shù)轉(zhuǎn)換為倒譜系數(shù)參數(shù)。
③利用訓(xùn)練階段得到的映射關(guān)系將源語音倒譜系數(shù)和基音頻率映射為轉(zhuǎn)換語音的倒譜系數(shù)和基音頻率。
④對得到的轉(zhuǎn)換語音特征參數(shù)利用公式(5)和(6)進行聯(lián)合優(yōu)化,實現(xiàn)對高斯過程輸出的后濾波,以便進一步輸出更為準確的預(yù)測值。
⑤將轉(zhuǎn)換后的倒譜系數(shù)參數(shù)反變換為諧波加隨機模型系數(shù),然后和映射后的基頻軌跡一起合成轉(zhuǎn)換后的語音,詳細步驟如下:
a.將獲得的用正弦模型的定義合成第k幀的語音,即:
b.為了減少幀間交替時產(chǎn)生的誤差,采用疊接相加法合成整個語音,即對于任意相鄰的兩幀,有:
其中N表示一幀語音中包含的樣點數(shù),m代表樣點數(shù)。
以上所述僅是本發(fā)明的優(yōu)選實施方式,應(yīng)當(dāng)指出:對于本技術(shù)領(lǐng)域的普通技術(shù)人員來說,在不脫離本發(fā)明原理的前提下,還可以做出若干改進和潤飾,這些改進和潤飾也應(yīng)視為本發(fā)明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!
- 一種單相并網(wǎng)lcl型逆變器系統(tǒng)的制作方法
- 正弦波濾波器的制造方法
- 一種雙饋變頻器的可擴展型數(shù)字量輸入輸出模塊的制作方法
- 基于lcl型濾波器的apf系統(tǒng)及其控制系統(tǒng)的制作方法
- 各種新型多波長合波器及使用合波器的新型多波長光源的制作方法
- 具有具堆疊芯片的經(jīng)部分薄化引線框架及內(nèi)插件的轉(zhuǎn)換器的制造方法
- 一種基于輸出濾波電路的正弦波逆變系統(tǒng)的制作方法
- 逆電視電影濾波器的制造方法
- 加強的峰值電流模式脈波寬度調(diào)變切換調(diào)節(jié)器的制造方法
- 具有半導(dǎo)體芯片端子的dc-dc轉(zhuǎn)換器的制造方法