一種自動韻律提取方法、系統及其在自然語言處理任務中的應用與流程
本發明涉及一種語音韻律提取方法,更具體的,涉及一種自動韻律提取方法、系統及其在自然語言處理任務中的應用。
背景技術:
語音中的韻律能夠通過賦予句子中不同詞語以不同的突出性來反應說話者的意圖,因此韻律突出性被認為對于理解語音的語義性和語用性有著指示性作用,語音的韻律主要包括連讀、意群停頓、重讀、升降調等信息。而除了語音之外,文本作為能夠表達語義性與語用性的另一種形式,其內含的韻律特性是可以被不同的閱讀者理解并學習的,即文本包含了自身的韻律特性,這種特性可以被學習與預測,同時這種內含的韻律能夠為其它自然語言處理任務提供語義性和語用性上的指導,進而提升它們的性能。文本數據中隱式的韻律無法被直接觀測與獲得,因此,只能從語音數據中獲得并標記其對應文本的韻律,進而才能讓算法學習如何從純文本中感知并預測韻律,從而為其它自然語言處理任務提供除了有監督的語法信息以外的指導。
當前大部分自然語言處理架構均以詞語及其表示(詞向量)為基本單位,而語音中的韻律特性表現為連續的特征序列,并且語音沒有明顯的詞語分割點,加上基于語音識別技術的精準詞語韻律提取無法得到大規模優質的語料和訓練,導致目前大部分對于語音的韻律特性的提取和利用的方法均需要有專家經驗的人進行人工分割語音片段、對齊語音與文本、標注詞語韻律特征等,使得有監督數據的產生過程效率低下。
現有技術中有以下相關文獻:
1)Brenier,J.M.;Cer,D.M.;and Jurafsky,D.2005.The detection of emphatic words using acoustic and lexical features.In INTERSPEECH,3297-3300.
2)Brenier,J.M.2008.The Automatic Prediction of Prosodic Prominence from Text.ProQuest.
提供了利用純文本預測韻律的方法及其對應的評價指標。文獻使用了ToBI工具集對語音及其對應文本進行人工的分割與韻律突出性標注,根據不同單詞對應的語音特征,如:發音時長(duration)、發音強度(intensity)、發音基礎頻率的最大最小值(fundamental frequency minima and maxima)等,來判斷其是否被突出,進而生成文本的韻律數據集。文獻同時使用了最大熵分類器對文本的韻律進行學習與預測,在只使用文本特征的情況下,分類器能夠達到79%左右的預測準確率。以上文獻并沒有將生成的韻律數據集應用于輔助其它自然語言處理任務。
另外一篇相關文獻:
3)Hovy,D.;Anumanchipalli,G.K.;Parlikar,A.;Vaughn,C.;Lammert,A.;Hovy,E.;and Black,A.W.2013.Analysis and Modeling of“Focus”in Context.In INTERSPEECH,402-406.
提供了一種利用純文本從上下文預測韻律的方法。文獻在相關工作的基礎上,使用了上下文輔助了文本韻律的預測,并使用了眾包(crowdsourcing)的方法進行了一定規模的人工韻律數據集標注。
上面列舉的三個相關文獻中,無一例外地均需要人工對詞語韻律屬性進行標注,同時在標注前需要進行語音的分割及其與文本的對齊,這在效率上對數據集的生成造成了限制,使得該方法無法在短時間內獲得大量標注數據,因而上節的文獻中提到的方法均缺乏實效性,無法在實際生產中應用。同時,以上方法產生的數據集樣本量不足以覆蓋所有韻律預測的問題空間,使得算法可擴展性不強,造成應用上性能不足的情況。
因此,現有技術中并沒有發現能夠自動從語音中提取詞語對應的韻律特性的方法,其全部均為人工進行手動提取,同時在現有相關文獻中,并沒有發現任何使用語音對應的文本韻律特性輔助自然語言處理任務的記載或實際應用,在此特定范疇內,本發明提供了第一個可行的方法。
技術實現要素:
本發明旨在至少解決現有技術中存在的技術問題之一。
為此,本發明的目的在于,提出一種高效的自動韻律提取及其在自然語言處理任務上應用的方法,這種方法能夠克服傳統人工標注的低效、標準不一、無法大規模應用的缺陷,同時能夠將存在于大量語音數據中的語義和語用特性遷移到其它任務上,作為一種在標注上無監督的數據生成方式,本發明能夠有效地利用語音中的韻律模式,對其它自然語言處理任務的性能進行改進。
為實現上述目的,本發明提供了一種自動語音韻律提取標注方法,該方法包括如下步驟:
步驟1,接收待標注語音數據,獲取所述語音數據的對應文本;
步驟2,使用文本-語音對齊技術對采集到的語音數據及所述對應文本進行時間軸上的對齊,形成對齊文本;
步驟3,對所述對齊文本進行句子分割,從而生成以句子為單位的樣本;
步驟4,對所述樣本中的每個句子應用自動韻律突出性標注算法,從而構造并得到自動標注的文本韻律數據集,其中,所述句子的韻律突出性標注(或句子的韻律標注)指代句子對應的數值序列,該序列通過數值大小反映句子不同部分(或基本單元)所具有的韻律突出性強度。
更具體的,所述步驟2中所述的語音數據及其對應文本進行時間軸上的對齊具體是指:使得每個文本中的基本單元能夠對應所述語音數據上的一段時間軸,從而得到所述文本中每個基本單元對應的語音數據片段,其中,所述基本單元指代中文的字或詞語,英文的單詞。
更具體的,所述步驟4還包括:若原始語音數據中包含多個朗讀者或者多個不同朗讀的環境,則需要對不同朗讀者的發音習慣分別做標準化處理,以及將所述語音數據的韻律特征進行離散化處理。
根據本發明的另一方面,還提供了一種自動韻律提取方法在自然語言處理任務中的應用,該方法包括:
將文本數據的韻律作為一個序列標注任務,采用長短期記憶人工神經網絡(LSTM)對于韻律序列進行建模,LSTM模型的輸入為句子對應的詞向量序列,在每個時間點預測并輸出當前位置基本單元的韻律突出性標注。
更具體的,所述LSTM模型可擴展到雙向LSTM網絡、多層雙向LSTM網絡或時間循環神經網絡及其衍生類型與結構等。
更具體的,該方法還包括:
將文本韻律數據集用于基于循環神經網絡(RNN)的句子壓縮任務:將文本韻律突出性標注作為輔助任務,將句子壓縮任務作為主要任務,采用多任務學習下的交替訓練方式,每個時間段給所述模型輸入一部分文本韻律數據或句子壓縮數據,下一個時間段輸入另外一個任務,兩個任務交替進行,直到所述模型收斂。
更具體的,該方法還包括:
將文本韻律數據集用于輔助基于循環神經網絡及其相關擴展改進結構的自然語言處理任務:將文本韻律突出性標注作為輔助任務,將句子壓縮任務作為主要任務,采用多任務學習下的交替訓練方式,每個時間段給所述模型輸入一部分文本韻律數據或句子壓縮數據,下一個時間段輸入另外一個任務,兩個任務交替進行,通過優化所述模型參數,直到所述模型收斂。
根據本發明的另一方面,還提供了一種自動語音韻律提取標注系統,該系統包括:
采集模塊,接收待標注語音數據,獲取所述語音數據的對應文本;
對齊模塊,使用文本-語音對齊技術對采集到的語音數據及其文本進行時間軸上的對齊,形成對齊文本;
分割模塊,對所述對齊文本進行句子分割,生成以句子為單位的樣本;
自動韻律標注模塊,對所述樣本中的每個句子應用自動韻律突出性標注算法,從而構造并得到自動標注的文本韻律數據集,其中,所述句子的韻律突出性標注(或句子的韻律標注)指代句子對應的數值序列,該序列通過數值大小反映句子不同部分(或基本單元)所具有的韻律突出性強度。
更具體的,所述對齊模塊中所述的語音數據及其對應文本進行時間軸上的對齊具體是指:使得每個文本中的基本單元能夠對應所述語音數據上的一段時間軸,從而得到所述文本中每個基本單元對應的語音數據片段,其中,所述基本單元指代中文的字或詞語,英文的單詞。
更具體的,所述分割模塊還用于:
若原始語音數據中包含多個朗讀者或者多個不同朗讀的環境,則需要對不同朗讀者發音習慣分別做標準化處理,以及根據需要將韻律特征進行離散化處理。
本發明具有如下有益技術效果:
1)使用了自動文本-語音對齊技術進行大規模韻律數據集的生成,利用對齊后的語音片段作為韻律指標,能夠將韻律突出性的標注質量控制在一定強度的基礎上,構造具有弱監督特性的文本韻律數據集,相比于傳統的人工標注手段,除了效率更高的優勢以外,在擴展性上也顯著優于傳統方式,能夠隨時加入先驗知識以調整數據集的實際標注結果和性能表現,處理速度快、成本低,節省了大量人力資源的情況下構造巨量的數據(相同時間內產生數據量比傳統方法多兩個數量級以上)。
2)本發明使用了循環神經網絡對句子的韻律進行建模,加入雙向擴展的機制之后,循環神經網絡能夠有效考慮詞語的上下文狀態,對于詞語韻律突出性標注的預測準確率可以達到90%以上,顯著優于傳統最大熵方法,同時無需專家知識進行特征提取,減少特征工程的同時,流程更加符合人類認知的過程。
3)本發明將自動構造的文本韻律數據集用于基于循環神經網絡的自然語言處理任務上。
此方法充分利用了文本韻律序列和自然語言處理任務中的常見序列數據的同構特性,通過在多任務學習下的交替訓練方式,使得自然語言處理任務在不需要顯式標注的語義信息的輔助下得到提升。在句子壓縮任務的實例中,本發明的方法相對于現有技術有著顯著的性能提升(10%以上的性能提升)。
本發明的附加方面和優點將在下面的描述部分中給出,部分將從下面的描述中變得明顯,或通過本發明的實踐了解到。
附圖說明
本發明的上述和/或附加的方面和優點從結合下面附圖對實施例的描述中將變得明顯和容易理解,其中:
圖1示出了根據本發明一種自動語音韻律提取標注方法的流程圖;
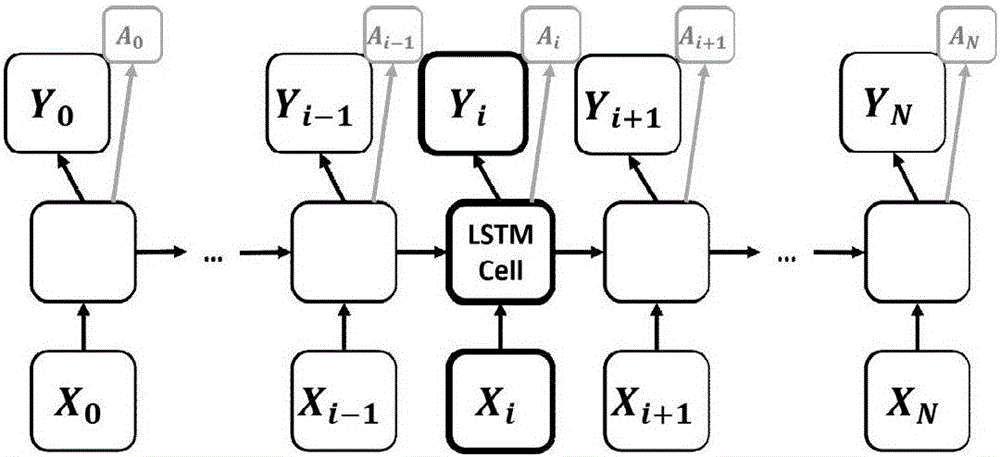
圖2中示出了根據本發明的多任務LSTM模型處理方式圖;
圖3中示出了根據本發明的多任務雙向LSTM模型處理方式圖;
圖4示出了本發明一種自動語音韻律提取標注系統的系統框圖。
具體實施方式
為了能夠更清楚地理解本發明的上述目的、特征和優點,下面結合附圖和具體實施方式對本發明進行進一步的詳細描述。需要說明的是,在不沖突的情況下,本申請的實施例及實施例中的特征可以相互組合。
在下面的描述中闡述了很多具體細節以便于充分理解本發明,但是,本發明還可以采用其他不同于在此描述的方式來實施,因此,本發明的保護范圍并不受下面公開的具體實施例的限制。
圖1示出了根據本發明一種自動語音韻律提取標注方法的流程圖。
如圖1所示,根據本發明的一種自動語音韻律提取標注方法,該方法包括如下步驟:
步驟1,接收待標注語音數據,獲取所述語音數據的對應文本。
步驟2,使用文本-語音對齊技術對采集到的語音數據及所述對應文本進行時間軸上的對齊,形成對齊文本;
具體的,可以通過每個文本中的基本單元對應所述語音數據上的一段時間軸,從而得到所述文本中每個基本單元對應的語音數據片段。其中,基本單元,指代中文中的字或詞語,英文中的一個單詞。
此外,文本-語音對齊技術包括但不限于通過獲取所述語音數據中每個基本單元起始發音對應的時間到結束發音對應的時間,從而獲取在所述語音數據中每個基本單元所用的一段時間軸以及基本單元之間的時間段。
步驟3,對所述對齊文本進行句子分割,生成以句子為單位的樣本。
舉例來說,可以但不限于根據句子的標點符號特性,對對齊文本進行句子分割,使得每個句子由附帶有對應語音數據片段的基本單元組成。
步驟4,對所述句子分割后文本中的每個句子應用自動韻律突出性標注算法,從而構造并得到自動標注的文本韻律數據集。
具體的,在該步驟中還包括:若原始語音數據中包含多個朗讀者或者多個不同朗讀的環境,則需要對不同朗讀者發音習慣分別做標準化處理,以消除其中的影響,并根據需要對語音數據的韻律特征進行離散化處理。其中,韻律特征指代所述基本單元的發音長度、發音強度、發音基礎頻率的最大值與最小值。
對所述句子分割后文本中的每個句子應用自動韻律突出性標注算法,可以選擇上述三個韻律特征中的部分或者全部特征作為自動韻律突出性標注算法的輸入,其中,所述句子的韻律突出性標注(或句子的韻律標注)指代句子對應的數值序列,該序列通過數值大小反映句子不同部分(或基本單元)所具有的韻律突出性強度。
根據本發明的第二方面,還提供了一種自動韻律提取在自然語言處理任務中的應用方法,該應用方法包括:
將對于文本數據的韻律作為一個序列標注任務,采用長短期記憶人工神經網絡(LSTM)對于韻律序列進行建模,LSTM模型的輸入為句子對應的詞向量序列,在每個時間點預測并輸出當前位置基本單元的韻律突出性標注。
更具體的,所述LSTM模型可擴展到雙向LSTM網絡、多層雙向LSTM網絡或時間循環神經網絡及其衍生類型與結構,如門控時間循環網絡(Gated Recurrent Network,GRN)等。
更具體的,該應用方法還包括:
將文本韻律數據集用于基于循環神經網絡(RNN)的句子壓縮任務:將文本韻律突出性標注作為輔助任務,將句子壓縮任務作為主要任務,采用多任務學習下的交替訓練方式,每個時間段給所述模型輸入一部分文本韻律數據或句子壓縮數據,下一個時間段輸入另外一個任務,兩個任務交替進行,直到所述模型收斂。圖2中示出了根據本發明的多任務LSTM模型處理方式,文本韻律突出性標注作為輔助任務,對應A系列節點的輸出,而句子壓縮任務作為主要任務,對應Y系列節點的輸出。采用交替訓練的方式,每個時間段給模型輸入一部分文本韻律突出性標注任務數據或句子壓縮數據,下一個時間段輸入另外一個任務,兩個任務交替進行,直到模型收斂。圖3中示出了根據本發明的多任務雙向LSTM模型處理方式。
更具體的,該應用方法還包括:
將文本韻律數據集用于基于循環神經網絡的自然語言處理任務:將文本韻律突出性標注作為輔助任務,將句子壓縮任務作為主要任務,采用多任務學習下的交替訓練方式,每個時間段給所述模型輸入一部分文本韻律數據或句子壓縮數據,下一個時間段輸入另外一個任務,兩個任務交替進行,通過優化所述模型參數,直到所述模型收斂。其中,循環神經網絡包括但不限于LSTM、GRU及其深度上的擴展。
對于上述方式可以用形式化語言描述,設X是輸入的文本序列,A為文本序列對應的韻律突出性序列,Y為文本對應的壓縮標記,三個序列對應于以下形式:
X=(x1,...,xN),
A=(a1,...,aN)
Y=(y1,...,yN)
上述任務實際上是優化如下問題:
對于LSTM模型(上),p可以表示為:
對于雙向LSTM模型(下),p可以表示為:
其中,
使用優化后的參數θ*,模型的韻律突出性A預測輸出表示為:
同理對于模型的主要預測任務Y,可以得到同構的表達式,這里不再贅述。
圖4示出了本發明一種自動語音韻律提取標注系統的系統框圖。
如圖4所示,該系統包括:
采集模塊,接收待標注語音數據,獲取所述語音數據的對應文本;
對齊模塊,使用文本-語音對齊技術對采集到的語音數據及其文本進行時間軸上的對齊,形成對齊文本;
分割模塊,對所述對齊文本進行句子分割,生成以句子為單位的樣本;
自動韻律標注模塊,對所述樣本中的每個句子應用自動韻律突出性標注算法,從而構造并得到自動標注的文本韻律數據集,其中,所述句子的韻律突出性標注(或句子的韻律標注)指代句子對應的數值序列,該序列通過數值大小反映句子不同部分(或基本單元)所具有的韻律突出性強度。
更具體的,所述對齊模塊中所述的語音數據及其對應文本進行時間軸上的對齊具體是指:使得每個文本中的基本單元能夠對應所述語音數據上的一段時間軸,從而得到所述文本中每個基本單元對應的語音數據片段,其中,所述基本單元指代中文的字或詞語,英文的單詞。
更具體的,所述分割模塊還用于:
若原始語音數據中包含多個朗讀者或者多個不同朗讀的環境,則需要對不同朗讀者發音習慣分別做標準化處理,以及根據需要將所述語音數據的韻律特征進行離散化處理。
本發明通過自動文本-語音對齊技術,將語音片段與對文本中應詞語進行對齊,利用語音片段作為詞語韻律突出性的指標,從而獲得自動生成的大量帶有標注的文本韻律數據,構建文本韻律數據集。
同時,本發明利用弱監督特性,將文本韻律數據集使用多任務學習的方式,在循環神經網絡的模型結構下,與其它自然語言處理任務進行交替訓練,從而達到改進其它任務性能的目的。
在本說明書的描述中,術語“一個實施例”、“具體實施例”等的描述意指結合該實施例或示例描述的具體特征、結構或特點包含于本發明的至少一個實施例或示例中。在本說明書中,對上述術語的示意性表述不一定指的是相同的實施例或實例。而且,描述的具體特征、結構或特點可以在任何的一個或多個實施例或示例中以合適的方式結合。
以上所述僅為本發明的優選實施例而已,并不用于限制本發明,對于本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!