基于匹配模型二次識(shí)別的語音識(shí)別方法及系統(tǒng)與流程
本發(fā)明屬于人機(jī)語音交互技術(shù)領(lǐng)域,特別是一種識(shí)別準(zhǔn)確度高、用戶體驗(yàn)好的基于匹配模型二次識(shí)別的語音識(shí)別方法及實(shí)現(xiàn)該方法的系統(tǒng)。
背景技術(shù):
語音識(shí)別是理想的人機(jī)交互中介工具,是推動(dòng)機(jī)器向更智能化發(fā)展的重要技術(shù)。能聽懂人講話,可以進(jìn)行思考和理解人的意圖,并最終對(duì)人作出語音或者行動(dòng)上的響應(yīng)的智能化機(jī)器一直是人工智能的終極目標(biāo)之一。
在大數(shù)據(jù)的背景下,機(jī)器學(xué)習(xí)逐漸滲透到智能家居、車載語音、身份識(shí)別等領(lǐng)域。基于大數(shù)據(jù)的深度學(xué)習(xí)研究方法對(duì)語音識(shí)別系統(tǒng)性能的提升有重要意義。早在幾年前就有國外學(xué)者提出了關(guān)于將深度學(xué)習(xí)研究方法運(yùn)用在語音識(shí)別上(geoffreyhinton,lideng,dongyu.deepneuralnetworksforacousticmodelinginspeechrecognition)。
但是通過調(diào)整模型結(jié)構(gòu)以及參數(shù)來提升語音識(shí)別系統(tǒng)準(zhǔn)確率的方法,在實(shí)際用戶語音噪聲背景不匹配時(shí)會(huì)導(dǎo)致語音識(shí)別準(zhǔn)確率急劇下降,嚴(yán)重影響人機(jī)交互體驗(yàn)。
技術(shù)實(shí)現(xiàn)要素:
本發(fā)明的目的在于提供一種基于匹配模型二次識(shí)別的語音識(shí)別方法,識(shí)別準(zhǔn)確度高、用戶體驗(yàn)好。
本發(fā)明的另一目的在于提供一種基于匹配模型二次識(shí)別的語音識(shí)別系統(tǒng),識(shí)別準(zhǔn)確度高、用戶體驗(yàn)好。
實(shí)現(xiàn)本發(fā)明目的的技術(shù)解決方案為:
一種基于匹配模型二次識(shí)別的語音識(shí)別方法,包括如下步驟:
(10)語音處理:對(duì)用戶輸入的語音進(jìn)行預(yù)處理及特征提取;
(20)語音識(shí)別:識(shí)別解析用戶的語音信息,提取并保存用戶性別和環(huán)境噪聲信息;
(30)用戶評(píng)價(jià):接收用戶對(duì)第一次識(shí)別結(jié)果的反饋信息,如第一次識(shí)別結(jié)果不符合期望,則繼續(xù)進(jìn)行二次識(shí)別,發(fā)出二次識(shí)別請(qǐng)求;
(40)匹配模型識(shí)別:在二次識(shí)別請(qǐng)求下,根據(jù)用戶性別和環(huán)境噪聲情況,匹配一個(gè)最優(yōu)的語音識(shí)別模型,重新識(shí)別并輸出解析結(jié)果。。
實(shí)現(xiàn)本發(fā)明另一目的的技術(shù)解決方案為:
一種基于匹配模型二次識(shí)別的語音識(shí)別系統(tǒng),包括:
語音處理單元(1),用于對(duì)用戶輸入的語音進(jìn)行預(yù)處理及特征提取;
語音識(shí)別單元(2),用于識(shí)別解析用戶的語音信息,提取并保存用戶性別和環(huán)境噪聲信息;
用戶評(píng)價(jià)(3),用于接收用戶對(duì)第一次識(shí)別結(jié)果的反饋信息;
匹配模型識(shí)別單元(4),用于根據(jù)用戶性別和環(huán)境噪聲情況,匹配一個(gè)最優(yōu)的語音識(shí)別模型,重新識(shí)別并輸出解析結(jié)果。
本發(fā)明與現(xiàn)有技術(shù)相比,其顯著優(yōu)點(diǎn)為:
1、識(shí)別準(zhǔn)確度高:本發(fā)明的方法基于機(jī)器學(xué)習(xí),利用針對(duì)不同用戶的輸入語音情況在對(duì)應(yīng)的訓(xùn)練集上建立與之匹配的聲學(xué)模型,很好的保證了識(shí)別系統(tǒng)的準(zhǔn)確率;
2、用戶體驗(yàn)好:本發(fā)明的方法重復(fù)利用了用戶輸入語音,避免了一旦識(shí)別出錯(cuò)只能二次輸入的情況,極大的提升了用戶體驗(yàn)。
下面結(jié)合附圖和具體實(shí)施方式對(duì)本發(fā)明作進(jìn)一步的詳細(xì)描述。
附圖說明
圖1為本發(fā)明基于匹配模型二次識(shí)別的語音識(shí)別方法的主流程圖。
圖2是圖1中識(shí)別解析用戶的語音信息步驟的原理框圖。
圖3是圖1中用戶性別提取步驟的原理框圖。
圖4是圖1中環(huán)境噪聲提取步驟的流程圖。
具體實(shí)施方式
如圖1所示,本發(fā)明基于匹配模型二次識(shí)別的語音識(shí)別方法,包括如下步驟:
(10)語音處理:對(duì)用戶輸入的語音進(jìn)行預(yù)處理及特征提取;
現(xiàn)有技術(shù)中,常見的語音識(shí)別模型建模過程包括以下步驟:
(1)獲取足量已經(jīng)標(biāo)注好的訓(xùn)練數(shù)據(jù),提取每個(gè)訓(xùn)練樣本的梅爾域倒譜系數(shù)(mfcc)作為聲學(xué)特征;整理訓(xùn)練數(shù)據(jù)的標(biāo)注信息提取文本特征矢量
(2)將訓(xùn)練樣本的聲學(xué)特征向量輸入到由受限玻爾茲曼機(jī)器(rbm)堆疊構(gòu)成的深度神經(jīng)網(wǎng)絡(luò)(dnn)中,采用gmm-hmm基線系統(tǒng)經(jīng)強(qiáng)制對(duì)齊得到神經(jīng)網(wǎng)絡(luò)的輸出層。將訓(xùn)練樣本的網(wǎng)絡(luò)輸出結(jié)果與實(shí)際標(biāo)注信息進(jìn)行對(duì)照得到輸出層的誤差信號(hào),利用誤差反向傳播(bp)算法來調(diào)整網(wǎng)絡(luò)參數(shù)。反復(fù)訓(xùn)練,調(diào)整參數(shù)得到最終的聲學(xué)模型。
(3)根據(jù)樣本文本特征矢量,分析得到統(tǒng)計(jì)意義上的語言環(huán)境中的詞序列概率。用三音素的n-gram分析方法訓(xùn)練語言模型,得到樣本空間的語言模型。
(4)運(yùn)用維特比解碼算法,把由訓(xùn)練樣本空間抽取得到的發(fā)音詞典,語音模型以及聲學(xué)模型連成一個(gè)網(wǎng)絡(luò),通過搜索網(wǎng)絡(luò)中的最優(yōu)路徑完成待解析的用戶輸入語音的解碼。
(20)語音識(shí)別:識(shí)別解析用戶的語音信息,提取并保存用戶性別和環(huán)境噪聲信息;
如圖2所示,所述(20)語音識(shí)別步驟中,識(shí)別解析用戶的語音信息步驟包括:
(211)提取用戶輸入語音的梅爾域倒譜系數(shù)(mfcc)作為聲學(xué)特征;
(212)將輸入語音的特征向量輸入到已經(jīng)在訓(xùn)練樣本集上訓(xùn)練完成的聲學(xué)模型中,解碼得到輸入語音的音素成分。
(213)用戶輸入語音的音素組成信息被輸入到解碼器中,解碼器綜合訓(xùn)練集的發(fā)音詞典以及語言模型,給用戶輸入語音一個(gè)最優(yōu)詞序列作為最終的識(shí)別解析結(jié)果。
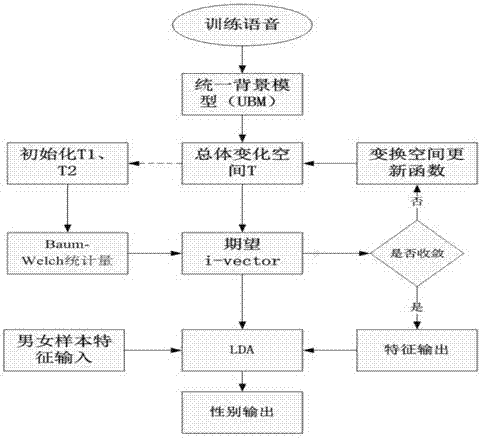
如圖3所示,所述(20)語音識(shí)別步驟中,用戶性別提取步驟包括:
(221)模型訓(xùn)練:采用最大似然準(zhǔn)則在足量的數(shù)據(jù)樣本上訓(xùn)練高斯混合模型;
(222)語音特征提取:提取用戶輸入語音的語音特征,其總體變量空間在ubm上的超級(jí)矢量m表示如下,
m=m+tx+e
其中,m是特定輸入語句的超級(jí)矢量,m是樣本數(shù)據(jù)的均值超級(jí)矢量,x是符合正態(tài)分布的低維隨機(jī)矢量,t是描述總體變化的矩陣,e是由噪聲或其他非相關(guān)因素產(chǎn)生的殘差,gmm為高斯混合模型,ubm為統(tǒng)一背景模型;
在已知ubm-gmm模型的參數(shù)為ω時(shí),i-vector可以由上式得到,從而解決如下問題:
(223)根據(jù)樣本數(shù)據(jù)的baum-welch統(tǒng)計(jì)量γk(i)和γy,k(i),公式如下:
可以得到i-vector的提取公式:
(224)特征向量估計(jì):根據(jù)i-vector的提取公式,可以利用em算法來估計(jì)實(shí)際特征向量。
(225)用戶性別分析:將提取得到的用戶i-vector特征用線性投影分析(lda)方法投影在由500名男性500名女性構(gòu)成的散布平面上,由此分析出用戶性別。
所述(224)特征向量估計(jì)步驟包括:
(2241)初始化:在訓(xùn)練樣本中隨機(jī)地選取t,設(shè)定t中每個(gè)成分的初始值,對(duì)于每個(gè)訓(xùn)練的語音片段計(jì)算其相應(yīng)的baum-welch統(tǒng)計(jì)量。
(2242)設(shè)定e值:對(duì)于每個(gè)訓(xùn)練的語音片段用充足的數(shù)據(jù)和當(dāng)前對(duì)t的估計(jì),計(jì)算ω(i)的期望值,計(jì)算的方法如下:
e[ω(i)]=i-1(i)ttr0-1γy(i)
e[ω(i)ωt(i)]=e[ω(i)]e[ωt(i)]+i-1(i)
(2243)設(shè)定m值:采用一個(gè)方程更新總體變化矩陣t:
(2244)重復(fù)或者中止:反復(fù)步驟(2242)、(2243),直到迭代次數(shù)的固定值或者直到目標(biāo)函數(shù)收斂。
如圖4所示,所述(20)語音識(shí)別步驟中,環(huán)境噪聲提取步驟包括:
(231)功率譜密度平滑:計(jì)算用戶輸入語音的功率譜密度,并進(jìn)行遞歸平滑,所用公式如下:
y(n,k)=x(n,k)+d(n,k);
|y(n,k)|2=|x(n,k)|2+|d(n,k)|2;
p(n,k)=αp(n-1,k)+(1-α)|y(n,k)|2;
上式中,x(n,k)、d(n,k)、y(n,k)分別表示用戶輸入語音y(t)中純凈語音x(t)和不相關(guān)加性噪聲d(t)的短時(shí)傅里葉變換形式;|y(n,k)|2、|x(n,k)|2、|d(n,k)|2分別表示輸入語音、純凈語音和噪聲的功率譜。p(n,k)是對(duì)輸入語音功率譜密度進(jìn)過平滑得到的結(jié)果,α是平滑因子。
(232)噪聲功率譜獲取:搜索輸入語音的功率譜密度在一定時(shí)間窗內(nèi)的最小值,乘以一個(gè)偏差修正量即可得到噪聲功率譜,公式如下:
smin(n,k)=min{p(n,k)|n-d+1≤n≤n};
上式中,d是最小值搜索窗口長(zhǎng)度,β是偏差補(bǔ)償因子,
(233)噪聲情況判斷:利用公式
(30)用戶評(píng)價(jià):
接收用戶對(duì)第一次識(shí)別結(jié)果的反饋信息,如第一次識(shí)別結(jié)果不符合期望,則繼續(xù)進(jìn)行二次識(shí)別,發(fā)出二次識(shí)別請(qǐng)求;
(40)匹配模型識(shí)別:在二次識(shí)別請(qǐng)求下,根據(jù)用戶性別和環(huán)境噪聲情況,匹配一個(gè)最優(yōu)的語音識(shí)別模型,重新識(shí)別并輸出解析結(jié)果。
所述(40)匹配模型識(shí)別步驟具體為:
接收用戶的二次識(shí)別請(qǐng)求信號(hào),根據(jù)第一次識(shí)別得到的性別和噪聲情況信息,以用戶特征信號(hào)作為輸入,匹配到預(yù)先準(zhǔn)備的語音識(shí)別模型中,重新按照第一次識(shí)別的過程進(jìn)行二次識(shí)別和解析,返回文本結(jié)果給用戶。
本發(fā)明基于匹配模型二次識(shí)別的語音識(shí)別系統(tǒng),包括:
語音處理單元(1),用于對(duì)用戶輸入的語音進(jìn)行預(yù)處理及特征提取;
語音識(shí)別單元(2),用于識(shí)別解析用戶的語音信息,提取并保存用戶性別和環(huán)境噪聲信息;
用戶評(píng)價(jià)(3),用于接收用戶對(duì)第一次識(shí)別結(jié)果的反饋信息,如第一次識(shí)別結(jié)果不符合期望,則繼續(xù)進(jìn)行二次識(shí)別,發(fā)出二次識(shí)別請(qǐng)求;
匹配模型識(shí)別單元(4),用于根據(jù)用戶性別和環(huán)境噪聲情況,匹配一個(gè)最優(yōu)的語音識(shí)別模型,重新識(shí)別并輸出解析結(jié)果。
根據(jù)用戶性別和環(huán)境噪聲情況,匹配一個(gè)最優(yōu)的語音識(shí)別模型:匹配模型由4種根據(jù)性別(男,女)以及噪聲情況(信噪比好,信噪比差)分別獨(dú)立訓(xùn)練而成的語音識(shí)別模型組成,其建模方法跟通用識(shí)別模型一致,建模數(shù)據(jù)不再基于男女混合的有噪無噪均勻分布的訓(xùn)練集,而是分別基于高信噪比的男性語音、高信噪比的女性語音、低信噪比的男性語音、低信噪比的女性語音。以用戶原始語音特征作輸入,重新識(shí)別并輸出解析結(jié)果。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!
- 基于語音實(shí)時(shí)驅(qū)動(dòng)人物模型的表情和姿態(tài)的方法與流程
- 一種基于詞網(wǎng)語言模型的連續(xù)語音識(shí)別系統(tǒng)的制作方法與工藝
- 生成聲學(xué)模型的設(shè)備和方法和用于語音識(shí)別的設(shè)備和方法與流程
- 建立語音聲學(xué)模型的方法和裝置與流程
- 一種果蔬外觀變化識(shí)別模型的建立方法和識(shí)別方法與流程
- 用于改進(jìn)含噪語音識(shí)別的動(dòng)態(tài)聲學(xué)模型切換的制造方法與工藝
- 文本識(shí)別模型建立方法和裝置與流程
- 一種基于GMM模型的語音激活檢測(cè)方法與流程
- 一種建立數(shù)據(jù)識(shí)別模型的方法及裝置與流程
- 訓(xùn)練神經(jīng)網(wǎng)絡(luò)聲學(xué)模型的方法和裝置及語音識(shí)別方法和裝置與流程
- 語音識(shí)別方法和裝置的制造方法
- 語音識(shí)別方法和裝置的制造方法
- 用lstm循環(huán)神經(jīng)網(wǎng)絡(luò)模型進(jìn)行語音識(shí)別的方法和裝置的制造方法
- 用于語音識(shí)別的電子裝置和方法
- 一種基于gmm噪聲估計(jì)的模型組合語音識(shí)別方法
- 一種基于多重自適應(yīng)的模型補(bǔ)償語音識(shí)別方法
- 用于向語音操作功能分配關(guān)鍵字模型的方法和裝置的制造方法
- 一種語種識(shí)別模型的訓(xùn)練方法及語種識(shí)別方法
- 分布式語音識(shí)別系統(tǒng)中的語音模型檢索的制作方法
- 基于垃圾模型的語音識(shí)別處理方法及裝置的制造方法
- 一種基于聲紋識(shí)別的智能鎖及其語音識(shí)別方法和系統(tǒng)與流程
- 一種語音識(shí)別測(cè)試系統(tǒng)和方法與流程
- 一種語音識(shí)別方法與制造工藝
- 在語音識(shí)別中插入字符的方法和設(shè)備與制造工藝
- 一種機(jī)器人語音識(shí)別方法及裝置與制造工藝
- 語音識(shí)別方法及裝置與制造工藝
- 語音識(shí)別方法及裝置與制造工藝
- 基于人工神經(jīng)網(wǎng)絡(luò)的語音識(shí)別方法、裝置及電子設(shè)備與制造工藝
- 一種可過濾揚(yáng)聲器噪音的語音識(shí)別方法及其系統(tǒng)的制作方法
- 語音識(shí)別方法及裝置的制造方法