一種基于聲紋的身份識別方法和設備與流程
本發明涉及身份識別領域,特別涉及一種基于聲紋的身份識別方法和設備。
背景技術:
人類與機器之間的信息傳遞,目前仍然以鍵盤輸入的文字為主,但是這種方式需要額外的設備,識別不夠方便,且容易被盜。
技術實現要素:
針對現有技術中的缺陷,本發明提出了一種基于聲紋的身份識別方法和設備。
具體的,本發明提出了以下具體的實施例:
本發明實施例提出了一種基于聲紋的身份識別方法,包括:
當業務應用請求需要用戶確認身份信息時,提示所述用戶輸入語音密碼;
接收所述用戶的語音數據,并將所述語音數據轉換為文字信息;
將所述文字信息與用戶列表中各用戶事先設置的預設語音密碼中文字信息進行匹配;
若所述語音密碼匹配成功,獲取所述用戶的聲紋特征;
將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度;
若所述匹配度大于預設識別閾值,則確認所述用戶的身份識別成功。
在一個具體的實施例中,該方法還包括:
基于所述業務應用請求確定所包括的用戶;
基于所確定的用戶生成用戶列表。
在一個具體的實施例中,該方法還包括:
若所述語音密碼匹配不成功,則提示所述用戶再次輸入語音密碼。
在一個具體的實施例中,所述將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度,包括:
將所述聲紋特征分別與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取到多個預設聲紋特征匹配值;
選取最大預設聲紋特征匹配值作為匹配度。
在一個具體的實施例中,該方法還包括:
若所述匹配度不大于預設識別閾值,則提示所述用戶再次輸入語音密碼。
在一個具體的實施例中,該方法還包括:
獲取用戶輸入的識別信息;
當所述識別信息驗證通過后,獲取所述用戶輸入的語音密碼以及聲紋特征;
在所述語音密碼得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲。
在一個具體的實施例中,所述識別信息包括身份證信息,和/或銀行卡信息,和/或人臉識別數據。
在一個具體的實施例中,該方法還包括:
當基于預設的密碼策略以及聲紋特征的完整性確定需要額外的語音密碼時,獲取所述用戶輸入的其他語音密碼;其中,所述其他語音密碼不同于已存儲的語音密碼;
在所述其他語音密碼得到所述用戶的確認之后,將所述其他語言密碼與所述用戶進行關聯并進行存儲。
在一個具體的實施例中,所述語音密碼具體為用戶輸入的語音;
所述在所述語音密碼得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲,包括:
將所述語音密碼轉換為文字信息;
播放或展示所述文字信息;
在得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲。
本發明實施例還提出了一種基于聲紋的身份識別設備,包括:
提示模塊,用于當業務應用請求需要用戶確認身份信息時,提示所述用戶輸入語音密碼;
轉換模塊,用于接收所述用戶的語音數據,并將所述語音數據轉換為文字信息;
語音匹配模塊,用于將所述文字信息與用戶列表中各用戶事先設置的預設語音密碼中文字信息進行匹配;
獲取模塊,用于若所述語音密碼匹配成功,獲取所述用戶的聲紋特征;
聲紋匹配模塊,用于將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度;
識別模塊,用于當所述匹配度大于預設識別閾值,確認所述用戶的身份識別成功。
以此,本發明實施例提出了一種基于聲紋的身份識別方法和設備,其中該方法包括:當業務應用請求需要用戶確認身份信息時,提示所述用戶輸入語音密碼;接收所述用戶的語音數據,并將所述語音數據轉換為文字信息;將所述文字信息與用戶列表中各用戶事先設置的預設語音密碼中文字信息進行匹配;若所述語音密碼匹配成功,獲取所述用戶的聲紋特征;將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度;若所述匹配度大于預設識別閾值,則確認所述用戶的身份識別成功。以此通過語音和聲紋實現了對用戶身份的識別,實現方便,識別準確,安全性高。
附圖說明
為了更清楚地說明本發明實施例的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,應當理解,以下附圖僅示出了本發明的某些實施例,因此不應被看作是對范圍的限定,對于本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他相關的附圖。
圖1為本發明實施例提出的一種基于聲紋的身份識別方法的流程示意圖;
圖2為本發明實施例提出的一種基于聲紋的身份識別方法中進行身份識別的流程示意圖;
圖3為本發明實施例提出的一種基于聲紋的身份識別方法中錄入聲紋特征以及語音密碼的流程示意圖;
圖4為本發明實施例提出的一種基于聲紋的身份識別設備的結構示意圖;
圖5為本發明實施例提出的一種基于聲紋的身份識別設備的結構示意圖。
具體實施方式
在下文中,將更全面地描述本公開的各種實施例。本公開可具有各種實施例,并且可在其中做出調整和改變。然而,應理解:不存在將本公開的各種實施例限于在此公開的特定實施例的意圖,而是應將本公開理解為涵蓋落入本公開的各種實施例的精神和范圍內的所有調整、等同物和/或可選方案。
在下文中,可在本公開的各種實施例中使用的術語“包括”或“可包括”指示所公開的功能、操作或元件的存在,并且不限制一個或更多個功能、操作或元件的增加。此外,如在本公開的各種實施例中所使用,術語“包括”、“具有”及其同源詞僅意在表示特定特征、數字、步驟、操作、元件、組件或前述項的組合,并且不應被理解為首先排除一個或更多個其它特征、數字、步驟、操作、元件、組件或前述項的組合的存在或增加一個或更多個特征、數字、步驟、操作、元件、組件或前述項的組合的可能性。
在本公開的各種實施例中,表述“或”或“a或/和b中的至少一個”包括同時列出的文字的任何組合或所有組合。例如,表述“a或b”或“a或/和b中的至少一個”可包括a、可包括b或可包括a和b二者。
在本公開的各種實施例中使用的表述(諸如“第一”、“第二”等)可修飾在各種實施例中的各種組成元件,不過可不限制相應組成元件。例如,以上表述并不限制所述元件的順序和/或重要性。以上表述僅用于將一個元件與其它元件區別開的目的。例如,第一用戶裝置和第二用戶裝置指示不同用戶裝置,盡管二者都是用戶裝置。例如,在不脫離本公開的各種實施例的范圍的情況下,第一元件可被稱為第二元件,同樣地,第二元件也可被稱為第一元件。
應注意到:如果描述將一個組成元件“連接”到另一組成元件,則可將第一組成元件直接連接到第二組成元件,并且可在第一組成元件和第二組成元件之間“連接”第三組成元件。相反地,當將一個組成元件“直接連接”到另一組成元件時,可理解為在第一組成元件和第二組成元件之間不存在第三組成元件。
在本公開的各種實施例中使用的術語“用戶”可指示使用電子裝置的人或使用電子裝置的裝置(例如,人工智能電子裝置)。
在本公開的各種實施例中使用的術語僅用于描述特定實施例的目的并且并非意在限制本公開的各種實施例。如在此所使用,單數形式意在也包括復數形式,除非上下文清楚地另有指示。除非另有限定,否則在這里使用的所有術語(包括技術術語和科學術語)具有與本公開的各種實施例所屬領域普通技術人員通常理解的含義相同的含義。所述術語(諸如在一般使用的詞典中限定的術語)將被解釋為具有與在相關技術領域中的語境含義相同的含義并且將不被解釋為具有理想化的含義或過于正式的含義,除非在本公開的各種實施例中被清楚地限定。
實施例1
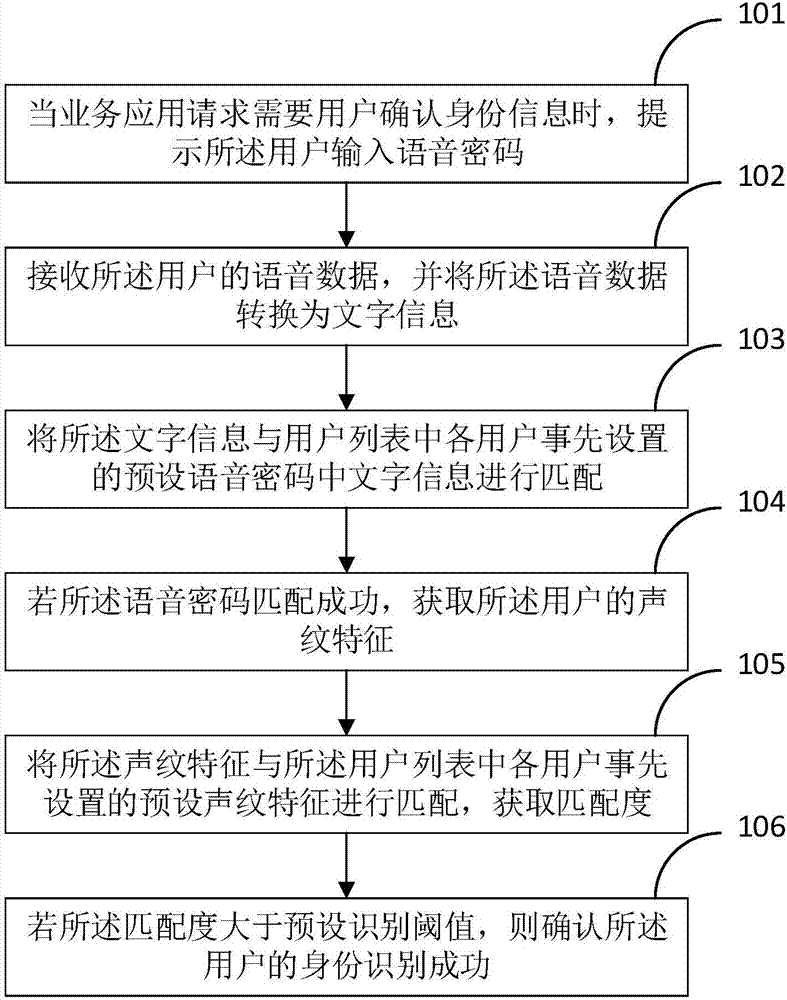
本發明實施例1公開了一種基于聲紋的身份識別方法,如圖1所示,包括:
步驟101、當業務應用請求需要用戶確認身份信息時,提示所述用戶輸入語音密碼;
步驟102、接收所述用戶的語音數據,并將所述語音數據轉換為文字信息;
步驟103、將所述文字信息與用戶列表中各用戶事先設置的預設語音密碼中文字信息進行匹配;
步驟104、若所述語音密碼匹配成功,獲取所述用戶的聲紋特征;
步驟105、將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度;
步驟106、若所述匹配度大于預設識別閾值,則確認所述用戶的身份識別成功。
具體的,在一個實施例中,還包括:
基于所述業務應用請求確定所包括的用戶;
基于所確定的用戶生成用戶列表。
具體的,以一個具體的例子來進行說明,例如業務應用請求為轉賬,基于該業務,可以查詢到所可能對應的用戶(例如預先只有這些用戶綁定了該業務,或者進行了該業務的設置),并將查詢到的用戶形成用戶列表
在一個具體的實施例中,該方法還包括:
若所述語音密碼匹配不成功,則提示所述用戶再次輸入語音密碼。
在一個具體的實施例中,步驟105中的所述將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度,包括:
將所述聲紋特征分別與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取到多個預設聲紋特征匹配值;
選取最大預設聲紋特征匹配值作為匹配度。
在一個具體的實施例中,該方法還包括:
若所述匹配度不大于預設識別閾值,則提示所述用戶再次輸入語音密碼。
具體的,在一個實施例中,使用聲紋識別驗證用戶身份流程如圖2所示,包括如下流程:
1、業務應用請求本發明所述系統確認用戶身份;
2、系統根據請求,判斷可能出現的用戶范圍(可能是一個或多個);
3、系統與用戶建立會話,提示用戶輸入語音密碼;
4、系統調用語音識別模塊,將用戶語音轉換為文字,并與用戶列表中各用戶事先設置的語音密碼進行比較;
5、如果語音密碼匹配失敗,則提示用戶重新輸入,轉回步驟3;
6、如果語音密碼匹配成功,則調用聲紋識別模塊,提取用戶聲紋特征,并與用戶列表中事先保存的聲紋特征進行比較;取出與聲紋特征匹配最佳的用戶,取出匹配度比值;
7、系統判斷匹配度的值;
8、如果匹配度大于或等于事先設定的識別通過值,則認為身份識別成功;
9、如果匹配度小于事先設定的識別最小值,則認為身份識別失敗,結束流程;
10、如果匹配度小于事先設定的識別通過值,但大于或等于事先設定的識別最小值,系統認為需要進一步識別用戶身份,轉到步驟3,提示用戶再次輸入下一組語音密碼。
至于采集聲紋特征以及語音密碼,具體的流程如下:
在一個具體的實施例中,該方法還包括:
獲取用戶輸入的識別信息;
當所述識別信息驗證通過后,獲取所述用戶輸入的語音密碼以及聲紋特征;
在所述語音密碼得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲。
在一個具體的實施例中,所述識別信息包括身份證信息,和/或銀行卡信息,和/或人臉識別數據。
在一個具體的實施例中,該方法還包括:
當基于預設的密碼策略以及聲紋特征的完整性確定需要額外的語音密碼時,獲取所述用戶輸入的其他語音密碼;其中,所述其他語音密碼不同于已存儲的語音密碼;
在所述其他語音密碼得到所述用戶的確認之后,將所述其他語言密碼與所述用戶進行關聯并進行存儲。
在一個具體的實施例中,所述語音密碼具體為用戶輸入的語音;
所述在所述語音密碼得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲,包括:
將所述語音密碼轉換為文字信息;
播放或展示所述文字信息;
在得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲。
具體的,以一個具體的實施例來進行說明,具體如圖3所示:
1、系統與用戶建立會話;
2、系統要求用戶輸入信息,并借助外部系統(如公安身份證信息、銀行卡綁定、人臉識別等)對用戶身份進行核實;
3、系統進一步收集用戶信息,通過一定保密措施之后妥善保存在用戶信息數據庫中;
4、系統提示用戶設置語音密碼;
5、用戶使用語音輸入,設置語音密碼;系統調用聲紋識別模塊提取用戶語音的聲紋特征;
6、系統保存用戶的聲紋特征;
7、系統調用語音識別模塊,將用戶輸入語音轉換為文字,并向用戶播放或展示,提示用戶確認;
8、用戶確認密碼正確后,系統保存語音密碼;
實施例2
本發明實施例2還公開了一種基于聲紋的身份識別設備,如圖4所示,包括:
提示模塊201,用于當業務應用請求需要用戶確認身份信息時,提示所述用戶輸入語音密碼;
轉換模塊202,用于接收所述用戶的語音數據,并將所述語音數據轉換為文字信息;
語音匹配模塊203,用于將所述文字信息與用戶列表中各用戶事先設置的預設語音密碼中文字信息進行匹配;
獲取模塊204,用于若所述語音密碼匹配成功,獲取所述用戶的聲紋特征;
聲紋匹配模塊205,用于將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度;
識別模塊206,用于當所述匹配度大于預設識別閾值,確認所述用戶的身份識別成功。
在一個具體的實施例中,該設備還包括:
生成模塊,用于基于所述業務應用請求確定所包括的用戶;
基于所確定的用戶生成用戶列表。
在一個具體的實施例中,該設備還包括:
第一提示模塊,用于當所述語音密碼匹配不成功時,提示所述用戶再次輸入語音密碼。
在一個具體的實施例中,所述將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度,包括:
將所述聲紋特征分別與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取到多個預設聲紋特征匹配值;
選取最大預設聲紋特征匹配值作為匹配度。
在一個具體的實施例中,該設備還包括:
第二提示模塊,用于當所述匹配度不大于預設識別閾值,則提示所述用戶再次輸入語音密碼。
在一個具體的實施例中,該設備還包括:
錄入模塊,用于獲取用戶輸入的識別信息;
當所述識別信息驗證通過后,獲取所述用戶輸入的語音密碼以及聲紋特征;
在所述語音密碼得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲。
在一個具體的實施例中,所述識別信息包括身份證信息,和/或銀行卡信息,和/或人臉識別數據。
在一個具體的實施例中,該設備還包括:
增強模塊,用于當基于預設的密碼策略以及聲紋特征的完整性確定需要額外的語音密碼時,獲取所述用戶輸入的其他語音密碼;其中,所述其他語音密碼不同于已存儲的語音密碼;
在所述其他語音密碼得到所述用戶的確認之后,將所述其他語言密碼與所述用戶進行關聯并進行存儲。
在一個具體的實施例中,所述語音密碼具體為用戶輸入的語音;
所述錄入模塊在所述語音密碼得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲,包括:
將所述語音密碼轉換為文字信息;
播放或展示所述文字信息;
在得到所述用戶的確認之后,將所述語音密碼以及聲紋特征與所述用戶進行關聯并進行存儲。
具體的,在一個具體的實施例中,該設備如圖5所示,包括以下模塊:
聲紋特征數據庫:用于保存用戶聲紋特征信息。
用戶信息數據庫:用于保存用戶個人信息。
語音通信模塊:用于實現系統和用戶之間的語音通信,包括放音單元、錄音單元和傳輸系統,例如,傳統電話網絡是一種語音通信模塊。
語音轉換模塊:用于將用戶的語音轉化為文字。根據用戶發音的特點,可提供支持用戶方言或不夠標準的普通話。
聲紋識別模塊:用于識別用戶音色、節奏、語氣、語調等發音特征,并通過一定算法提取為數字信息。
智能處理模塊:使用聲音、圖像和文字等方式與用戶交互,組織和處理業務流程。包括調用語音通信模塊采集用戶語音,調用語音識別和聲紋識別模塊進行識別,訪問聲紋特征數據庫和個人信息數據庫,并提供與外部系統的接口,實現用戶身份識別功能。
本發明所述利用聲紋識別認定用戶身份的方法,包括兩個部分:一部分是保存用戶信息,另一部分是驗證用戶身份。其中,保存用戶身份信息流程如下:
1、系統與用戶建立通信會話,在確認用戶身份之后,收集用戶聲紋特征,并保存在聲紋特征數據庫中;
2、系統請求用戶設置一組語音密碼,每級密碼分別設置對應的提示語,并保存在用戶個人信息數據庫中;
其中,語音通信模塊301包括錄音單元、放音單元和傳輸系統。錄音單元負責對用戶發出的語音進行采樣,放音單元負責向用戶播放提示語音,傳輸系統負責將語音信息傳輸到其它模塊。
聲紋識別模塊302負責解析和處理用戶聲音采樣,并通過一定的算法,抽取出用戶聲紋特征。當采樣樣本數較多時,可以獲得更準確的特征數據。此模塊也負責比對兩個聲紋特征,比較結果可以通過比值進行量化。
語音轉換模塊303負責實現語音和文本之間的轉換,即tts技術。
聲紋特征數據庫304專門負責存儲用戶聲紋特征。一個用戶的聲紋特征由語氣、語調、語速、音色、音調、頻率范圍等內容組成。此模塊可從多個維度保存用戶聲紋特征,并與用戶建立關聯關系。
用戶信息數據庫305負責保存用戶身份信息,包括用戶的姓名、證件類型和證件號、性別、生日、聯系方式等,
智能處理模塊306負責執行邏輯,靈活調用各個模塊的能力,完成交互過程。它同時處理與外部系統的通信。
本發明通過聲紋識別的,具備以下有益效果:
一、絕大多數用戶終端設備都具備發音和聲音采樣功能,因此聲紋識別對用戶終端的要求低,不需要額外增加成本;
二、相比其它身份識別手段,語音輸出是人類最為快捷、自然、簡單的傳遞信息方式,幾乎沒有學習成本;
三、同時識別用戶聲紋特征和語音內容,可以有效識別他人仿冒;
四、精確計算匹配度并據此使用多次校驗的密碼策略,能有效提高識別率,解決單次識別無法確認身份的問題。
以此,本發明實施例提出了一種基于聲紋的身份識別方法和設備,其中該方法包括:當業務應用請求需要用戶確認身份信息時,提示所述用戶輸入語音密碼;接收所述用戶的語音數據,并將所述語音數據轉換為文字信息;將所述文字信息與用戶列表中各用戶事先設置的預設語音密碼中文字信息進行匹配;若所述語音密碼匹配成功,獲取所述用戶的聲紋特征;將所述聲紋特征與所述用戶列表中各用戶事先設置的預設聲紋特征進行匹配,獲取匹配度;若所述匹配度大于預設識別閾值,則確認所述用戶的身份識別成功。以此通過語音和聲紋實現了對用戶身份的識別,實現方便,識別準確,安全性高。
本領域技術人員可以理解附圖只是一個優選實施場景的示意圖,附圖中的模塊或流程并不一定是實施本發明所必須的。
本領域技術人員可以理解實施場景中的裝置中的模塊可以按照實施場景描述進行分布于實施場景的裝置中,也可以進行相應變化位于不同于本實施場景的一個或多個裝置中。上述實施場景的模塊可以合并為一個模塊,也可以進一步拆分成多個子模塊。
上述本發明序號僅僅為了描述,不代表實施場景的優劣。
以上公開的僅為本發明的幾個具體實施場景,但是,本發明并非局限于此,任何本領域的技術人員能思之的變化都應落入本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!