利用射頻感測輔助的語音用戶接口的制作方法
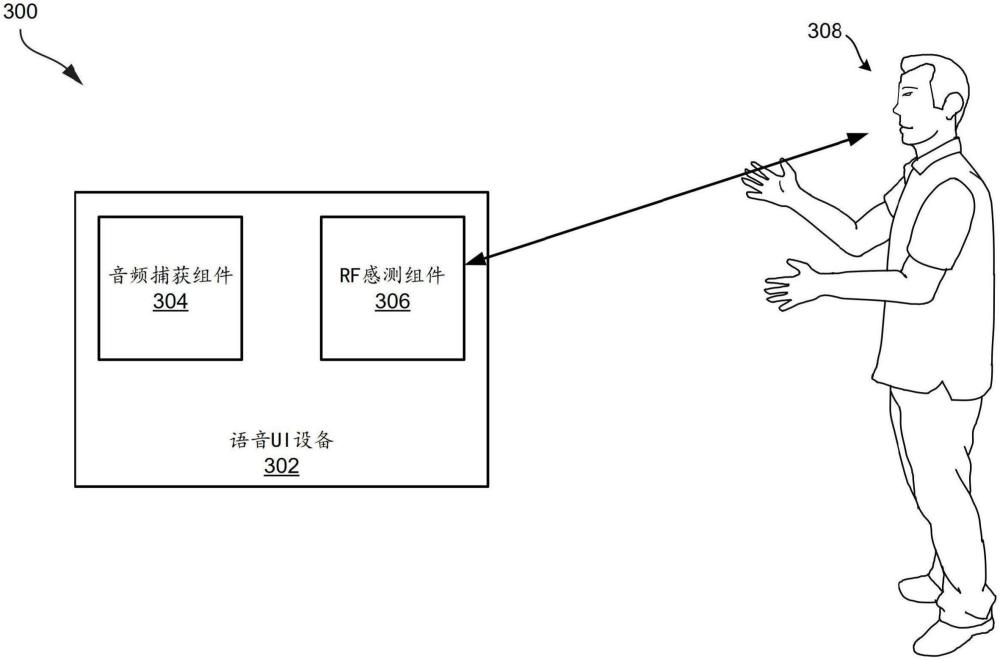
本公開總體上涉及由語音用戶接口(ui)設備使用射頻(rf)感測來增強語音識別。在一些示例中,本公開的各方面涉及用于從環境獲得rf數據以增強由環境內的說話實體發布的語音命令的歧義消除的系統和技術。
背景技術:
1、存在能夠從用戶接收音頻輸入、將音頻輸入轉換成一個或多個命令、并基于命令執行一個或多個動作的設備。然而,在某些場景中,其中存在這樣的設備的環境可能經歷增加的噪聲量,這可能使命令模糊,從而使設備不能有效地執行所請求的一個或多個操作。在其他場景中,用戶可能希望向這樣的設備發布命令,而不必以特定音量水平說話以產生可由這樣的設備的音頻輸入組件獲得的命令。
2、為了實現各種功能,電子設備可以包括被配置為發送和接收射頻(rf)信號的硬件和軟件組件。例如,無線設備可以被配置為經由wi-fi、5g/新無線電(nr)、藍牙tm(bluetoothtm)和/或超寬帶(uwb)、毫米波(mmwave)等進行通信。
技術實現思路
1、在一些示例中,描述了用于由射頻(rf)感測輔助的語音識別的系統和技術。根據至少一個說明性示例,提供了一種用于由射頻(rf)感測輔助的語音識別的方法。該方法包括:在語音用戶接口(ui)設備處獲得包括來自說話實體的語音命令的音頻數據;獲得對應于所述音頻數據的rf感測數據;處理所述音頻數據以確定音頻語音命令輸出;處理所述rf感測數據以確定rf感測語音命令輸出;基于所述音頻語音命令輸出和所述rf感測語音命令輸出,來確定所述語音命令;以及在語音ui設備處基于語音命令執行操作。
2、在另一說明性示例中,提供了一種用于由射頻(rf)感測輔助的語音識別的裝置,其包括存儲器設備和耦合到存儲器設備的處理器。處理器被配置為:在語音用戶接口(ui)設備處獲得包括來自說話實體的語音命令的音頻數據;獲得對應于所述音頻數據的rf感測數據;處理所述音頻數據以確定音頻語音命令輸出;處理所述rf感測數據以確定rf感測語音命令輸出;基于所述音頻語音命令輸出和所述rf感測語音命令輸出,來確定所述語音命令;以及在語音ui設備處基于語音命令執行操作。
3、在另一說明性示例中,提供了一種非暫時性計算機可讀介質,其上存儲有指令,所述指令在由一個或多個處理器執行時,使得所述一個或多個處理器:在語音用戶接口(ui)設備處獲得包括來自說話實體的語音命令的音頻數據;獲得對應于所述音頻數據的rf感測數據;處理所述音頻數據以確定音頻語音命令輸出;處理所述rf感測數據以確定rf感測語音命令輸出;基于所述音頻語音命令輸出和所述rf感測語音命令輸出,來確定所述語音命令;以及在語音ui設備處基于語音命令執行操作。
4、在另一說明性示例中,提供了一種用于由射頻(rf)感測輔助的語音識別的裝置,其包括:用于在語音用戶接口(ui)設備處獲得包括來自說話實體的語音命令的音頻數據的部件;用于獲得對應于所述音頻數據的rf感測數據的部件;用于處理所述音頻數據以確定音頻語音命令輸出的部件;用于處理所述rf感測數據以確定rf感測語音命令輸出的部件;用于基于所述音頻語音命令輸出和所述rf感測語音命令輸出、來確定所述語音命令的部件;以及用于在語音ui設備處基于語音命令執行操作的部件。
5、在一些方面中,本文描述的裝置中的一個或多個是移動或無線通信設備(例如,移動電話或其他移動設備)、擴展現實(xr)設備或系統(例如,虛擬現實(vr)設備、增強現實(ar)設備、或混合現實(mr)設備)、可穿戴設備(例如,網絡連接手表或其他可穿戴設備)、車輛或車輛的計算設備或組件、相機、個人計算機、膝上型計算機、服務器計算機或服務器設備(例如,基于邊緣或云的服務器、充當服務器設備的個人計算機、充當服務器設備的諸如移動電話的移動設備、充當服務器設備的xr設備、充當服務器設備的車輛、網絡路由器、或充當服務器設備的其他設備)、其任何組合、和/或其他類型的設備。在一些方面,裝置包括用于捕獲一個或多個圖像的相機或多個相機。在一些方面,裝置包括用于顯示一個或多個圖像、通知和/或其他可顯示數據的顯示器。在一些方面,裝置可以包括一個或多個傳感器(例如,一個或多個rf傳感器),例如一個或多個陀螺儀、一個或多個陀螺測試儀、一個或多個加速度計、其任何組合、和/或其他傳感器。
6、本
技術實現要素:
不旨在標識所要求保護的主題的關鍵或必要特征,也不旨在單獨用于確定所要求保護的主題的范圍。應當通過參考本專利的整個說明書、任何或所有附圖、和每一權利要求的合適部分,來理解本主題。
7、通過參考以下說明書、權利要求和附圖,前述內容、連同其他特征和示例將變得更加明顯。
技術特征:
1.一種用于由射頻(rf)感測輔助的語音識別的方法,包括:
2.根據權利要求1所述的方法,其中:
3.根據權利要求1所述的方法,其中:
4.根據權利要求1所述的方法,其中:
5.根據權利要求1所述的方法,其中,所述rf感測數據包括用于包括所述說話實體的環境的深度圖信息。
6.根據權利要求5所述的方法,其中:
7.根據權利要求6所述的方法,其中,所述特征信息至少部分地對應于所述說話實體的舌頭。
8.根據權利要求6所述的方法,其中,所述特征信息至少部分地對應于所述說話實體的嘴唇。
9.根據權利要求6所述的方法,還包括:在處理所述rf感測數據之前,對所述rf感測數據進行濾波以獲得經濾波的rf感測數據,其中,所述經濾波的rf感測數據包括所述嘴部區域數據,而沒有來自所述環境的其他rf感測環境數據。
10.根據權利要求1所述的方法,其中,確定所述語音命令包括提供所述語音命令的缺失部分,以便確定要執行的一個或多個操作。
11.根據權利要求1所述的方法,其中:
12.根據權利要求1所述的方法,其中,處理所述rf感測數據包括將所述rf感測數據提供給經訓練的機器學習(ml)模型,以確定所述rf感測語音命令輸出。
13.根據權利要求12所述的方法,還包括:在處理所述rf感測數據之前,從對應于不同言語圖案的多個經訓練的ml模型中選擇所述經訓練的ml模型。
14.根據權利要求12所述的方法,其中,使用包括多個語音命令關鍵字的語音命令數據集,來訓練所述經訓練的ml模型。
15.根據權利要求1所述的方法,還包括:在獲得所述rf感測數據之前,朝向包括所述說話實體的環境發送rf信號,其中,所述rf信號由rf感測組件發送,并且其中,所述rf感測數據基于所發送的rf信號從所述說話實體的一個或多個反射。
16.根據權利要求15所述的方法,其中,從所述rf感測組件的角度來看,所述說話實體被遮擋。
17.根據權利要求15所述的方法,其中,所述語音ui設備包括所述rf感測組件。
18.根據權利要求1所述的方法,還包括:
19.根據權利要求1所述的方法,其中所述rf感測數據包括深度圖信息,并且其中處理所述rf感測數據包括:
20.根據權利要求19所述的方法,其中,所述二維數據是通過使所述深度圖信息平坦化而獲得的。
21.根據權利要求19所述的方法,其中,所述二維數據是從相機獲得的。
22.根據權利要求1所述的方法,其中處理所述rf感測數據包括:
23.一種用于由射頻(rf)感測輔助的語音識別的裝置,所述裝置包括:
24.根據權利要求23所述的裝置,其中:
25.根據權利要求23所述的裝置,其中:
26.根據權利要求23所述的裝置,其中:
27.根據權利要求23所述的裝置,其中,所述rf感測數據包括用于包括所述說話實體的環境的深度圖信息。
28.根據權利要求27所述的裝置,其中:
29.根據權利要求28所述的裝置,其中,所述特征信息至少部分地對應于所述說話實體的舌頭。
30.根據權利要求28所述的裝置,其中,所述特征信息至少部分地對應于所述說話實體的嘴唇。
31.根據權利要求28所述的裝置,其中所述至少一個處理器還被配置為:在處理所述rf感測數據之前,對所述rf感測數據進行濾波以獲得經濾波的rf感測數據,其中所述經濾波的rf感測數據包括所述嘴部區域數據,而沒有來自所述環境的其他rf感測環境數據。
32.根據權利要求23所述的裝置,其中,所述至少一個處理器還被配置為通過提供所述語音命令的缺失部分來確定所述語音命令,以便確定要執行的一個或多個操作。
33.根據權利要求23所述的裝置,其中:
34.根據權利要求23所述的裝置,其中,為了處理所述rf感測數據,所述至少一個處理器還被配置為將所述rf感測數據提供給經訓練的機器學習(ml)模型,以確定所述rf感測語音命令輸出。
35.根據權利要求34所述的裝置,其中,所述至少一個處理器還被配置為在處理所述rf感測數據之前,從對應于不同言語圖案的多個經訓練的ml模型中選擇經訓練的ml模型。
36.根據權利要求34所述的裝置,其中,使用包括多個語音命令關鍵字的語音命令數據集,來訓練所述經訓練的ml模型。
37.根據權利要求23所述的裝置,其中,所述至少一個處理器還被配置成:在獲得所述rf感測數據之前,朝向包括所述說話實體的環境發送rf信號,其中,所述rf信號由rf感測組件發送,并且其中,所述rf感測數據基于所發送的rf信號從所述說話實體的一次或多次反射。
38.根據權利要求37所述的裝置,其中,從所述rf感測組件的角度來看,所述說話實體被遮擋。
39.根據權利要求37所述的裝置,其中,所述語音ui設備包括所述rf感測組件。
40.根據權利要求23所述的裝置,其中,所述至少一個處理器還被配置為:
41.根據權利要求23所述的裝置,其中:
42.根據權利要求41所述的裝置,其中,所述二維數據是通過使所述深度圖信息平坦化而獲得的。
43.根據權利要求41所述的裝置,其中,所述二維數據是從相機獲得的。
44.根據權利要求23所述的裝置,其中,為了處理所述rf感測數據,所述處理器還被配置為:
技術總結
提供了用于由射頻(RF)感測輔助的語音識別的系統和技術。例如,用于由射頻(RF)感測輔助的語音識別的處理可以包括:在語音用戶接口(UI)設備處獲得包括來自說話實體的語音命令的音頻數據;獲得對應于所述音頻數據的RF感測數據;處理所述音頻數據以確定音頻語音命令輸出;處理所述RF感測數據以確定RF感測語音命令輸出;基于所述音頻語音命令輸出和所述RF感測語音命令輸出,來確定所述語音命令;以及在所述語音UI設備處基于所述語音命令執行操作。
技術研發人員:B·拉馬薩米,J·菲洛斯,E·C·帕克,張小欣
受保護的技術使用者:高通股份有限公司
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!