一種語音數據的處理方法和電子設備與流程
本技術涉及數據處理,尤其涉及一種語音數據的處理方法和電子設備。
背景技術:
1、在語音數據處理領域,可以通過深度學習來實現。通常情況下,深度學習模型支持的采樣率在訓練階段已經確定,那么在應用階段,只能對與模型支持的采樣率相同的采樣率進行采樣的語音數據行處理,如果對其他采樣率進行采樣的語音數據進行處理,則可能致處理的語音數據無法使用。
2、現有技術中通常有兩種處理方式,一種處理方式中,可以訓練多個支持不同采樣率的模型,但是這種方式需要準備不同采樣率的訓練樣本,工作量大,而且同時集成多個模型還會導致安裝包很大。另一種處理方式中,當輸入的語音數據的采樣率大于模型支持的采樣率時,對輸入的語音數據進行降采樣,然后經過模型處理后,再把降采樣的語音數據升采樣到原來的采樣率,但是,這樣處理會損失高頻成分,降低語音質量。
技術實現思路
1、本技術示例性的實施方式中提供一種語音數據的處理方法和電子設備,用以實現通過一個訓練好的模型適用不同采樣率的輸入的語音數據,不會損失高頻成分,也不會降低語音質量;一個模型的安裝包較小,減少移動端的安裝資源。
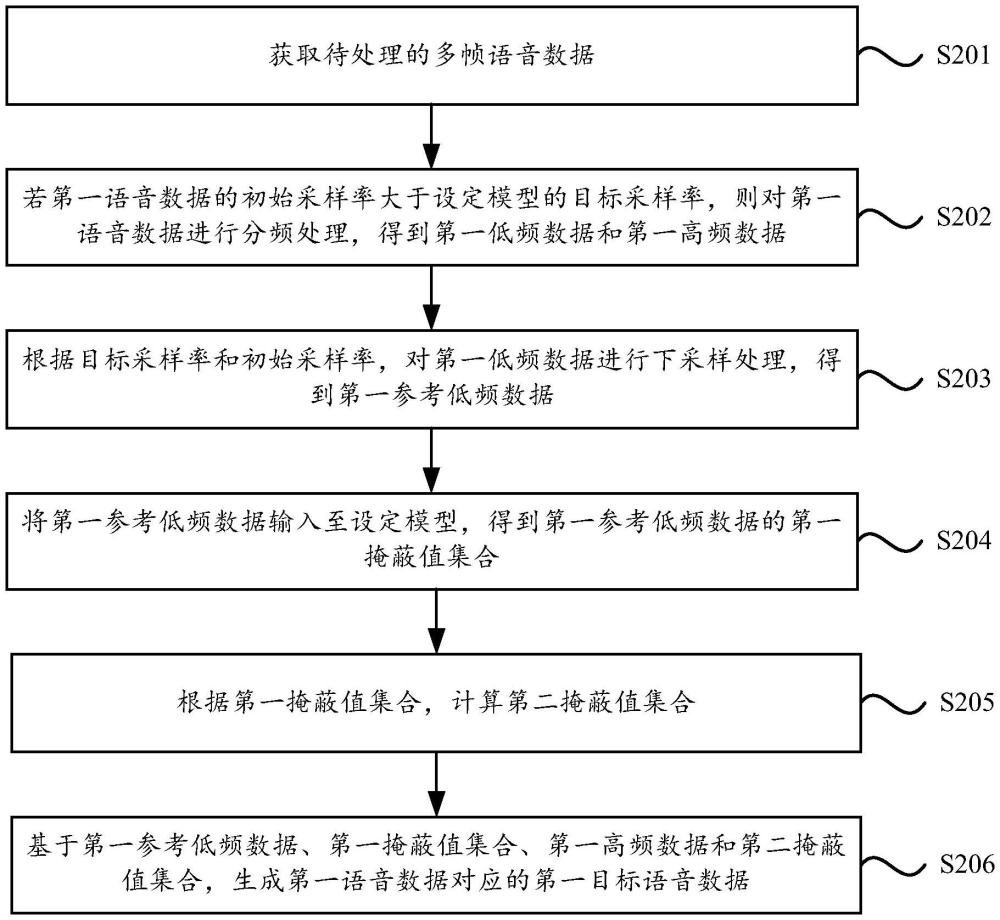
2、根據示例性的實施方式中的第一方面,提供一種語音數據的處理方法,包括:
3、獲取待處理的多幀語音數據;
4、若第一語音數據的初始采樣率大于設定模型的目標采樣率,則對第一語音數據進行分頻處理,得到第一低頻數據和第一高頻數據;其中,設定模型為用于對第一語音數據進行優化處理的模型;第一語音數據為待處理的多幀語音數據中的任意一幀;
5、根據目標采樣率和初始采樣率,對第一低頻數據進行下采樣處理,得到第一參考低頻數據;其中,第一參考低頻數據的采樣率和目標采樣率相同;
6、將第一參考低頻數據輸入至設定模型,得到第一參考低頻數據的第一掩蔽值集合;其中,第一掩蔽值集合用于描述第一低頻數據的幅度譜特性;
7、根據第一掩蔽值集合,計算第二掩蔽值集合;其中,第二掩蔽值集合用于描述第一高頻數據的幅度譜特性;
8、基于第一參考低頻數據、第一掩蔽值集合、第一高頻數據和第二掩蔽值集合,生成第一語音數據對應的第一目標語音數據。
9、本技術實施例,針對待處理的多幀語音數據中的任意一幀,以第一語音數據為例,當第一語音數據的初始采樣率大于設定模型的目標采樣率時,如果直接進行下采樣處理后輸入設定模型,根據設定模型的輸出再進行升采樣處理,這樣得到的處理結果可能損失高頻成分,降低語音數量。因此,可以對第一語音數據進行分頻處理,得到第一低頻數據和第一高頻數據,進而針對第一低頻數據和第一高頻數據執行不同的操作。其中,針對第一低頻數據,可以根據目標采樣率和初始采樣率進行下采樣處理,得到和目標采樣率相同的第一參考低頻數據,進而將第一參考低頻數據輸入至設定模型得到第一參考低頻數據的第一掩蔽值集合,該第一掩蔽值集合用來描述第一低頻數據的幅度譜特性。針對第一高頻數據,為了不損失高頻成分,第一高頻數據無需輸入設定迷行,直接根據第一掩蔽值集合來計算第二掩蔽值集合。這樣,可以基礎第一參考低頻數據、第一掩蔽值集合、第一高頻數據和第二掩蔽值集合,生成第一語音數據對應的第一目標語音數據同一個模型可以支持多種采樣率。應用本技術實施例的方法,一個模型可以適用不同采樣率的輸入語音數據,并且還可以不損失高頻成分,不會降低語音質量。另外,無需每種采樣率都訓練一個模型的方式還減少模型訓練時間以及準備訓練數據的時間,減少安裝包的大小,降低移動端的安裝資源。
10、在一種可選的實施方式中,對第一語音數據進行分頻處理,得到第一低頻數據和第一高頻數據,包括:
11、將第一語音數據輸入至低通濾波器,得到第一低頻數據;
12、將第一語音數據輸入至高通濾波器,得到第一高頻數據;
13、其中,低通濾波器和高通濾波器各自的截止頻率分別是根據目標采樣率確定的。
14、上述實施例,為了不損失高頻成分,優先對第一語音數據進行分頻處理,這樣可以針對得到的第一高頻數據和第一低頻數據采用不同的后續處理方式。
15、在一種可選的實施方式中,將第一參考低頻數據輸入至設定模型,得到第一參考低頻數據的第一掩蔽值集合,包括:
16、將第一低頻數據和第二低頻數據進行拼接,得到低頻拼接數據;其中,第二低頻數據為第二語音數據對應的低頻數據,第二語音數據為第一語音數據的上一幀語音數據;若第一語音數據為初始幀,則第二語音數據為第一預設語音數據;
17、對低頻拼接數據進行加窗操作以及快速傅里葉變換fff操作,得到第一變換低頻數據;
18、將第一變換低頻數據輸入至設定模型,得到第一參考低頻數據的第一掩蔽值集合。
19、上述實施例,將第一參考低頻數據的第一掩蔽值集合和第一高頻數據的第二掩蔽值集合采用不同的方式計算。其中,第一掩蔽值集合的過程中,綜合考慮時延、計算復雜度和效果,選擇與上一幀語音數據進行拼接,而后對低頻拼接數據進行相應的操作。這樣得到的第一掩蔽值集合能更準確的描述第一參考低頻數據的幅度譜特性。
20、在一種可選的實施方式中,方法還包括:
21、將第一高頻數據和第二高頻數據進行拼接,得到高頻拼接數據;其中,第二高頻數據為第二語音數據對應的高頻數據,第二語音數據為第一語音數據的上一幀語音數據;若第一語音數據為初始幀,則第二語音數據為第二預設語音數據;
22、對高頻拼接數據進行加窗操作以及fft操作,得到第一變換高頻數據。
23、上述實施例,綜合考慮時延、計算復雜度和效果,選擇與上一幀語音數據進行拼接,而后對高頻拼接數據進行相應的操作。利用這樣得到的第一變換高頻數據來計算第二掩蔽值集合,得到的第二掩蔽值集合能更準確的描述第一高頻數據的幅度譜特性。
24、在一種可選的實施方式中,基于第一參考低頻數據、第一掩蔽值集合、第一高頻數據和第二掩蔽值集合,生成第一語音數據對應的第一目標語音數據,包括:
25、將第一變換低頻數據與第一掩蔽值集合相乘,得到第一掩蔽低頻數據,并對第一掩蔽低頻數據進行快速傅里葉逆變換ifft操作和加權折疊相加wola操作,得到第一目標低頻數據;
26、對第一目標低頻數據進行插值處理;其中,插值倍數是根據初始采樣率和目標采樣率確定的;
27、將插值后的第一目標低頻數據輸入至低通濾波器,得到第一濾波低頻數據;
28、將第一變換高頻數據與第二掩蔽值集合相乘,得到第一掩蔽高頻數據,并對第一掩蔽敢拼數據進行ifft操作和wola操作,得到第一目標高頻數據;
29、合成第一濾波低頻數據和第一目標高頻數據,得到第一語音數據對應的第一目標語音數據。
30、上述實施例,由于進行了分頻處理,還需要進行混頻處理。因此,在混頻處理的過程中,第一參考低頻數據和第一高頻數據分別與自身對應的第一掩蔽值集合和第二掩蔽值集合相乘,并且,由于第二掩蔽值集合的計算過程無需經過設定模型,這樣,保證合成后的第一目標語音數據不損失高頻成分。另外,ifft和wola操作可以進一步保證合成的第一目標數據的準確性。
31、在一種可選的實施方式中,根據第一掩蔽值集合,計算第二掩蔽值集合,包括:
32、選取第一掩蔽值集合中的部分掩蔽值進行計算,得到基準掩蔽值;其中,第一掩蔽值集合中的掩蔽值的個數為第一參考低頻數據的頻域點數;
33、根據基準掩蔽值、設定常數、第一高頻數據的頻域點數,計算第二掩蔽值集合;其中,第一高頻數據的頻域點數是根據第一參考低頻數據的頻域點數,以及初始采樣率和目標采樣率的關系確定的。
34、上述實施例,將第一參考低頻數據的第一掩蔽值集合和第一高頻數據的第二掩蔽值集合采用不同的方式計算。其中,第二掩蔽值集合的計算過程中,為了不損失高頻成分,無需將第一高頻數據輸入設定模型,而是利用第一掩蔽值集合來計算第二掩蔽值集合。該過程中考慮了第一參考低頻數據的頻域點數和第一高頻數據的頻域點數的關系。這樣,得到的第二掩蔽值集合在進行混頻時,能更好的還原高頻成分。
35、在一種可選的實施方式中,通過如下公式計算第二掩蔽值集合中的每個第二掩蔽值;
36、index=constcoeff+i/len;
37、highfreq_mask[i]=powf(base_mask,index);
38、其中,highfreq_mask[i]為第i個第二掩蔽值,powf為冪函數,base_mask為基準掩蔽值,constcoeff為設定常數,len為第一高頻數據的頻域點數,i為任意一個第二掩蔽值的編號。
39、上述實施例,通過第一掩蔽值集合計算出一個基準掩蔽值,在計算第二掩蔽值集合中的每個第二掩蔽值時,可以利用該基準掩蔽值。這樣計算的第二掩蔽值集合無需經過設定模型,不損失高頻成分,保證語音質量。
40、根據示例性的實施方式中的第二方面,提供一種電子設備,包括處理器和存儲器;
41、存儲器,被配置為執行:
42、存儲設定模型;
43、處理器,被配置為執行:
44、獲取待處理的多幀語音數據;
45、若第一語音數據的初始采樣率大于設定模型的目標采樣率,則對第一語音數據進行分頻處理,得到第一低頻數據和第一高頻數據;其中,設定模型為用于對第一語音數據進行優化處理的模型;第一語音數據為待處理的多幀語音數據中的任意一幀;
46、根據目標采樣率和初始采樣率,對第一低頻數據進行下采樣處理,得到第一參考低頻數據;其中,第一參考低頻數據的采樣率和目標采樣率相同;
47、將第一參考低頻數據輸入至設定模型,得到第一參考低頻數據的第一掩蔽值集合;其中,第一掩蔽值集合用于描述第一低頻數據的幅度譜特性;
48、根據第一掩蔽值集合,計算第二掩蔽值集合;其中,第二掩蔽值集合用于描述第一高頻數據的幅度譜特性;
49、基于第一參考低頻數據、第一掩蔽值集合、第一高頻數據和第二掩蔽值集合,生成第一語音數據對應的第一目標語音數據。
50、根據示例性的實施方式中的第三方面,提供一種語音數據的處理裝置,包括:
51、處理單元,用于:獲取待處理的多幀語音數據;
52、處理單元,還用于:若第一語音數據的初始采樣率大于設定模型的目標采樣率,則對第一語音數據進行分頻處理,得到第一低頻數據和第一高頻數據;其中,設定模型為用于對第一語音數據進行優化處理的模型;第一語音數據為待處理的多幀語音數據中的任意一幀;
53、重采樣單元,用于:根據目標采樣率和初始采樣率,對第一低頻數據進行下采樣處理,得到第一參考低頻數據;其中,第一參考低頻數據的采樣率和目標采樣率相同;
54、處理單元,還用于:將第一參考低頻數據輸入至設定模型,得到第一參考低頻數據的第一掩蔽值集合;其中,第一掩蔽值集合用于描述第一低頻數據的幅度譜特性;
55、處理單元,還用于:根據第一掩蔽值集合,計算第二掩蔽值集合;其中,第二掩蔽值集合用于描述第一高頻數據的幅度譜特性;
56、合成單元,用于:基于第一參考低頻數據、第一掩蔽值集合、第一高頻數據和第二掩蔽值集合,生成第一語音數據對應的第一目標語音數據。
57、根據示例性的實施方式中的第四方面,提供一種計算機存儲介質,計算機存儲介質中存儲有計算機程序指令,當指令在計算機上運行時,使得計算機執行如第一方面的語音數據的處理方法。
- 還沒有人留言評論。精彩留言會獲得點贊!