基于對話內容生成實時音頻的方法、系統及電子設備與流程
本申請涉及人工智能,尤其涉及一種基于對話內容生成實時音頻的方法、系統及電子設備。
背景技術:
1、隨著人工智能技術的發展,人機對話的應用場景已普遍出現在日常生活中的方方面面。現有的人機對話場景主要集中于根據人機對話內容生成文本內容并顯示,而缺少結合人機對話內容生成符合對話場景、氛圍的音效的能力,無法為用戶提供更為沉浸的使用體驗與交互體驗。
技術實現思路
1、有鑒于此,本申請實施例提供了一種基于對話內容生成實時音頻的方法、系統及電子設備,以實現實時根據人機交互場景、交互內容生成適配的音效,以向用戶提供更為沉浸的使用體驗與交互體驗。
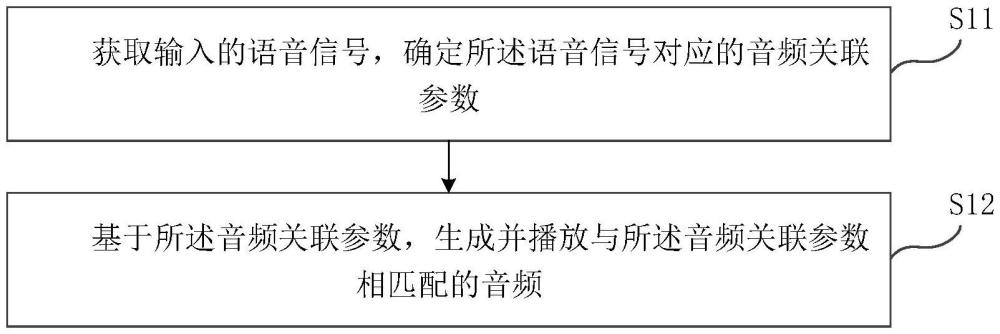
2、第一方面,本申請實施例提供了一種基于對話內容生成實時音頻的方法,其中,該方法包括:
3、獲取輸入的語音信號,確定所述語音信號對應的音頻關聯參數,其中,所述音頻關聯參數包括:主題類型、情感傾向、交互位置、交互時間、交互事件類型;其中,所述交互事件類型為預先根據所述交互位置設定的互動任務;
4、基于所述音頻關聯參數,生成并播放與所述音頻關聯參數相匹配的音頻。
5、在一些可能的實施例中,所述基于所述音頻關聯參數,生成并播放與所述音頻關聯參數相匹配的音頻,包括:
6、將所述音頻關聯參數,輸入至預設背景音樂生成算法模型中,由所述預設背景音樂生成算法模型生成多個初始音樂片段;
7、基于用戶的身份標簽信息,將與所述用戶的身份標簽信息相對應的初始音樂片段確定為初始音樂。
8、在一些可能的實施例中,所述方法還包括:
9、按照預設采樣間隔,獲取所述輸入的語音信號并進行解析,確定各采樣間隔對應的音頻關聯系數;
10、并基于各采樣間隔對應的音頻關聯系數,結合預設過程音樂生成算法模型,生成不同采樣間隔對應的過程音樂片段;
11、按照所述采樣間隔順序,將各所述過程音樂片段進行前后銜接得到過程音樂。
12、在一些可能的實施例中,所述方法還包括:
13、基于預先訓練得到的音效匹配模型確定出匹配的音效聲音組合,其中,所述音效聲音組合中包括多個音效,其中,所述音效聲音組合中的各音效與所述交互事件類型的存在關聯關系;
14、在持續不停頓播放所述初始音樂、所述過程音樂的過程中,在不同的過程音樂片段之間的間隙中嵌入并播放與所述交互事件類型相匹配的目標音效。
15、在一些可能的實施例中,所述方法還包括:
16、實時獲取輸入的語音信號的聲音強度,若所述聲音強度低于預設聲音強度閾值,按照預設聲音強度下調比例,降低播放的音頻的聲音強度。
17、在一些可能的實施例中,所述方法還包括:
18、若所述互動任務發生變更,終止當前交互任務相關聯的音頻,切換并播放變更后的新交互任務對應的音頻。
19、在一些可能的實施例中,所述主題類型通過如下方式確定:
20、根據預設的語音轉文字函數,將所述輸入的語音信號轉換為目標文本內容;
21、基于所述目標文本內容進行語義分析,提取所述目標文本內容中包含的與預設主題類型相關的關聯詞匯;
22、根據所述關聯詞匯,確定與所述關聯詞匯之間的關聯程度最高的主題類型為所述語音信號對應的主題類型;
23、所述情感傾向,通過如下方式確定:
24、獲取所述語音信號的音頻特征,所述音頻特征包括:語速、音量、音高;
25、基于基準語速、基準音量、基準音高,對所述語音特征進行歸一化處理得到歸一化的音頻系數;
26、根據所述音頻系數結合預設情感傾向標簽信息,計算目標情感傾向分,并基于所述目標情感傾向分確定所述語音信號對應的情感傾向。
27、第二方面,本申請提供了一種基于對話內容生成實時音頻的系統,其中,所述系統包括:
28、獲取模塊,用于獲取輸入的語音信號,確定所述語音信號對應的音頻關聯參數,其中,所述音頻關聯參數包括:主題類型、情感傾向、交互位置、交互時間、交互事件類型;其中,所述交互事件類型為預先根據所述交互位置設定的互動任務;
29、音頻生成播放模塊,用于基于所述音頻關聯參數,生成并播放與所述音頻關聯參數相匹配的音頻。
30、第三方面,本申請實施例提供了一種電子設備,其中,所述電子設備包括:處理器;以及存儲程序的存儲器;其中,所述程序包括指令,所述指令在由所述處理器執行時使所述處理器執行第一方面所述的基于對話內容生成實時音頻的方法。
31、第四方面,本申請實施例提供了一種存儲有計算機指令的非瞬時計算機可讀存儲介質,其特征在于,所述計算機指令用于使計算機執行第一方面所述的基于對話內容生成實時音頻的方法。
32、本申請的有益效果:
33、本申請實施例提供了一種基于對話內容生成實時音頻的方法、系統及電子設備,其中,該方法通過獲取輸入的語音信號,并確定出語音信號對應的主題類型、情感傾向、交互位置、交互時間、交互事件類型等音頻關聯參數,然后基于確定得到的音頻關聯參數生成并播放與音頻相匹配的音頻。選用本申請實施例,可實時根據人機交互的語音信號的主題類型、情感傾向、交互位置、交互時間、交互事件類型等具體的音頻關聯參數,并生成相匹配的音頻并播放,可生成與當前對話場景、氛圍相匹配的音效,對于一些需要類似游樂園、主題公園、展覽館等側重交互體驗的場景,選用本申請實施例可為用戶提供更為沉浸的使用體驗與交互體驗。
技術特征:
1.一種基于對話內容生成實時音頻的方法,其特征在于,所述方法包括:
2.根據權利要求1所述的方法,其特征在于,所述基于所述音頻關聯參數,生成并播放與所述音頻關聯參數相匹配的音頻,包括:
3.根據權利要求2所述的方法,其特征在于,所述方法還包括:
4.根據權利要求3所述的方法,其特征在于,所述方法還包括:
5.根據權利要求1所述的方法,其特征在于,所述方法還包括:
6.根據權利要求1所述的方法,其特征在于,所述方法還包括:
7.根據權利要求1所述的方法,其特征在于,所述主題類型通過如下方式確定:
8.一種基于對話內容生成實時音頻的系統,其特征在于,所述系統包括:
9.一種電子設備,其特征在于,所述電子設備包括:處理器以及存儲程序的存儲器;其中,所述程序包括指令,所述指令在由所述處理器執行時使所述處理器執行根據權利要求1-7中任一項所述的方法。
10.一種存儲有計算機指令的非瞬時計算機可讀存儲介質,其特征在于,所述計算機指令用于使計算機執行根據權利要求1-7中任一項所述的方法。
技術總結
本申請實施例提供了一種基于對話內容生成實時音頻的方法、系統及電子設備,其中,該方法通過獲取輸入的語音信號,并確定出語音信號對應的主題類型、情感傾向、交互位置、交互時間、交互事件類型等音頻關聯參數,然后基于確定得到的音頻關聯參數生成并播放與音頻相匹配的音頻。選用本申請實施例,可實時根據人機交互的語音信號的主題類型、情感傾向、交互位置、交互時間、交互事件類型等具體的音頻關聯參數,并生成相匹配的音頻并播放,可生成與當前對話場景、氛圍相匹配的音效,對于一些需要類似游樂園、主題公園、展覽館等側重交互體驗的場景,選用本申請實施例可為用戶提供更為沉浸的使用體驗與交互體驗。
技術研發人員:吳卓浩,姜波,徐昕,高晨暉,王超,金準
受保護的技術使用者:北京阿派朗創造力科技有限公司
技術研發日:
技術公布日:2025/4/24
- 還沒有人留言評論。精彩留言會獲得點贊!