一種電力繳費渠道分析的指標(biāo)選擇、權(quán)值優(yōu)化與渠道規(guī)劃的計算方法與流程
本發(fā)明涉及電力系統(tǒng)通信領(lǐng)域,特別是涉及一種電力繳費渠道分析的指標(biāo)選擇、權(quán)值優(yōu)化與渠道規(guī)劃的計算方法。
背景技術(shù):
隨著繳費渠道建設(shè)多樣化、交費方式多元化的發(fā)展,原有電力機構(gòu)營業(yè)所繳費的“單一交費”模式被打破,但在實際生活中,電力機構(gòu)繳費仍然是廣大用戶繳納電費時的首選方式,個別營業(yè)所繳費高峰時人滿為患。用戶繳費習(xí)慣、繳費需求與繳費渠道建設(shè)之間的矛盾凸顯,電費回收隱患、供電服務(wù)隱患、人力資源分配不合理等問題逐漸顯現(xiàn)。
中國政府在美國提出《大數(shù)據(jù)研究和發(fā)展計劃》的2012年也批復(fù)了“十二五國家政務(wù)信息化建設(shè)工程規(guī)劃”,將大數(shù)據(jù)作為建設(shè)重點,總投資額估計在幾百億。2013年發(fā)布《中國電力大數(shù)據(jù)發(fā)展白皮書》,提出了電力大數(shù)據(jù)是能源變革中電力工業(yè)技術(shù)革新的必然過程,而不是簡單的技術(shù)范疇。電力大數(shù)據(jù)不僅僅是技術(shù)進(jìn)步,更是涉及整個電力系統(tǒng)在大數(shù)據(jù)時代下發(fā)展理念、管理體制和技術(shù)路線等方面的重大變革,是下一代智能化電力系統(tǒng)在大數(shù)據(jù)時代下價值形態(tài)的躍升。
在大數(shù)據(jù)環(huán)境下,海量異構(gòu)數(shù)據(jù)批量整合、流式分析及低時延ETL融合技術(shù)是系統(tǒng)關(guān)鍵技術(shù),如何準(zhǔn)確高效的將原始數(shù)據(jù)提煉為KPI指標(biāo)和大數(shù)據(jù)系統(tǒng)的核心能力之一。大數(shù)據(jù)分析模式需要分析繳費渠道評價體系,首先從數(shù)據(jù)和服務(wù)的生產(chǎn)者和消費者角度給出參與大數(shù)據(jù)分析的各種角色,并從整個分析和數(shù)據(jù)生命周期過程中對信息和數(shù)據(jù)進(jìn)行分類,結(jié)合實際業(yè)務(wù)場景,形成數(shù)據(jù)服務(wù)。
因此,通過用戶繳費數(shù)據(jù)地挖掘,發(fā)現(xiàn)數(shù)據(jù)庫中那些看似無關(guān)的交易數(shù)據(jù)交易背后隱藏的某種聯(lián)系,根據(jù)分析結(jié)果可以對用電客戶的繳費進(jìn)行深入的研究分析,發(fā)現(xiàn)對電力公司有價值的渠道,以此來找出最受客戶歡迎的繳費渠道,具有深遠(yuǎn)的意義。
技術(shù)實現(xiàn)要素:
為解決上述技術(shù)問題,本發(fā)明在包含用戶個人信息的調(diào)查數(shù)據(jù)以及供電公司端的數(shù)據(jù)的基礎(chǔ)上,建立個體用戶畫像,并通過用戶典型行為分析、聚類算法及模型建立,可以了解客戶對繳費和相關(guān)業(yè)務(wù)的要求,從而在保持成本或降低成本的同時,提升客戶滿意度。
本發(fā)明的目的是提供一種在電力繳費渠道分析中,可為不同價值客戶制定不同的供電方式提供營銷決策支持并做出預(yù)判的指標(biāo)選擇、權(quán)值優(yōu)化與渠道規(guī)劃的計算方法。
為實現(xiàn)上述發(fā)明目的,本發(fā)明提供的技術(shù)方案是:
一種電力繳費渠道分析的指標(biāo)選擇、權(quán)值優(yōu)化與渠道規(guī)劃的計算方法,包括以下步驟:
步驟一通過SG186系統(tǒng)或調(diào)查問卷獲取繳費用戶基本屬性信息和繳費習(xí)慣屬性信息的數(shù)據(jù);
步驟二采用特征權(quán)重優(yōu)化方法對個體用戶畫像中各權(quán)重進(jìn)行優(yōu)化,得到最優(yōu)個體用戶畫像,通過聚類算法建立群體用戶繳費行為畫像;
步驟三采用K最近鄰分類算法建立指標(biāo)評價體系;
步驟四采用遺傳退火算法,計算各個屬性指標(biāo)的權(quán)重值;
步驟五判斷是否為最優(yōu)值,確定最優(yōu)繳費渠道。
進(jìn)一步地,在步驟一中,用戶的基本屬性信息包括姓名、年齡、性別、家庭住址;繳費習(xí)慣屬性信息包括每次平均繳費金額以及繳費方式的信息。
進(jìn)一步地,在步驟二中,以標(biāo)簽的形式表示個體用戶的性質(zhì)與繳費習(xí)慣,作為個體用戶畫像,特征權(quán)重優(yōu)化方法包括K最近鄰算法和模擬退火算法,隨機設(shè)置各個屬性的初始權(quán)重;基于樣本數(shù)據(jù)集劃分集合測試集,進(jìn)行K近鄰分類計算,遍歷測試集中每條數(shù)據(jù),從訓(xùn)練集中提取距離最近的前K條數(shù)據(jù),與測試數(shù)據(jù)的實際值比較,并統(tǒng)計誤差;進(jìn)行誤差比較,調(diào)整各個屬性的權(quán)重,若誤差小于閾值,則得到各個屬性的權(quán)重,否則,調(diào)整屬性的權(quán)重,進(jìn)行迭代測試,得到各個屬性的權(quán)重。
進(jìn)一步地,在步驟二中,所述聚類算法的原理為將待聚類的屬性數(shù)據(jù)隨機放置一個兩維網(wǎng)格的環(huán)境中,每一個屬性數(shù)據(jù)對象有一個隨機初始位置,每一只螞蟻能夠在網(wǎng)格上移動,并測量當(dāng)前對象在局部環(huán)境的群體相似度,通過概率轉(zhuǎn)換函數(shù)將群體相似度轉(zhuǎn)換成移動對象的概率,以這個概率拾起或放下對象;蟻群聯(lián)合行動導(dǎo)致屬于同一類別的屬性數(shù)據(jù)對象在同一個空間區(qū)域能聚積在一起;
從而使相似的評價因素聚為一類,聚合結(jié)果作為電力系統(tǒng)繳費渠道評價指標(biāo),電力系統(tǒng)繳費渠道評價因素包括渠道的覆蓋率、渠道的利用率、成本、工作效率、用戶繳費行為畫像、便捷性、客戶滿意度、渠道發(fā)展趨勢。
進(jìn)一步地,在步驟三中,所述K最近鄰分類算法包括以下步驟:
對于一個測試集中的測試樣本,根據(jù)特征詞形成測試樣本向量;
計算該測試樣本與訓(xùn)練集中每個樣本的樣本相似度,計算公式為:
其中,di為測試樣本的特征向量,dj為第j類的中心向量;M為特征向量的維數(shù);Wk為向量的第k維;k值的確定先采用一個初始值,然后根據(jù)實驗測試K的結(jié)果調(diào)整K值;
按照樣本相似度,在訓(xùn)練樣本集中選出與測試樣本最相似的k個樣本;
在測試樣本的個k近鄰中,依次計算每類的權(quán)重,計算公式如下:
其中,x為測試樣本的特征向量;Sim(x,di)為相似度計算公式;b為閾值,有待于優(yōu)化選擇;y(di,Cj)的取值為1或0,如果di屬于Cj,則函數(shù)值為1,否則為0;
比較類的權(quán)重,將樣本分到權(quán)重最大的那個類別中。
進(jìn)一步地,在步驟四中,遺傳退火計算方法為:
步驟四a給定模型每一個參數(shù)變化范圍,在這個范圍內(nèi)隨機選擇一個初始模型,并計算相應(yīng)的目標(biāo)函數(shù)值;
步驟四b對當(dāng)前模型進(jìn)行擾動產(chǎn)生一個新模型,計算相應(yīng)的目標(biāo)函數(shù)值,得到
ΔE=E(m)-E(m0);
步驟四c若ΔE<0,則新模型被m接受;若ΔE>0,則新模型m按概率P=exp(-ΔE/T)進(jìn)行接受,T為外界影響因素,當(dāng)模型被接受時,置m0=m;
步驟四d在外界影響因素T下,重復(fù)一定次數(shù)的擾動和接受過程,即重復(fù)步驟四b和步驟四c;
步驟四e緩慢降低外界影響因素T;
步驟四f重復(fù)步驟四b和四e,直至收斂條件滿足為止。
進(jìn)一步地,在步驟五中,最優(yōu)值的判斷公式為|ΔE|=|E(m)-E(m0)|≤0
其中,ΔE表示渠道最優(yōu)解;E(m)表示計算的渠道值,E(m0)表示初始渠道值。
采用上述技術(shù)方案,本發(fā)明具有如下有益效果:
第一,本發(fā)明采用特征權(quán)重優(yōu)化的方式優(yōu)化用戶畫像的權(quán)重,特征權(quán)重優(yōu)化既作為數(shù)據(jù)挖掘的預(yù)處理階段,又將這它與具體的數(shù)據(jù)挖掘算法結(jié)合起來,從而構(gòu)造出簡潔、精確、穩(wěn)定的數(shù)據(jù)挖掘計算方法。
第二,在本發(fā)明中,通過聚類算法把相似屬性的客戶聚為一類,而不同類里的客戶的屬性則不同,并分別建立每一類客戶的模型。該模型可運用于后續(xù)軟件對未來數(shù)據(jù)的預(yù)測以及對用戶偏好的分析和繳費渠道建設(shè)的決斷。
第三,本發(fā)明在用戶繳費大數(shù)據(jù)的基礎(chǔ)上,破解營業(yè)網(wǎng)點布局不合理、營業(yè)窗口設(shè)置不靈活、人力資源配置不平衡、電費回收存在風(fēng)險、費控協(xié)議簽訂緩慢的難題,提高營銷電費回收工作的精益化管理水平,最終實現(xiàn)讓用戶方便繳費、讓用戶滿意的繳費服務(wù)渠道。
附圖說明
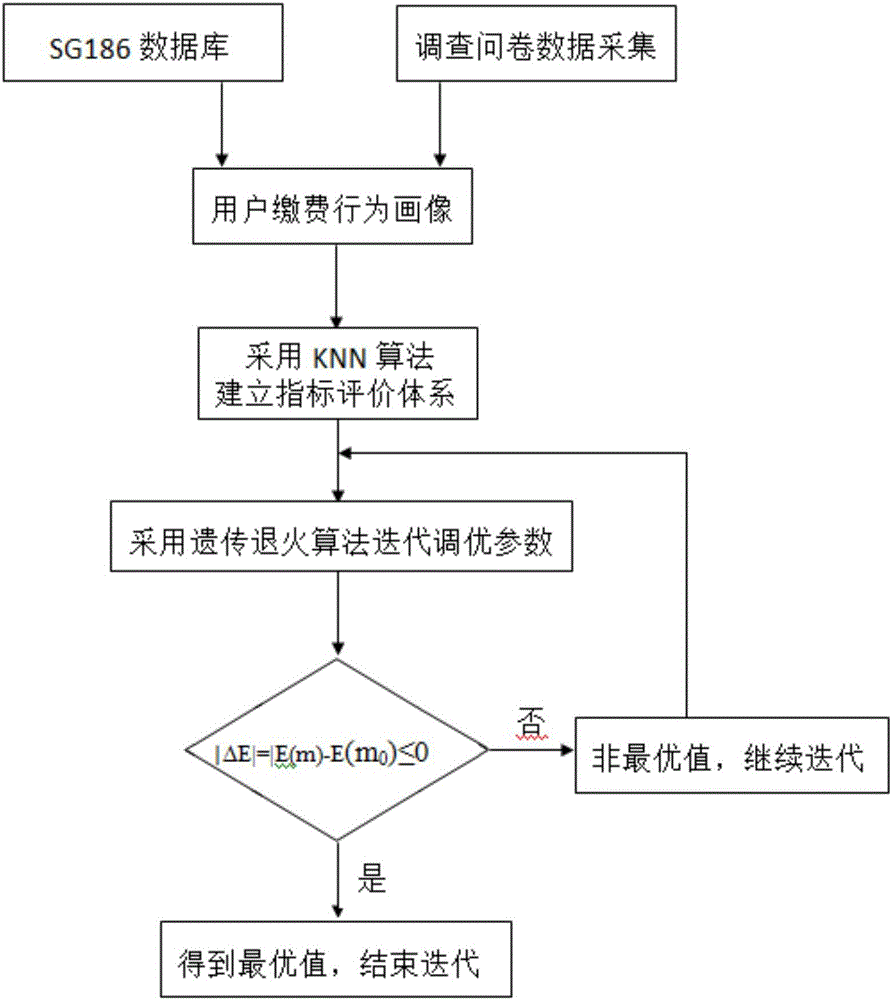
圖1為本發(fā)明電力繳費渠道分析的指標(biāo)選擇、權(quán)值優(yōu)化與渠道規(guī)劃的計算方法的流程圖;
圖2為本發(fā)明KNN算法的流程圖;
圖3為基于KNN和模擬退火算法的權(quán)重優(yōu)化的流程圖;
圖4為聚類算法的流程圖;
圖5為遺傳退火算法流程圖。
具體實施方式
為了使本發(fā)明的目的、技術(shù)方案及優(yōu)點更加清楚明白,下面結(jié)合附圖及實施例,對本發(fā)明進(jìn)行進(jìn)一步詳細(xì)說明。應(yīng)當(dāng)理解,此處所描述的結(jié)構(gòu)圖及具體實施例僅用以解釋本發(fā)明,并不用于限定本發(fā)明。
實施例1
圖1為本發(fā)明電力繳費渠道分析的指標(biāo)選擇、權(quán)值優(yōu)化與渠道規(guī)劃的計算方法的流程圖,如圖1所示,一種電力繳費渠道分析的指標(biāo)選擇、權(quán)值優(yōu)化與渠道規(guī)劃的計算方法,包括以下步驟:
步驟一通過SG186系統(tǒng)或調(diào)查問卷獲取繳費用戶基本屬性信息和繳費習(xí)慣屬性信息的數(shù)據(jù);
步驟二采用特征權(quán)重優(yōu)化方法對個體用戶畫像中各權(quán)重進(jìn)行優(yōu)化,得到最優(yōu)個體用戶畫像,通過聚類算法建立群體用戶繳費行為畫像;
步驟三采用K最近鄰分類算法建立指標(biāo)評價體系,
步驟四采用遺傳退火算法,計算各個屬性指標(biāo)的權(quán)重值;
步驟五判斷是否為最優(yōu)值,確定最優(yōu)繳費渠道。
實施例2
獲得繳費用戶基本屬性信息和繳費習(xí)慣屬性信息的數(shù)據(jù)
繳費客戶群體調(diào)研目的是客觀地收集繳費客戶的研究數(shù)據(jù),為后續(xù)工作做準(zhǔn)備。調(diào)研對象主要是以家庭為單位的電費繳納客戶,每一戶以電網(wǎng)用戶編號表示。調(diào)研方式為問卷調(diào)查和供電公司提供數(shù)據(jù)研究相結(jié)合為主。
問卷調(diào)查主要采集了用戶的姓名、年齡、性別、家庭住址、繳費習(xí)慣信息,并結(jié)合供電公司提供的用戶繳費信息,建立個體用戶畫像。具體如下:
姓名:由用戶編號代替
年齡:根據(jù)家庭平均年齡及家庭每人繳費權(quán)重分析,把電費繳納戶劃分為三種,分別為
性別:用編號代替(男:0,女:1)
家庭住址:在問卷調(diào)查和提供數(shù)據(jù)的基礎(chǔ)上,把對象的住址劃分為
繳費習(xí)慣:繳費習(xí)慣包括用戶的欠費頻率、是否能及時繳費、每次平均繳費金額以及繳費方式等信息,具體為:
備注:姓名、性別、家庭住址為個人隱私,需加密處理。
在包含以上信息的問卷調(diào)查以及供電公司提供的數(shù)據(jù)的基礎(chǔ)上,建立個體用戶畫像,并通過用戶典型行為分析、聚類算法及模型建立,可以了解客戶對繳費和相關(guān)業(yè)務(wù)的要求,從而在保持成本或降低成本的同時,提升客戶滿意度。并且可以根據(jù)調(diào)研內(nèi)容分析及過去三年的繳費信息數(shù)據(jù)分析,預(yù)測出未來一年的繳費信息數(shù)據(jù)。
獲得最優(yōu)個體用戶畫像
繳費客戶群體典型行為分析是在調(diào)研和供電公司提供數(shù)據(jù)的基礎(chǔ)上,對調(diào)研結(jié)果和數(shù)據(jù)進(jìn)行分析綜合,并為客戶群體的數(shù)據(jù)模型建立做準(zhǔn)備。對繳費客戶群體典型行為進(jìn)行分析,首先需要用特征權(quán)重優(yōu)化方法對個體用戶畫像中各權(quán)重進(jìn)行調(diào)整優(yōu)化,得到調(diào)整后的最優(yōu)個體用戶畫像,再對最優(yōu)個體用戶畫像進(jìn)行聚類及建模,得到群體用戶畫像及數(shù)據(jù)模型。
繳費客戶群體典型行為分析主要依據(jù)是問卷調(diào)查和供電公司提供的繳費數(shù)據(jù),分析內(nèi)容包括:
用戶畫像又稱用戶角色(Persona),作為一種勾畫目標(biāo)用戶、聯(lián)系用戶訴求與設(shè)計方向的有效工具,用戶畫像在各領(lǐng)域得到了廣泛的應(yīng)用。在實際操作的過程中往往會以最為淺顯和貼近生活的話語將用戶的屬性、行為與期待聯(lián)結(jié)起來。作為實際用戶的虛擬代表,用戶畫像所形成的用戶角色并不是脫離產(chǎn)品和市場之外所構(gòu)建出來的,形成的用戶角色需要有代表性能代表產(chǎn)品的主要受眾和目標(biāo)群體。用戶畫像要建立在真實的數(shù)據(jù)之上,當(dāng)有多個用戶畫像的時候,需要考慮用戶畫像的優(yōu)先級,并且用戶畫像是處在不斷修正中的。
用戶畫像的核心工作是為用戶“打標(biāo)簽”。在調(diào)查問卷中已經(jīng)定義了用戶標(biāo)簽,這些標(biāo)簽具有簡潔、樸素的特點,方便標(biāo)簽提取和聚類分析。以例說明用戶標(biāo)簽,如下:
該例以標(biāo)簽的形式說明了該繳費客戶的性質(zhì)與繳費習(xí)慣,表格中每一小格內(nèi)容即為一個用戶標(biāo)簽。
建立電費繳納客戶的用戶畫像可分為三個層次:第一層次是群體用戶的調(diào)查分析;第二層次是數(shù)據(jù)分析的具象化個體描述;第三層次是抽象數(shù)據(jù)建模后的開發(fā)應(yīng)用。
確定標(biāo)簽權(quán)重的做法有多個:如專家設(shè)定法,通過人工設(shè)定,有調(diào)整方便的優(yōu)點;算法優(yōu)化法,基于調(diào)查樣本和提供的數(shù)據(jù)樣本,得有足夠的樣本訓(xùn)練集,根據(jù)模型目標(biāo)不同,得到的權(quán)重不一樣。電費繳納客戶用戶畫像的權(quán)重通過KNN算法和模擬退火算法得到。
K最近鄰(k-Nearest Neighbor,KNN)分類算法,根據(jù)某些樣本實例與其他實例之間的相似性進(jìn)行分類。KNN算法不僅可以用于分類,還可以用于回歸,是一個理論上比較成熟的方法,也是最簡單的機器學(xué)習(xí)算法之一。該方法的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數(shù)屬于某一個類別,則該樣本也屬于這個類別。KNN算法中,所選擇的鄰居都是已經(jīng)正確分類的對象。該方法在定類決策上只依據(jù)最鄰近的一個或者幾個樣本的類別來決定待分樣本所屬的類別。KNN方法雖然從原理上也依賴于極限定理,但在類別決策時,只與極少量的相鄰樣本有關(guān)。由于KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合。具體為通過找出一個樣本的k個最近鄰居,將這些鄰居的屬性的平均值賦給該樣本,從而得到該樣本的屬性。KNN算法流程圖如圖2所示。
根據(jù)傳統(tǒng)的向量空間模型,樣本被形式化為特征空間中的加權(quán)特征向量,即D=D(T1,W1;T2,W2;…;Tn,Wn)。對于一個測試樣本,計算它與訓(xùn)練樣本集中每個樣本的相似度,找出K個最相似的樣本,根據(jù)加權(quán)距離和判斷測試樣本所屬的類別。計算該測試樣本與訓(xùn)練集中每個樣本的相似度,計算公式為:
式中:di為測試樣本的特征向量,dj為第j類的中心向量;M為特征向量的維數(shù);Wk為向量的第k維。k值的確定一般先采用一個初始值,然后根據(jù)實驗測試K的結(jié)果調(diào)整K值,一般初值定為幾十到幾百。
模擬退火算法是基于Monte-Carlo迭代求解策略的一種隨機尋優(yōu)算法,其出發(fā)點是基于物理中固體物質(zhì)的退火過程與一般組合優(yōu)化問題之間的相似性。模擬退火算法從某一較高初溫出發(fā),伴隨外界影響因素參數(shù)的不斷下降,結(jié)合概率突跳特性在解空間中隨機尋找目標(biāo)函數(shù)的全局最優(yōu)解,即在局部最優(yōu)解能概率性地跳出并最終趨于全局最優(yōu)。模擬退火算法先以搜尋空間內(nèi)一個任意點作起始,每一步先選擇一個“鄰居”,然后再計算從現(xiàn)有位置到達(dá)“鄰居”的概率。
模擬退火的算法模型如下:
在第次迭代中被模擬退火算法(SA)訪問的是解j,而在第(k+1)次迭代中被模擬退火算法(SA)訪問的是解j的概率。它由兩個獨立的概率分布構(gòu)成,在第k次迭代中從解i產(chǎn)生解的概率gij(T),其中g(shù)ij(T)要求滿足歸一化條件:
解被接受的概率λij(T),這里T是第k次迭代時的外界影響因素,對于i≠j的情況,轉(zhuǎn)移概率的表達(dá)式如下
因為λij(T)不總是等于,故新解有不被接受的可能,算法停留在解i的概率為
由于Ω是一個可列集,故模擬退火算法產(chǎn)生的隨機變量所代表的隨機過程是一個Markov鏈,其一步轉(zhuǎn)移概率由以上兩式定義,記一步轉(zhuǎn)移概率為:
則k步轉(zhuǎn)移概率為
其中I為單位矩陣,Tt表示第t次迭代時的外界影響因素值。其矩陣元的含義為
Pij(m,m+k)=Pr{Xm+k=j(luò)|Xm=i}
即被m次迭代處于狀態(tài)i,第m+k次迭代處于狀態(tài)j的概率。
迭代調(diào)優(yōu)指標(biāo)權(quán)重參數(shù),從而為渠道規(guī)劃提供指標(biāo)權(quán)重參考。如圖3所示,隨機設(shè)置各個屬性的初始權(quán)重;基于樣本數(shù)據(jù)集劃分集合測試集,進(jìn)行K近鄰分類計算,遍歷測試集中每條數(shù)據(jù),從訓(xùn)練集中提取距離最近的前K條數(shù)據(jù),與測試數(shù)據(jù)的實際值比較,并統(tǒng)計誤差;進(jìn)行誤差比較,調(diào)整各個屬性的權(quán)重,若誤差小于閾值,則得到各個屬性的權(quán)重,否則,調(diào)整屬性的權(quán)重,進(jìn)行迭代測試,得到各個屬性的權(quán)重。
聚類分析
聚類的目標(biāo)是在潛在的數(shù)據(jù)集中區(qū)分和提取重要有區(qū)別的簇,到目前為止研究人員開發(fā)了有五種基本的聚類方法,劃分聚類,層次聚類,基于密度的聚類,基于網(wǎng)格聚類和基于模型的聚類。其中,基于劃分的k-means算法由于算法本身的思想簡單,實現(xiàn)起來比較容易,受到廣泛地使用。但是,k-means算法對異常值敏感,并且需要提前確定k值。因此采用改進(jìn)的基于群體智能的客戶行為分析算法,該算法是以蟻群合作蟻巢分類的簡單模型為基礎(chǔ),分析客戶行為的一種自組織聚類算法,此方法可使數(shù)據(jù)更容易可視化,它突顯出引人興趣的特征。聚類中心的個數(shù)從數(shù)據(jù)中自動產(chǎn)生。
假設(shè)只有一種物體,所有的物體都隨機分布在二維格上面,每個格點只包含一個物體,螞蟻被隨機放在二維格上,并且每次沿著隨機的方向移動一格,每次移動后,如果相應(yīng)的格點有物體的話,沒有負(fù)擔(dān)的螞蟻決定給予如下的概率撿起一個物體:
其中,λ是螞蟻在它的周圍感覺到得物體數(shù),且γ1>0。當(dāng)只有少量物體在螞蟻周圍時,即λ<<γ1,則Pp接近于1;因此,物體有較大的概率被拾起,另一方面,如果螞蟻覺察到許多物體λ>>γ1,則Pp接近于0,物體被拾起的概率就比較小。
每只有負(fù)擔(dān)的螞蟻放下所背負(fù)的物體的概率由下面的公式給出:
其中,應(yīng)保證給定相應(yīng)格點是空的,γ2>0,如果螞蟻在周圍發(fā)現(xiàn)大量的物體,即λ>>γ2,則Pd接近于1,放下物體的概率很大。若λ<<γ2,則Pd接近于0,放下的概率幾乎沒有。
基于蟻群聚類算法的基本模型(BM),Lumer和Faieta將BM推廣到用實際元素來聚類數(shù)據(jù)向量,提出著名的LF算法。LF算法中引入了一個相似密度函數(shù),來衡量兩個數(shù)據(jù)對象之間的相似程度。
在LF算法中,數(shù)據(jù)向量被隨機地放置在二維格上,在觀察被稱為nN路徑的個地點周圍區(qū)域時,螞蟻隨機地在格附近移動,移動區(qū)域就是一個方形領(lǐng)域即螞蟻當(dāng)前位置i周圍的nN×nN個地點,假設(shè)螞蟻在時間t時位于位置i,找到數(shù)據(jù)向量Oi,在螞蟻領(lǐng)域內(nèi)的數(shù)據(jù)向量Oi的“局部”密度f(Oi)的計算公式如下:
式中,α>0定義了數(shù)據(jù)向量Oi和Oj的相異度的范圍。常量α確定兩個物體何時應(yīng)該或不應(yīng)該放在一起,是一個調(diào)節(jié)數(shù)據(jù)向量間平均密度的系數(shù),如果α太小,會形成許多的小組,把屬于同一組的物體聚到不同的組,如果α太大,可能會造成各個組之間的混淆,把不屬于同一組的物體聚到一起。所以α對形成的簇的個數(shù)有直接的影響,如圖4所示。
利用相似度度量f(Oi),拾起和放棄概率的定義如下:
通過聚類算法,可建立繳費客戶的群體用戶畫像。該群體用戶畫像是在個體用戶畫像通過聚類建立起來的。群體用戶畫像可描述整個繳費客戶的年齡分布、繳費偏好與繳費方式等標(biāo)簽信息。反之,若知道某個個體樣本的標(biāo)簽信息,在群體中應(yīng)有一類樣本群與之有相近的性質(zhì)。因此,可用群體用戶畫像來描述個體用戶畫像,也可用個體用戶畫像來推斷分析群體用戶畫像。
通過用戶畫像、繳費客戶群體典型行為分析及后續(xù)軟件分析,可得到電費繳納群體的繳費偏好等信息,為渠道規(guī)劃和人力資源調(diào)配提供支撐。
實施例3
采用K最近鄰分類算法建立指標(biāo)評價體系
KNN分類算法的主要思想是:先計算待分類樣本與已知類別的訓(xùn)練樣本之間的距離或相似度,找到距離或相似度與待分類樣本數(shù)據(jù)最近的K個鄰居;再根據(jù)這些鄰居所屬的類別來判斷待分類樣本數(shù)據(jù)的類別。如果待分類樣本數(shù)據(jù)的K個鄰居都屬于一個類別,那么待分類樣本也屬于這個類別。否則,對每一個候選類別進(jìn)行評分,按照某種規(guī)則來確定待分類樣本數(shù)據(jù)的類別。
對于一個測試樣本,計算它與訓(xùn)練樣本集中每個樣本的相似度,找出K個最相似的樣本,根據(jù)加權(quán)距離和判斷測試樣本所屬的類別。具體算法步驟如下:
(1)對于一個測試樣本,根據(jù)特征詞形成測試樣本向量。
(2)計算該測試樣本與訓(xùn)練集中每個樣本的樣本相似度,計算公式為:
式中:di為測試樣本的特征向量,dj為第j類的中心向量;M為特征向量的維數(shù);Wk為向量的第k維.k值的確定一般先采用一個初始值,然后根據(jù)實驗測試K的結(jié)果調(diào)整K值,一般初值定為幾十到幾百。
(3)按照樣本相似度,在訓(xùn)練樣本集中選出與測試樣本最相似的k個樣本。
(4)在測試樣本的k個近鄰中,依次計算每類的權(quán)重,計算公式如下:
式中:x為測試樣本的特征向量;
Sim(x,di)為相似度計算公式;
b為閾值,有待于優(yōu)化選擇;
y(di,Cj)的取值為1或0,如果di屬于Cj,則函數(shù)值為1,否則為0。
(5)比較類的權(quán)重,將樣本分到權(quán)重最大的那個類別中。
KNN方法基于類比學(xué)習(xí),是一種非參數(shù)的分類技術(shù),在基于統(tǒng)計的模式識別中非常有效,對于未知和非正態(tài)分布可以取得較高的分類準(zhǔn)確率,具有魯棒性、概念清晰等優(yōu)點。但在樣本分類中,KNN方法也存在不足,如KNN算法是懶散的分類算法,其時空開銷大;計算相似度時,特征向量維數(shù)高,沒有考慮特征詞間的關(guān)聯(lián)關(guān)系;樣本距離計算時,各維權(quán)值相同,使得特征向量之間的距離計算不夠準(zhǔn)確,影響分類精度。
采用遺傳退火算法,計算各個屬性指標(biāo)的權(quán)重值
模擬退火算法(Simulated Annealing)源于統(tǒng)計物理學(xué),據(jù)統(tǒng)計熱力學(xué),物體中的每個分子的狀態(tài)服從Gibbs分布,即:
式中:E(ri)為第i個分子的能量函數(shù);
ri為第i個分子所處的狀態(tài);
k為玻爾茲曼常數(shù);
T表示外界影響因素;
ρ(ri)為第i個分子的概率密度,為了方便起見令k=1。
模擬退火算法的具體步驟如下:
1)給定模型每一個參數(shù)變化范圍,在這個范圍內(nèi)隨機選擇一個初始模型m0,并計算相應(yīng)的目標(biāo)函數(shù)值E(m0);
2)對當(dāng)前模型進(jìn)行擾動產(chǎn)生一個新模型m,計算相應(yīng)的目標(biāo)函數(shù)值E(m),得到ΔE=E(m)-E(m0)
3)若ΔE<0,則新模型被m接受;若ΔE>0,則新模型m按概率P=exp(-ΔE/T)進(jìn)行接受,T為外界影響因素。當(dāng)模型被接受時,置m0=m;
4)在外界影響因素T下,重復(fù)一定次數(shù)的擾動和接受過程,即重復(fù)步驟2)、3);
5)緩慢降低外界影響因素T;
6)重復(fù)步驟2)、5),直至收斂條件滿足為止。
判斷是否為最優(yōu)值,最優(yōu)值的判斷公式為|ΔE|=|E(m)-E(m0)|≤0,ΔE表示渠道最優(yōu)解;E(m)表示計算的渠道值,E(m0)表示初始渠道值。
如果判斷結(jié)果為否,則返回從此進(jìn)行聚類分析;如果判斷結(jié)果為是,得到該屬性指標(biāo)的權(quán)重最優(yōu)值,從而確定最優(yōu)繳費渠道,如圖5所示。
以上所述實施例僅表達(dá)了本發(fā)明的實施方式,其描述較為具體和詳細(xì),但并不能因此而理解為對本發(fā)明專利范圍的限制。應(yīng)當(dāng)指出的是,對于本領(lǐng)域的普通技術(shù)人員來說,在不脫離本發(fā)明構(gòu)思的前提下,還可以做出若干變形和改進(jìn),這些都屬于本發(fā)明的保護(hù)范圍。因此,本發(fā)明專利的保護(hù)范圍應(yīng)以所附權(quán)利要求為準(zhǔn)。
- 還沒有人留言評論。精彩留言會獲得點贊!
- 用電信息采集本地通信可靠性測試系統(tǒng)及方法
- 一種面向電力網(wǎng)絡(luò)的性能可靠性評估方法
- 包含風(fēng)電場的電力系統(tǒng)可靠性評估方法
- 基于ahp建立電力通信網(wǎng)可靠性和風(fēng)險映射的方法
- 一種分布式電力系統(tǒng)電能質(zhì)量多指標(biāo)分析監(jiān)測平臺的制作方法
- 輕型高可靠性電力傳輸導(dǎo)線的制作方法
- 四自由度電力回路式傳動系統(tǒng)可靠性試驗臺的制作方法
- 分布式電力系統(tǒng)電能質(zhì)量多指標(biāo)分析監(jiān)測平臺的制作方法
- 一種電力通信網(wǎng)中面向可靠性的節(jié)點分簇方法
- 電力ict網(wǎng)絡(luò)區(qū)分可靠性的路由建立方法和系統(tǒng)的制作方法