燃煤電站鍋爐飛灰含碳量預測模型構建方法及系統與流程
本發明涉及一種電站鍋爐燃燒系統,具體地,涉及一種燃煤電站鍋爐飛灰含碳量預測模型構建方法及系統。
背景技術:
為了實現電站鍋爐燃燒系統優化控制的目標,第一步是要對鍋爐的燃燒實際情況給出真實及時合理的評估。其中關鍵是要對鍋爐燃燒性的關鍵參變量在線預測。自改革開放以來,我國電力行業熱工自動化水平有了極大的提高,但由于測量技術的限制以及測量系統的不可靠、不準確和不實時,因而電站鍋爐系統的一些關鍵參變量還沒有能實現在線測量。
飛灰含碳量是鍋爐經濟運行的重要指標。根據檢測方法的實時性進行分類,可以分為離線檢測和在線檢測。離線測量技術方面,燃燒法是最常用的一種方法,通過對飛灰樣品的燃燒,根據前后兩次的重量變化,從而計算得到飛灰含碳量的水平。但是這種方法無法滿足實時性的要求。因而實現在線測量飛灰含碳量面臨著一些技術困難,主要原因有以下兩點:第一,為了精確測量飛灰含碳量水平,最重要的是要得到入爐煤的煤質數據,但實際情況是很多電站無法在線測量這些數據,從而使得精確性得不到提高。同時我國燃煤電站由于地域因素用煤的煤質波動較大,給飛灰含碳量在線計算帶來了困難;第二,一些關鍵的測量值由于儀器損壞或者故障等原因使得在線測量值不能得到真實的數據。
經檢索,公開號為102778538A、申請號為201210234724.3的中國發明申請,公開了一種基于改進支持向量機的鍋爐飛灰含碳量軟測量方法,該方法基于粒子群算法對支持向量回歸進行參數尋優,選取了影響回歸模型有效性的兩個參數,首先通過傳感器采集相關輔助變量的值,并進行數據預處理,根據過去6小時的歷史數據辨識出支持向量回歸模型的兩個主要參數以確定飛灰含碳量軟測量模型,并根據歷史數據的更新每小時更新一次軟測量模型,將實時測量的輔助變量值輸入建立好的軟測量模型即可得到飛灰含碳量輸出值。
上述專利是針對飛灰含碳量在線監測提出的,但是其選取了支持向量回歸的方式選擇影響回歸模型的有效參數,某些程度上會導致過分依賴歷史數據易造成模型適應度差等問題。
因此如何解決以上問題實現飛灰含碳量在線監測對鍋爐燃燒狀況進行實時評估是十分重要的。
技術實現要素:
針對現有技術中的缺陷/之一,本發明的目的之一是提供一種精度較高的燃煤電站鍋爐飛灰含碳量預測模型的構建方法,相較于傳統的機理模型提升了建模的精度,相較于純黑箱模型有更快的速度。
本發明的目的之二是提供一種燃煤電站鍋爐飛灰含碳量預測模型的構建系統。
根據本發明的第一目的,提供一種燃煤電站鍋爐飛灰含碳量預測模型的構建方法,所述方法包含以下步驟:
S1:獲取燃煤電站鍋爐歷史運行數據,建立離線樣本庫,通過最大相關最小冗余算法篩選飛灰含碳量預測模型的輸入變量和輸出變量;使用模糊C均值聚類算法(FCM)將歷史樣本進行聚類,得到N個子類,計算出N個子類模糊隸屬度函數;
S2:利用每個子類的歷史樣本分別訓練最小二乘支持向量機算法(LSSVM算法),得到N個以飛灰含碳量為輸出的子模型;
S3:將S1得到的所述模糊隸屬度函數連接S2得到的所述子模型,構建全局模型,即飛灰含碳量預測模型。
進一步的,所述飛灰含碳量預測模型,選取如下變量作為模型輸入變量:
一次風量、一次風壓、二次風量、二次風壓和煙氣含氧量,它們反映了空氣動力場對飛灰含碳量的影響;
爐膛出口溫度和二次風溫反映了溫度的影響因素;
二次風閥門開度反映了配風方式對其的影響;
入爐煤量和鍋爐負荷反映了負荷的影響。
更進一步的,在選取模型輸入變量時考慮燃煤電站鍋爐在低負荷和高負荷和變負荷三種情況。
更進一步的,所述飛灰含碳量預測模型,利用最大相關最小冗余(mRMR)算法分析輸入變量之間以及輸入變量與飛灰含碳量的相關性。
進一步的,所述最小二乘支持向量機算法(LSSVM算法)中,選擇高斯徑向基核函數作為核函數,利用10層交叉驗證網格搜索技術確定核函數中的徑向基核參數和正規化參數。
進一步的,所述飛灰含碳量預測模型,利用平均絕對誤差,均方根誤差作為評價標準指標。
進一步的,所述S1中,使用模糊C均值聚類算法(FCM)將歷史樣本進行聚類,是指:將歷史運行數據即原始火電數據X={x1,x2,…,xm},根據FCM聚類算法分成N個子集Γ1,Γ2,…,ΓN;FCM算法中的隸屬度函數U計算出xi∈X的隸屬度ui1,ui2,…,uiN。
進一步的,所述S3,是指:對于輸入向量xj,利用S2中得到的N個子模型預測,從而知道N個結果G={g1,g2,…,gN},對于xj而言,其歸屬于S1中N個子類Γ1,Γ2,…,ΓN的隸屬度分別是u1,u2,…,uN,從而利用式(1)得到最后的飛灰含碳量預測值R:
R=u1·g1+u2·g2+…+uN·gN (1)
根據本發明的第二目的,提供一種燃煤電站鍋爐飛灰含碳量預測模型的構建系統,所述系統包括:
樣本聚類模塊:獲取燃煤電站鍋爐歷史運行數據,建立離線樣本庫,通過最大相關最小冗余算法篩選飛灰含碳量預測模型的輸入變量和輸出變量;使用模糊C均值聚類算法(FCM)將歷史樣本進行聚類,得到N個子類,計算出N個子類模糊隸屬度函數;
子模型構建模塊:利用所述樣本聚類模塊得到的每個子類的歷史樣本,分別訓練最小二乘支持向量機算法(LSSVM算法),得到N個以飛灰含碳量為輸出的子模型;
全局模型構建模塊:將所述樣本聚類模塊得到的所述模糊隸屬度函數連接所述子模型構建模塊得到的所述子模型,構建全局模型,即飛灰含碳量預測模型。
與現有技術相比,本發明具有如下的有益效果:
本發明提出了一種精度較高的飛灰含碳量預測方法,對下一刻的飛灰含碳量進行預估,實現了對實時燃燒效率的監控。本發明結合流程工業機理特性進行數據驅動建模與預測,選擇通過最大相關最小冗余算法篩選飛灰含碳量預測模型的輸入變量和輸出變量等方法,側重于機理/數據混合建模方法,避免了處理流程工業建模問題過分依賴歷史數據易造成模型適應度差等問題,可以更加有效地進行飛灰含碳量預測,相較于傳統的機理模型提升了建模的精度,相較于純黑箱模型有更快的速度。
飛灰含碳量預測模型的構建系統由燃煤電站的運行實時數據驅動,無需硬件改造,具備投入運行成本低,預測精度高等優點。
附圖說明
通過閱讀參照以下附圖對非限制性實施例所作的詳細描述,本發明的其它特征、目的和優點將會變得更明顯:
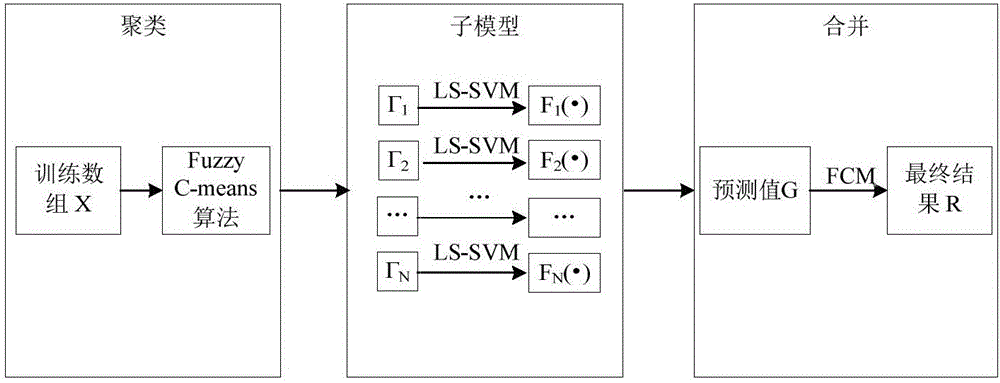
圖1為本發明一實施例中飛灰含碳量預測模型(FCM-LSSVM模型)結構示意圖;
圖2為本發明一實施例中子模型LSSVM框架示意圖;
圖3為本發明一實施例中飛灰含碳量預測模型預測值與測量值對比圖;
圖4為本發明一實施例中構建系統的結構框圖。
具體實施方式
下面結合具體實施例對本發明進行詳細說明。以下實施例將有助于本領域的技術人員進一步理解本發明,但不以任何形式限制本發明。應當指出的是,對本領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干變形和改進。這些都屬于本發明的保護范圍。
如圖1所示,一種燃煤電站鍋爐飛灰含碳量預測模型的構建原理圖,其中具體包括以下步驟:
首先,獲取燃煤電站鍋爐歷史運行數據,建立離線樣本庫,通過最大相關最小冗余算法篩選飛灰含碳量預測模型的輸入變量和輸出變量;
將原始火電數據X={x1,x2,…,xm}根據FCM聚類算法分成N個子集Γ1,Γ2,…,ΓN。具體而言,FCM算法中的隸屬度函數U計算出xi∈X的隸屬度ui1,ui2,…,uiN。在本文構建的FCM-LSSVM算法中,假設:如果uij是ui1,ui2,…,uiN中最大的,則認為xi∈X屬于類別Γj。根據此假設,X={x1,x2,…,xm}可以劃分為N個子集。
第二步,利用每個子集的火電數據分別訓練LSSVM算法,得到N個子模型。
第三步,對于輸入向量xj,利用第二步中得到的N個子模型預測,從而知道N個結果G={g1,g2,…,gN},對于xj而言,其歸屬于第一步中N個子集Γ1,Γ2,…,ΓN的隸屬度分別是u1,u2,…,uN,從而利用式1得到最后的預測結果。
R=u1·g1+u2·g2+…+uN·gN (1)
本發明通過最大相關最小冗余算法選取與飛灰含碳量相關的參數作為飛灰含碳量在線預測模型的輸入變量:一次風量、一次風壓、二次風量、二次風壓和煙氣含氧量,它們反映了空氣動力場對飛灰含碳量的影響;爐膛出口溫度和二次風溫反映了溫度的影響因素;二次風閥門開度反映了配風方式對其的影響;入爐煤量和鍋爐負荷反映了負荷的影響。
根據理論分析,上述參數與飛灰含碳量存在內在的聯系。但在實際情況下,模型的輸入參數過多,使得模型的復雜度增加;另一方面,這些參數本身之間也存在著較強的相關性。因此,本發明利用mRMR算法分析這些參數之間以及這些參數與飛灰含碳量的相關性。根據mRMR算法,可以得到各個參數φ算子,如表1所示。
本發明選取了2012年5月2日10:00a.m.到4:00p.m.時間段的機組的運行數據,數據采集間隔為30s,共686組數據,進行驗證。為了保證預測模型能適應全工況,驗證樣本對應的機組在此時間段的變動范圍為150-260MW,基本全面覆蓋了300MW正常運行的工況變動范圍。
表1各參數φ算子
如果φ算子值φ<0.2,則認為不符合模型輸入的要求,不能作為輸入。因此,一次風壓,二次風壓,煙氣含氧量和閥門F被剔除。選取剩下的12個參數作為本發明提出的FCM-LSSVM預測模型的輸入。整個子模型LSSVM框架如圖2所示。
在本發明提出的FCM-LSSVM預測模型構建過程中,第一步需要利用FCM算法將原始的數據聚類為不同類別。在一實施例中,一共選取了686組數據,如果聚類的數量太多,則每個數據子集的數據量太少,建立后的模型精確度會降低;但如果聚類數太少,則每個數據子集之間存在冗余,同樣也會影響模型的精確度。本實施例從實際情況考慮,將原始數據聚類為三個數據子集。根據FCM算法,利用隸屬度公式可以計算出每組數據的隸屬度,根據隸屬度從而歸類。
根據上述的聚類原則,686組數據一共劃分為3類,數據子集1一共是225組數據,數據子集2一共272組數據,數據子集3一共189組數據。
接下來,利用LSSVM算法分別對三個數據子集建模。在LSSVM算法中,選擇高斯徑向基核函數(RBF)作為核函數,利用10層交叉驗證網格搜索技術確定核函數中的徑向基核參數σ和正規化參數γ。這兩個參數在三個子模型的大小如表2所示。
表2 LSSVM模型參數
第三步,根據式(1),從而得到模型的預測結果。
為了驗證本發明FCM-LSSVM預測模型的有效性,選取了同樣時間段中的200個數據作為FCM-LSSVM預測模型的測試數據,驗證FCM-LSSVM預測模型的預測性能,預測結果如圖3所示,可見所述預測模型具有較好的預測性能。
本發明利用以下兩個指標作為評價標準:平均絕對誤差(MAE),均方根誤差(RMSE)。
式2和式3中,yi是飛灰含碳量的測量值,是相應的預測值,N是測試數據的數量。
表3 FCM-LSSVM與LSSVM預測性能對比
FCM-LSSVM的建模精度較LSSVM建模方法更高,訓練時間更短。本發明所提出的FCM-LSSVM模型通過聚類劃分使得子模型訓練精度更高,進而得到的飛灰含碳量模型精度相較于傳統LSSVM建模模型精度更高。
如圖4所示,一種燃煤電站鍋爐飛灰含碳量預測模型的構建系統,所述系統包括:
樣本聚類模塊:獲取燃煤電站鍋爐歷史運行數據,建立離線樣本庫,通過最大相關最小冗余算法篩選飛灰含碳量預測模型的輸入變量和輸出變量;使用模糊C均值聚類算法將歷史樣本進行聚類,得到N個子類,計算出N個子類模糊隸屬度函數;
子模型構建模塊:利用所述樣本聚類模塊得到的每個子類的歷史樣本,分別訓練最小二乘支持向量機算法,得到N個以飛灰含碳量為輸出的子模型;
全局模型構建模塊:將所述樣本聚類模塊得到的所述模糊隸屬度函數連接所述子模型構建模塊得到的所述子模型,構建全局模型,即飛灰含碳量預測模型。
上述各個模塊具體實現的技術與上述方法對應步驟相同,在此不再贅述。
以上對本發明的具體實施例進行了描述。需要理解的是,本發明并不局限于上述特定實施方式,本領域技術人員可以在權利要求的范圍內做出各種變形或修改,這并不影響本發明的實質內容。
- 還沒有人留言評論。精彩留言會獲得點贊!