用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置和方法與流程
本發(fā)明涉及人工神經(jīng)網(wǎng)絡,更具體涉及用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置和方法。
背景技術:
人工神經(jīng)網(wǎng)絡(artificialneuralnetworks,ann)也簡稱為神經(jīng)網(wǎng)絡(nn),它是一種模仿動物神經(jīng)網(wǎng)絡行為特征,進行分布式并行信息處理的算法數(shù)學模型。近年來神經(jīng)網(wǎng)絡發(fā)展很快,被廣泛應用于很多領域,包括圖像識別、語音識別,自然語言處理,天氣預報,基因表達,內(nèi)容推送等等。
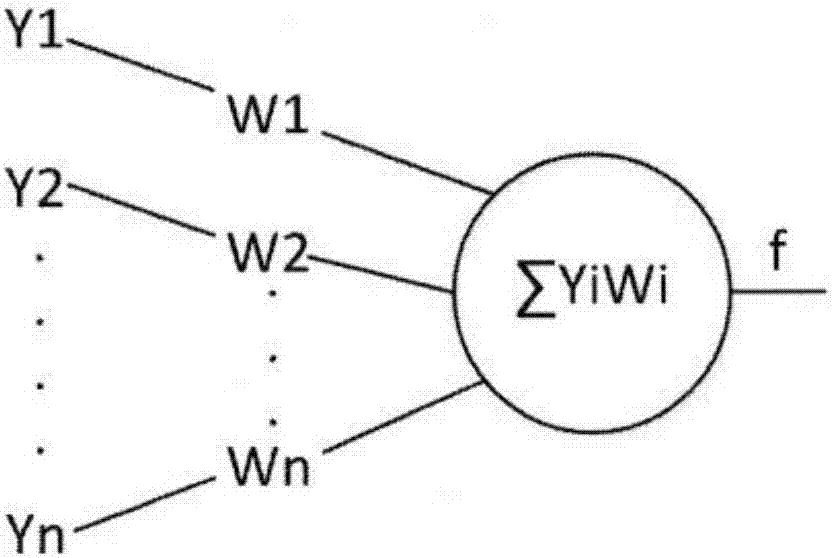
圖1圖示說明了人工神經(jīng)網(wǎng)絡中的一個神經(jīng)元的計算原理圖。
神經(jīng)元的積累的刺激是由其他神經(jīng)元傳遞過來的刺激量和對應的權重之和,用xj表示在第j個神經(jīng)元的這種積累,yi表示第i個神經(jīng)元傳遞過來的刺激量,wi表示鏈接第i個神經(jīng)元刺激的權重,得到公式:
xj=(y1*w1)+(y2*w2)+...+(yi*wi)+...+(yn*wn)
而當xj完成積累后,完成積累的第j個神經(jīng)元本身對周圍的一些神經(jīng)元傳播刺激,將其表示為yj得到如下所示:
yj=f(xj)
第j個神經(jīng)元根據(jù)積累后xj的結果進行處理后,對外傳遞刺激yj。用f函數(shù)映射來表示這種處理,將它稱之為激活函數(shù)。
卷積神經(jīng)網(wǎng)絡(convolutionalneuralnetworks,cnn)是人工神經(jīng)網(wǎng)絡的一種,已成為當前語音分析和圖像識別領域的研究熱點。它的權值共享網(wǎng)絡結構使之更類似于生物神經(jīng)網(wǎng)絡,降低了網(wǎng)絡模型的復雜度,減少了權值的數(shù)量。該優(yōu)點在網(wǎng)絡的輸入是多維圖像時表現(xiàn)的更為明顯,使圖像可以直接作為網(wǎng)絡的輸入,避免了傳統(tǒng)識別算法中復雜的特征提取和數(shù)據(jù)重建過程。卷積網(wǎng)絡是為識別二維形狀而特殊設計的一個多層感知器,這種網(wǎng)絡結構對平移、比例縮放、傾斜或者共他形式的變形具有高度不變性。
圖2示出了卷積神經(jīng)網(wǎng)絡的處理結構示意圖。
卷積神經(jīng)網(wǎng)絡是一個多層的神經(jīng)網(wǎng)絡,每層由多個二維平面組成,而每個平面由多個獨立神經(jīng)元組成。卷積神經(jīng)網(wǎng)絡通常由卷積層(convolutionlayer)、下采樣層(或稱為池化層即poolinglayer)以及全連接層(fullconnectionlayer,fc)組成。
卷積層通過線性卷積核與非線性激活函數(shù)產(chǎn)生輸入數(shù)據(jù)的特征圖,卷積核重復與輸入數(shù)據(jù)的不同區(qū)域進行內(nèi)積,之后通過非線性函數(shù)輸出,非線性函數(shù)通常為rectifier、sigmoid、tanh等。以rectifier為例,卷積層的計算可以表示為:
其中,(i,j)為特征圖中的像素索引,xi,j表示輸入域以(i,j)為中心,k表示特征圖的通道索引。特征圖計算過程中雖然卷積核與輸入圖像的不同區(qū)域進行內(nèi)積,但卷積核不變。
池化層通常為平均池化或極大池化,該層只是計算或找出前一層特征圖某一區(qū)域的平均值或最大值。
全連接層與傳統(tǒng)神經(jīng)網(wǎng)絡相似,輸入端的所有元素全都與輸出的神經(jīng)元連接,每個輸出元素都是所有輸入元素乘以各自權重后再求和得到。
在近幾年里,神經(jīng)網(wǎng)絡的規(guī)模不斷增長,公開的比較先進的神經(jīng)網(wǎng)絡都有數(shù)億個鏈接,屬于計算和訪存密集型應用現(xiàn)有技術方案中通常是采用通用處理器(cpu)或者圖形處理器(gpu)來實現(xiàn),隨著晶體管電路逐漸接近極限,摩爾定律也將會走到盡頭。
在神經(jīng)網(wǎng)絡逐漸變大的情況下,模型壓縮就變得極為重要。模型壓縮可以將稠密神經(jīng)網(wǎng)絡變成稀疏神經(jīng)網(wǎng)絡,可以有效減少計算量、降低訪存量。然而,cpu與gpu無法充分享受到稀疏化后帶來的好處,取得的加速極其有限。而傳統(tǒng)稀疏矩陣計算架構并不能夠完全適應于神經(jīng)網(wǎng)絡的計算。已公開實驗表明模型壓縮率較低時現(xiàn)有處理器加速比有限。因此專有定制電路可以解決上述問題,可使得處理器在較低壓縮率下獲得更好的加速比。
就卷積神經(jīng)網(wǎng)絡而言,由于卷積層的卷積核能夠共享參數(shù),因此卷積層的參數(shù)量相對較少,而且卷積核往往較小(1*1、3*3、5*5等),因此對卷積層的稀疏化效果不明顯。池化層的計算量也較少。但全連接層仍然有數(shù)量龐大的參數(shù),如果對全連接層進行稀疏化處理將會極大減少計算量。
因此,希望提出一種針對稀疏cnn加速器的實現(xiàn)裝置和方法,以達到提高計算性能、降低響應延時的目的。
技術實現(xiàn)要素:
基于以上的討論,本發(fā)明提出了一種專用電路,支持fc層稀疏化cnn網(wǎng)絡,采用ping-pang緩存并行化設計,有效平衡i/o帶寬和計算效率。
現(xiàn)有技術方案中稠密cnn網(wǎng)絡需要較大io帶寬、較多存儲和計算資源。為了適應算法需求,模型壓縮技術變得越來越流行。模型壓縮后的稀疏神經(jīng)網(wǎng)絡存儲需要編碼,計算需要解碼。本發(fā)明采用定制電路,流水線設計,能夠獲得較好的性能功耗比。
本發(fā)明的目的在于提供一種稀疏cnn網(wǎng)絡加速器的實現(xiàn)裝置和方法,以便達到提高計算性能、降低響應延時的目的。
根據(jù)本發(fā)明的第一方面,提供一種用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置,包括:卷積與池化單元,用于根據(jù)卷積參數(shù)信息對輸入數(shù)據(jù)進行第一迭代次數(shù)的卷積與池化操作,以最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量,其中,每個輸入數(shù)據(jù)被分割為多個子塊,由卷積與池化單元對多個子塊并行進行卷積與池化操作;全連接單元,用于根據(jù)全連接層權值矩陣位置信息對輸入向量進行第二迭代次數(shù)的全連接計算,以最終得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果,其中,每個輸入向量被分割為多個子塊,由全連接單元對多個子塊并行進行全連接操作;控制單元,用于確定并且向所述卷積與池化單元和所述全連接單元分別發(fā)送所述卷積參數(shù)信息和所述全連接層權值矩陣位置信息,并且對上述單元中的各個迭代層級的輸入向量讀取與狀態(tài)機進行控制。
在根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置中,所述卷積與池化單元可以進一步包括:卷積單元,用于進行輸入數(shù)據(jù)與卷積參數(shù)的乘法運算;累加樹單元,用于累加卷積單元的輸出結果,以完成卷積運算;非線性單元,用于對卷積運算結果進行非線性處理;池化單元,用于對非線性處理后的運算結果進行池化操作,以得到下一迭代級的輸入數(shù)據(jù)或最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量。
優(yōu)選地,所述累加樹單元除了累加卷積單元的輸出結果以外,還根據(jù)卷積參數(shù)信息而加上偏置。
在根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置中,所述全連接單元可以進一步包括:輸入向量緩存單元,用于緩存稀疏神經(jīng)網(wǎng)絡的輸入向量;指針信息緩存單元,用于根據(jù)全連接層權值矩陣位置信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息;權重信息緩存單元,用于根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息;算術邏輯單元,用于根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息與輸入向量進行乘累加計算;輸出緩存單元,用于緩存算術邏輯單元的中間計算結果以及最終計算結果;激活函數(shù)單元,用于對輸出緩存單元中的最終計算結果進行激活函數(shù)運算,以得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果。
優(yōu)選地,所述壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息可以包括位置索引值和權重值。所述算術邏輯單元可以被進一步配置為:將權重值與輸入向量的對應元素進行乘法運算;根據(jù)位置索引值,讀取所述輸出緩存單元中相應位置的數(shù)據(jù),與上述乘法運算的結果相加;根據(jù)位置索引值,將相加結果寫入到輸出緩存單元中相應位置。
根據(jù)本發(fā)明的第二方面,提供一種用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的方法,包括:依據(jù)控制信息而讀取卷積參數(shù)信息與輸入數(shù)據(jù)與中間計算數(shù)據(jù),并且讀取全連接層權值矩陣位置信息;根據(jù)卷積參數(shù)信息對輸入數(shù)據(jù)進行第一迭代次數(shù)的卷積與池化操作,以最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量,其中,每個輸入數(shù)據(jù)被分割為多個子塊,對多個子塊并行進行卷積與池化操作;根據(jù)全連接層權值矩陣位置信息對輸入向量進行第二迭代次數(shù)的全連接計算,以最終得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果,其中,每個輸入向量被分割為多個子塊,并行進行全連接操作。
在根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的方法中,所述的根據(jù)卷積參數(shù)信息對輸入數(shù)據(jù)進行第一迭代次數(shù)的卷積與池化操作,以最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量的步驟可以進一步包括:進行輸入數(shù)據(jù)與卷積參數(shù)的乘法運算;累加乘法運算的輸出結果,以完成卷積運算;對卷積運算結果進行非線性處理;對非線性處理后的運算結果進行池化操作,以得到下一迭代級的輸入數(shù)據(jù)或最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量。
優(yōu)選地,所述的累加乘法運算的輸出結果,以完成卷積運算的步驟可以進一步包括:根據(jù)卷積參數(shù)信息而加上偏置。
在根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的方法中,所述的根據(jù)全連接層權值矩陣位置信息對輸入向量進行第二迭代次數(shù)的全連接計算,以最終得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果的步驟可以進一步包括:緩存稀疏神經(jīng)網(wǎng)絡的輸入向量;根據(jù)全連接層權值矩陣位置信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息;根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息;根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息與輸入向量進行乘累加計算;緩存乘累加計算的中間計算結果以及最終計算結果;對乘累加計算的最終計算結果進行激活函數(shù)運算,以得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果。
優(yōu)選地,所述壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息可以包括位置索引值和權重值。所述的根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息與輸入向量進行乘累加計算的步驟可以進一步包括:將權重值與輸入向量的對應元素進行乘法運算;根據(jù)位置索引值,讀取所緩存的中間計算結果中相應位置的數(shù)據(jù),與上述乘法運算的結果相加;根據(jù)位置索引值,將相加結果寫入到所緩存的中間計算結果中相應位置。
本發(fā)明的目的是采用高并發(fā)設計,高效處理稀疏神經(jīng)網(wǎng)絡,從而獲得更好的計算效率,更低的處理延時。
附圖說明
下面參考附圖結合實施例說明本發(fā)明。在附圖中:
圖1圖示說明了人工神經(jīng)網(wǎng)絡中的一個神經(jīng)元的計算原理圖。
圖2示出了卷積神經(jīng)網(wǎng)絡的處理結構示意圖。
圖3是根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置的示意圖。
圖4是根據(jù)本發(fā)明的卷積與池化單元的具體結構示意圖。
圖5是根據(jù)本發(fā)明的全連接單元的具體結構示意圖。
圖6是根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的方法的流程圖。
圖7是根據(jù)本發(fā)明的具體實現(xiàn)例1的計算層結構的示意圖。
圖8是根據(jù)本發(fā)明的具體實現(xiàn)例2圖示說明稀疏矩陣與向量的乘法操作的示意圖。
圖9是根據(jù)本發(fā)明的具體實現(xiàn)例2圖示說明pe0對應的權重信息的示意表格。
具體實施方式
下面將結合附圖來詳細解釋本發(fā)明的具體實施例。
圖3是根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置的示意圖。
本發(fā)明提供了一種用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置。如圖3所示,該裝置主要包含三大模塊:卷積與池化單元、全連接單元、控制單元。具體地說,卷積與池化單元,也可稱為convolution+pooling模塊,用于根據(jù)卷積參數(shù)信息對輸入數(shù)據(jù)進行第一迭代次數(shù)的卷積與池化操作,以最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量,其中,每個輸入數(shù)據(jù)被分割為多個子塊,由卷積與池化單元對多個子塊并行進行卷積與池化操作。全連接單元,也可稱為fullconnection模塊,用于根據(jù)全連接層權值矩陣位置信息對輸入向量進行第二迭代次數(shù)的全連接計算,以最終得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果,其中,每個輸入向量被分割為多個子塊,由全連接單元對多個子塊并行進行全連接操作。控制單元,也可稱為controller模塊,用于確定并且向所述卷積與池化單元和所述全連接單元分別發(fā)送所述卷積參數(shù)信息和所述全連接層權值矩陣位置信息,并且對上述單元中的各個迭代層級的輸入向量讀取與狀態(tài)機進行控制。
下文中將結合附圖4、5,針對各個單元進行進一步的詳細描述。
圖4是根據(jù)本發(fā)明的卷積與池化單元的具體結構示意圖。
本發(fā)明的卷積與池化單元用于cnn中實現(xiàn)卷積層與池化層的計算,該單元可以例化多個實現(xiàn)并行計算,也就是說,每個輸入數(shù)據(jù)被分割為多個子塊,由卷積與池化單元對多個子塊并行進行卷積與池化操作。
應該注意到,卷積與池化單元對輸入數(shù)據(jù)不僅進行分塊化并行處理,而且對輸入數(shù)據(jù)進行若干層級的迭代處理。至于具體的迭代層級數(shù)目,本領域技術人員可根據(jù)具體應用而指定不同的數(shù)目。例如,針對不同類型的處理對象,諸如視頻或語音,迭代層級的數(shù)目可能需要不同的指定。
如圖4中所示,該單元包含但不僅限于如下幾個單元(又稱為模塊):
卷積單元,也可稱為convolver模塊:實現(xiàn)輸入數(shù)據(jù)與卷積核參數(shù)的乘法運算。
累加樹單元,也可稱為addertree模塊:累加卷積單元的輸出結果,完成卷積運算,有偏置輸入的情況下還加上偏置。
非線性單元,也可稱為nonlinear模塊:實現(xiàn)非線性激活函數(shù),根據(jù)需要可以為rectifier、sigmoid、tanh等函數(shù)。
池化單元,也可稱為pooling模塊,用于對非線性處理后的運算結果進行池化操作,以得到下一迭代級的輸入數(shù)據(jù)或最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量。這里的池化操作,根據(jù)需要可以為最大池化或平均池化。
圖5是根據(jù)本發(fā)明的全連接單元的具體結構示意圖。
本發(fā)明的全連接單元用于實現(xiàn)稀疏化全連接層的計算。與卷積與池化單元相類似,應該注意到,全連接單元對輸入向量不僅進行分塊化并行處理,而且對輸入向量進行若干層級的迭代處理。至于具體的迭代層級數(shù)目,本領域技術人員可根據(jù)具體應用而指定不同的數(shù)目。例如,針對不同類型的處理對象,諸如視頻或語音,迭代層級的數(shù)目可能需要不同的指定。此外,全連接單元的迭代層級的數(shù)目可以與卷積與池化層的迭代層級的數(shù)目相同或不同,這完全取決于具體的應用與本領域技術人員對計算結果的不同控制需求。
如圖5所示,該單元包含但不僅限于如下幾個單元(又稱為子模塊):
輸入向量緩存單元,也可稱為actqueue模塊:用于存儲稀疏神經(jīng)網(wǎng)絡的輸入向量。多計算單元(pe,processelement)可共享輸入向量。該模塊包含先進先出緩存(fifo),每個計算單元pe對應一個fifo,相同輸入元素下能有效平衡多個計算單元間計算量的差異。fifo深度的設置可以取經(jīng)驗值,過深會浪費資源,過小又不能有效平衡不同pe間的計算差異。
指針信息緩存單元,也可稱為ptrread模塊:用于根據(jù)全連接層權值矩陣位置信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息。如稀疏矩陣采用列存儲(ccs)的存儲格式,ptrread模塊存儲列指針向量,向量中的pj+1-pj值表示第j列中非零元素的個數(shù)。設計中有兩個緩存,采用ping-pang設計。
權重信息緩存單元,也可稱為spmatread模塊:用于根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息。這里所述的權重信息包括位置索引值和權重值等。通過ptrread模塊輸出的pj+1和pj值可獲得該模塊對應的權重值。該模塊緩存也是采用ping-pang設計。
算術邏輯單元,即alu模塊:用于根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息與輸入向量進行乘累加計算。具體地說,根據(jù)spmatread模塊送來的位置索引以及權重值,主要做三步計算:第一步,讀取神經(jīng)元的輸入向量和權重進行對應乘法計算;第二步,根據(jù)索引值讀取下一單元(actbuffer模塊,或輸出緩存單元)中對應位置歷史累加結果,再與第一步結果進行加法運算;第三步,根據(jù)位置索引值,將相加結果再寫入到輸出緩存單元中相應位置。為了提高并發(fā)度,本模塊采用多個乘法和加法樹來完成一列中的非零元素的乘累加運算。
輸出緩存單元,也稱為actbuffer模塊:用于緩存算術邏輯單元的矩陣運算的中間計算結果以及最終計算結果。為提高下一級的計算效率,存儲也采用ping-pang設計,流水線操作。
激活函數(shù)單元,也稱為function模塊:用于對輸出緩存單元中的最終計算結果進行激活函數(shù)運算。常見的激活函數(shù)諸如sigmoid/tanh/rectifier等。當加法樹模塊完成了各組權重與向量的疊加運算后,經(jīng)該函數(shù)后可獲得稀疏卷積神經(jīng)網(wǎng)絡的計算結果。
本發(fā)明的控制單元負責全局控制,卷積與池化層的數(shù)據(jù)輸入選擇額,卷積參數(shù)與輸入數(shù)據(jù)的讀取,全連接層中稀疏矩陣與輸入向量的讀取,計算過程中的狀態(tài)機控制等。
根據(jù)以上參考描述,并參考圖3至圖5的圖示說明,本發(fā)明還提供一種用于實現(xiàn)稀疏cnn網(wǎng)絡加速器的方法,具體步驟包括:
步驟1:初始化依據(jù)全局控制信息讀取cnn卷積層的參數(shù)與輸入數(shù)據(jù),讀取全連接層權值矩陣的位置信息。
步驟2:convolver模塊進行輸入數(shù)據(jù)與參數(shù)的乘法操作,多個convolver模塊軻同時計算實現(xiàn)并行化。
步驟3:addertree模塊將前一步驟的結果相加并在有偏置(bias)的情況下與偏置求和。
步驟4:nonlinear模塊對前一步結果進行非線性處理。
步驟5;pooling模塊對前一步結果進行池化處理。
其中步驟2、3、4、5流水進行以提高效率。
步驟6:根據(jù)卷積層的迭代層級數(shù)目重復進行步驟2、3、4、5。在此期間,controller模塊控制將上一次卷積和池化的結果連接至卷積層的輸入端,直到所有層都計算完成。
步驟7:根據(jù)步驟1的權值矩陣位置信息讀取稀疏神經(jīng)網(wǎng)絡的位置索引、權重值。
步驟8:根據(jù)全局控制信息,把輸入向量廣播給多個計算單元pe。
步驟9:計算單元把spmatread模塊送來的權重值跟actqueue模塊送來的輸入向量對應元素做乘法計算。
步驟10,計算模塊根據(jù)步驟7的位置索引值讀取輸出緩存actbuffer模塊中相應位置的數(shù)據(jù),然后跟步驟9的乘法結果做加法計算。
步驟11:根據(jù)步驟7的索引值把步驟10的加法結果寫入輸出緩存actbuffer模塊中。
步驟12:控制模塊讀取步驟11中輸出的結果經(jīng)激活函數(shù)模塊后得到cnnfc層的計算結果。
步驟7-12也可以根據(jù)指定的迭代層級數(shù)目而重復進行,從而得到最終的稀疏cnn的計算結果。
可以將上述的步驟1-12概括為一個方法流程圖。
圖6是根據(jù)本發(fā)明的用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的方法的流程圖。
圖6所示的方法流程圖s600開始于步驟s601。在此步驟,依據(jù)控制信息而讀取卷積參數(shù)信息與輸入數(shù)據(jù)與中間計算數(shù)據(jù),并且讀取全連接層權值矩陣位置信息。這一步驟對應于根據(jù)本發(fā)明的裝置中的控制單元的操作。
接下來,在步驟s603,根據(jù)卷積參數(shù)信息對輸入數(shù)據(jù)進行第一迭代次數(shù)的卷積與池化操作,以最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量,其中,每個輸入數(shù)據(jù)被分割為多個子塊,對多個子塊并行進行卷積與池化操作。這一步驟對應于根據(jù)本發(fā)明的裝置中的卷積與池化單元的操作。
更具體地說,步驟s603的操作進一步包括:
1、進行輸入數(shù)據(jù)與卷積參數(shù)的乘法運算,對應于卷積單元的操作;
2、累加乘法運算的輸出結果,以完成卷積運算,對應于累加樹單元的操作;這里,如果卷積參數(shù)信息指出偏置的存在,再還需要加上偏置;
3、對卷積運算結果進行非線性處理,對應于非線性單元的操作;
4、對非線性處理后的運算結果進行池化操作,以得下一迭代級的輸入數(shù)據(jù)或最終得到稀疏神經(jīng)網(wǎng)絡的輸入向量,對應于池化單元的操作。
接下來,在步驟s605,根據(jù)全連接層權值矩陣位置信息對輸入向量進行第二迭代次數(shù)的全連接計算,以最終得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果,其中,每個輸入向量被分割為多個子塊,并行進行全連接操作。這一步驟對應于根據(jù)本發(fā)明的裝置中的全連接單元的操作。
更具體地說,步驟s605的操作進一步包括:
1、緩存稀疏神經(jīng)網(wǎng)絡的輸入向量,對應于輸入向量緩存單元的操作;
2、根據(jù)全連接層權值矩陣位置信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息,對應于指針信息緩存單元的操作;
3、根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的指針信息,緩存壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息,對應于權重信息緩存單元的操作;
4、根據(jù)壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息與輸入向量進行乘累加計算,對應于算術邏輯單元的操作;
5、緩存乘累加計算的中間計算結果以及最終計算結果,對應于輸出緩存單元的操作;
6、對乘累加計算的最終計算結果進行激活函數(shù)運算,以得到稀疏卷積神經(jīng)網(wǎng)絡的計算結果,對應于激活函數(shù)單元的操作。
在步驟s605中,所述壓縮后的稀疏神經(jīng)網(wǎng)絡的權重信息包括位置索引值和權重值。因此,其中的子步驟4進一步包括:
4.1、將權重值與輸入向量的對應元素進行乘法運算,
4.2、根據(jù)位置索引值,讀取所緩存的中間計算結果中相應位置的數(shù)據(jù),與上述乘法運算的結果相加,
4.3、根據(jù)位置索引值,將相加結果寫入到所緩存的中間計算結果中相應位置。
在執(zhí)行完步驟s605之后,就得到了稀疏卷積神經(jīng)網(wǎng)絡的計算結果。由此,方法流程圖s600結束。
非專利文獻songhanetal.,eie:efficientinferenceengineoncompresseddeepneuralnetwork,isca2016:243-254中提出了一種加速器硬件實現(xiàn)eie,旨在利用cnn的信息冗余度比較高的特點,使得壓縮后得到的神經(jīng)網(wǎng)絡參數(shù)可以完全分配到sram上,從而極大地減少了dram的訪問次數(shù),由此可以取得很好的性能和性能功耗比。與沒有壓縮的神經(jīng)網(wǎng)絡加速器dadiannao相比,eie的吞吐率提高了2.9倍,性能能耗比提高了19倍,而面積只有dadiannao的1/3。在此,將該非專利文獻的內(nèi)容通過援引全部加入到本申請的說明書中。
本發(fā)明提議的稀疏cnn加速器的實現(xiàn)裝置和方法與eie論文的區(qū)別在于:eie設計中有一個計算單元,一個周期僅能實現(xiàn)一個乘加計算,而一個計算核前后模塊卻需要較多的存儲和邏輯單元。無論是專用集成電路(asic)還是可編程芯片都會帶來資源的相對不均衡。實現(xiàn)過程中并發(fā)度越高,需要的片上存儲以及邏輯資源相對越多,芯片中需要的計算資源dsp與上述兩者越不均衡。本發(fā)明計算單元采用高并發(fā)設計,在增加了dsp資源的同時,沒有使得其他的邏輯電路相應的增加,達到了平衡計算、片上存儲、邏輯資源之間的關系等目的。
下面結合圖7至圖9來看本發(fā)明的兩個具體實現(xiàn)例。
具體實現(xiàn)例1:
圖7是根據(jù)本發(fā)明的具體實現(xiàn)例1的計算層結構的示意圖。
如圖7所示,以alexnet為例,該網(wǎng)絡除輸入輸出外,包含八層,五個卷積層與三個全連接層。第一層為卷積+池化,第二層為卷積+池化,第三層為卷積,第四層為卷積,第五層為卷積+池化,第六層為全連接,第七層為全連接,第八層為全連接。
該cnn結構可用本發(fā)明的專用電路實現(xiàn),第1-5層由convolution+pooling模塊(卷積與池化單元)按順序分時實現(xiàn),由controller模塊(控制單元)控制convolution+pooling模塊的數(shù)據(jù)輸入,參數(shù)配置以及內(nèi)部電路連接,例如當不需要池化時,可由controller模塊控制數(shù)據(jù)流直接跳過pooling模塊。該網(wǎng)絡的第6-8層由本發(fā)明的fullconnection模塊按順序分時實現(xiàn),由controller模塊控制fullconnection模塊的數(shù)據(jù)輸入、參數(shù)配置以及內(nèi)部電路連接等。
具體實現(xiàn)例2:
圖8是根據(jù)本發(fā)明的具體實現(xiàn)例2圖示說明稀疏矩陣與向量的乘法操作的示意圖。
對于fc層的稀疏矩陣與向量的乘法操作,以4個計算單元(processelement,pe)計算一個矩陣向量乘,采用列存儲(ccs)為例進行詳細說明。
如圖8所示,第1、5行元素由pe0完成,第2、6行元素由pe1完成,第3、7行元素由pe2完成,第4、8行元素由pe3完成,計算結果分別對應輸出向量的第1、5個元素,第2、6個元素,第3、7個元素,第4、8個元素。輸入向量會廣播給4個計算單元。
圖9是根據(jù)本發(fā)明的具體實現(xiàn)例2圖示說明pe0對應的權重信息的示意表格。
如圖9所示,該表格示出了pe0對應的權重信息。
以下介紹在pe0的各個模塊中的作用。
ptrread模塊0(指針):存儲1、5行非零元素的列位置信息,其中p(j+1)-p(j)為第j列中非零元素的個數(shù)。
spmatread模塊0:存儲1、5行非零元素的權重值和相對行索引。
actqueue模塊:存儲輸入向量x,該模塊把輸入向量廣播給4個計算單元pe0、pe1、pe2、pe3,為了平衡計算單元間元素稀疏度的差異,每個計算單元的入口都添加先進先出緩存(fifo)來提高計算效率。
controller模塊:控制系統(tǒng)狀態(tài)機的跳轉,實現(xiàn)計算控制,使得各模塊間信號同步,從而實現(xiàn)權值與對應輸入向量的元素做乘,對應行值做累加。
alu模塊:完成權值矩陣奇數(shù)行元素與輸入向量x對應元素的乘累加。
actbuffer模塊:存放中間計算結果以及最終y的第1、5個元素。
與上類似,另一個計算單元pe1,計算y的2、6個元素,其他pe以此類推。
上面已經(jīng)描述了本發(fā)明的各種實施例和實施情形。但是,本發(fā)明的精神和范圍不限于此。本領域技術人員將能夠根據(jù)本發(fā)明的教導而做出更多的應用,而這些應用都在本發(fā)明的范圍之內(nèi)。
- 還沒有人留言評論。精彩留言會獲得點贊!
- 基于分層稀疏濾波卷積神經(jīng)網(wǎng)絡的sar圖像分類方法
- 訓練神經(jīng)網(wǎng)絡的方法和裝置以及確定稀疏特征向量的方法
- 稀疏化的u-tdoa無線定位網(wǎng)絡的制作方法
- 稀疏化的u-tdoa無線定位網(wǎng)絡的制作方法
- 稀疏化的u-tdoa無線定位網(wǎng)絡的制作方法
- 稀疏化的u-tdoa無線定位網(wǎng)絡的制作方法
- 稀疏網(wǎng)絡歷書的制作方法
- 一種新型的稀疏移動Ad Hoc網(wǎng)絡消息簽名方法
- 一種基于神經(jīng)網(wǎng)絡解決協(xié)同過濾推薦數(shù)據(jù)稀疏性的方法
- 數(shù)字信號處理器中執(zhí)行多個向量稀疏卷積方法與系統(tǒng)的制作方法
- 一種基于深度神經(jīng)網(wǎng)絡的人群情緒異常檢測和定位方法與流程
- 一種基于深度卷積神經(jīng)網(wǎng)絡的汽車駕駛場景目標檢測方法與流程
- 基于卷積神經(jīng)網(wǎng)絡特征編碼的人體動作識別方法與流程
- 一種情感識別方法及裝置與流程
- 一種混合長短期記憶網(wǎng)絡和卷積神經(jīng)網(wǎng)絡的文本分類方法與流程
- 一種融合多特征的雙向循環(huán)神經(jīng)網(wǎng)絡細粒度意見挖掘方法與流程
- 一種改進的浮點乘加器及浮點乘加計算方法與流程
- 基于區(qū)域卷積神經(jīng)網(wǎng)絡的第一視角手勢識別與交互方法與流程
- 一種基于神經(jīng)網(wǎng)絡的鋰電池SOC觀測方法與流程
- 一種基于BP神經(jīng)網(wǎng)絡的人工智能優(yōu)化方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的圖像處理方法、裝置及移動終端與流程
- 結合LBP特征圖與卷積神經(jīng)網(wǎng)絡的人臉識別方法與流程
- 一種利用卷積神經(jīng)網(wǎng)絡的醫(yī)學圖像處理裝置與方法與流程
- 一種基于1D卷積神經(jīng)網(wǎng)絡的室性異位搏動檢測方法與流程
- 用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置和方法與流程
- 基于多任務級聯(lián)卷積神經(jīng)網(wǎng)絡的人臉檢測方法及檢測裝置與流程
- 一種基于卷積神經(jīng)網(wǎng)絡和主成分分析法的肺結節(jié)特征提取方法與流程
- 基于一維卷積神經(jīng)網(wǎng)絡的雷達輻射源信號的識別方法與流程
- 基于深度卷積神經(jīng)網(wǎng)絡的乳腺癌風險評估分析系統(tǒng)的制造方法與工藝
- 一種基于醫(yī)學征象和卷積神經(jīng)網(wǎng)絡的肺結節(jié)CT圖像哈希檢索方法與流程
- 對花卉識別系統(tǒng)進行改進的輔助系統(tǒng)和進行改進的方法與流程
- 一種基于卷積神經(jīng)的農(nóng)作物害蟲圖像識別方法與流程
- 一種基于雙流卷積神經(jīng)網(wǎng)絡的立體匹配方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的圖像處理方法、裝置及移動終端與流程
- 一種基于卷積深度網(wǎng)絡的圖像識別算法及系統(tǒng)的制造方法與工藝
- 一種利用卷積神經(jīng)網(wǎng)絡的醫(yī)學圖像處理裝置與方法與流程
- 基于BP神經(jīng)網(wǎng)絡算法的電力變壓器故障診斷裝置及方法與流程
- 一種基于1D卷積神經(jīng)網(wǎng)絡的室性異位搏動檢測方法與流程
- 用于實現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡加速器的裝置和方法與流程
- 基于多任務級聯(lián)卷積神經(jīng)網(wǎng)絡的人臉檢測方法及檢測裝置與流程
- 一種基于卷積神經(jīng)網(wǎng)絡和主成分分析法的肺結節(jié)特征提取方法與流程
- 基于一維卷積神經(jīng)網(wǎng)絡的雷達輻射源信號的識別方法與流程
- 基于深度卷積神經(jīng)網(wǎng)絡的乳腺癌風險評估分析系統(tǒng)的制造方法與工藝
- 一種基于醫(yī)學征象和卷積神經(jīng)網(wǎng)絡的肺結節(jié)CT圖像哈希檢索方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的APP相似圖標檢索方法和系統(tǒng)與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的企業(yè)實體關系抽取的方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡自適應背景建模物體檢測方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的輸電線路螺栓檢測方法與流程
- 一種基于FPGA的卷積神經(jīng)網(wǎng)絡實現(xiàn)方法及裝置與流程
- 一種基于多個分類器的卷積神經(jīng)網(wǎng)絡快速分類方法與流程
- 基于全卷積神經(jīng)網(wǎng)絡的極化SAR地物分類方法與流程
- 基于一維卷積神經(jīng)網(wǎng)絡的雷達輻射源信號的識別方法與流程
- 基于深度卷積神經(jīng)網(wǎng)絡的乳腺癌風險評估分析系統(tǒng)的制造方法與工藝
- 一種基于醫(yī)學征象和卷積神經(jīng)網(wǎng)絡的肺結節(jié)CT圖像哈希檢索方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的APP相似圖標檢索方法和系統(tǒng)與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的企業(yè)實體關系抽取的方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡自適應背景建模物體檢測方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡的輸電線路螺栓檢測方法與流程
- 一種基于多個分類器的卷積神經(jīng)網(wǎng)絡快速分類方法與流程
- 一種基于全卷積神經(jīng)網(wǎng)絡的SAR圖像目標檢測方法與流程