一種基于卷積神經(jīng)網(wǎng)絡(luò)的APP相似圖標(biāo)檢索方法和系統(tǒng)與流程
本發(fā)明屬于數(shù)據(jù)檢索領(lǐng)域,更具體地,涉及一種基于卷積神經(jīng)網(wǎng)絡(luò)的app相似圖標(biāo)檢索方法和系統(tǒng)。
背景技術(shù):
隨著互聯(lián)網(wǎng)的發(fā)展以及智能手機(jī)普及率的提高,手持移動(dòng)終端得到了巨大的發(fā)展,伴隨而來的是手機(jī)端應(yīng)用程序數(shù)量的增加,對(duì)于用戶以及安全性檢測(cè)人員而言通過手機(jī)應(yīng)用程序圖標(biāo)來快速的搜索出對(duì)應(yīng)的或者相似的手機(jī)應(yīng)用程序是一件非常困難的事情。對(duì)此,需要用到圖像檢索技術(shù)。
當(dāng)前的圖像檢索技術(shù)主要集中在基于文本的檢索以及基于內(nèi)容的檢索。基于文本的檢索是指對(duì)圖像文件建立關(guān)鍵字或文本標(biāo)題以及一些附加信息對(duì)圖像進(jìn)行描述,然后將圖像的存儲(chǔ)路徑和圖像的關(guān)鍵詞建立聯(lián)系。它的缺點(diǎn)在于:隨著大量圖像的出現(xiàn),需要大量的勞動(dòng)力去管理和注釋這些圖像:不同的人對(duì)同一幅圖像的理解不同,文本描述信息相對(duì)主觀;不同國家的人由于語言的差異會(huì)造成對(duì)同一圖像的語義理解的差異。因而僅僅基于關(guān)鍵詞的檢索已不能滿足用戶的檢索要求。不僅如此,傳統(tǒng)的數(shù)據(jù)庫檢索結(jié)果與信息的組織方式及查詢結(jié)果的顯示方式有關(guān),而無法按照查詢結(jié)果的相似程度進(jìn)行輸出。能夠?qū)Χ嗝襟w數(shù)據(jù)內(nèi)容進(jìn)行自動(dòng)語義分析、表達(dá)和檢索是數(shù)據(jù)庫及其它信息系統(tǒng)的發(fā)展趨勢(shì)。
基于內(nèi)容的主要做法是提取圖像的特征,然后再根據(jù)圖像特征進(jìn)行相似度的計(jì)算,目前在大規(guī)模數(shù)據(jù)中較多的算法有d-hash、sift、lbp等算法,但是這些算法的缺點(diǎn)也是比較明顯,對(duì)于d-hash算法而言,檢索效率比較高,但是準(zhǔn)確率很低,而且該算法對(duì)輪廓的敏感度太高,不能用在輪廓一致的圖像中檢索;對(duì)于sifi算法,相對(duì)于d-hash算法而言,該算法具有很高的準(zhǔn)確率,但是該算法的復(fù)雜度很高,不僅在計(jì)算sift特征時(shí),最主要的是在檢索時(shí),sift特征由n個(gè)128維的浮點(diǎn)型向量組成,在兩幅圖像進(jìn)行相似度計(jì)算時(shí)計(jì)算量非常大,而且sift算法在大規(guī)模的數(shù)據(jù)中進(jìn)行檢索時(shí),只能采用線性計(jì)算的方法,在全庫中檢索時(shí)需要與全庫中的每一張圖像進(jìn)行一次相似度的計(jì)算,這大大提高了檢索的時(shí)間。
由此可見,現(xiàn)有技術(shù)存在檢索效率低和檢索準(zhǔn)確率低的技術(shù)問題。
技術(shù)實(shí)現(xiàn)要素:
針對(duì)現(xiàn)有技術(shù)的以上缺陷或改進(jìn)需求,本發(fā)明提供了一種基于卷積神經(jīng)網(wǎng)絡(luò)的app(armorpiercingproof,計(jì)算機(jī)應(yīng)用程序)相似圖標(biāo)檢索方法和系統(tǒng),其目的在于將樣本特征向量、樣本文件標(biāo)識(shí)和索引存入檢索系統(tǒng),對(duì)組合特征向量,在檢索系統(tǒng)中進(jìn)行檢索,得到文件標(biāo)識(shí)集合,將文件標(biāo)識(shí)集合取并集,在并集中進(jìn)行線性計(jì)算,得到樣本app圖標(biāo)與目標(biāo)app圖標(biāo)的相似度,利用相似度對(duì)樣本app圖標(biāo)進(jìn)行排序。由此解決現(xiàn)有技術(shù)存在檢索效率低和檢索準(zhǔn)確率低的技術(shù)問題。
為實(shí)現(xiàn)上述目的,按照本發(fā)明的一個(gè)方面,提供了一種基于卷積神經(jīng)網(wǎng)絡(luò)的app相似圖標(biāo)檢索方法,包括:
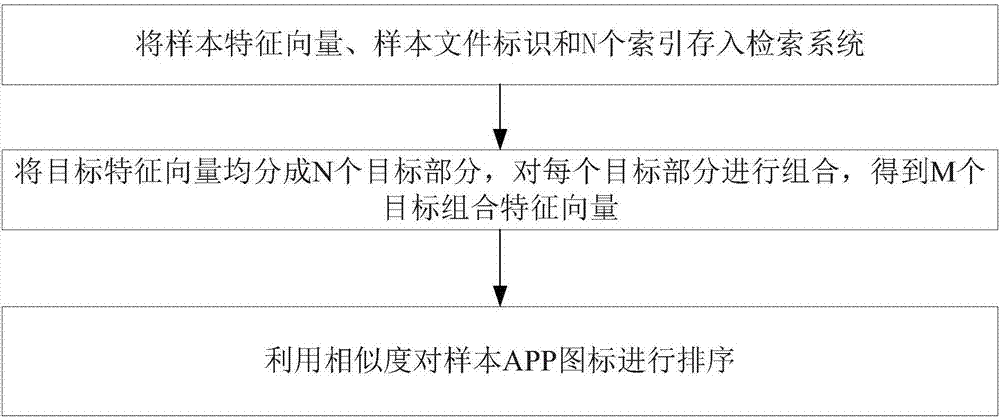
(1)對(duì)于樣本app圖標(biāo),基于卷積神經(jīng)網(wǎng)絡(luò)提取樣本特征向量,記錄樣本特征向量的樣本文件標(biāo)識(shí),將樣本特征向量均分成n個(gè)樣本部分,在每個(gè)樣本部分建立一個(gè)索引,得到n個(gè)索引,將樣本特征向量、樣本文件標(biāo)識(shí)和n個(gè)索引存入檢索系統(tǒng);
(2)對(duì)于目標(biāo)app圖標(biāo),基于卷積神經(jīng)網(wǎng)絡(luò)提取目標(biāo)特征向量,將目標(biāo)特征向量均分成n個(gè)目標(biāo)部分,對(duì)每個(gè)目標(biāo)部分進(jìn)行組合,得到m個(gè)目標(biāo)組合特征向量;
(3)對(duì)m個(gè)組合特征向量,在檢索系統(tǒng)中進(jìn)行m次檢索,得到m個(gè)文件標(biāo)識(shí)集合,將m個(gè)文件標(biāo)識(shí)集合取并集,在并集中進(jìn)行線性計(jì)算,得到樣本app圖標(biāo)與目標(biāo)app圖標(biāo)的相似度,利用相似度對(duì)樣本app圖標(biāo)進(jìn)行排序。
進(jìn)一步的,步驟(1)還包括對(duì)樣本app圖標(biāo)進(jìn)行預(yù)處理,步驟(2)還包括對(duì)目標(biāo)app圖標(biāo)進(jìn)行預(yù)處理。
進(jìn)一步的,預(yù)處理包括:圖像灰度化、圖像放縮和圖像歸一化。
進(jìn)一步的,步驟(1)還包括對(duì)樣本特征向量進(jìn)行哈希化處理,步驟(2)還包括對(duì)目標(biāo)特征向量進(jìn)行哈希化處理。
進(jìn)一步的,哈希化處理的具體實(shí)現(xiàn)方式為:設(shè)定一個(gè)閾值,將特征向量x映射為二進(jìn)制向量f(x),
按照本發(fā)明的另一方面,提供了一種基于卷積神經(jīng)網(wǎng)絡(luò)的app相似圖標(biāo)檢索系統(tǒng),包括:
檢索系統(tǒng)模塊,用于對(duì)于樣本app圖標(biāo),基于卷積神經(jīng)網(wǎng)絡(luò)提取樣本特征向量,記錄樣本特征向量的樣本文件標(biāo)識(shí),將樣本特征向量均分成n個(gè)樣本部分,在每個(gè)樣本部分建立一個(gè)索引,得到n個(gè)索引,將樣本特征向量、樣本文件標(biāo)識(shí)和n個(gè)索引存入檢索系統(tǒng);
組合特征向量模塊,用于對(duì)于目標(biāo)app圖標(biāo),基于卷積神經(jīng)網(wǎng)絡(luò)提取目標(biāo)特征向量,將目標(biāo)特征向量均分成n個(gè)目標(biāo)部分,對(duì)每個(gè)目標(biāo)部分進(jìn)行組合,得到m個(gè)目標(biāo)組合特征向量;
圖標(biāo)排序模塊,用于對(duì)m個(gè)組合特征向量,在檢索系統(tǒng)中進(jìn)行m次檢索,得到m個(gè)文件標(biāo)識(shí)集合,將m個(gè)文件標(biāo)識(shí)集合取并集,在并集中進(jìn)行線性計(jì)算,得到樣本app圖標(biāo)與目標(biāo)app圖標(biāo)的相似度,利用相似度對(duì)樣本app圖標(biāo)進(jìn)行排序。
進(jìn)一步的,檢索系統(tǒng)模塊還包括對(duì)樣本app圖標(biāo)進(jìn)行預(yù)處理,組合特征向量模塊還包括對(duì)目標(biāo)app圖標(biāo)進(jìn)行預(yù)處理。
進(jìn)一步的,預(yù)處理包括:圖像灰度化、圖像放縮和圖像歸一化。
進(jìn)一步的,檢索系統(tǒng)模塊還包括對(duì)樣本特征向量進(jìn)行哈希化處理,組合特征向量模塊還包括對(duì)目標(biāo)特征向量進(jìn)行哈希化處理。
進(jìn)一步的,哈希化處理的具體實(shí)現(xiàn)方式為:設(shè)定一個(gè)閾值,將特征向量x映射為二進(jìn)制向量f(x),
總體而言,通過本發(fā)明所構(gòu)思的以上技術(shù)發(fā)明與現(xiàn)有技術(shù)相比,能夠取得下列有益效果:
(1)本發(fā)明將樣本特征向量、樣本文件標(biāo)識(shí)和索引存入檢索系統(tǒng),對(duì)組合特征向量,在檢索系統(tǒng)中進(jìn)行檢索,得到文件標(biāo)識(shí)集合,將文件標(biāo)識(shí)集合取并集,在并集中進(jìn)行線性計(jì)算,得到樣本app圖標(biāo)與目標(biāo)app圖標(biāo)的相似度,利用相似度對(duì)樣本app圖標(biāo)進(jìn)行排序。進(jìn)而克服了傳統(tǒng)圖像檢索中準(zhǔn)確率低,檢索效率不高的問題,同時(shí)為用戶提供很大的方便,可以根據(jù)圖標(biāo)來搜索對(duì)應(yīng)的手機(jī)應(yīng)用程序;同時(shí)也為安全檢測(cè)人員對(duì)于仿冒app的檢測(cè)提供了一個(gè)新的途徑;更為重要的是為銀行或者一些機(jī)構(gòu)打擊仿冒app或者發(fā)布安全警告等提供了技術(shù)支持。
(2)優(yōu)選的,本發(fā)明對(duì)樣本app圖標(biāo)和目標(biāo)app圖標(biāo)進(jìn)行預(yù)處理,將圖標(biāo)圖像的規(guī)格統(tǒng)一化,保證了計(jì)算的高效性。
(3)優(yōu)選的,本發(fā)明對(duì)樣本app圖標(biāo)和目標(biāo)app圖標(biāo)進(jìn)行哈希化處理,提高了檢索效率。
(4)優(yōu)選的,本發(fā)明對(duì)樣本app圖標(biāo)和目標(biāo)app圖標(biāo)進(jìn)行哈希化處理,設(shè)定閾值為0.5,在保證檢索效率的同時(shí),提高了檢索準(zhǔn)確率。
附圖說明
圖1是本發(fā)明實(shí)施例提供的一種基于卷積神經(jīng)網(wǎng)絡(luò)的app相似圖標(biāo)檢索方法的流程圖;
圖2是本發(fā)明實(shí)施例提供的卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)示意圖;
圖3是本發(fā)明實(shí)施例將目標(biāo)特征向量均分和轉(zhuǎn)換的示意圖。
具體實(shí)施方式
為了使本發(fā)明的目的、技術(shù)發(fā)明及優(yōu)點(diǎn)更加清楚明白,以下結(jié)合附圖及實(shí)施例,對(duì)本發(fā)明進(jìn)行進(jìn)一步詳細(xì)說明。應(yīng)當(dāng)理解,此處所描述的具體實(shí)施例僅僅用以解釋本發(fā)明,并不用于限定本發(fā)明。此外,下面所描述的本發(fā)明各個(gè)實(shí)施方式中所涉及到的技術(shù)特征只要彼此之間未構(gòu)成沖突就可以相互組合。
如圖1所示,一種基于卷積神經(jīng)網(wǎng)絡(luò)的app相似圖標(biāo)檢索方法,包括:
(1)對(duì)于樣本app圖標(biāo),基于卷積神經(jīng)網(wǎng)絡(luò)提取樣本特征向量,記錄樣本特征向量的樣本文件標(biāo)識(shí),將樣本特征向量均分成n個(gè)樣本部分,在每個(gè)樣本部分建立一個(gè)索引,得到n個(gè)索引,將樣本特征向量、樣本文件標(biāo)識(shí)和n個(gè)索引存入檢索系統(tǒng);
(2)對(duì)于目標(biāo)app圖標(biāo),基于卷積神經(jīng)網(wǎng)絡(luò)提取目標(biāo)特征向量,將目標(biāo)特征向量均分成n個(gè)目標(biāo)部分,對(duì)每個(gè)目標(biāo)部分進(jìn)行組合,得到m個(gè)目標(biāo)組合特征向量;
(3)對(duì)m個(gè)組合特征向量,在檢索系統(tǒng)中進(jìn)行m次檢索,得到m個(gè)文件標(biāo)識(shí)集合,將m個(gè)文件標(biāo)識(shí)集合取并集,在并集中進(jìn)行線性計(jì)算,得到樣本app圖標(biāo)與目標(biāo)app圖標(biāo)的相似度,利用相似度對(duì)樣本app圖標(biāo)進(jìn)行排序。
進(jìn)一步的,對(duì)樣本app圖標(biāo)和目標(biāo)app圖標(biāo)進(jìn)行預(yù)處理。
在對(duì)圖標(biāo)進(jìn)行檢索時(shí),為了提取圖標(biāo)的特征向量,需要將圖像的規(guī)格統(tǒng)一化,本發(fā)明中對(duì)于圖標(biāo)圖像的預(yù)處理主要有三個(gè)步驟:圖像灰度化、圖像放縮、圖像歸一化。
圖標(biāo)圖像采用的是rgb的編碼方式,一個(gè)像素點(diǎn)由一個(gè)三維的向量表示如(r,g,b),但是由于設(shè)計(jì)的卷積神經(jīng)網(wǎng)絡(luò)的輸入是一維的,同時(shí)為了計(jì)算的高效性,所以需要將圖標(biāo)圖像進(jìn)行灰度化的轉(zhuǎn)換,本發(fā)明中采用的灰度轉(zhuǎn)化算法如下:
gray(i,j)=0.299*r(i,j)+0.578*g(i,j)+0.114*b(i,j)
(i,j)是像素點(diǎn)坐標(biāo),gray(i,j)是像素點(diǎn)坐標(biāo)為(i,j)時(shí)的灰度值,r(i,j)是像素點(diǎn)坐標(biāo)為(i,j)時(shí)的r通道,g(i,j)是像素點(diǎn)坐標(biāo)為(i,j)時(shí)的g通道,b(i,j)是像素點(diǎn)坐標(biāo)為(i,j)時(shí)的b通道。
對(duì)于樣本app圖標(biāo)和目標(biāo)app圖標(biāo),圖標(biāo)圖像大小不一,同時(shí)卷積神經(jīng)網(wǎng)絡(luò)的輸入大小固定,需要對(duì)圖標(biāo)進(jìn)行縮小或者放大,本發(fā)明中采用了雙線性插值法,對(duì)于一個(gè)目標(biāo)像素點(diǎn),通過反向變換得到它的浮點(diǎn)坐標(biāo)為(i+u,j+v),其中i、j是原始圖像中的坐標(biāo)點(diǎn),u、v為區(qū)間[0,1)之間的浮點(diǎn)數(shù),則目標(biāo)像素點(diǎn)的值可以由原始圖像中最鄰近的四個(gè)點(diǎn)的值來確定,相應(yīng)的公式為:
其中,f(i,j)是原始圖像中(i,j)處的像素值,依次類推,f(i,j+1)是原始圖像中(i,j+1)處的像素值,f(i+1,j)是原始圖像中(i+1,j)處的像素值,f(i+1,j+1)是原始圖像中(i+1,j+1)處的像素值,使用周圍的四個(gè)點(diǎn)計(jì)算出目標(biāo)像素(i+u,j+v)的像素值f(i+u,j+v)。
第三個(gè)要做的是對(duì)圖像進(jìn)行歸一化,本發(fā)明采用線性歸一化的算法,具體公式如下:
設(shè)定min(x)為0,max(x)為255,然后代入上面的公式,x為使用周圍的四個(gè)點(diǎn)計(jì)算出目標(biāo)像素(i+u,j+v)的像素值f(i+u,j+v),計(jì)算出歸一化之后的像素值x。
進(jìn)一步的,對(duì)預(yù)處理后的圖標(biāo)進(jìn)行特征向量提取,深度學(xué)習(xí)出現(xiàn)之前較為傳統(tǒng)的辦法都是人工設(shè)定的特征向量提取規(guī)則,本發(fā)明采用了最前沿的研究成果,使用深度學(xué)習(xí)技術(shù)來對(duì)圖標(biāo)圖像特征向量進(jìn)行提取,并且使提取出來的特征向量易于在大規(guī)模的數(shù)據(jù)中進(jìn)行相似度的計(jì)算。
具體的做法如下:
設(shè)計(jì)卷積神經(jīng)網(wǎng)絡(luò),參照alexnet網(wǎng)絡(luò)結(jié)構(gòu),在第七層與第八層之間添加一個(gè)全連接層,該層的維度為64,并且采用softmax函數(shù)作為激活函數(shù),具體設(shè)計(jì)如圖2所示。
訓(xùn)練上一步設(shè)計(jì)的神經(jīng)網(wǎng)絡(luò),使用caffe深度學(xué)習(xí)框架進(jìn)行訓(xùn)練調(diào)參,由于待檢索的圖像沒有標(biāo)簽,無法使用待檢索數(shù)據(jù)進(jìn)行訓(xùn)練,所以使用公開的帶標(biāo)簽的數(shù)據(jù)集對(duì)網(wǎng)絡(luò)模型進(jìn)行訓(xùn)練,本發(fā)明采用的訓(xùn)練數(shù)據(jù)集為imagenet中的數(shù)據(jù)。
使用訓(xùn)練好的卷積神經(jīng)網(wǎng)絡(luò)對(duì)全庫的圖標(biāo)進(jìn)行離線的前向計(jì)算(forword),然后記錄下第八層的值。
通過以上步驟,每張圖像可以得到一個(gè)64維的特征向量,向量中每一維的值都是0到1之間的浮點(diǎn)數(shù),將該特征向量保存。
進(jìn)一步的,步驟(1)還包括對(duì)樣本特征向量進(jìn)行哈希化處理,步驟(2)還包括對(duì)目標(biāo)特征向量進(jìn)行哈希化處理。
進(jìn)一步的,哈希化處理的具體實(shí)現(xiàn)方式為:設(shè)定一個(gè)閾值,將特征向量x映射為二進(jìn)制向量f(x),
具體的,對(duì)于64維的特征向量進(jìn)行相似度的檢索效率會(huì)非常低,本發(fā)明采用了對(duì)特征向量進(jìn)行哈希化的方法,具體做法是設(shè)定一個(gè)閾值,發(fā)明中的閾值為0.5,然后將特征向量x映射為01二進(jìn)制向量,采用如下公式:
通過以上方法,64維的特征向量變成了64維的二進(jìn)制向量,該64維的二進(jìn)制向量作為最終的特征向量。
根據(jù)對(duì)前面局部敏感哈希算法的介紹,本發(fā)明中的檢索問題也轉(zhuǎn)換成為高維空間中的相似搜索問題,為了解決這個(gè)問題,本發(fā)明采用了lsh算法的核心思想,將特征根據(jù)不同的哈希函數(shù)放入不同的桶中,然后在檢索時(shí),在相同的桶中做檢索。本發(fā)明根據(jù)lsh算法思想,將特征均勻的分為四個(gè)部分,這四個(gè)部分當(dāng)做keyl、key2、key3、key4,keyl為0101010111000101,key2為0001100110000111,key3為0010100110001101,key4為0110001100011100,每個(gè)特征都是一個(gè)16維的二進(jìn)制向量,然后將這些二進(jìn)制向量轉(zhuǎn)換為一個(gè)十六進(jìn)制數(shù),作為最后的id,這樣特征轉(zhuǎn)換成了4個(gè)id:idl、id2、id3、id4,id1為55c5,id2為1987,id3為298d,id4為631c,每個(gè)id都是一個(gè)十六進(jìn)制的數(shù),如圖3所示。
對(duì)特征進(jìn)行處理之后,將特征存放到另一個(gè)搜索系統(tǒng)中,在本發(fā)明中,采用了elasticsearch搜索系統(tǒng),在es系統(tǒng)中建立新的索引(index),然后將每個(gè)特征作為文件標(biāo)識(shí)文檔(document)存入系統(tǒng)中,文件標(biāo)識(shí)文檔中包含的特征有:id1、id2、id3、id4、特征向量哈希化處理后的值、文件md5等屬性。
隨著app的增長,對(duì)于app的檢索技術(shù)的要求越來越高,通常app商店提供的搜索欄都是通過關(guān)鍵字來查找對(duì)應(yīng)的app,輸入app的關(guān)鍵字,然后去app的描述信息中查找對(duì)應(yīng)的app,這往往需要在將app錄入時(shí)輸入大量的描述信息,當(dāng)然這些信息也可以由開發(fā)人員輸入。但是,在對(duì)于安全行業(yè)的工作者來說,僅僅根據(jù)app的描述信息來對(duì)app進(jìn)行安全分析,是一件困難的事情,尤其是對(duì)一些仿冒的app的檢測(cè)而言,仿冒的app描述信息可能與真實(shí)的app不一樣,或者完全不相關(guān),但是仿冒的app在圖標(biāo)上與真實(shí)的app很相似,從用戶的角度很難區(qū)分這兩者的區(qū)別,為了區(qū)分出這些仿冒app,一個(gè)可行的辦法是根據(jù)該app的圖標(biāo)去搜索出相似的app,然后再根據(jù)這些相似app的集合去確定該app是不是仿冒app。從另一個(gè)安全情報(bào)分析的角度上考慮,基于app圖標(biāo)的搜索也是很有必要的,比如某銀行的app應(yīng)用被惡意的仿冒假冒,銀行為了發(fā)掘出有哪些仿冒者,有多少個(gè)仿冒的app時(shí),通過圖標(biāo)去進(jìn)行搜索,找出相似的app,然后過濾出良性的app,剩下的就可以找到被仿冒的一些app,進(jìn)一步可以查找仿冒app的開發(fā)者的信息,進(jìn)而追究法律責(zé)任。
本發(fā)明克服了傳統(tǒng)圖像檢索中準(zhǔn)確率低,檢索效率不高的問題,同時(shí)為用戶提供很大的方便,可以根據(jù)圖標(biāo)來搜索對(duì)應(yīng)的手機(jī)應(yīng)用程序;同時(shí)也為安全檢測(cè)人員對(duì)于仿冒app的檢測(cè)提供了一個(gè)新的途徑;更為重要的是為銀行或者一些機(jī)構(gòu)打擊仿冒app或者發(fā)布安全警告等提供了技術(shù)支持。
本領(lǐng)域的技術(shù)人員容易理解,以上所述僅為本發(fā)明的較佳實(shí)施例而已,并不用以限制本發(fā)明,凡在本發(fā)明的精神和原則之內(nèi)所作的任何修改、等同替換和改進(jìn)等,均應(yīng)包含在本發(fā)明的保護(hù)范圍之內(nèi)。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!
- 一種基于全卷積神經(jīng)網(wǎng)絡(luò)的SAR圖像目標(biāo)檢測(cè)方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的圖像像素分類方法與制造工藝
- 一種基于并行卷積神經(jīng)網(wǎng)絡(luò)的圖像質(zhì)量測(cè)試方法與制造工藝
- 一種基于深度卷積神經(jīng)網(wǎng)絡(luò)的圖像風(fēng)格遷移方法與制造工藝
- 用于基于卷積神經(jīng)網(wǎng)絡(luò)回歸的2D/3D圖像配準(zhǔn)的方法和系統(tǒng)與制造工藝
- 基于深度卷積?反卷積神經(jīng)網(wǎng)絡(luò)的夜視圖像場景識(shí)別方法與制造工藝
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的圖像白平衡方法、裝置和計(jì)算設(shè)備與制造工藝
- 一種基于卷積對(duì)神經(jīng)網(wǎng)絡(luò)的圖像去噪方法與制造工藝
- 基于中層語義屬性和卷積神經(jīng)網(wǎng)絡(luò)的SAR圖像分類方法與制造工藝
- 基于卷積神經(jīng)網(wǎng)絡(luò)的圖片檢索方法、裝置和服務(wù)器的制造方法
- 一種基于深度神經(jīng)網(wǎng)絡(luò)的人群情緒異常檢測(cè)和定位方法與流程
- 一種基于深度卷積神經(jīng)網(wǎng)絡(luò)的汽車駕駛場景目標(biāo)檢測(cè)方法與流程
- 基于卷積神經(jīng)網(wǎng)絡(luò)特征編碼的人體動(dòng)作識(shí)別方法與流程
- 一種情感識(shí)別方法及裝置與流程
- 一種混合長短期記憶網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)的文本分類方法與流程
- 一種融合多特征的雙向循環(huán)神經(jīng)網(wǎng)絡(luò)細(xì)粒度意見挖掘方法與流程
- 一種改進(jìn)的浮點(diǎn)乘加器及浮點(diǎn)乘加計(jì)算方法與流程
- 基于區(qū)域卷積神經(jīng)網(wǎng)絡(luò)的第一視角手勢(shì)識(shí)別與交互方法與流程
- 一種基于神經(jīng)網(wǎng)絡(luò)的鋰電池SOC觀測(cè)方法與流程
- 一種基于BP神經(jīng)網(wǎng)絡(luò)的人工智能優(yōu)化方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的圖像處理方法、裝置及移動(dòng)終端與流程
- 結(jié)合LBP特征圖與卷積神經(jīng)網(wǎng)絡(luò)的人臉識(shí)別方法與流程
- 一種利用卷積神經(jīng)網(wǎng)絡(luò)的醫(yī)學(xué)圖像處理裝置與方法與流程
- 一種基于1D卷積神經(jīng)網(wǎng)絡(luò)的室性異位搏動(dòng)檢測(cè)方法與流程
- 用于實(shí)現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡(luò)加速器的裝置和方法與流程
- 基于多任務(wù)級(jí)聯(lián)卷積神經(jīng)網(wǎng)絡(luò)的人臉檢測(cè)方法及檢測(cè)裝置與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)和主成分分析法的肺結(jié)節(jié)特征提取方法與流程
- 基于一維卷積神經(jīng)網(wǎng)絡(luò)的雷達(dá)輻射源信號(hào)的識(shí)別方法與流程
- 基于深度卷積神經(jīng)網(wǎng)絡(luò)的乳腺癌風(fēng)險(xiǎn)評(píng)估分析系統(tǒng)的制造方法與工藝
- 一種基于醫(yī)學(xué)征象和卷積神經(jīng)網(wǎng)絡(luò)的肺結(jié)節(jié)CT圖像哈希檢索方法與流程
- 對(duì)花卉識(shí)別系統(tǒng)進(jìn)行改進(jìn)的輔助系統(tǒng)和進(jìn)行改進(jìn)的方法與流程
- 一種基于卷積神經(jīng)的農(nóng)作物害蟲圖像識(shí)別方法與流程
- 一種基于雙流卷積神經(jīng)網(wǎng)絡(luò)的立體匹配方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的圖像處理方法、裝置及移動(dòng)終端與流程
- 一種基于卷積深度網(wǎng)絡(luò)的圖像識(shí)別算法及系統(tǒng)的制造方法與工藝
- 一種利用卷積神經(jīng)網(wǎng)絡(luò)的醫(yī)學(xué)圖像處理裝置與方法與流程
- 基于BP神經(jīng)網(wǎng)絡(luò)算法的電力變壓器故障診斷裝置及方法與流程
- 一種基于1D卷積神經(jīng)網(wǎng)絡(luò)的室性異位搏動(dòng)檢測(cè)方法與流程
- 用于實(shí)現(xiàn)稀疏卷積神經(jīng)網(wǎng)絡(luò)加速器的裝置和方法與流程
- 基于多任務(wù)級(jí)聯(lián)卷積神經(jīng)網(wǎng)絡(luò)的人臉檢測(cè)方法及檢測(cè)裝置與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)和主成分分析法的肺結(jié)節(jié)特征提取方法與流程
- 基于一維卷積神經(jīng)網(wǎng)絡(luò)的雷達(dá)輻射源信號(hào)的識(shí)別方法與流程
- 基于深度卷積神經(jīng)網(wǎng)絡(luò)的乳腺癌風(fēng)險(xiǎn)評(píng)估分析系統(tǒng)的制造方法與工藝
- 一種基于醫(yī)學(xué)征象和卷積神經(jīng)網(wǎng)絡(luò)的肺結(jié)節(jié)CT圖像哈希檢索方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的APP相似圖標(biāo)檢索方法和系統(tǒng)與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的企業(yè)實(shí)體關(guān)系抽取的方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)自適應(yīng)背景建模物體檢測(cè)方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的輸電線路螺栓檢測(cè)方法與流程
- 一種基于FPGA的卷積神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)方法及裝置與流程
- 一種基于多個(gè)分類器的卷積神經(jīng)網(wǎng)絡(luò)快速分類方法與流程
- 基于全卷積神經(jīng)網(wǎng)絡(luò)的極化SAR地物分類方法與流程
- 基于一維卷積神經(jīng)網(wǎng)絡(luò)的雷達(dá)輻射源信號(hào)的識(shí)別方法與流程
- 基于深度卷積神經(jīng)網(wǎng)絡(luò)的乳腺癌風(fēng)險(xiǎn)評(píng)估分析系統(tǒng)的制造方法與工藝
- 一種基于醫(yī)學(xué)征象和卷積神經(jīng)網(wǎng)絡(luò)的肺結(jié)節(jié)CT圖像哈希檢索方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的APP相似圖標(biāo)檢索方法和系統(tǒng)與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的企業(yè)實(shí)體關(guān)系抽取的方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)自適應(yīng)背景建模物體檢測(cè)方法與流程
- 一種基于卷積神經(jīng)網(wǎng)絡(luò)的輸電線路螺栓檢測(cè)方法與流程
- 一種基于多個(gè)分類器的卷積神經(jīng)網(wǎng)絡(luò)快速分類方法與流程
- 一種基于全卷積神經(jīng)網(wǎng)絡(luò)的SAR圖像目標(biāo)檢測(cè)方法與流程