一種條目提取方法和裝置與流程
本發(fā)明涉及信息技術(shù)領(lǐng)域,特別涉及一種條目提取方法和裝置。
背景技術(shù):
在大規(guī)模表存儲結(jié)構(gòu)中,經(jīng)常需要獲取訪問頻率高的一些條目,例如,最經(jīng)常訪問的前8個條目,以對條目進行分析和進行控制操作。
相關(guān)技術(shù)中,為獲取訪問頻率最高的一些條目,通常為每一個條目增加一個計數(shù)器和一個初始計數(shù)記錄,在指定的時間后觀察統(tǒng)計每一個條目的初始計數(shù)與當(dāng)前計數(shù)之間的計數(shù)差值,進行排序后取得訪問頻率最高的前N(例如,10個)個條目。
但是,這種獲取訪問頻率高的條目的方法會耗費極大的存儲空間。
技術(shù)實現(xiàn)要素:
為了解決現(xiàn)有技術(shù)的問題,本發(fā)明實施例提供了一種條目提取方法和裝置,以在獲取訪問頻率高的條目的過程中節(jié)省存儲空間。
一方面,提供一種條目提取方法,其特征在于,所述方法包括:
從第一個采樣周期開始直到最后一個采樣周期的前一個采樣周期,執(zhí)行以下步驟:
a.獲取當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù);
b.根據(jù)所述當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù),確定所述當(dāng)前采樣周期內(nèi)條目訪問的平均值;
c.移除所述當(dāng)前采樣周期內(nèi)訪問次數(shù)小于所述平均值的條目,并將訪問次數(shù)不小于所述平均值的條目作為下一采樣周期內(nèi)的條目;
d.確定下一采樣周期是否為最后一個采樣周期;
若下一采樣周期不為最后一個采樣周期,重復(fù)步驟a~d,直到下一采樣周期為最后一個采樣周期;
當(dāng)下一采樣周期為最后一個采樣周期時,按照訪問次數(shù)從高到低的順序提取最后一個采樣周期中的指定個條目。
可選地,在一個實施例中,所述方法還包括:
確定提取的所述指定個條目中的各個條目的訪問次數(shù)是否超過閾值;
將提取的所述指定個條目中超過閾值的條目封鎖指定時間。
可選地,在另一個實施例中,在步驟c之后,所述方法還包括:
針對當(dāng)前采樣周期,確定訪問次數(shù)不小于所述平均值的條目中的各個條目的訪問次數(shù)是否超過閾值;
將訪問次數(shù)超過閾值的條目進行封鎖。
可選地,在另一個實施例中,所述方法還包括:
當(dāng)封鎖的條目數(shù)目達到指定的條目數(shù)目的情況下,對于后續(xù)各個采樣周期,將后續(xù)各個采樣周期內(nèi)需要封鎖的條目進行封鎖,同時將已封鎖的條目中的至少一個條目進行解封鎖;
其中,封鎖的條目數(shù)目等于解封鎖的條目數(shù)目;
其中,所述需要封鎖的條目為訪問次數(shù)超過所述閾值的條目。
可選地,在另一個實施例中,所述將后續(xù)各個采樣周期內(nèi)需要封鎖的條目進行封鎖,同時將已封鎖的條目中的至少一個條目進行解封鎖包括:
在進行條目封鎖時,按照訪問次數(shù)從高到低的順序選取條目進行封鎖;
在進行條目解封鎖時,按照訪問次數(shù)從低到高的順序或者按照封鎖時間從先到后的順序進行解封鎖。
可選地,在本發(fā)明實施例中,所述條目為IP地址或統(tǒng)一資源定位符(URL)地址,所述閾值為每秒數(shù)據(jù)包(PPS)的閾值或每秒請求(RPS)的閾值。
可選地,在另一個實施例中,所述方法還包括:以固定大小的存儲空間存儲提取的所述指定個條目。
另一方面,提供一種條目提取裝置,所述裝置包括獲取模塊和處理模塊;
從第一個采樣周期開始直到最后一個采樣周期的前一個采樣周期:
所述獲取模塊,用于獲取當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù);
所述處理模塊,用于根據(jù)所述當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù),確定所述當(dāng)前采樣周期內(nèi)條目訪問的平均值;
所述處理模塊,還用于移除所述當(dāng)前采樣周期內(nèi)訪問次數(shù)小于所述平均值的條目,并將訪問次數(shù)不小于所述平均值的條目作為下一采樣周期內(nèi)的條目;
所述處理模塊,還用于當(dāng)下一采樣周期為最后一個采樣周期時,按照訪問次數(shù)從高到低的順序提取最后一個采樣周期中的指定個條目。
可選地,在一個實施例中,所述處理模塊還用于:
確定提取的所述指定個條目中的各個條目的訪問次數(shù)是否超過閾值;
將提取的所述指定個條目中超過閾值的條目封鎖指定時間。
可選地,在另一個實施例中,所述處理模塊還用于:
針對當(dāng)前采樣周期,確定訪問次數(shù)不小于所述平均值的條目中的各個條目的訪問次數(shù)是否超過閾值;
將訪問次數(shù)超過閾值的條目進行封鎖。
可選地,在另一個實施例中,所述處理模塊具體用于:
當(dāng)封鎖的條目數(shù)目達到指定的條目數(shù)目的情況下,對于后續(xù)各個采樣周期,將后續(xù)各個采樣周期內(nèi)需要封鎖的條目進行封鎖,同時將已封鎖的條目中的至少一個條目進行解封鎖;
其中,封鎖的條目數(shù)目等于解封鎖的條目數(shù)目;
其中,所述需要封鎖的條目為訪問次數(shù)超過所述閾值的條目。
可選地,在另一個實施例中,所述處理模塊具體用于:
在進行條目封鎖時,按照訪問次數(shù)從高到低的順序選取條目進行封鎖;
在進行條目解封鎖時,按照訪問次數(shù)從低到高的順序或者按照封鎖時間從先到后的順序進行解封鎖。
其中,在本發(fā)明實施例中,所述條目為IP地址或統(tǒng)一資源定位符(URL)地址,所述閾值為每秒數(shù)據(jù)包(PPS)的閾值或每秒請求(RPS)的閾值。
可選地,在另一個實施例中,所述裝置還包括:
存儲模塊,用于以固定大小的存儲空間存儲提取的所述指定個條目。
另一方面,提供一種終端設(shè)備,所述終端設(shè)備包括存儲器和處理器,所述存儲器上存儲有計算機程序,當(dāng)所述處理器執(zhí)行所述計算機程序時執(zhí)行本發(fā)明實施例中的任一種條目提取方法。
另一方面,提供一種非臨時性存儲介質(zhì),所述非臨時性存儲介質(zhì)上存儲有計算機程序,當(dāng)所述計算機程序被處理器執(zhí)行時執(zhí)行本發(fā)明實施例中的任一種條目提取方法。
本發(fā)明實施例提供的技術(shù)方案帶來的有益效果是:
通過對每個采樣周期內(nèi)各個條目的訪問次數(shù)求平均、去除訪問次數(shù)在平均值以下的條目,并將當(dāng)前處理后得到的條目作為下一采樣周期的條目,如此循環(huán)處理,可以保證最后一個采樣周期內(nèi)得到的條目是訪問次數(shù)高的條目,且占用的存儲空間較小。
附圖說明
為了更清楚地說明本發(fā)明實施例中的技術(shù)方案,下面將對實施例描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發(fā)明的一些實施例,對于本領(lǐng)域普通技術(shù)人員來講,在不付出創(chuàng)造性勞動的前提下,還可以根據(jù)這些附圖獲得其他的附圖。
圖1是本發(fā)明實施例提供的條目提取方法的流程圖。
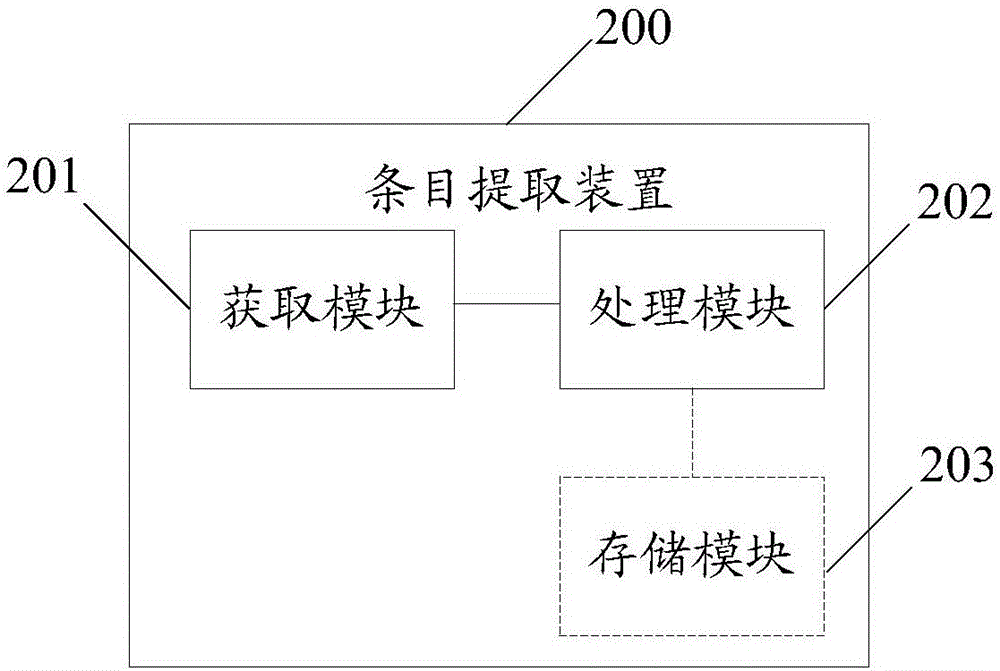
圖2是本發(fā)明實施例提供的條目提取裝置的結(jié)構(gòu)框圖。
具體實施方式
為使本發(fā)明的目的、技術(shù)方案和優(yōu)點更加清楚,下面將結(jié)合附圖對本發(fā)明實施方式作進一步地詳細描述。
圖1是本發(fā)明實施例提供的條目提取方法的流程圖。參照圖1,從第一個采樣周期開始直到最后一個采樣周期的前一個采樣周期,本發(fā)明實施例提供的條目提取方法可包括:
11、獲取當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù)。
其中,本發(fā)明實施例中的“條目”可以為各種不同形式的條目,例如,所述條目為IP地址或URL地址等等。本發(fā)明實施例對條目的具體形式不做具體限定。
本發(fā)明實施例中,條目可以為服務(wù)端中的條目。對條目的訪問一般是指客戶端對服務(wù)端條目的訪問。
12、根據(jù)所述當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù),確定所述當(dāng)前采樣周期內(nèi)條目訪問的平均值。
13、移除所述當(dāng)前采樣周期內(nèi)訪問次數(shù)小于所述平均值的條目,并將訪問次數(shù)不小于所述平均值的條目作為下一采樣周期內(nèi)的條目。
14、確定下一采樣周期是否為最后一個采樣周期。
若下一采樣周期不為最后一個采樣周期,重復(fù)步驟a~d,直到下一采樣周期為最后一個采樣周期。
在下一采樣周期為最后一個采樣周期時,執(zhí)行步驟15。
15、按照訪問次數(shù)從高到低的順序提取最后一個采樣周期中的指定個條目。
在本發(fā)明實施例中,以三個采樣周期t1-t3為例,舉例而言,條目提取的過程可以為:先獲取第一個采樣周期t1中各個條目的訪問次數(shù),并計算第一采樣周期內(nèi)條目訪問的第一平均值v1;然后去除第一采樣周期t1中訪問次數(shù)小于第一平均值v1的條目,將第一采樣周期中不小于第一平均值的條目作為第二采樣周期t2的輸入。由于第二采樣周期不是最后一個采樣周期,同樣地,對于第二采樣周期,也是先獲取第二個采樣周期t2中各個條目的訪問次數(shù),并計算第二采樣周期內(nèi)條目訪問的第二平均值v2;然后去除第二采樣周期t2中訪問次數(shù)小于第二平均值v2的條目,將第二采樣周期中不小于第二平均值的條目作為第三采樣周期t3的輸入。此時,由于第三采樣周期為最后一個采樣周期,因而,從作為第三采樣周期t3的輸入的第二采樣周期中不小于第二平均值的條目,和第三采樣周期內(nèi)的條目中,按照訪問次數(shù)從高到低的順序提取指定個條目。
在本發(fā)明實施例中,待提取到指定數(shù)目個條目后,可以以固定大小的存儲空間存儲提取的所述指定個條目。
本發(fā)明實施例提供的條目提取方法,通過對每個采樣周期內(nèi)各個條目的訪問次數(shù)求平均、去除訪問次數(shù)在平均值以下的條目,并將當(dāng)前處理后得到的條目作為下一采樣周期的條目,如此循環(huán)處理,可以保證最后一個采樣周期內(nèi)得到的條目是訪問次數(shù)高的條目,且占用的存儲空間較小。
本發(fā)明實施例提供的條目提取的方法可應(yīng)用于設(shè)定時間的條目提取。例如,提取10分鐘內(nèi)或20分鐘內(nèi)或其他時間段內(nèi)訪問頻率高的條目。在此情形下,可將設(shè)定的時間段劃分為多個采樣周期,然后對每個采樣周期應(yīng)用上面所描述的條目提取方法。待提取到指定數(shù)目個訪問頻率高的條目后,可進一步確定提取的所述指定個條目中的各個條目的訪問次數(shù)是否超過閾值;將提取的所述指定個條目中超過閾值的條目封鎖指定時間。
本發(fā)明實施例中的“閾值”為可以例如為每秒數(shù)據(jù)包(Packet Per Second,PPS)的閾值或每秒請求(Request Per Second,RPS)的閾值等等。本發(fā)明實施例對閾值的具體形式不做具體限定。
本發(fā)明實施例中,對條目的封鎖是指,阻止對條目的訪問。也就是說,一旦條目被封鎖后,任何訪問請求都不能繼續(xù)對條目進行訪問。
若對條目的訪問超過閾值,則可以判定這種訪問可能是異常的攻擊。通過對超過閾值的條目進行封鎖,可以有效減緩或停止這種異常攻擊。
在本發(fā)明實施例中,不但可以在最后一個采樣周期提取條目的操作完成后,對指定個條目中的至少一個條目進行封鎖,還可以在每一采樣周期執(zhí)行條目封鎖操作,即,在移除當(dāng)前采樣周期內(nèi)訪問次數(shù)小于平均值的條目的同時,對確定訪問次數(shù)不小于所述平均值的條目中的各個條目的訪問次數(shù)是否超過閾值,然后將訪問次數(shù)超過閾值的條目進行封鎖。具體地,同樣以三個采樣周期t1-t3為例,假定需要提取的條目數(shù)目為10個,舉例而言,若第一個采樣周期t1中有一個條目的訪問次數(shù)超過閾值,則可將這個條目進行封鎖;若第二個采樣周期t2中有三個條目的訪問次數(shù)超過閾值,則將這三個條目進行封鎖;若第三個采樣周期t3中有四個條目的訪問次數(shù)超過閾值,則將這四個條目進行封鎖。
當(dāng)然,在本發(fā)明實施例中,當(dāng)封鎖的條目數(shù)目達到指定的條目數(shù)目的情況下,對于后續(xù)各個采樣周期,將后續(xù)各個采樣周期內(nèi)需要封鎖的條目進行封鎖,同時將已封鎖的條目中的至少一個條目進行解封鎖;其中,所述需要封鎖的條目為訪問次數(shù)超過所述閾值的條目。
具體地,舉例而言,若指定提取的條目數(shù)目為10個,且前三個采樣周期t1-t3分別封鎖了1個、3個和4個條目的情況下,只剩下2個封鎖名額。若第四個采樣周期t4需要封鎖的條目數(shù)目為4個,此時由于采樣周期t4需要封鎖的條目數(shù)目(即,4個)超出了剩下的封鎖名額(即,2個),無法直接將采樣周期t4中的這4個需要封鎖的條目直接進行封鎖,而需要先將之前封鎖的8個條目中解封所2個條目(即,釋放2個名額),才能完成對采樣周期t4需要封鎖的條目進行封鎖。
一旦封鎖的條目數(shù)目已有10個,則在后續(xù)采樣周期中,需要封鎖的條目數(shù)目等于解封鎖的條目數(shù)目。具體地,后續(xù)在第五個采樣周期t5中需要封鎖的條目數(shù)目為5個,此時由于10個指定的封鎖條目數(shù)目已占滿,需要從這10個封鎖條目中解封鎖5個條目,才能完成對采樣周期t5中需要封鎖的5個條目進行封鎖。
其中,在封鎖和解封鎖的過程中,可以按照一定的優(yōu)先次序來進行。具體地,本發(fā)明實施例在進行條目封鎖時,可以按照訪問次數(shù)從高到低的順序選取條目進行封鎖;同時,在進行條目解封鎖時,按照訪問次數(shù)從低到高的順序或者按照封鎖時間從先到后的順序進行解封鎖。即,在指定數(shù)目的條目(在示例中為10個)已被封鎖的情況下,訪問次數(shù)少的條目或者封鎖時間最早的條目可以優(yōu)先進行解封鎖。其中,封鎖的條目數(shù)目可等于解封鎖的條目數(shù)目。
本發(fā)明實施例中的“條目”可以為各種不同形式的條目,例如,所述條目為IP地址或URL地址等等。本發(fā)明實施例中的“閾值”為可以例如為每秒數(shù)據(jù)包(Packet Per Second,PPS)的閾值或每秒請求(Request Per Second,RPS)的閾值等等。本發(fā)明實施例對條目和閾值的具體形式不做具體限定。
在本發(fā)明實施例中,將整個時間域劃分為一個個時間段(例如,T1、T2…等)來計算,然后在每個時間段內(nèi)再劃分為一個個的采樣周期(t1、t2…等)。在本文描述中n為提取的指定條目數(shù)目,可以使用一個大小為n的小數(shù)組(例如n=10)和一個n*n的矩陣。在T(例如,T1或T2等)時間段內(nèi)劃分多個采樣周期,并對大規(guī)模表的訪問進行多次采樣,將采樣所得的針對條目和訪問次數(shù)的訪問量記錄到數(shù)組中,條目到數(shù)組索引的運算由矩陣給出。
當(dāng)一個采樣周期結(jié)束后,計算采樣的各個條目訪問次數(shù)的平均值,然后去除該采樣周期內(nèi)訪問次數(shù)小于平均值的條目。在此基礎(chǔ)上再進行繼續(xù)采樣。待T時間段到的時候,已經(jīng)進行了很多次采樣,在最后留在n個數(shù)組內(nèi)超過平均數(shù)的條目就是訪問最頻繁的n個條目。再對這n個條目中訪問次數(shù)超過閾值的進行訪問封鎖,后續(xù)組的采樣將不會記錄已經(jīng)被封鎖的條目。封鎖的條目可以設(shè)定封鎖的時間,當(dāng)封鎖時間到的時候,放開已經(jīng)封鎖的條目。
當(dāng)然,在本發(fā)明實施例中,也可以逐次放開已經(jīng)封鎖的條目。逐次放開已經(jīng)封鎖條目的策略是:由于每個采樣周期并不能得到n個最高的條目,只是得到一部分,但是考慮經(jīng)過了若干個采樣周期之后得到了n個封鎖的條目。但是下一個采樣周期來臨時又得出了新的封鎖條目,此時,就會把之前已經(jīng)封禁的條目釋放封鎖(例如,按照訪問次數(shù)從低到高的順序釋放封鎖),釋放封鎖的條目數(shù)目可以等于新添加的封鎖條目數(shù)目。
本發(fā)明實施例中是將時間域用于存儲信息,而不是把所有的信息存儲在內(nèi)存空間。然后通過去除舊封鎖條目引入新封鎖條目的策略,來動態(tài)控制的封禁的前n個條目(例如,訪問量最高的前n個條目)。如此便實現(xiàn)了對整個時間域內(nèi)動態(tài)的前n個條目的封鎖。
在本發(fā)明實施例中,前n個條目是基于時間段而動態(tài)變化的,因而,對于前n個條目的選取只能是以一個時間段為標(biāo)桿。本公開中的時間段是坐標(biāo)軸上順序移動的大于采樣周期的動態(tài)間隔,并沒有上限。上限取決于前n個條目中超過閾值的條目的規(guī)模。如果在一個小時內(nèi)封禁數(shù)目都沒有超過n個,則可以認為一個小時內(nèi)已經(jīng)封禁的條目還應(yīng)該繼續(xù)封禁。
可見,如果條目中只會有個別的條目訪問量突然大規(guī)模增長,就應(yīng)該把n設(shè)置的盡量小。如果有很多個條目會出現(xiàn)訪問量異常,就應(yīng)該n設(shè)置的較大。所以n的選取是取決于系統(tǒng)的訪問特性。
本發(fā)明實施例提供的條目提取方法,不僅可以節(jié)省CPU資源和內(nèi)存資源,而且通過對條目進行封鎖,可以避免條目收到異常攻擊。
圖2是本發(fā)明實施例提供的一種條目提取裝置的結(jié)構(gòu)框圖。參照圖2,本發(fā)明實施例提供的條目提取裝置200可包括獲取模塊201和處理模塊202。其中:
從第一個采樣周期開始直到最后一個采樣周期的前一個采樣周期,所述獲取模塊201和所述處理模塊202分別執(zhí)行以下操作:
所述獲取模塊201,用于獲取當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù);
所述處理模塊202,用于根據(jù)所述當(dāng)前采樣周期內(nèi)對各個條目的訪問次數(shù),確定所述當(dāng)前采樣周期內(nèi)條目訪問的平均值;
所述處理模塊202,還用于移除所述當(dāng)前采樣周期內(nèi)訪問次數(shù)小于所述平均值的條目,并將訪問次數(shù)不小于所述平均值的條目作為下一采樣周期內(nèi)的條目;
所述處理模塊202,還用于當(dāng)下一采樣周期為最后一個采樣周期時,按照訪問次數(shù)從高到低的順序提取最后一個采樣周期中的指定個條目。
本發(fā)明實施例提供的條目提取裝置,通過對每個采樣周期內(nèi)各個條目的訪問次數(shù)求平均、去除訪問次數(shù)在平均值以下的條目,并將當(dāng)前處理后得到的條目作為下一采樣周期的條目,如此循環(huán)處理,可以保證最后一個采樣周期內(nèi)得到的條目是訪問次數(shù)高的條目,且占用的存儲空間較小。
可選地,在一個實施例中,所述處理模塊202還用于:
確定提取的所述指定個條目中的各個條目的訪問次數(shù)是否超過閾值;
將提取的所述指定個條目中超過閾值的條目封鎖指定時間。
可選地,在另一個實施例中,所述處理模塊202還用于:
針對當(dāng)前采樣周期,確定訪問次數(shù)不小于所述平均值的條目中的各個條目的訪問次數(shù)是否超過閾值;
將訪問次數(shù)超過閾值的條目進行封鎖。
可選地,在另一個實施例中,所述處理模塊202具體用于:
當(dāng)封鎖的條目數(shù)目達到指定的條目數(shù)目的情況下,對于后續(xù)各個采樣周期,將后續(xù)各個采樣周期內(nèi)需要封鎖的條目進行封鎖,同時將已封鎖的條目中的至少一個條目進行解封鎖;
其中,封鎖的條目數(shù)目等于解封鎖的條目數(shù)目;
其中,所述需要封鎖的條目為訪問次數(shù)超過所述閾值的條目。
可選地,在另一個實施例中,所述處理模塊202具體用于:
在進行條目封鎖時,按照訪問次數(shù)從高到低的順序選取條目進行封鎖;
在進行條目解封鎖時,按照訪問次數(shù)從低到高的順序或者按照封鎖時間從先到后的順序進行解封鎖。
在本發(fā)明實施例中,所述條目可以為IP地址或URL地址,所述閾值為PPS的閾值或RPS的閾值。
可選地,在另一個實施例中,所述裝置200還包括:存儲模塊203,用于以固定大小的存儲空間存儲提取的所述指定個條目。
需要指出的是,在相關(guān)技術(shù)中,耗費的CPU資源和內(nèi)存資源是隨著集合中條目的數(shù)目線性增長的,而且在條目巨大的時候耗費是驚人的。本發(fā)明實施例提供的條目提取的方法和裝置,對CPU和內(nèi)存的需要限制在一定的規(guī)模,不隨著條目數(shù)目的增長而變化。并且,所需的內(nèi)存和CPU資源都是非常小的。具體地,假設(shè)有300萬個條目,不采用本裝置需要的內(nèi)存是300w*8字節(jié),本裝置固定的使用n*24字節(jié)的內(nèi)存(上文中以n為10為例進行了說明)。不采用本公開時要遍歷計算300w次,采用了本公開后只需遍歷n*2次,外加額外的n*n的矩陣運算(以n為10為例)。可以看到無論內(nèi)存資源還是CPU資源都是上百萬數(shù)量級的提升。
需要說明的是:上述實施例提供的條目提取裝置,僅以上述各功能模塊的劃分進行舉例說明,實際應(yīng)用中,可以根據(jù)需要而將上述功能分配由不同的功能模塊完成,即將條目提取裝置的內(nèi)部結(jié)構(gòu)劃分成不同的功能模塊,以完成以上描述的全部或者部分功能。另外,上述實施例提供的條目提取裝置和條目提取方法實施例屬于同一構(gòu)思,其具體實現(xiàn)過程詳見方法實施例,這里不再贅述。
本領(lǐng)域普通技術(shù)人員可以理解實現(xiàn)上述實施例的全部或部分步驟可以通過硬件來完成,也可以通過程序來指令相關(guān)的硬件完成,所述的程序可以存儲于一種計算機可讀存儲介質(zhì)中,上述提到的存儲介質(zhì)可以是只讀存儲器,磁盤或光盤等。
以上所述僅為本發(fā)明的較佳實施例,并不用以限制本發(fā)明,凡在本發(fā)明的精神和原則之內(nèi),所作的任何修改、等同替換、改進等,均應(yīng)包含在本發(fā)明的保護范圍之內(nèi)。
- 還沒有人留言評論。精彩留言會獲得點贊!