一種視覺目標跟蹤方法及裝置與流程
本發明屬于計算機圖像技術領域,具體地涉及一種融合檢測器的魯棒視覺目標跟蹤的方法及裝置。
背景技術:
常見的視覺目標的跟蹤方法是通過人工選取第一幀圖像中的目標,然后通過在線學習目標的生成模型或在線學習判別目標和背景的判別模型來實現對目標的跟蹤,在一些復雜條件下(如環境光線變化、目標被遮擋及目標不在攝像機視野內等),會導致跟蹤漂移問題,進而使得跟蹤失敗,由于缺乏檢測器的有效輔助,跟蹤器丟失目標之后很難重新跟蹤到目標。
技術實現要素:
為了解決現有技術中在復雜條件下,跟蹤器會產生漂移問題使得跟蹤失敗以及跟蹤器丟失目標之后很難重新跟蹤到目標等問題,本發明目的在于提供一種融合檢測器的魯棒的視覺目標跟蹤方法及裝置。
根據本發明的一個方面,提供了一種視覺目標跟蹤方法,該方法包括步驟如下:
步驟S1:離線訓練預定目標的檢測器
步驟S2:采用所述檢測器檢測第i-1幀圖像中的所述預定目標,其中i為大于等于1的正整數;
步驟S3:在線學習跟蹤器判別模型;
步驟S4:采用所述跟蹤器判別模型跟蹤第i幀圖像中的所述預定目標;
步驟S5:通過所述檢測器判斷所述跟蹤器判別模型跟蹤所述預定目標是否成功;
步驟S6:若所述跟蹤器判別模型跟蹤所述預定目標成功,則存儲所述跟蹤器判別模型跟蹤得到的所述預定目標的特征向量及跟蹤得到的目標圖像,并在線學習跟蹤器判別模型,轉步驟S7;否則,i=i+1,轉步驟S2重新檢測所述預定目標并重新在線學習所述跟蹤器判別模型;
步驟S7:通過基于密度峰值的方法在線挖掘正支持向量,并對跟蹤器進行在線修正,i=i+1,然后跳轉到步驟S4。
其中,步驟S1包括以下步驟:
步驟S11:計算正負樣本圖像的梯度方向直方圖特征,生成正樣本圖像和負樣本圖像的特征向量;包括:
步驟S11A:將正樣本圖像通過雙線性差值方法歸一化為固定大小ws×hs,其中ws為歸一化正樣本圖像的寬,hs為歸一化正樣本圖像的高;
步驟S11B:將歸一化的正樣本圖像劃分為Nc1×Nc2個細胞單元Cij,1<i<Nc1,1<j<Nc2;每個細胞單元大小為k×k,其中k=ws/Nc1=hs/Nc2;
步驟S11C:在每個細胞單元Cij中對梯度方向進行獨立統計,以梯度方向為橫軸的直方圖,然后將這個梯度分布平均分成多個無符號方向角度,每個方向角度范圍對應方向角度范圍的梯度幅值累積值,將多個梯度幅值累積值組成多個維特征向量Vij,然后通過4個歸一化系數對Vii進行歸一化,進而得到細胞單元Cij對應的特征向量Fij;
步驟S11D:將歸一化正樣本圖像中所有細胞單元的梯度方向直方圖特征向量Fij串聯構成正樣本圖像的特征向量VP;
步驟S11E:采用與步驟S11A至步驟S11D相同的方式計算大小為ws×hs的負樣本圖像的特征向量VF;
步驟S12:采用隨機梯度下降法訓練檢測分類器;
其中,檢測分類器采用的是線性支持向量機分類器,其優化目標函數為:
其中為SVM的參數向量,yi∈{-1,+1}為樣本的類別標簽,其中x為正樣本圖像或負樣本圖像的特征向量;其中為檢測分類器的判別函數。
其中,步驟S2包括以下步驟:
步驟S21:根據所述當前幀圖像生成圖像金子塔;
步驟S22:將每幅所述圖像金字塔劃分為多個細胞單元,;然后通過梯度直方圖統計方法獲取每個細胞單元的特征向量,生成圖像特征金字塔;
步驟S23:在圖像特征金字塔中,利用所述檢測器采用滑動窗口的方式檢測所述預定目標。
其中,步驟S3包括下述步驟:
步驟S31:將第i幀圖像的所述預定目標進行狀態化表示,得到目標狀態si;其中,si=(Δxi,Δyi,sci,ri),其中Δxi、Δyi為所述檢測器檢測到的第i幀圖像中的所述預定目標相對前一幀跟蹤到的所述預定目標的中心點位置的二維平移量,sci表示所述檢測器檢測到的第i幀圖像中的所述預定目標相對前一幀跟蹤到的所述預定目標的面積大小的尺度比,ri表示目標狀態si對應的圖像區域的長寬比;
步驟S32:通過高斯分布對所述目標狀態進行狀態轉移,獲得采樣狀態集合m為采樣狀態集合中目標狀態的個數;
步驟S33:計算采樣狀態集合對應的圖像區域的特征向量;
步驟S34:將采樣狀態集合對應的圖像區域的特征向量作為樣本,通過優化基于狀態的結構SVM分類器實現跟蹤器判別模型的在線學習。
其中,所述步驟S33包括以下步驟:
步驟S33A:獲取所述采樣狀態集合中每個狀態對應的圖像區域;通過所述檢測器在第i幀圖像中檢測到的所述預定目標的位置(xCi,yCi,wi,hi),采用以下公式計算第j個狀態對應的圖像區域的位置
其中,xCi、yCi為所述狀態si對應的圖像區域的中心點位置,wi、hi分別為所述狀態si對應的圖像區域的寬和高;分別為第j個狀態對應的圖像區域的中心點位置,分別為第j個狀態對應的圖像區域的寬和高;表示所述狀態si對應的圖像區域的長寬比;
步驟S33B:計算所述采樣狀態集合中每個狀態對應的圖像區域的歸一化特征向量。
其中,步驟34中基于狀態的結構SVM分類器的優化問題如下表示:
其中C為懲罰系數,其中為對應狀態si的特征向量,為第i幀圖像中所有的狀態,包括狀態轉移獲得的采樣狀態和目標的狀態;其中為特征向量和之間的損失函數,其中為高斯核函數,Φ為將特征向量從低維空間到高維空間的映射,其中1≤i≤n為模型參數,n為在跟蹤過程中,每幀圖像中采集的狀態的個數;其中,跟蹤器判別模型的判別函數為其中
其中,基于狀態的結構SVM分類器的在線優化過程包括如下步驟:
步驟S34A:選取第i幀圖像中狀態目標特征向量對應的參數作為選取其中,為步驟S34中優化目標函數對的梯度;si+表示與參數相對應的目標狀態,si-表示與參數相對應的目標狀態;
步驟S34B:更新參數和首先,計算然后,計算其中
計算然后,更新若則將添加到支持向量集合Vsup中,即將添加到支持梯度集合G中,即若則將添加到支持向量集合Vsup中,即將添加到支持梯度集合G中,即最后,更新支持梯度集合G中的梯度
步驟S34C:進行支持向量維護;若支持向量集合Vsup中的支持向量數量大于200,則剔除支持向量集合Vsup中的支持向量xclear直到支持向量集合Vsup中的支持向量數量小于200,其中
步驟S34D:從現有的支持模式集合中,選取其中至少包含一個支持向量的集合稱為支持模式集合,采用步驟S34B更新參數和并采用步驟S34C進行支持向量維護;
步驟S34E:從現有的支持模式集合中,選取采用步驟S34B更新參數和并采用步驟S34C進行支持向量維護;
步驟S34F:轉步驟S34E,直至滿足第一迭代結束條件為止;
步驟S34G:轉步驟S34D,直至滿足第二迭代結束條件為止。
其中,步驟S4包括以下步驟:
步驟S41:將所述預定目標在第i-1幀圖像中的目標狀態和采樣狀態做為第i幀圖像的采樣狀態,并計算每個采樣狀態在第i幀圖像中的圖像區域,進而計算每個采樣狀態對應的圖像區域的特征向量;
步驟S42:通過所述跟蹤器判別模型的判別函數,計算每個采樣狀態對應的圖像區域的特征向量的判別值,并將具有最大判別值的采樣狀態作為第i+1幀圖像的目標狀態。
其中,所述步驟S6中存儲的所述預定目標的特征向量最多不超過200個,若超過200個,則僅保存最新得到的200個所述預定目標的特征向量。
其中,步驟S7包括下述步驟:
步驟S71:對步驟S6中存儲的所述預定目標的特征向量集進行基于密度峰值的聚類;首先,對于集合C中的每一個特征向量計算其對應的局部密度ρi及比其局部密度更高的點的距離δi;
然后,計算集合C中每個特征向量對應的γi=ρiδi,從而獲得集合
最后,將集合中的數據進行降序排列,以獲得集合選擇集合C中對應集合中前nr個數據構成數據集
步驟S72:將基于密度峰值聚類方法挖掘出的數據集D中的特征向量替換跟蹤器判別模型中具有較低置信度的nr個正支持向量。
根據本發明第二方面,提供了一種視覺目標跟蹤裝置,包括:
檢測器訓練模塊,用于離線訓練預定目標的檢測器
檢測模塊,用于采用所述檢測器檢測第i-1幀圖像中的所述預定目標,其中i為大于等于1的正整數;
跟蹤器學習模塊,用于在線學習跟蹤器判別模型;
跟蹤模塊,用于采用所述跟蹤器判別模型跟蹤第i幀圖像中的所述預定目標;
判別模塊,用于通過所述檢測器判斷所述跟蹤器判別模型跟蹤所述預定目標是否成功;若所述跟蹤器判別模型跟蹤所述預定目標成功,則存儲所述跟蹤器判別模型跟蹤得到的所述預定目標的特征向量及對應的子圖像,并利用跟蹤器學習模塊在線學習跟蹤器判別模型,采用基于密度峰值的方法在線挖掘正支持向量,并對跟蹤器進行在線修正,i=i+1,轉跟蹤模塊繼續跟蹤下一幀圖像;否則,i=i+1,轉檢測模塊重新檢測所述預定目標并重新在線學習所述跟蹤器判別模型。
通過本發明上述技術方案,通過檢測器和跟蹤器的有效融合,實現了對特定目標的魯棒視覺檢測與跟蹤,能夠為視覺導航、視覺監控等提供準確的視覺目標信息。
附圖說明
圖1為本發明中一種視覺目標跟蹤方法的流程圖;
圖2為本發明中離線訓練特定目標的檢測器的流程圖;
圖3為本發明中采用檢測器檢測圖像中的目標的流程圖;
圖4為本發明中在線學習跟蹤器判別模型的流程圖;
圖5為本發明中采用跟蹤器跟蹤下一幀圖像中的目標的流程圖;
圖6為本發明中通過基于密度峰值的方法在線挖掘正支持向量,并對跟蹤器進行在線修正的流程圖;
圖7為本發明中計算待檢測圖像的圖像特征金字塔的示意圖。
具體實施方式
為使本發明的目的、技術方案和優點更加清楚明白,以下結合具體實施例,并參照附圖,對本發明進一步詳細說明。
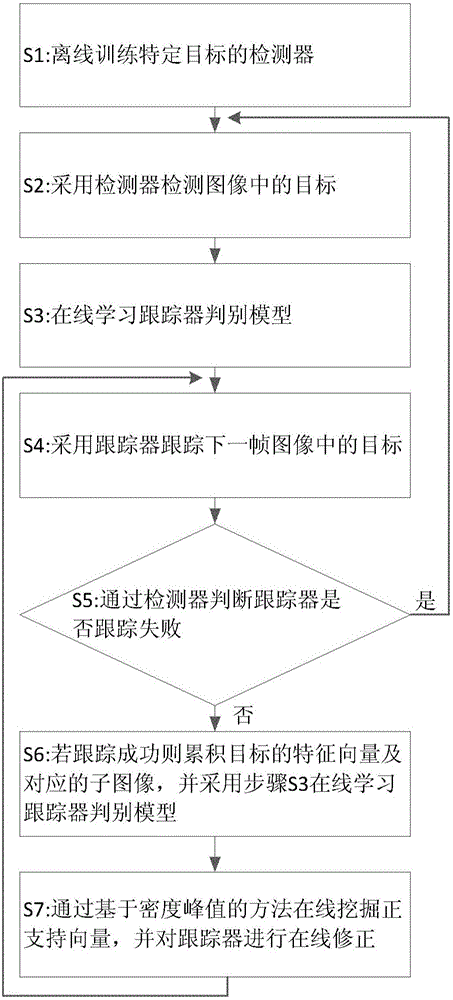
如圖1示出本發明一種融合檢測器的魯棒的視覺目標跟蹤方法的流程圖,其步驟包括如下:
步驟S1:離線訓練特定目標的檢測器;
步驟S2:采用檢測器檢測圖像中的目標;
步驟S3:在線學習跟蹤器判別模型;
步驟S4:采用跟蹤器跟蹤下一幀圖像中的目標;
步驟S5:通過檢測器判斷跟蹤器是否跟蹤失敗;
步驟S6:若跟蹤成功則累積目標的特征向量及對應的子圖像,并再一次采用步驟S3中的方法進行在線學習跟蹤器判別模型,否則跳轉到步驟S2重新檢測圖像中的目標;
步驟S7:通過基于密度峰值的方法在線挖掘正支持向量,并對跟蹤器進行在線修正,然后跳轉到步驟S4。
其中,如圖2所示,步驟S1離線訓練特定目標的檢測器包括以下幾個步驟:
步驟S11:計算正負樣本圖像的梯度方向直方圖特征,生成正樣本圖像和負樣本圖像的特征向量。具體過程為:
步驟S11A:將正樣本圖像通過雙線性差值方法歸一化為固定大小ws×hs,其中ws為歸一化正樣本圖像的寬,hs為歸一化正樣本圖像的高。
步驟S11B:將歸一化的正樣本圖像劃分為Nc1×Nc2個細胞單元Cij,1<i<Nc1,1<j<Nc2。每個細胞單元大小為k×k,其中k=ws/Nc1=hs/Nc2。
步驟S11C:在每個細胞單元Cij中對梯度方向進行獨立統計,以梯度方向為橫軸的直方圖,梯度方向取0度到180度(忽略方向符號),然后將這個梯度分布平均分成n個無符號方向角度,每個方向角度范圍對應方向角度范圍的梯度幅值累積值,將n個梯度幅值的累積值,組成n維特征向量Vij,然后通過m個歸一化系數對Vij進行歸一化,進而得到細胞單元Cij對應的特征向量Fij。其中Fij由下式求取,其中n的取值范圍為5至15,優選為9,m可以為4:
其中α,β∈{-1,1}為4個歸一化系數,通過下式求取:
其中Vi+α,j,Vi,j+β,Vi+α,j+β分別為細胞單元Ci+α,j,Ci,j+β,Ci+α,j+β通過步驟S11C計算出的9維特征向量。
步驟S11D:將歸一化正樣本圖像中所有細胞單元的梯度方向直方圖特征向量Fjj串聯構成正樣本特征向量VP。
步驟S11E:采用與步驟S11A至步驟S11D相同的方式計算大小為ws×hs的負樣本圖像的特征向量VF。
步驟S12:采用隨機梯度下降法訓練檢測分類器;
其中,檢測分類器采用的是線性支持向量機分類器(SVM),其優化目標函數為:
其中為SVM的參數向量,w為權重向量,b為偏移量,yi∈{-1,+1}為樣本的類別標簽,其中x為正樣本或負樣本圖像對應的特征向量,C為懲罰系數,N為樣本數量。其中為檢測分類器的判別函數,其表達式為
其中,如圖3所示,步驟S2采用檢測器檢測圖像中的目標包括以下步驟:
步驟S21:通過平滑及下采樣等步驟生成圖像金子塔。過程如圖7左圖所示,參數λ代表圖像金子塔中每個八度中圖像的個數,亦代表圖像的長(寬)降低到原來的一半需要下采樣的次數,圖7所示的圖像金子塔的參數λ=2,其可以根據實際設置成不同的值,例如可以設置成λ=5。
步驟S22:將金字塔中的每幅圖像劃分為小的細胞單元,每個細胞單元大小為k×k大小的小圖像,然后按照步驟S11C計算每個細胞單元的特征向量Fij,生成圖像特征金字塔,如圖7右圖所示。
步驟S23:在圖像特征金字塔中,視覺檢測分類器采用滑動窗口的方式對錐套目標進行檢測。具體過程為:
步驟S23A:采用大小為Nc1×Nc2個細胞單元的窗口在圖像特征金字塔中滑動,通過檢測器的判別函數計算圖像特征金字塔中所有滑動位置處的分值,其中為SVM的參數向量,x為每個滑動窗口處的特征向量。
步驟S23B:通過比較得到所有滑動位置處分類分值的最大值SM,如果SM>T1,則具有最大分類分值的滑動位置為待檢測圖像中目標的位置,否則待檢測圖像中不存在目標,其中T1為分類閾值。
其中,如圖4所示,步驟S3在線學習跟蹤器判別模型的具體過程如下:
步驟S31:將第i幀圖像的目標進行狀態化表示。其中檢測器檢測到目標在當前幀圖像中的位置為(xCi,yCi,wi,hi),xCi,yCi為目標圖像區域的中心點位置,wi,hi分別為目標圖像區域的寬和高。其中狀態定義為si=(Δxi,Δyi,sci,ri),其中Δxi,Δyi為檢測器檢測到目標相對第i-1幀圖像中跟蹤到的目標中心點位置的二維平移量,sci表示相對目標大小的尺度比,即狀態si對應圖像區域的面積與第i-1幀圖像中跟蹤到的目標的面積比,ri表示長寬比,即狀態si對應圖像區域(即所述檢測器檢測到的第i幀圖像中的所述預定目標)的高度和寬度的比值。目標在當前圖像中的狀態
步驟S32:通過高斯分布對目標狀態進行狀態轉移,獲得采樣狀態集合其中獲得采樣狀態集合中的狀態si的高斯分布為:
其中,為高斯分布的概率密度函數,符號記為N;∑ST為對角協方差矩陣,其對角元素對應著Δxi,Δyi,sci,ri的方差σΔx,σΔy,σsc,σr。
步驟S33:計算采樣狀態集合對應圖像區域的特征向量。具體步驟如下:
步驟S33A:獲取每個狀態對應的圖像區域。通過目標在圖像中的位置(xCi,yCi,wi,hi)及采樣狀態集合中狀態采用以下公式計算狀態對應的圖像區域的位置
步驟S33B:計算每個狀態對應的圖像區域的特征向量。將每個狀態對應的圖像區域歸一化為X×X大小的子圖像,并將子圖像的像素值,按列排列成X×X維特征向量,并將特征向量除以256,使得特征向量每個維度的取值歸一化在[0,1]范圍。
步驟S34:通過優化基于狀態的結構SVM分類器實現跟蹤器判別模型的在線學習。
其中,基于狀態的結構SVM分類器的優化問題為:
其中C為懲罰系數,其中為對應狀態si的特征向量,為第i幀圖像中所有的狀態,包括狀態轉移獲得的采樣狀態和目標的狀態。其中為特征向量和之間的損失函數,其中為高斯核函數,Φ為將特征向量從低維空間到高維空間的映射,其中1≤i≤n為模型參數,n為在跟蹤過程中,每幀圖像中采集的狀態的個數。其中,跟蹤器判別模型的判別函數為其中
其中,基于狀態的結構SVM分類器的在線優化過程為:
步驟S34A:選取當前幀圖像中目標特征向量對應的參數作為選琳其中,為步驟S34中優化目標函數對的梯度。si+表示與參數相對應的狀態,si-表示與參數相對應的狀態。
步驟S34B:更新參數和首先,計算然后,計算其中
計算然后,更新者則將添加到支持向量集合Vsup中,即將添加到支持梯度集合G中,即若則將添加到支持向量集合Vsup中,即將添加到支持梯度集合G中,即最后,更新支持梯度集合G中的梯度
步驟S34C:進行支持向量維護。若支持向量集合Vsup中的支持向量數量大于200,剔除支持向量集合Vsup中的支持向量xclear直到支持向量集合Vsup中的支持向量數量小于200,其中
其中,代表第i幀圖像中的采樣狀態集合中的采樣狀態。
步驟S34D:從現有的支持模式集合中,選取其中至少包含一個支持向量的集合稱為支持模式集合,采用步驟S34B更新參數和并采用步驟S34C進行支持向量維護。
步驟S34E:從現有的支持模式集合中,選取采用步驟S34B更新參數和并采用步驟S34C進行支持向量維護。
步驟S34F:循環運行步驟S34E 10次。
步驟S34G:循環運行步驟S34D至S34F 10次。
其中,如圖5所示,步驟S4采用跟蹤器跟蹤下一幀圖像中的目標的步驟為:
步驟S41:將目標在上一幀圖像中的目標狀態和采樣狀態做為下一幀圖像的采樣狀態,并通過步驟S33A計算每個狀態在下一幀圖像中的圖像區域,通過步驟S33B計算每個狀態對應的圖像區域的特征向量。
步驟S42:通過步驟S34中跟蹤器判別模型的判別函數計算每個狀態對應的圖像區域的特征向量的判別值。并將具有最大判別值的狀態作為下一幀圖像中目標的狀態。
其中步驟S5通過檢測器判斷跟蹤器是否跟蹤失敗的具體實施過程為:對具有最大判別值的狀態對應的圖像區域計算步驟S11中的梯度方向直方圖特征,并通過步驟S12中檢測分類器的判別函數計算判別值,若判別值大于閾值T2,則跟蹤目標成功,否則跟蹤目標失敗。
其中步驟S6中所存儲的目標的特征向量最多不超過200個,若超過200個則僅保存最新累積的200個目標特征向量。
其中,如圖6所示,步驟S7中通過基于密度峰值的方法在線挖掘正支持向量,并對跟蹤器進行在線修正的具體實施步驟如下:
步驟S71:對步驟S6中累積的目標的特征向量集進行基于密度峰值的聚類。首先,對于集合C中的每一個特征向量計算其對應的局部密度ρi,計算與比其局部密度高的點的距離,取所有距離的最小值為δi,其中
其中dij為特征向量和特征向量之間的距離,當x<0時,χ(x)=1,否則χ(x)=0,dc為距離閾值。然后,計算集合C中每個特征向量對應的密度評價系數γi=ρiδi,從而獲得集合最后,將集合中的數據進行降序排列,以獲得集合選擇集合C中對應集合中前nr個數據構成數據集
步驟S72:將基于密度峰值聚類方法挖掘出的數據集D中的特征向量替換跟蹤器判別模型中具有較低置信度的nr個正支持向量。首先,對步驟S34B中支持向量集合Vsup中對應的支持向量的狀態對應的圖像區域歸一化為大小為ws×hs的圖像。然后,對每一個歸一化的圖像,計算步驟S11中的梯度直方圖特征向量Tpxi,將所有特征向量構成集合Tp={Tpx1,...,Tpxi,...TpxN}。通過檢測器的判別函數計算集合Tp中所有特征向量的判別值。最后,將數據集D中的前nr個特征向量替換支持向量集合Vsup中具有較小檢測判別值的nr個正支持向量。
以上所述,僅為本發明中的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉該技術的人在本發明所揭露的技術范圍內,可理解想到的變換或替換,都應涵蓋在本發明的權利要求書的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!