一種左右遞歸新詞發現方法與流程
本發明屬于搜索引擎技術領域,來源于詞法分析和快速檢索的構建和使用實踐。本發明既可以用于通用商業數據的高效分類和檢索又可以作為公安、軍事等特殊領域的專業分檢。
背景技術:
隨著各個行業信息化的快速發展,當今各個垂直領域的數據越來越多,而其中有很多數據是無用的,不需要特殊處理。
如何快速、高效從垂直領域內的海量數據中檢索、智能挖掘出有用的信息成為現在智能搜索引擎發展的一大難題。隨著搜索引擎技術的發展,出現了各種各樣的搜索引擎技術,但絕大部分搜索引擎技術針對特殊領域中的特殊術語和特殊表達方式不能進行有效的檢索和智能推薦,所以現有的搜索引擎技術不能滿足當前行業的需求,這就促進了分布式智能搜索引擎的發展。
針對垂直領域往往會出現很多特定的專業詞匯以及新詞匯,對于這些詞匯,現有詞典中是沒有的,如果語料中包含了這些詞匯,那么詞法分析邏輯處理模塊處理時將會造成一定的誤差。所以需要針對這些專業詞匯、新詞匯進行自動化的搜集功能,并把這些詞匯加入到詞庫中構建出該垂直領域的特殊詞庫,這樣就能提高搜索引擎中詞法分析邏輯處理模塊的處理效率、精度,從而提高搜索引擎的搜索效率、精確度。
一般而言,當數據進入分布式搜索引擎時,同時也進入新詞詞庫構建流程,對輸入語料數據進行新詞發現,如果發現的新詞沒有在現有詞庫中出現過,就把這個新詞加入到新詞詞庫。
現有的新詞發現方法一般是采用基于規則的新詞發現或者基于統計的新詞發現。最早采用的新詞發現方法都是采用的基于規則的新詞發現方法,它通過研究新詞的內部構造規則和外部構造規則來形成對應的規則庫,以此規則庫為準則來發現新詞。而基于統計的新詞發現方法是通過找到長度不大于n的所有詞匯,對這些詞匯進行詞頻、互信息的計算,如果計算指標滿足預先設定的指標閾值就作為新詞。
在新詞發現方法中,前述兩種方法都各有利弊。基于規則的方法,新詞發現的準確度、效率都相對較高,但在規則庫的創建上需要耗費大量的人力去進行規則提取,隨著語言的發展,規則庫需要不斷的更新,因此該方法不是自適應的,擴展性不好;基于統計的方法,新詞發現的過程是自動化的,但這種方式會發現很多詞頻較高的垃圾串,而且不能發現長度非常長的新詞,例如,少數民族人名、音譯名。
通過對各種新詞發現技術的調研,發現當前大部分的新詞發現方法都是基于窗口的模式去發現新詞,這種模式使得長度較長的新詞不能被發現。我們發明一種基于左右遞歸的新詞發現方法,在進行新詞發現時,大大提高了新詞發現的準確度。利用這種新詞發現方法可以很方便地建立高準確度的自適應垂直領域詞典,并且隨著數據量的增加,詞典越來越健全。針對特殊的領域,可以大幅度提高索引數據時分詞的準確度。
通過一種左右遞歸新詞發現方法能夠有效解決現有方法面臨的上述問題。
技術實現要素:
本發明公開了一種左右遞歸新詞發現方法。一種左右遞歸新詞發現方法由語料預處理、位置集合計算、集合遍歷、收納性判斷、詞頻計算、左遞歸、右遞歸、合并八個步驟組成。
下面具體設計這種左右遞歸新詞發現方法:
一種左右遞歸新詞發現方法按照三個指標評定一個新詞,即詞頻、互信息、信息熵。
(1)詞頻
統計詞匯在語料中出現的頻率,出現的頻率越高就越可能是新詞,當詞頻達到某個閾值就認為可能成為一個新詞,計算公式如下:
其中,N(X)表示字符串X出現的次數;N表示語料的總字數。
(2)互信息
互信息是最早出現在信息論中的信息度量指標,標識了一個事件集合與另一個事件集合關系的信息量。兩個事件集合之間的互信息越大就表明相關性越大,反之越小。互信息作為計算語言學模型分析的常用方法,由于它對特征詞和分類之間關系的性質沒有任何限制,所以互信息常常用于文本分類的特征和類別的配準。
在新詞發現方法中,利用互信息能夠發現字符串與字符串之間的一個關聯程度,字符串X,Y互信息的計算公式如下:
其中,X、Y表示字符串或者單字;p(XY)表示字符串X和字符串Y在輸入語料中同時出現的概率;p(X)和p(Y)分別表示字符串X在輸入語料中出現的概率和字符串Y在輸入語料中出現的概率。
舉例說明:如果在3000萬字的語料中,“飛機場”出現了215次,出現的概率約為7.1667×10-6;“飛機”出現了2899次,出現的概率約為9.6633×10-5;“場”出現了5384次,出現的概率約為1.7947×10-4。理論上如果“飛機”和“場”之間毫無關系,“飛機場”出現的概率應該為9.6633×10-5×1.7947×10-4,約為1.7345×10-8。但是,實際值卻是理論值的約5571倍,這表明“飛機”和“場”搭配到一起不是偶然拼在一起的,而是兩個字符串有某種必然的聯系。不過“飛機場”也可能是由“飛”和“機場”組合的,所以在新詞發現技術中,我們常常使用平均互信息來衡量字符串的互信息,平均互信息如下:
其中X1,X2,…,Xn表示字符串或者單字;p(X1,X2,…,Xn)表示字符串X1,X2,…,Xn在輸入語料中同時出現的概率。
(3)信息熵
信息熵表示信息量的多少,其中,信息量隨著信息熵的增大而減小。信息熵的計算公式如下:
其中,p(Xi)表示事件Xi發生的概率。
在新詞發現技術中,我們用信息熵來衡量一個字符串的左鄰集合和右鄰集合的隨機性,隨機性越高成為新詞的可能性就越大。例如“我愛吃重慶火鍋,我愛看重慶美女。”這段語料中,“重慶”出現了2次,它的左鄰集合為{吃,看},它的右鄰集合為{火,美},根據信息熵計算方法,我們可以得到:
在新詞發現方法中,計算某個字符串的信息熵,我們一般采用左右平均信息熵來衡量該字符串的自由度,計算方法如下:
其中,HL(X)表示字符串X的左信息熵;HR(X)表示字符串X的右信息熵。
現有新詞發現技術存在無法發現長度較長的新詞、發現一些垃圾串等問題,而本方法可以有效地解決這些問題。
(1)輸入預料預處理
由于輸入的語料往往存在格式不規范,或者中英文語料中包含一些沒有用的垃圾串,這對新詞發現造成了很大的干擾使得對新詞指標的計算存在誤差。本方法針對輸入的語料進行文本預處理,主要步驟如下:
第一步:通過正則過濾,刪除了語料中包含的Html標簽、Xml標簽等與文本無關的特殊標簽。
第二步:對語料中的符號進行全角轉半角操作,中文繁體轉簡體操作以及規范首行等操作。
第三步:刪除語料中多余的空格、換行符、制表符等空白符號。
第四步:刪除語料中包含的特殊符號,包括ASCII編碼、特殊編碼、亂碼等與文本無關的特殊符號。
第五步:刪除文本中的非文本數據,包括圖片、聲音、視頻等數據。
第六步:通過斷句標志,即“。”、“!”、“?”、“…”、“;”、空格、換行符等將語料切分成一個一個的句子。如果句中包含對稱的符號,例如引號、書名號等則要求左右匹配。最后還需要把分好的句子進行編號。
第七步:為了避免語料中大量完全相同的句子對新詞指標的計算造成誤差,針對步驟四中分好的句子進行Hash求值,對Hash碼完全相同的句子進行去重,避免輸入語料中出現大量完全相同的句子或者段落。
一種左右遞歸新詞發現方法采用的預處理技術可以使語料規范、準確、有意義的,很大情況下避免了因為語料本身的缺陷、誤差造成的錯誤指標計算,提高了新詞發現的準確性。
(2)新詞分類設計
一種左右遞歸新詞發現方法根據實體名詞、派生詞、縮略詞、復合詞和數字組合詞對新詞進行分類設計。在新詞發現中,針對中文語料的處理要比英文語料的處理困難,這是由于中文的語法規則特別的復雜。英文的詞語之間是直接可以用空格分開的,這使得新詞的發現就很簡單,只需要利用空格進行分詞,在對分好的詞與詞庫進行匹配就可以了;在詞匯的形態變化上,英文詞匯雖然變化較為復雜但全部都是規則化的變換,而中文的變換是沒有規律可循的;中文是有嚴格詞序的,不同的詞序代表了完全不同的意思,比如“不完全認同”和“完全不認同”就代表了截然不同的意思;中文中對于虛詞的使用是非常廣泛的,通過研究表明“的”和“了”字的使用頻率高達3%-5%,所以在進行新詞發現時,往往會把“屬絲”這個新詞發現為“屌絲的”;中文中的漢字是一個比較穩定的集合,盡管漢字組成的詞匯是千變萬化的,但是很少會有新的漢字出現,所以這是對中文的新詞發現比較有利的一點。綜上所述,中文的語言特點相對于其他語言的特點是完全不同的,我們必須找到專門的信息處理方法和規則才能有效的提高中文新詞發現的準確度。
一種左右遞歸新詞發現方法主要針對現有詞庫中不包含的詞匯進行發現,經過研究表明大部分新詞主要分為以下五大類:
第一類是實體名詞:主要包括了人名、地名、組織名,其中人名根據特點的不同又分為了漢族人名、少數名族人名、英譯人名等。實體名詞是本方法發現的主要詞匯之一。
第二類是派生詞:主要是指根據已有的詞匯添加特定的后綴形成的新詞,比如“老年化”,在進行新詞發現時,本方法可以發現一些類似的派生詞。
第三類是縮略詞:這種詞匯主要針對一些非常長的詞匯,這些詞匯使用其中的某幾個字代表該詞,例如“中國國家足球隊”的縮略詞為“國足”、“美國男子職業籃球聯賽”的縮略詞為“NBA”。
第四類是復合詞:這種詞匯主要由動詞、名詞等組合而成,通過兩個或兩個以上詞的合并而形成,例如“軟件工程”、“中國重慶沙坪壩區重慶大學A區”,前者就是兩個名詞組合成的詞匯,后者則是由“中國”、“沙坪壩區”、“重慶大學”、“A區”多個地名詞組合成的詞匯。
第五類是數字組合詞:這種詞匯是通過對數字、日期、電話號碼、編碼等組合而形成的詞匯。
針對以上提到的規則,我們設計了相關的規則庫。規則庫中的規則既可以自動添加也可以手工追加。隨著規則庫中規則的增加,新詞發現就越來越準確。
由于規則和規則之間,有時候存在排斥關系,本方法采取了優先級排序策略,當規則與規則沖突時就利用優先級進行規則的選擇。
(3)新詞評定指標設計
新詞評定指標為詞頻、互信息以及信息熵。詞頻表明了字符串出現的次數,只有詞頻到達閾值后,我們才會考慮這個字符串可能是一個新詞。如果僅僅是看字符串出現的次數還是不夠的,例如“的電影”出現了492次,“電影院”出現了323次,“的電影”出現的頻次是大于“電影院”出現的頻次的,但我們更傾向于“電影院”作為一個詞,因為我們感覺“電影”和“院”的凝固程度比“的”和“電影”的凝固程度更大,所以當詞頻達到閾值后,我們還需要用互信息來表明詞的內部凝固程度。如果我們只是通過詞頻、互信息兩個指標來判斷是否為新詞,這還是不夠的,我們還需要用信息熵來看它外部的表現。例如“世紀”和“事跡”兩個字符串,我們只可以說“上世紀”、“下世紀”、“本世紀”等有限幾個,可見“世紀”這個字符串左鄰集合很小,所以我們更傾向“上世紀”、“下世紀”、“本世紀”作為一個新詞;而對“事跡”這個字符串,我們可以說“輝煌事跡”、“優秀事跡”、“人物事跡”、“候選人事跡”等等很多,它的左鄰集合非常大,所以我們可以直接把“事跡”作為一個新詞。信息熵衡量了一個字符串的自由運用程度,如果一個字符串的左鄰集合和右鄰集合越大,那么這個字符串就更有可能作為一個新詞。計算出字符串的左信息熵和右信息熵之后,再根據左信息熵或右信息熵進行左遞歸或右遞歸的計算。
一種左右遞歸新詞發現方法可以發現任何長度的新詞,其步驟如下:
步驟一:語料預處理。具體參見前述步驟。
步驟二:位置集合計算,即計算:
其中w1,w2,…,wm表示輸入語料中出現過且互不相同的字;(wi,POSi)表示一個集合而是該集合的一個元素,表示第i個字wi在輸入語料中第j次出現的位置;表示第i個字wi在位置出現過。
例如,針對語料“我是中國人,我愛中國”那么集合W為{(‘我’,{0,6}),(‘是’,{1}),(‘中’,{2,8}),(‘國’,{3,9}),(‘人’,{4}),(‘愛’,{7})}。位置集合W記錄了每個字出現的位置;
步驟三:集合遍歷,即遍歷集合W,依次取出每個字wi,即word=wi,i=i+1。
步驟四:收納性判斷,即判斷word是否滿足規則庫收納規則的要求,如果不滿足,跳回步驟三,如果滿足進行步驟五。收納性是指新詞是否符合新詞分類標準,新詞分類標準包括實體名詞、派生詞、縮略詞、復合詞、數字組合詞。針對這五類詞,我們設計了相應的規則庫,規則庫中的規則既可以自動添加也可以手工追加。因此在進行收納時,要按照這五種類型進行。
步驟五:詞頻計算,即計算word出現的頻次,如果小于閾值,跳回步驟三,如果大于閾值則進行步驟六。
步驟六:左遞歸,即針對word執行左遞歸,記為createPrefixTree(word,W),得到左遞歸新詞集合P1,其具體又分為以下幾步:
a.通過W計算出word的左信息熵和互信息,如果左信息熵和互信息滿足閾值要求,則進行步驟b;如果左信息熵和互信息不滿足閾值要求,則進行步驟c;
b.若已有詞庫S中不包含word,則把word加入到新詞集合P1;判斷集合W是否遍歷完,若沒有遍歷完,則跳回步驟三,反之,進入步驟七;
c.計算word的左鄰字集pre{pre1,pre2,…,prek}:
步驟七:右遞歸,即針對word執行createSufTree(word,W),得到右遞歸新詞集合P2。
a.通過W計算出word的右信息熵和互信息,如果右信息熵和互信息滿足閾值要求,則進行步驟b;如果右信息熵和互信息不滿足閾值要求,則進行步驟c;
b.若現有詞庫S中不包含word,則把word加入到新詞集合P2;判斷集合W是否遍歷完,若沒有遍歷完,則跳回步驟三,反之,進入步驟八;
c.計算word的右鄰字集suf{suf1,suf2,…,sufk}
步驟八:合并,即計算集合P1和集合P2的交集得到發現的新詞集合P3。
附圖說明
以下參考附圖是對本發明的結構和工作流程進行說明,其中:
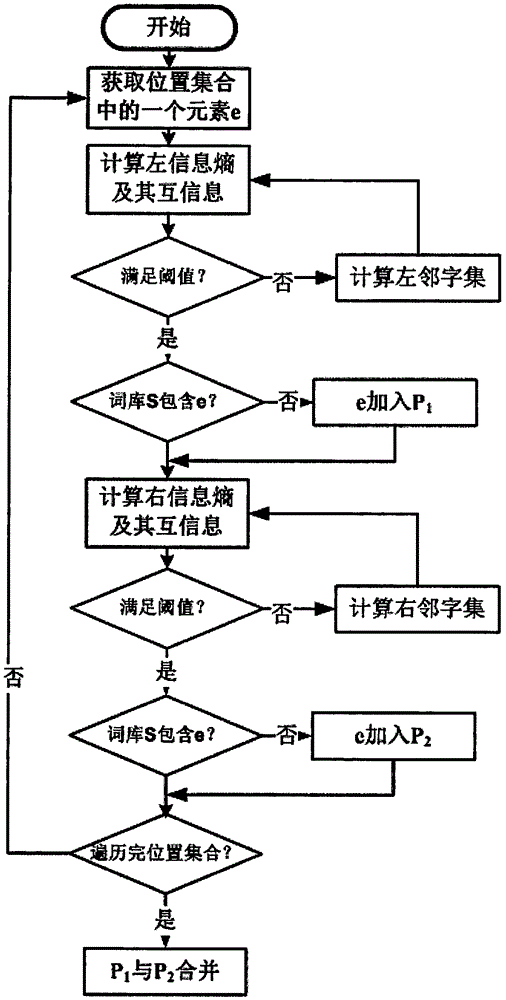
圖1 是一種左右遞歸新詞發現方法的流程圖
圖2 是輸入語料預處理框圖
圖3 是左遞歸流程圖
圖4 是右遞歸流程圖
具體實施方式
下面結合附圖來對本發明所述的“一種左右遞歸新詞發現方法”的實施方式作進一步的說明。
(1)輸入語料預處理
輸入語料預處理涉及到正則過濾、半角轉換、空白符號刪除、特殊符號刪除、非文本符刪除、切分句子和Hash去重七個步驟。
輸入語料預處理涉及的幾個步驟可以互換,本方法提供了其中一種實施方法作為驗證,即按照正則過濾、半角轉換、空白符號刪除、特殊符號刪除、非文本符刪除、切分句子、Hash去重的順序進行輸入語料預處理。其中:正則過濾的作用是刪除語料中包含的Html標簽、Xml標簽等與文本無關的特殊標簽;半角轉換是對語料中的符號進行全角轉半角操作、中文繁體轉簡體操作以及規范首行操作;空白符號刪除是刪除語料中多余的空格、換行符、制表符;特殊符號刪除是刪除語料中包含的ASCII編碼、特殊編碼、亂碼;非文本符刪除是刪除文本中的非文本數據;切分句子是通過斷句標志,即“。”、“!”、“?”、“…”、“;”、空格、換行符將語料切分成一個一個的句子,如果句中包含對稱的符號,例如引號、書名號等則要求左右匹配,最后還需要把分好的句子進行編號;Hash去重是對分好的句子進行Hash求值,對Hash碼完全相同的句子進行去重。
這種預處理技術可以使語料規范、準確、有意義的,避免了因為語料本身的缺陷、誤差造成的錯誤指標計算。
(2)新詞發現方法
本新詞發現方法基于左右遞歸,可以有效的發現少數名族人名、英譯人名、英譯地名等字符串長度很長的新詞。它的基本流程是:從位置集合中任取一個元素,記為e,首先計算它的左信息熵和互信息,然后與閾值比較,若左信息熵和互信息大于等于閾值并且詞庫S中沒有包含e,就將e加入詞庫P1;若左信息熵和互信息小于閾值則計算e的左鄰字集,然后再計算左鄰字集,并針對左鄰字集中每個元素的左信息熵和互信息并作進一步閾值判斷和是否加入詞庫P1的判斷,符合條件則加入,否則遞歸進行計算。同理進行右遞歸,并將符合條件的新詞加入詞庫P2中。最后,求P1和P2的交集,即可得到最終的新詞集合。
我們具體實施了新詞發現方法,采用的是百度百科200篇以“電影”為主題的真實文章作為實驗數據。在這200篇文章中頻繁地出現了少數名族人名、音譯人名、音譯地名等詞語。
具體實施步驟如下:
①使用現有的新詞發現方法對這200篇文章進行新詞發現,記錄發現的新詞,并計算出正確率、召回率和F值。
②使用本新詞發現方法對這200篇文章進行新詞發現,記錄發現的新詞,并計算出正確率、召回率和F值。
③針對現有的新詞發現方法和本新詞發現方法的新詞發現結果做對比和分析。
實驗結果與分析
表1新詞發現方法結果對比
從表1看出在窗口大小設為4的情況下傳統的新詞發現方法只能發現字符串長度不超過4的新詞,可以明顯的看出“妮絲·帕”、“萊昂納多”、“里弗”、“速度與激”、“漢弗萊”等詞只是新詞的一部分,由于現有的新詞發現方法發現出的新詞與窗口設定的大小息息相關,新詞的長度不能超過窗口的大小;而本新詞發現方法是基于左右遞歸的新詞發現方法,它發現的新詞不受字符串的長度限制。
我們采用了正確率(precision)、召回率(recall)和F值(F-measure)三個指標來對新詞發現結果進行評判,其中
正確率計算公式如下:
召回率計算公式如下:
F值計算公式如下:
在以上公式中,n1代表了正確識別出的新詞個數;n2代表了識別出的詞串的總個數;n3代表了語料中新詞的總個數。
表2各個指標評測結果
如表2各個指標評測結果所示,我們的新詞發現方法對于長度較長的新詞發現效果有顯著提高,在其他指標方面,我們的方法提高。
(3)左遞歸方法
左遞歸的實施如下:
首先獲取從位置集合中任取一個元素,記為word;
接著根據公式(4)及其示例計算word的左信息熵;
第三,根據預設的信息熵閾值,檢測計算出的左信息熵是否滿足閾值,若不滿足則計算word的左鄰集合。并在左鄰集合中任取一個元素pre,將pre與word組合成pre+word返回上一步重新計算左信息熵,并再次做判斷,以此類推;
第四,如果計算出的左信息熵滿足閾值,則根據公式(2)和(3)計算互信息;
第五,根據預設的互信息閾值,檢測計算出的互信息是否滿足閾值,若不滿足則計算對應的左鄰集合,并在左鄰集合中任取一個元素pre,將pre與word組合成pre+word返回上一步重新計算左信息熵,并再次做判斷,以此類推;
第六,如果計算出的互信息滿足閾值,則判斷word或者pre+word是否已經存在于詞庫,如果沒有存在則加入詞庫P1,如果存在則從位置集合中再取出一個新的word,重復進行前述步驟。
(4)右遞歸方法
右遞歸的實施如下:
首先從位置集合中任取一個元素,記為word;
接著根據公式(4)及其示例計算右信息熵;
第三,根據預設的信息熵閾值,檢測計算出的右信息熵是否滿足閾值,如不滿足則計算word的右鄰集合,并在右鄰集合中任取一個元素suf,將word與suf組合成word+suf返回上一步重新計算右信息熵,并再次做判斷,以此類推;
第四,如果計算出的右信息熵滿足閾值,則根據公式(2)和(3)計算互信息;
第五,根據預設的互信息閾值,檢測計算出的互信息是否滿足閾值,若不滿足則計算對應的右鄰集合,并在右鄰集合中任取一個元素suf,將word與suf組合成word+suf返回上一步重新計算右信息熵,并再次做判斷,以此類推;
第六,如果計算出的互信息滿足閾值,則判斷word或者word+suf是否已經存在于詞庫,如果沒有存在則加入詞庫P2,如果存在則從位置集合中再取出一個新的word,重復進行前述步驟。
- 還沒有人留言評論。精彩留言會獲得點贊!