基于流式計算的數據監控方法及裝置與流程
本發明實施例涉及計算機技術領域,尤其涉及一種基于流式計算的數據監控方法及裝置。
背景技術:
隨著互聯網技術的飛速發展,網絡業務量不斷增大,業務方的不斷增多,使得服務被調用的次數明顯增大,進而對網絡的大數據處理提出了較高要求;現有技術中,通過storm流式計算框架接收服務請求日志信息,經由storm做簡單處理后,將明細數據寫入到MySQL中。
然而,在實施本技術方案的過程中,發現現有技術存在以下缺陷:由于storm接收數據的方式只支持阻塞方式的消息隊列,消息只能通過實時的接收,在訪問量暴增的情況下,storm對于MySQL的實時寫入壓力會同時暴增,會對MySQL數據庫造成巨大的壓力,同時也會減緩計算速度和數據的顯示速度。
技術實現要素:
本發明實施例提供一種基于流式計算的數據監控方法及裝置,可以有效克服現有技術中存在的會對MySQL數據庫造成巨大的壓力,同時也會減緩計算速度和數據的顯示速度的問題。
本發明實施例的一方面提供了一種基于流式計算的數據監控方法,包括:
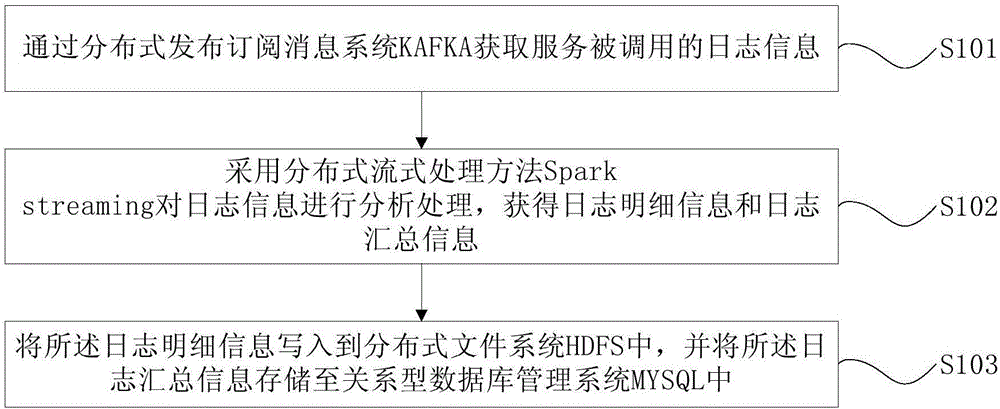
通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息;
采用分布式流式處理方法Spark streaming對日志信息進行分析處理,獲得日志明細信息和日志匯總信息;
將所述日志明細信息寫入到分布式文件系統HDFS中,并將所述日志匯總信息存儲至關系型數據庫管理系統MYSQL中。
如上所述的基于流式計算的數據監控方法,所述通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息,具體包括:
通過預設的監控埋點AGENT從服務端中獲取服務被調用的日志信息;
將所述日志信息寫入到所述KAFKA中預先創建的TOPIC中。
如上所述的基于流式計算的數據監控方法,所述采用分布式流式處理方法Spark streaming對日志信息進行分析處理,具體包括:
采用預設的匯總算法對所述日志信息進行分析處理,獲得所述日志匯總信息。
如上所述的基于流式計算的數據監控方法,所述采用分布式流式處理方法Spark streaming對日志信息進行分析處理,具體包括:
獲取KAFKA中所述TOPIC的TOPIC信息;
根據所述TOPIC信息并按照預設的采集周期從所述KAFKA中拉取相應的所述日志明細信息。
如上所述的基于流式計算的數據監控方法,在將所述日志匯總信息存儲至關系型數據庫管理系統MYSQL中之后,所述方法還包括:
接收用戶發送的查詢指令,所述查詢指令中包括查詢時間;
根據所述查詢指令從所述MYSQL中查找與所述查詢時間相對應的日志匯總信息,并顯示所查找到的日志匯總信息。
本發明的又一方面提供了一種基于流式計算的數據監控裝置,包括:
獲取模塊,用于通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息;
處理模塊,用于采用分布式流式處理方法Spark streaming對日志信息進行分析處理,獲得日志明細信息和日志匯總信息;
存儲模塊,用于將所述日志明細信息寫入到分布式文件系統HDFS中,并將所述日志匯總信息存儲至關系型數據庫管理系統MYSQL中。
如上所述的基于流式計算的數據監控裝置,所述獲取模塊,具體用于:
通過預設的監控埋點AGENT從服務端中獲取服務被調用的日志信息;
將所述日志信息寫入到所述KAFKA中預先創建的TOPIC中。
如上所述的基于流式計算的數據監控裝置,所述處理模塊,具體用于:
采用預設的匯總算法對所述日志信息進行分析處理,獲得所述日志匯總信息。
如上所述的基于流式計算的數據監控裝置,所述處理模塊,具體用于:
獲取KAFKA中所述TOPIC的TOPIC信息;
根據所述TOPIC信息并按照預設的采集周期從所述KAFKA中拉取相應的所述日志明細信息。
如上所述的基于流式計算的數據監控裝置,所述數據監控裝置還包括:
接收模塊,用于在將所述日志匯總信息存儲至關系型數據庫管理系統MYSQL中之后,接收用戶發送的查詢指令,所述查詢指令中包括查詢時間;
顯示模塊,用于根據所述查詢指令從所述MYSQL中查找與所述查詢時間相對應的日志匯總信息,并顯示所查找到的日志匯總信息。。
本發明提供的基于流式計算的數據監控方法及裝置,通過KAFKA獲取服務被調用的日志信息,采用Spark streaming對日志信息進行分析處理,并將得到的日志明細信息寫入HDFS中,將日志匯總信息存儲至MYSQL中,有效地解決了現有技術中存在的會對MySQL數據庫造成巨大的壓力,同時也會減緩計算速度和數據的顯示速度的問題,提高了數據處理效率,同時減緩了對MySQL數據庫造成的數據壓力,進而提高了該數據監控方法應用的穩定可靠性,有利于市場的推廣與應用。
附圖說明
圖1為本發明實施例提供的一種基于流式計算的數據監控方法的流程示意圖;
圖2為本發明實施例提供的通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息的流程示意圖;
圖3為本發明實施例提供的采用分布式流式處理方法Spark streaming對日志信息進行分析處理的流程示意圖;
圖4為本發明實施例提供的顯示所查找到的日志匯總信息的流程示意圖;
圖5為本發明實施例提供的一種基于流式計算的數據監控裝置的結構示意圖;
圖6為本發明實施例提供的基于流式計算的數據監控裝置具體應用時的流程示意圖。
具體實施方式
下面結合附圖和實施例,對本發明的具體實施方式作進一步詳細描述。以下實例用于說明本發明,但不用來限制本發明的范圍。
圖1為本發明實施例提供的一種基于流式計算的數據監控方法的流程示意圖;參考附圖1可知,本實施例提供了一種基于流式計算的數據監控方法,包括:
S101:通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息;
KAFKA是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據;這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網絡上的許多社會功能的一個關鍵因素。這些數據通常是由于吞吐量的要求而通過處理日志和日志聚合來解決,通過KAFKA獲取服務被調用的日志信息,可以實現通過Hadoop的并行加載機制來統一線上和離線的消息處理,并通過集群機來提供實時的消費。
S102:采用分布式流式處理方法Spark streaming對日志信息進行分析處理,獲得日志明細信息和日志匯總信息;
其中,本實施例對于采用分布式流式處理方法對日志信息進行分析處理的具體實現過程不做限定,本領域技術人員可以根據具體的設計需求進行設置,只要能夠通過對日志信息進行分析處理獲得日志明細信息和日志匯總信息即可,在此不再贅述。
S103:將日志明細信息寫入到分布式文件系統HDFS中,并將日志匯總信息存儲至關系型數據庫管理系統MYSQL中。
將日志明細信息寫入到HDFS中,將日志匯總信息存儲至MYSQL中,有效提提高了數據收集以及數據計算的效率,緩解了MYSQL的數據處理壓力和存儲壓力,進而提高了該數據監控方法的實用性。
本實施例提供的基于流式計算的數據監控方法,通過KAFKA獲取服務被調用的日志信息,采用Spark streaming對日志信息進行分析處理,并將得到的日志明細信息寫入HDFS中,將日志匯總信息存儲至MYSQL中,有效地解決了現有技術中存在的會對MySQL數據庫造成巨大的壓力,同時也會減緩計算速度和數據的顯示速度的問題,提高了數據處理效率,同時減緩了對MySQL數據庫造成的數據壓力,進而提高了該數據監控方法應用的穩定可靠性,有利于市場的推廣與應用。
圖2為本發明實施例提供的通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息的流程示意圖;在上述實施例的基礎上,參考附圖2可知,本實施例對于通過KAFKA獲取日志信息的具體實現過程不做限定,較為優選的,將通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息,設置為具體包括:
S1011:通過預設的監控埋點AGENT從服務端中獲取服務被調用的日志信息;
在具體應用時,可能會存在多個服務端,因此,為了保證日志信息獲取的準確度,可以將每個服務端中設置有AGENT,以使得AGENT從服務端中可以有效獲取到服務被調用的日志信息。
S1012:將日志信息寫入到KAFKA中預先創建的TOPIC中。
在AGENT獲取到日志信息后,將日志信息寫入到KAFKA消息隊列中,KAFKA根據不同的服務設定到預先創建的TOPIC中,進而實現了KAFKA獲取到日志信息的過程。
通過設置的AGENT獲取日志信息,有效地保證了日志信息獲取的準確可靠性,并且將日志信息存儲在KAFKA中預先創建的TOPIC中,有效地保證了日志信息存儲的穩定性,并且便于對日志信息的調用與計算處理。
圖3為本發明實施例提供的采用分布式流式處理方法Spark streaming對日志信息進行分析處理的流程示意圖;在上述實施例的基礎上,繼續參考附圖3可知,本實施例對于采用分布式流式處理方法Spark streaming對日志信息進行分析處理的具體實現過程不做限定,本領域技術人員可以根據具體的設計需求進行設置,其中,較為優選的,將采用分布式流式處理方法Spark streaming對日志信息進行分析處理,設置為具體包括:
S1021:采用預設的匯總算法對日志信息進行分析處理,獲得日志匯總信息。
其中,匯總算法為預先設置的,并且該匯總算法可以為現有技術中的處理算法,用于對日志信息進行匯總處理,進而可以獲得日志匯總信息;另外,為了進一步減緩數據處理的壓力,用戶可以設置計算周期,按照預設的計算周期獲取日志匯總信息,進而實現了周期內的日志指標匯總。
S1022:獲取KAFKA中TOPIC的TOPIC信息;
由于日志信息存儲在KAFKA中的TOPIC中,因此,在獲取日志明細信息之前,需要配置對應的TOPIC信息,以實現從KAFKA中拉取相應的日志信息。
S1023:根據TOPIC信息并按照預設的采集周期從KAFKA中拉取相應的日志明細信息。
用戶可以按照預設的采集周期定期獲取日志明細信息,進而可以有效地減少日志信息處理的壓力,并且還可以有效地提高對日志信息處理的效率,進一步提高了該數據監控方法的實用性。
圖4為本發明實施例提供的顯示所查找到的日志匯總信息的流程示意圖;在上述實施例的基礎上,繼續參考附圖4可知,在經過分析處理后,獲得日志明細信息和日志匯總信息后,為了方便用戶調取與查看,在將日志匯總信息存儲至關系型數據庫管理系統MYSQL中之后,將方法還包括:
S201:接收用戶發送的查詢指令,查詢指令中包括查詢時間;
其中,對于接收用戶發送的查詢指令的具體實現方式不做限定,本領域技術人員可以根據具體的設計需求進行設置,例如:可以通過藍牙、WiFi以及有線連接的方式來接收用戶發送的查詢指令,查詢指令中包括查詢時間,以按照查詢時間獲得相對應的日志匯總信息/日志明細信息。
S202:根據查詢指令從MYSQL中查找與查詢時間相對應的日志匯總信息,并顯示所查找到的日志匯總信息。
當用戶欲查詢的信息為日志匯總信息時,由于日志匯總信息存儲于MYSQL中,因此,可以在MYSQL中查找與查詢時間相對應的日志匯總信息,并可以通過顯示設備顯示所查找到的日志匯總信息,方便用戶直觀查看日志匯總信息。
相類似的,當用戶欲查詢的信息為日志明細信息時,由于日志明細信息存儲于HDFS中,因此,可以在HDFS中查找與查詢時間相對應的日志明細信息,并可以通過顯示設備顯示所查找到的日志明細信息,方便用戶直觀查閱日志明細信息。
通過上述查閱并顯示日志匯總信息的方式,可以方便用戶對日志匯總信息進行查閱與管理,進一步提高了該數據監控方法的實用性,有利于市場的推廣與應用。
具體應用時,參考附圖6可知,本技術方案所提供的數據監控方法的操作步驟如下:
1、啟動KAFKA,創建對應的TOPIC;
2、服務日志通由埋點AGENT被寫入到對應的KAFKA的TOPIC中;
3、SPARKSTREAMING開發,用戶根據需求設定數據采集周期;指定KAFKA中的TOPIC;根據原有指標統計算法,設置基于SPARK的匯總算法;
4、SPARKSTREAMING按照數據采集周期接收KAFKA中的日志數據,并對日志數據進行匯總計算,獲得日志匯總指標;
5、將從KAFKA中被SPARKSTREAMING拉取的服務日志明細數據寫入到HDFS文件系統中;
6、匯總指標數據寫入到MYSQL數據庫中;
7、當前端調用查詢時,根據選擇的時間周期,從MYSQL數據庫中,匹配對應時間周期內的匯總指標;
8、將所選擇的數據返回前端進行展示。
基于上述過程,本技術方案較現有技術而言,可以有效地縮減了存空間,具體的,以服務QPS為4000條為例,假設,現有技術中存儲5分鐘的數據會產生4000*5=20000條數據;而本申請中同樣以周期5分鐘為例,將原有的5分鐘20000條數據直接匯總為1條,壓縮比例為20000:1;并且,當用于需要查看監控系統時,以監控周期為10分鐘為例,現有技術中需要提取出10分鐘內所有的明細數據,并在監控引擎中進行匯總計算,效率十分緩慢,且高占用網絡IO;而由于本技術方案中的數據存儲周期為5分鐘,因此,計算10分鐘的匯總數據,只需要提取2條數據即可,且計算邏輯只是單純的相加,從數據量和相應速度上大大提高,進而大大減少了MYSQL的讀寫壓力,進一步提高了該數據監控方法的實用性,有利于市場的推廣與應用。
圖5為本發明實施例提供的一種基于流式計算的數據監控裝置的結構示意圖;參考附圖5可知,本實施例提供了一種基于流式計算的數據監控裝置,該數據監控裝置用于對數據進行監控處理,具體包括:
獲取模塊1,用于通過分布式發布訂閱消息系統KAFKA獲取服務被調用的日志信息;
其中,對于獲取模塊1的具體形狀結構不做限定,本領域技術人員可以根據具體的設計需求進行設置;另外,本實施例中獲取模塊1所實現操作步驟的具體實現過程以及實現效果與上述實施例中步驟S101的實現過程以及實現效果相同,具體可參考上述陳述內容,在此不再贅述。
處理模塊2,用于采用分布式流式處理方法Spark streaming對日志信息進行分析處理,獲得日志明細信息和日志匯總信息;
其中,對于處理模塊2的具體形狀結構不做限定,本領域技術人員可以根據具體的設計需求進行設置;另外,本實施例中處理模塊2所實現操作步驟的具體實現過程以及實現效果與上述實施例中步驟S102的實現過程以及實現效果相同,具體可參考上述陳述內容,在此不再贅述。
存儲模塊3,用于將日志明細信息寫入到分布式文件系統HDFS中,并將日志匯總信息存儲至關系型數據庫管理系統MYSQL中。
其中,對于存儲模塊3的具體形狀結構不做限定,本領域技術人員可以根據具體的設計需求進行設置;另外,本實施例中存儲模塊3所實現操作步驟的具體實現過程以及實現效果與上述實施例中步驟S103的實現過程以及實現效果相同,具體可參考上述陳述內容,在此不再贅述。
本實施例提供的基于流式計算的數據監控裝置,獲取模塊1通過KAFKA獲取服務被調用的日志信息,處理模塊2采用Spark streaming對日志信息進行分析處理,并且存儲模塊3將得到的日志明細信息寫入HDFS中,將日志匯總信息存儲至MYSQL中,有效地解決了現有技術中存在的會對MySQL數據庫造成巨大的壓力,同時也會減緩計算速度和數據的顯示速度的問題,提高了數據處理效率,同時減緩了對MySQL數據庫造成的數據壓力,進而提高了該數據監控裝置應用的穩定可靠性,有利于市場的推廣與應用。
在上述實施例的基礎上,繼續參考附圖5可知,本實施例對于獲取模塊1通過KAFKA獲取日志信息的具體實現過程不做限定,較為優選的,將獲取模塊1,設置為具體用于:
通過預設的監控埋點AGENT從服務端中獲取服務被調用的日志信息;
將日志信息寫入到KAFKA中預先創建的TOPIC中。
本實施例中獲取模塊1所實現操作步驟的具體實現過程以及實現效果與上述實施例中步驟S1011-S1012的實現過程以及實現效果相同,具體可參考上述陳述內容,在此不再贅述。
獲取模塊1通過設置的AGENT獲取日志信息,有效地保證了日志信息獲取的準確可靠性,并且將日志信息存儲在KAFKA中預先創建的TOPIC中,有效地保證了日志信息存儲的穩定性,并且便于對日志信息的調用與計算處理。
在上述實施例的基礎上,繼續參考附圖5可知,本實施例對于處理模塊2采用分布式流式處理方法Spark streaming對日志信息進行分析處理的具體實現過程不做限定,較為優選的,將處理模塊2,具體用于:
采用預設的匯總算法對日志信息進行分析處理,獲得日志匯總信息;
處理模塊2,具體用于:
獲取KAFKA中TOPIC的TOPIC信息;
根據TOPIC信息并按照預設的采集周期從KAFKA中拉取相應的日志明細信息。
本實施例中處理模塊2所實現操作步驟的具體實現過程以及實現效果與上述實施例中步驟S1021-S1023的實現過程以及實現效果相同,具體可參考上述陳述內容,在此不再贅述。
用戶可以按照預設的采集周期定期獲取日志明細信息,進而可以有效地減少日志信息處理的壓力,并且還可以有效地提高對日志信息處理的效率,進一步提高了該數據監控裝置的實用性。
在上述實施例的基礎上,繼續參考附圖5可知,在經過分析處理后,獲得日志明細信息和日志匯總信息后,為了方便用戶調取與查看,將數據監控裝置設置為還包括:
接收模塊4,用于在將日志匯總信息存儲至關系型數據庫管理系統MYSQL中之后,接收用戶發送的查詢指令,查詢指令中包括查詢時間;
其中,對于接收模塊4的具體形狀結構不做限定,本領域技術人員可以根據具體的設計需求進行設置;另外,本實施例中接收模塊4所實現操作步驟的具體實現過程以及實現效果與上述實施例中步驟S201的實現過程以及實現效果相同,具體可參考上述陳述內容,在此不再贅述。
顯示模塊5,用于根據查詢指令從MYSQL中查找與查詢時間相對應的日志匯總信息,并顯示所查找到的日志匯總信息。
其中,對于顯示模塊5的具體形狀結構不做限定,本領域技術人員可以根據具體的設計需求進行設置,例如,可以將顯示模塊5設置為顯示器、智能終端顯示屏等;另外,本實施例中顯示模塊5所實現操作步驟的具體實現過程以及實現效果與上述實施例中步驟S202的實現過程以及實現效果相同,具體可參考上述陳述內容,在此不再贅述。
通過上述查閱并顯示日志匯總信息的方式,可以方便用戶對日志匯總信息進行查閱與管理,進一步提高了該數據監控裝置的實用性,有利于市場的推廣與應用。
在本發明所提供的幾個實施例中,應該理解到,所揭露的裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特征可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以采用硬件的形式實現,也可以采用硬件加軟件功能單元的形式實現。
上述以軟件功能單元的形式實現的集成的單元,可以存儲在一個計算機可讀取存儲介質中。上述軟件功能單元存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)或處理器(processor)執行本發明各個實施例所述方法的部分步驟。而前述的存儲介質包括:U盤、移動硬盤、只讀存儲器(Read-Only Memory,ROM)、隨機存取存儲器(Random Access Memory,RAM)、磁碟或者光盤等各種可以存儲程序代碼的介質。
本領域技術人員可以清楚地了解到,為描述的方便和簡潔,僅以上述各功能模塊的劃分進行舉例說明,實際應用中,可以根據需要而將上述功能分配由不同的功能模塊完成,即將裝置的內部結構劃分成不同的功能模塊,以完成以上描述的全部或者部分功能。上述描述的裝置的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
最后應說明的是:以上各實施例僅用以說明本發明的技術方案,而非對其限制;盡管參照前述各實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分或者全部技術特征進行等同替換;而這些修改或者替換,并不使相應技術方案的本質脫離本發明各實施例技術方案的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!