輸入表情信息的方法及裝置與流程
本公開涉及社交應(yīng)用領(lǐng)域,尤其涉及一種輸入表情信息的方法及裝置。
背景技術(shù):
隨著社交聊天軟件的使用率不斷提高,終端提供大量的表情符號(hào)供用戶選擇,用戶在聊天時(shí),可以選擇恰當(dāng)?shù)谋砬榉?hào)來生動(dòng)地表達(dá)用戶當(dāng)時(shí)的心情。
技術(shù)實(shí)現(xiàn)要素:
為克服相關(guān)技術(shù)中存在的問題,本公開提供一種輸入表情信息的方法及裝置。
根據(jù)本公開實(shí)施例的第一方面,提供一種輸入表情信息的方法,包括:獲取輸入者的目標(biāo)特征信息,所述目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取所述目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入所述目標(biāo)表情信息。
可選地,所述獲取輸入者的目標(biāo)特征信息,包括:獲取目標(biāo)信息,所述目標(biāo)信息包括以下至少一項(xiàng):第一圖像信息、音頻信息;從所述目標(biāo)信息中獲取所述目標(biāo)特征信息。
可選地,所述獲取目標(biāo)信息,包括:通過采集設(shè)備采集所述目標(biāo)信息;或者,獲取所述輸入者從本地?cái)?shù)據(jù)庫中選定的目標(biāo)信息。
可選地,所述方法還包括:獲取目標(biāo)數(shù)據(jù)庫,所述目標(biāo)數(shù)據(jù)庫包括指示輸入者的特征信息與表情信息之間的對(duì)應(yīng)關(guān)系;所述獲取所述目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息包括:根據(jù)所述目標(biāo)數(shù)據(jù)庫獲取所述目標(biāo)特征信息對(duì)應(yīng)的所述目標(biāo)表情信息。
可選地,所述目標(biāo)表情信息包括以下任一項(xiàng):表情圖標(biāo)信息、表情符號(hào)信息、第二圖像信息;其中,所述第二圖像信息是根據(jù)所述第一圖像信息獲取的。
可選地,所述方法還包括:確定所述目標(biāo)數(shù)據(jù)庫是否包括所述目標(biāo)特征信息與所述目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系;所述獲取所述目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息,包括:當(dāng)所述目標(biāo)數(shù)據(jù)庫不包括所述目標(biāo)特征信息與所述目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系時(shí),將所述第一圖像信息作為所述第二圖像信息,得到所述目標(biāo)表情信息;或者,對(duì)所述第一圖像信息進(jìn)行處理得到所述第二圖像信息,并將所述第二圖像信息作為所述目標(biāo)表情信息。
可選地,所述對(duì)所述第一圖像信息進(jìn)行處理得到所述第二圖像信息,并將所述第二圖像信息作為所述目標(biāo)表情信息包括:獲取所述輸入者選定的模型圖像;將所述第一圖像信息與所述模型圖像進(jìn)行合成得到第二圖像信息,將所述第二圖像信息作為所述目標(biāo)表情信息。
可選地,所述將所述第一圖像信息與所述模型圖像進(jìn)行合成得到第二圖像信息包括:提取所述第一圖像信息中的用戶的特征信息;將所述用戶的特征信息添加至所述模型圖像上所述輸入者選定的圖像區(qū)域。
可選地,所述對(duì)所述第一圖像信息進(jìn)行處理得到所述第二圖像信息,并將所述第二圖像信息作為所述目標(biāo)表情信息包括:獲取所述第一圖像信息的圖像參數(shù);將所述圖像參數(shù)調(diào)整至所述輸入者確定的目標(biāo)參數(shù)得到所述第二圖像信息,并將所述第二圖像信息作為所述目標(biāo)表情信息。
根據(jù)本公開實(shí)施例的第二方面,提供一種輸入表情信息的裝置,所述裝置包括:第一獲取模塊,被配置為獲取輸入者的目標(biāo)特征信息,所述目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;第二獲取模塊,被配置為獲取所述目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入模塊,被配置為輸入所述目標(biāo)表情信息。
可選地,所述第一獲取模塊包括:第一獲取子模塊,被配置為獲取目標(biāo)信息,所述目標(biāo)信息包括以下至少一項(xiàng):第一圖像信息、音頻信息;第二獲取子模塊,被配置為從所述目標(biāo)信息中獲取所述目標(biāo)特征信息。
可選地,所述第一獲取子模塊,被配置為通過采集設(shè)備采集所述目標(biāo)信息;或者,獲取所述輸入者從本地?cái)?shù)據(jù)庫中選定的目標(biāo)信息。
可選地,所述裝置還包括:第三獲取模塊,被配置為獲取目標(biāo)數(shù)據(jù)庫,所述目標(biāo)數(shù)據(jù)庫包括指示輸入者的特征信息與表情信息之間的對(duì)應(yīng)關(guān)系;所述第二獲取模塊,被配置為根據(jù)所述目標(biāo)數(shù)據(jù)庫獲取所述目標(biāo)特征信息對(duì)應(yīng)的所述目標(biāo)表情信息。
可選地,所述目標(biāo)表情信息包括以下任一項(xiàng):表情圖標(biāo)信息、表情符號(hào)信息、第二圖像信息;其中,所述第二圖像信息是根據(jù)所述第一圖像信息獲取的。
可選地,所述裝置還包括:確定模塊,被配置為確定所述目標(biāo)數(shù)據(jù)庫是否包括所述目標(biāo)特征信息與所述目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系;所述第二獲取模塊,被配置為當(dāng)所述目標(biāo)數(shù)據(jù)庫不包括所述目標(biāo)特征信息與所述目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系時(shí),將所述第一圖像信息作為所述第二圖像信息,得到所述目標(biāo)表情信息;或者,對(duì)所述第一圖像信息進(jìn)行處理得到所述第二圖像信息,并將所述第二圖像信息作為所述目標(biāo)表情信息。
可選地,所述第二獲取模塊,被配置為獲取所述輸入者選定的模型圖像;將所述第一圖像信息與所述模型圖像進(jìn)行合成得到第二圖像信息,將所述第二圖像信息作為所述目標(biāo)表情信息。
可選地,所述第二獲取模塊,被配置為提取所述第一圖像信息中的用戶的特征信息;將所述用戶的特征信息添加至所述模型圖像上所述輸入者選定的圖像區(qū)域。
可選地,所述第二獲取模塊,被配置為獲取所述第一圖像信息的圖像參數(shù);將所述圖像參數(shù)調(diào)整至所述輸入者確定的目標(biāo)參數(shù)得到所述第二圖像信息,并將所述第二圖像信息作為所述目標(biāo)表情信息。
根據(jù)本公開實(shí)施例的第三方面,提供一種輸入表情信息的裝置,其特征在于,包括:處理器;用于存儲(chǔ)處理器可執(zhí)行指令的存儲(chǔ)器;其中,所述處理器被配置為:獲取輸入者的目標(biāo)特征信息,所述目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取所述目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入所述目標(biāo)表情信息。
根據(jù)本公開實(shí)施例的第四方面,提供一種非臨時(shí)性計(jì)算機(jī)可讀存儲(chǔ)介質(zhì),當(dāng)所述存儲(chǔ)介質(zhì)中的指令由移動(dòng)終端的處理器執(zhí)行時(shí),使得移動(dòng)終端能夠執(zhí)行一種輸入表情信息的方法,所述方法包括:獲取輸入者的目標(biāo)特征信息,所述目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取所述目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入所述目標(biāo)表情信息。
本公開的實(shí)施例提供的技術(shù)方案可以包括以下有益效果:獲取輸入者的目標(biāo)特征信息,所述目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取所述目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入所述目標(biāo)表情信息,從而解決相關(guān)技術(shù)中表情信息輸入效率低的技術(shù)問題。
應(yīng)當(dāng)理解的是,以上的一般描述和后文的細(xì)節(jié)描述僅是示例性和解釋性的,并不能限制本公開。
附圖說明
此處的附圖被并入說明書中并構(gòu)成本說明書的一部分,示出了符合本公開的實(shí)施例,并與說明書一起用于解釋本公開的原理。
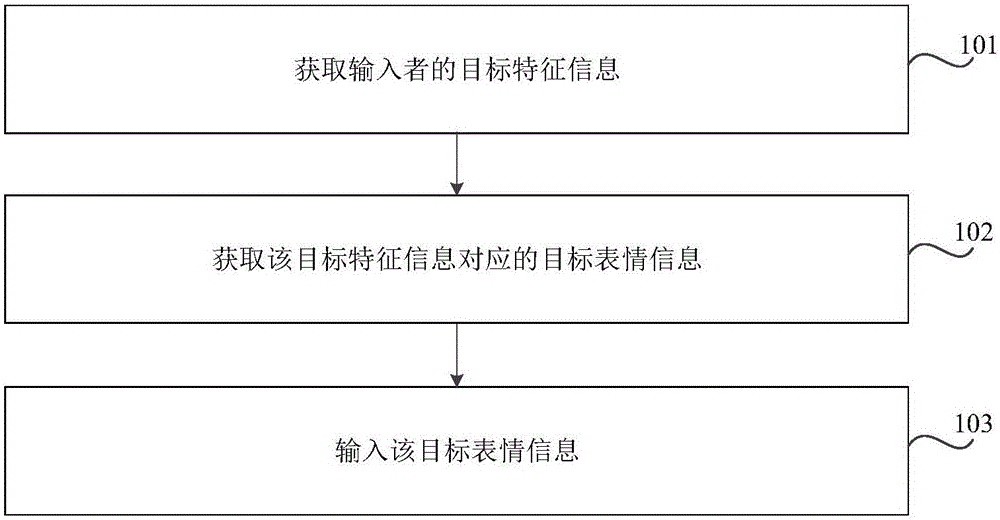
圖1是根據(jù)一示例性實(shí)施例示出的一種輸入表情信息的方法的流程圖;
圖2是根據(jù)一示例性實(shí)施例示出的另一種輸入表情信息的方法的流程圖;
圖3是根據(jù)一示例性實(shí)施例示出的又一種輸入表情信息的方法的流程圖;
圖4是根據(jù)一示例性實(shí)施例示出的第一種輸入表情信息的裝置的框圖;
圖5是根據(jù)一示例性實(shí)施例示出的第二種輸入表情信息的裝置的框圖;
圖6是根據(jù)一示例性實(shí)施例示出的第三種輸入表情信息的裝置的框圖;
圖7是根據(jù)一示例性實(shí)施例示出的第四種輸入表情信息的裝置的框圖;
圖8是根據(jù)一示例性實(shí)施例示出的第五種輸入表情信息的裝置的框圖。
具體實(shí)施方式
這里將詳細(xì)地對(duì)示例性實(shí)施例進(jìn)行說明,其示例表示在附圖中。下面的描述涉及附圖時(shí),除非另有表示,不同附圖中的相同數(shù)字表示相同或相似的要素。以下示例性實(shí)施例中所描述的實(shí)施方式并不代表與本公開相一致的所有實(shí)施方式。相反,它們僅是與如所附權(quán)利要求書中所詳述的、本公開的一些方面相一致的裝置和方法的例子。
本公開可以應(yīng)用于輸入信息的場(chǎng)景,例如通過終端(如手機(jī))進(jìn)行聊天或者發(fā)表言論等需要用戶輸入信息的場(chǎng)景,在該場(chǎng)景下,用戶往往會(huì)通過輸入表情信息生動(dòng)地表示用戶當(dāng)前的人物心情,如輸入一個(gè)笑臉的表情信息,以表示用戶當(dāng)前的心情是高興,又如輸入一個(gè)流淚的表情信息,以表示用戶當(dāng)前的心情是難過等,相關(guān)技術(shù)中,終端預(yù)先存儲(chǔ)大量表情信息,在輸入符合用戶當(dāng)前心情的表情符號(hào)時(shí),需要在羅列的表情信息中逐個(gè)查找,該查找過程耗費(fèi)大量時(shí)間,從而降低了輸入信息的效率。
為了解決上述問題,本公開提供一種輸入表情信息的方法和裝置,該方法是通過獲取輸入者的目標(biāo)特征信息,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入該目標(biāo)表情信息,這樣,避免了相關(guān)技術(shù)在輸入表情信息時(shí)耗費(fèi)大量的查找時(shí)間,從而解決了輸入表情信息效率低的技術(shù)問題。
下面通過具體實(shí)施例對(duì)本公開進(jìn)行詳細(xì)說明。
圖1是根據(jù)一示例性實(shí)施例示出的一種輸入表情信息的方法的流程圖,如圖1所示,應(yīng)用于終端中,包括以下步驟:
在步驟101中,獲取輸入者的目標(biāo)特征信息。
其中,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息。
本步驟中,可以獲取目標(biāo)信息,并從該目標(biāo)信息中獲取目標(biāo)特征信息,該目標(biāo)信息包括以下至少一項(xiàng):第一圖像信息、音頻信息。
在步驟102中,獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息。
其中,該目標(biāo)表情信息包括以下任一項(xiàng):表情圖標(biāo)信息、表情符號(hào)信息、第二圖像信息,該表情圖標(biāo)信息可以是表情靜態(tài)圖片,也可以是表情動(dòng)態(tài)圖片;該表情符號(hào)信息可以是顏文字,該顏文字是通過標(biāo)點(diǎn)符號(hào)或者英文字母組成的用于表示表情的圖案;該第二圖像信息是根據(jù)該第一圖像信息獲取的,上述示例只是舉例說明,本公開對(duì)此不作限定。
在步驟103中,輸入該目標(biāo)表情信息。
在本步驟中,可以在輸入?yún)^(qū)域輸入該目標(biāo)表情信息,該輸入?yún)^(qū)域可以是輸入框,該輸入框用于輸入表情信息或文本信息,在該目標(biāo)表情信息輸入至該輸入框后,可以將該目標(biāo)表情信息進(jìn)行發(fā)送,例如,在聊天場(chǎng)景下,可以將該目標(biāo)表情信息發(fā)送至對(duì)方;在瀏覽網(wǎng)頁(如小米論壇)的場(chǎng)景下,可以對(duì)相關(guān)新聞或者帖子發(fā)表個(gè)人看法的目標(biāo)表情信息;在更新個(gè)人主頁(如微信朋友圈或者微博)的場(chǎng)景下,可以上傳該目標(biāo)表情信息,上述示例只是舉例說明,本公開對(duì)此不作限定。
采用上述方法,通過獲取輸入者的目標(biāo)特征信息,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入該目標(biāo)表情信息,這樣,避免了相關(guān)技術(shù)在輸入表情信息時(shí)耗費(fèi)大量的查找時(shí)間,從而解決了表情信息輸入效率低的技術(shù)問題。
圖2是根據(jù)一示例性實(shí)施例示出的一種輸入表情信息的方法的流程圖,如圖2所示,本實(shí)施例中的目標(biāo)信息是以第一圖像信息為例進(jìn)行說明的,該方法包括以下步驟:
在步驟201中,獲取第一圖像信息。
在本步驟中,可以通過以下兩種方式獲取第一圖像信息:通過采集設(shè)備采集該第一圖像信息;或者,獲取輸入者從本地?cái)?shù)據(jù)庫中選定的第一圖像信息。
示例地,用戶在需要輸入表情信息時(shí),在輸入鍵盤上點(diǎn)擊表情輸入鍵,此時(shí),終端調(diào)用攝像頭,捕捉用戶的面部圖像信息或者肢體圖像信息(即第一圖像信息);或者終端獲取輸入者從相冊(cè)中(相當(dāng)于本地?cái)?shù)據(jù)庫)選定的面部圖像信息或者肢體圖像信息(即第一圖像信息),其中,該面部圖像信息可以包括面部器官的形態(tài)或者位置等圖像,如扮鬼臉的圖像,該肢體圖像信息可以包括肢體上動(dòng)作的圖像,如豎起大拇指的圖像,上述示例只是舉例說明,本公開對(duì)此不作限定。
在步驟202中,從該第一圖像信息中獲取目標(biāo)特征信息。
其中,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息,示例地,當(dāng)獲取到的第一圖像信息為面部圖像信息時(shí),可以通過獲取面部器官的形態(tài)和在面部的位置等信息,終端可根據(jù)面部器官發(fā)生的變化來提取該目標(biāo)特征信息,例如,面部器官的變化包括眉毛,眼睛,眼皮,嘴,鼻子等器官的形態(tài)變化和位置變化,如眉毛下彎,嘴角下拉,眉頭皺在一起,眼睛睜大,鼻子鼓起,臉頰抬起等變化;當(dāng)獲取到的第一圖像信息為肢體圖像信息時(shí),該目標(biāo)特征信息可以包括肢體上的動(dòng)作(通過手、肘、臂、胯、足等人體部位做出的動(dòng)作),示例地,搓手表示焦慮,捶胸表示痛苦,垂頭表示沮喪,頓足表示生氣,上述示例只是舉例說明,本公開對(duì)此不作限定。
在步驟203中,獲取目標(biāo)數(shù)據(jù)庫。
其中,該目標(biāo)數(shù)據(jù)庫包括指示輸入者的特征信息與表情信息之間的對(duì)應(yīng)關(guān)系,該表情信息可以是預(yù)先存儲(chǔ)的大量表情模型(如開心、傷心、恐懼、厭惡等表情模型),該特征信息可以包括面部特征信息和肢體特征信息,獲取該特征信息的方法參考步驟201,在此不進(jìn)行贅述。例如,通過攝像頭采集到一張面部圖像模型,并從該面部圖像模型中提取到的面部特征信息為笑臉,則將面部特征信息為笑臉與表示笑臉的表情信息建立對(duì)應(yīng)關(guān)系;又如,通過攝像頭采集到一張肢體圖像模型,并從該肢體圖像模型中提取到的肢體特征信息為捶胸,則將肢體特征信息為捶胸與表示痛苦的表情信息建立對(duì)應(yīng)關(guān)系;再如,由輸入者從相冊(cè)中選定的一張面部圖像模型,并從該面部圖像模型中提取到的面部特征信息為吐舌頭,則將面部特征信息為吐舌頭與表示調(diào)皮的表情信息建立對(duì)應(yīng)關(guān)系,這樣,在后續(xù)步驟中可以將獲取的目標(biāo)特征信息與該目標(biāo)數(shù)據(jù)庫中存儲(chǔ)的特征信息進(jìn)行匹配,從而得到目標(biāo)表情信息。
在步驟204中,確定該目標(biāo)數(shù)據(jù)庫是否包括目標(biāo)特征信息與目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系。
在本步驟中,可以通過以下兩種方式中的任一種確定該目標(biāo)數(shù)據(jù)庫是否包括目標(biāo)特征信息與目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系:
方式一:分別獲取該目標(biāo)特征信息與該目標(biāo)數(shù)據(jù)庫中存儲(chǔ)的特征信息的匹配度,并在該匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該匹配度對(duì)應(yīng)的特征信息為匹配特征信息,該匹配特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息,則確定該目標(biāo)數(shù)據(jù)庫包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系;在該匹配度小于預(yù)設(shè)閾值時(shí),則確定該目標(biāo)數(shù)據(jù)庫不包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系。
方式二:分別獲取該目標(biāo)特征信息與該目標(biāo)數(shù)據(jù)庫中存儲(chǔ)的特征信息的匹配度,對(duì)獲取的該匹配度按照從大到小的順序進(jìn)行排序得到最大匹配度,在該最大匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該最大匹配度對(duì)應(yīng)的特征信息為匹配特征信息,該匹配特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息,則確定該目標(biāo)數(shù)據(jù)庫包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系;在該最大匹配度小于預(yù)設(shè)閾值時(shí),則確定該目標(biāo)數(shù)據(jù)庫不包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系。
由上述描述可知,方式一是將獲取的匹配度依次與預(yù)設(shè)閾值進(jìn)行比較,在匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該匹配度對(duì)應(yīng)的特征信息為匹配特征信息,該匹配特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息,這樣,當(dāng)存在多個(gè)匹配度大于或者等于預(yù)設(shè)閾值時(shí),則可以獲取到多個(gè)目標(biāo)表情信息,從而用戶可以進(jìn)一步從多個(gè)目標(biāo)表情信息中選擇需要的表情信息;方式二則是在得到全部匹配度后,從得到的全部匹配度中選擇最大匹配度,并將該最大匹配度與預(yù)設(shè)閾值進(jìn)行比較,在該最大匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該最大匹配度對(duì)應(yīng)的特征信息為匹配特征信息,該匹配特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息。
在確定該目標(biāo)數(shù)據(jù)庫包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系時(shí),執(zhí)行步驟205;
在確定該目標(biāo)數(shù)據(jù)庫不包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系時(shí),執(zhí)行步驟206。
在步驟205中,輸入該目標(biāo)表情信息。
其中,該目標(biāo)表情信息包括以下任一項(xiàng):表情圖標(biāo)信息、表情符號(hào)信息,該表情圖標(biāo)信息可以是表情靜態(tài)圖片,也可以是表情動(dòng)態(tài)圖片;該表情符號(hào)信息可以是顏文字,該顏文字是通過標(biāo)點(diǎn)符號(hào)或者英文字母組成的用于表示表情的圖案,上述示例只是舉例說明,本公開對(duì)此不作限定。
在本步驟中,終端可以將該目標(biāo)表情信息輸入至輸入框,該輸入框用于輸入表情信息或文本信息,在該表情信息輸入至輸入框后,可以將該表情信息進(jìn)行發(fā)送,例如,在聊天場(chǎng)景下,可以將該表情信息發(fā)送至對(duì)方;在瀏覽網(wǎng)頁(如小米論壇)的場(chǎng)景下,可以對(duì)相關(guān)新聞或者帖子發(fā)表個(gè)人看法的表情信息;在更新個(gè)人主頁(如微信朋友圈或者微博)的場(chǎng)景下,可以上傳該表情信息。
需要說明的是,在步驟204中若存在多個(gè)匹配度大于或者等于預(yù)設(shè)閾值時(shí),則可以獲取到多個(gè)目標(biāo)表情信息,此時(shí),終端無法確定應(yīng)該輸入哪個(gè)目標(biāo)表情信息,為了解決該問題,在本公開另一實(shí)施例中,終端可以將得到的多個(gè)目標(biāo)表情信息通過展示框全部展示給用戶,以便用戶進(jìn)行選擇,并在用戶確定所需的目標(biāo)表情信息后,終端將輸入用戶選擇的目標(biāo)表情信息;在本公開另一實(shí)施例中,終端還可以將得到的全部目標(biāo)表情信息都輸入至輸入框中,當(dāng)然,為了進(jìn)一步提高用戶與終端的交互性,在本實(shí)施例中也可以由用戶通過終端對(duì)輸入至展示框的全部目標(biāo)表情信息進(jìn)行刪減,以便得到準(zhǔn)確的目標(biāo)表情信息,并發(fā)送出去,上述示例只是舉例說明,本公開對(duì)此不作限定。
在步驟206中,對(duì)該第一圖像信息進(jìn)行處理得到第二圖像信息,并將該第二圖像信息作為目標(biāo)表情信息。
在一種可能的實(shí)現(xiàn)方式中,可以通過以下兩種方式中的任一種對(duì)該第一圖像信息進(jìn)行處理得到該第二圖像信息,并將該第二圖像信息作為目標(biāo)表情信息:
方式一:獲取該輸入者選定的模型圖像;將該第一圖像信息與該模型圖像進(jìn)行合成得到第二圖像信息,將該第二圖像信息作為該目標(biāo)表情信息。具體地,提取該第一圖像信息中的用戶的特征信息,將該用戶的特征信息添加至該模型圖像上該輸入者選定的圖像區(qū)域,其中,該模型圖像可以是預(yù)先設(shè)置的圖像模板,用戶可以在該圖像模板中添加用戶的特征信息。例如,當(dāng)模型圖像是一只缺少眼睛和嘴巴的小貓,提取到的用戶特征是嘟嘴、眨眼睛時(shí),則將該用戶特征為嘟嘴和眨眼睛分別設(shè)置在小貓面部得嘴巴和眼睛對(duì)應(yīng)的位置;又如,當(dāng)模型圖像是缺少眉毛和嘴巴的白娘子,提取到的用戶特征是眉毛下彎、嘴角上揚(yáng)時(shí),則將該用戶特征為眉毛下彎、嘴角上揚(yáng)設(shè)置在白娘子面部的眉毛和嘴巴對(duì)應(yīng)的位置;再如,當(dāng)模型圖像是缺少腿部的唐老鴨,提取到的用戶特征是上腿跳起時(shí),則將該用戶特征為雙腿跳起設(shè)置在唐老鴨的腿部對(duì)應(yīng)的位置,上述示例只是舉例說明,本公開對(duì)此不作限定。
方式二:獲取該第一圖像信息的圖像參數(shù),將該圖像參數(shù)調(diào)整至該輸入者確定的目標(biāo)參數(shù)得到該第二圖像信息,并將該第二圖像信息作為該目標(biāo)表情信息,其中,該圖像參數(shù)可以包括圖像的顏色,或者圖像中五官的尺寸或者五官的位置等參數(shù)。例如,當(dāng)獲取的第一圖像信息中的圖像參數(shù)包括眼睛的大小以及嘴唇的顏色,終端可以調(diào)整該眼睛的大小以及嘴唇的顏色得到第二圖像信息,并將該第二圖像信息作為該目標(biāo)表情信息;又如,當(dāng)獲取的第一圖像信息中的圖像參數(shù)包括膚色、臉型,終端可以調(diào)整該膚色和臉型得到該第二圖像信息,并將該第二圖像信息作為該目標(biāo)表情信息;再如,當(dāng)獲取到的第一圖像信息中的圖像參數(shù)包括圖像顏色為彩色,終端可以將該圖像調(diào)整至黑白色得到第二圖像信息,并將該第二圖像信息作為該目標(biāo)表情信息,上述示例只是舉例說明,本公開對(duì)此不作限定。
為了進(jìn)一步減少輸入者對(duì)圖像的處理操作,在另一種可能實(shí)現(xiàn)的方式中,還可以將該第一圖像信息作為該第二圖像信息,得到該目標(biāo)表情信息,示例地,當(dāng)獲取到該第一圖像信息為揮手再見的圖像時(shí),則可以直接將該揮手再見的圖像作為目標(biāo)表情信息,從而提高了用戶的體驗(yàn)。
在確定該目標(biāo)表情信息后,執(zhí)行步驟205。
采用上述方法,通過獲取輸入者的目標(biāo)特征信息,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入該目標(biāo)表情信息,這樣,避免了相關(guān)技術(shù)在輸入表情信息時(shí)耗費(fèi)大量的查找時(shí)間,從而解決了表情信息輸入效率低的技術(shù)問題。
圖3是根據(jù)一示例性實(shí)施例示出的一種輸入表情信息的方法的流程圖,如圖3所示,本實(shí)施例中以目標(biāo)信息為音頻信息為例進(jìn)行說明,該方法可以包括以下步驟:
在步驟301中,獲取音頻信息。
在本步驟中,可以通過以下兩種方式獲取音頻信息:通過采集設(shè)備采集該音頻信息;或者,獲取輸入者從本地?cái)?shù)據(jù)庫中選定的音頻信息。
示例地,用戶在需要輸入表情信息時(shí),在輸入鍵盤上點(diǎn)擊表情輸入鍵,此時(shí),終端通過話筒采集用戶的音頻信息;或者,終端獲取輸入者從音樂庫或者錄音庫(相當(dāng)于本地?cái)?shù)據(jù)庫)中選定的音頻信息。
在步驟302中,從音頻信息中獲取目標(biāo)特征信息。
其中,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息。
在一種可能實(shí)現(xiàn)的方式中,終端將音頻信息轉(zhuǎn)換為文本信息后,從文本信息提取文本特征,該文本特征可以包括各種具有感情色彩的詞語(如愉快、難過、憤怒、驚恐等詞語),以及用在句末表示語氣的助詞(如啊、啦、呀、哇、唉、嗚、嗎等語氣助詞),還可以從音頻信息提取到包括音調(diào)、響度、音色等語音參數(shù),這樣,終端可以根據(jù)該文本特征和/或該語音參數(shù)得到目標(biāo)特征信息,如該文本特征為“哈哈”時(shí),則該目標(biāo)特征信息為微笑(即面部特征信息);又如該文本特征為“yeah”時(shí),則該目標(biāo)特征信息為剪刀手(即肢體特征信息),上述示例只是舉例說明,本公開對(duì)此不作限定。
在步驟303中,獲取目標(biāo)數(shù)據(jù)庫。
其中,該目標(biāo)數(shù)據(jù)庫包括指示輸入者的特征信息與表情信息之間的對(duì)應(yīng)關(guān)系,該表情信息是預(yù)先存儲(chǔ)的大量表情模型(如開心、傷心、恐懼、厭惡等表情模型),可以預(yù)先通過話筒采集輸入者的音頻信息模型或者由輸入者從本地?cái)?shù)據(jù)庫中選定音頻信息模型,并將該音頻信息模型轉(zhuǎn)換為文本信息模型,并從文本信息模型中提取文本特征(如具有感情色彩的詞語以及用在句末表示語氣的助詞),從而建立該文本特征與預(yù)設(shè)特征信息(即面部特征信息和肢體特征信息)之間的對(duì)應(yīng)關(guān)系,也可以根據(jù)音頻信息模型直接獲取到音調(diào)、響度、音色等語音參數(shù),并建立該語音參數(shù)與預(yù)設(shè)特征信息之間的對(duì)應(yīng)關(guān)系。
例如,通過話筒采集到音頻信息模型,并將該音頻信息模型轉(zhuǎn)換為文本信息模型后,從文本信息模型中提取到高興、開心或者愉快等文本特征,則該文本特征與表示開心的面部特征信息或者肢體特征信息建立對(duì)應(yīng)關(guān)系,并將該面部特征信息或者該肢體特征信息與表示笑臉的表情信息建立對(duì)應(yīng)關(guān)系;又如,通過話筒采集到音頻信息模型,并將該音頻信息模型轉(zhuǎn)換為文本信息模型后,從文本信息模型中提取到傷心、難過或者悲傷等文本特征,則將該文本特征與表示傷心的面部特征信息或者肢體特征信息建立對(duì)應(yīng)關(guān)系,并將該面部特征信息或者該肢體特征信息與表示傷心的表情信息建立對(duì)應(yīng)關(guān)系;再如,通過話筒采集到音頻信息模型,并從該音頻信息模型中提取到包括音調(diào)、響度和音色等語音參數(shù),則將該語音參數(shù)與對(duì)應(yīng)的面部特征信息或者肢體特征信息建立對(duì)應(yīng)關(guān)系,并且將該面部特征信息或者該肢體特征信息與對(duì)應(yīng)的表情信息建立對(duì)應(yīng)關(guān)系,這樣,在后續(xù)步驟中將獲取的目標(biāo)特征信息與該目標(biāo)數(shù)據(jù)庫中預(yù)設(shè)特征信息進(jìn)行匹配得到目標(biāo)表情信息。
在步驟304中,根據(jù)該目標(biāo)數(shù)據(jù)庫獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息。
其中,可以通過以下兩種方式中的任一種獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息:
方式一:分別獲取該目標(biāo)特征信息與該目標(biāo)數(shù)據(jù)庫中預(yù)設(shè)特征信息的匹配度,并在該匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該匹配度對(duì)應(yīng)的預(yù)設(shè)特征信息為目標(biāo)預(yù)設(shè)特征信息,該目標(biāo)預(yù)設(shè)特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息。
方式二:分別獲取該目標(biāo)特征信息與該目標(biāo)數(shù)據(jù)庫中預(yù)設(shè)特征信息的匹配度,對(duì)獲取的該匹配度按照從大到小的順序進(jìn)行排序得到最大匹配度,在該最大匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該最大匹配度對(duì)應(yīng)的預(yù)設(shè)特征信息為目標(biāo)預(yù)設(shè)特征信息,該目標(biāo)預(yù)設(shè)特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息。
由上述描述可知,方式一是將獲取的匹配度依次與預(yù)設(shè)閾值進(jìn)行比較,在匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該匹配度對(duì)應(yīng)的預(yù)設(shè)特征信息為目標(biāo)預(yù)設(shè)特征信息,該目標(biāo)預(yù)設(shè)特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息,這樣,當(dāng)存在多個(gè)匹配度大于或者等于預(yù)設(shè)閾值時(shí),則可以獲取到多個(gè)目標(biāo)表情信息;方式二則是在得到全部匹配度后,從得到的全部匹配度中選擇最大匹配度,并將該最大匹配度與預(yù)設(shè)閾值進(jìn)行比較,在該最大匹配度大于或者等于預(yù)設(shè)閾值時(shí),確定該最大匹配度對(duì)應(yīng)的預(yù)設(shè)特征信息為目標(biāo)預(yù)設(shè)特征信息,該目標(biāo)預(yù)設(shè)特征信息對(duì)應(yīng)的表情信息為目標(biāo)表情信息。
另外,若根據(jù)該目標(biāo)數(shù)據(jù)庫無法獲取該目標(biāo)特征信息對(duì)應(yīng)的該目標(biāo)表情信息,則終端可以通過提示框展示提示信息給用戶,以提醒用戶重新輸入音頻信息,該提示信息可以包括文本信息,如“表情匹配失敗,請(qǐng)重新輸入”,該提示信息還可以是以聲音的形式展示給用戶,該聲音可以提前進(jìn)行設(shè)置,示例地,可以設(shè)置成一段語音,如發(fā)出“輸入失敗”的聲音,或者是一段音樂,還可以是提示音等信息,本公開對(duì)具體的聲音設(shè)置不作限定,當(dāng)然,該提示信息還可以通過終端的呼吸燈或者閃光燈進(jìn)行提示,例如,通過呼吸燈或者閃光燈的發(fā)光頻率,或者通過呼吸燈的顏色等方式進(jìn)行提示。
在步驟305中,輸入該目標(biāo)表情信息。
其中,該目標(biāo)表情信息包括以下任一項(xiàng):表情圖標(biāo)信息、表情符號(hào)信息,該表情圖標(biāo)信息可以是表情靜態(tài)圖片,也可以是表情動(dòng)態(tài)圖片;該表情符號(hào)信息可以是顏文字,該顏文字是通過標(biāo)點(diǎn)符號(hào)或者英文字母組成的用于表示表情的圖案,上述示例只是舉例說明,本公開對(duì)此不作限定。
在本步驟中,終端可以將該目標(biāo)表情信息輸入至輸入框,該輸入框用于輸入表情信息或文本信息,在該表情信息輸入至輸入框后,可以將該表情信息進(jìn)行發(fā)送,例如,在聊天場(chǎng)景下,可以將該表情信息發(fā)送至對(duì)方;在瀏覽網(wǎng)頁(如小米論壇)的場(chǎng)景下,可以對(duì)相關(guān)新聞或者帖子發(fā)表個(gè)人看法的表情信息;在更新個(gè)人主頁(如微信朋友圈或者微博)的場(chǎng)景下,可以上傳該表情信息。
需要說明的是,在步驟304中若存在多個(gè)匹配度大于或者等于預(yù)設(shè)閾值時(shí),則可以獲取到多個(gè)目標(biāo)表情信息,此時(shí),終端無法確定應(yīng)該輸入哪個(gè)目標(biāo)表情信息,為了解決該問題,在本公開另一實(shí)施例中,終端可以將得到的多個(gè)目標(biāo)表情信息通過展示框全部展示給用戶,以便用戶進(jìn)行選擇,并在用戶確定所需的目標(biāo)表情信息后,終端將輸入用戶選擇的目標(biāo)表情信息;在本公開另一實(shí)施例中,終端還可以將得到的全部目標(biāo)表情信息都輸入至輸入框中,當(dāng)然,為了進(jìn)一步提高用戶與終端的交互性,在本實(shí)施例中也可以由用戶通過終端對(duì)輸入至展示框的全部目標(biāo)表情信息進(jìn)行刪減,以便得到準(zhǔn)確的目標(biāo)表情信息,并發(fā)送出去。
采用上述方法,通過獲取輸入者的目標(biāo)特征信息,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入該目標(biāo)表情信息,這樣,避免了相關(guān)技術(shù)在輸入表情信息時(shí)耗費(fèi)大量的查找時(shí)間,從而解決了表情信息輸入效率低的技術(shù)問題。
圖4是根據(jù)一示例性實(shí)施例示出的一種輸入表情信息的裝置的框圖,參照?qǐng)D4,該裝置包括第一獲取模塊401,第二獲取模塊402和輸入模塊403。
該第一獲取模塊401,被配置為獲取輸入者的目標(biāo)特征信息,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;
該第二獲取模塊402,被配置為獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;
該輸入模塊403,被配置為輸入該目標(biāo)表情信息。
可選地,圖5是圖4所示實(shí)施例示出的一種輸入表情信息的裝置的框圖,該第一獲取模塊401包括:
第一獲取子模塊4011,被配置為被配置為獲取目標(biāo)信息,該目標(biāo)信息包括以下至少一項(xiàng):第一圖像信息、音頻信息;
第二獲取子模塊4012,被配置為從該目標(biāo)信息中獲取該目標(biāo)特征信息。
可選地,該第一獲取子模塊4011,被配置為通過采集設(shè)備采集該目標(biāo)信息;或者,獲取該輸入者從本地?cái)?shù)據(jù)庫中選定的目標(biāo)信息。
可選地,圖6是圖4所示實(shí)施例示出的一種輸入表情信息的裝置的框圖,該裝置還包括:
第三獲取模塊404,被配置為獲取目標(biāo)數(shù)據(jù)庫,該目標(biāo)數(shù)據(jù)庫包括指示輸入者的特征信息與表情信息之間的對(duì)應(yīng)關(guān)系;
該第二獲取模塊402,被配置為根據(jù)該目標(biāo)數(shù)據(jù)庫獲取該目標(biāo)特征信息對(duì)應(yīng)的該目標(biāo)表情信息。
可選地,該目標(biāo)表情信息包括以下任一項(xiàng):表情圖標(biāo)信息、表情符號(hào)信息、第二圖像信息;其中,該第二圖像信息是根據(jù)該第一圖像信息獲取的。
可選地,圖7是圖6所示實(shí)施例示出的一種輸入表情信息的裝置的框圖,該裝置還包括:
確定模塊405,被配置為確定該目標(biāo)數(shù)據(jù)庫是否包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系;
該第二獲取模塊402,被配置為當(dāng)該目標(biāo)數(shù)據(jù)庫不包括該目標(biāo)特征信息與該目標(biāo)表情信息之間的對(duì)應(yīng)關(guān)系時(shí),將該第一圖像信息作為該第二圖像信息,得到該目標(biāo)表情信息;或者,對(duì)該第一圖像信息進(jìn)行處理得到該第二圖像信息,并將該第二圖像信息作為所述目標(biāo)表情信息。
可選地,該第二獲取模塊402,被配置為獲取該輸入者選定的模型圖像;將該第一圖像信息與該模型圖像進(jìn)行合成得到第二圖像信息,將該第二圖像信息作為該目標(biāo)表情信息。
可選地,該第二獲取模塊402,被配置為提取該第一圖像信息中的用戶的特征信息;將該用戶的特征信息添加至該模型圖像上該輸入者選定的圖像區(qū)域。
可選地,該第二獲取模塊402,被配置為獲取該第一圖像信息的圖像參數(shù):將該圖像參數(shù)調(diào)整至該輸入者確定的目標(biāo)參數(shù)得到該第二圖像信息,并將該第二圖像信息作為該目標(biāo)表情信息。
采用上述裝置,通過獲取輸入者的目標(biāo)特征信息,該目標(biāo)特征信息包括以下至少一項(xiàng):面部特征信息、肢體特征信息;獲取該目標(biāo)特征信息對(duì)應(yīng)的目標(biāo)表情信息;輸入該目標(biāo)表情信息,避免了相關(guān)技術(shù)在輸入表情信息時(shí)耗費(fèi)大量的查找時(shí)間,從而解決了表情信息輸入效率低的技術(shù)問題。
關(guān)于上述實(shí)施例中的裝置,其中各個(gè)模塊執(zhí)行操作的具體方式已經(jīng)在有關(guān)該方法的實(shí)施例中進(jìn)行了詳細(xì)描述,此處將不做詳細(xì)闡述說明。
圖8是根據(jù)一示例性實(shí)施例示出的一種用于輸入表情信息的裝置800的框圖。例如,裝置800可以是移動(dòng)電話,計(jì)算機(jī),數(shù)字廣播終端,消息收發(fā)設(shè)備,游戲控制臺(tái),平板設(shè)備,醫(yī)療設(shè)備,健身設(shè)備,個(gè)人數(shù)字助理等。
參照?qǐng)D8,裝置800可以包括以下一個(gè)或多個(gè)組件:處理組件802,存儲(chǔ)器804,電力組件806,多媒體組件808,音頻組件810,輸入/輸出(I/O)的接口812,傳感器組件814,以及通信組件816。
處理組件802通常控制裝置800的整體操作,諸如與顯示,電話呼叫,數(shù)據(jù)通信,相機(jī)操作和記錄操作相關(guān)聯(lián)的操作。處理組件802可以包括一個(gè)或多個(gè)處理器820來執(zhí)行指令,以完成上述的輸入表情信息的方法的全部或部分步驟。此外,處理組件802可以包括一個(gè)或多個(gè)模塊,便于處理組件802和其他組件之間的交互。例如,處理組件802可以包括多媒體模塊,以方便多媒體組件808和處理組件802之間的交互。
存儲(chǔ)器804被配置為存儲(chǔ)各種類型的數(shù)據(jù)以支持在裝置800的操作。這些數(shù)據(jù)的示例包括用于在裝置800上操作的任何應(yīng)用程序或方法的指令,聯(lián)系人數(shù)據(jù),電話簿數(shù)據(jù),消息,圖片,視頻等。存儲(chǔ)器804可以由任何類型的易失性或非易失性存儲(chǔ)設(shè)備或者它們的組合實(shí)現(xiàn),如靜態(tài)隨機(jī)存取存儲(chǔ)器(SRAM),電可擦除可編程只讀存儲(chǔ)器(EEPROM),可擦除可編程只讀存儲(chǔ)器(EPROM),可編程只讀存儲(chǔ)器(PROM),只讀存儲(chǔ)器(ROM),磁存儲(chǔ)器,快閃存儲(chǔ)器,磁盤或光盤。
電力組件806為裝置800的各種組件提供電力。電力組件806可以包括電源管理系統(tǒng),一個(gè)或多個(gè)電源,及其他與為裝置800生成、管理和分配電力相關(guān)聯(lián)的組件。
多媒體組件808包括在該裝置800和用戶之間的提供一個(gè)輸出接口的屏幕。在一些實(shí)施例中,屏幕可以包括液晶顯示器(LCD)和觸摸面板(TP)。如果屏幕包括觸摸面板,屏幕可以被實(shí)現(xiàn)為觸摸屏,以接收來自用戶的輸入信號(hào)。觸摸面板包括一個(gè)或多個(gè)觸摸傳感器以感測(cè)觸摸、滑動(dòng)和觸摸面板上的手勢(shì)。該觸摸傳感器可以不僅感測(cè)觸摸或滑動(dòng)動(dòng)作的邊界,而且還檢測(cè)與該觸摸或滑動(dòng)操作相關(guān)的持續(xù)時(shí)間和壓力。在一些實(shí)施例中,多媒體組件808包括一個(gè)前置攝像頭和/或后置攝像頭。當(dāng)裝置800處于操作模式,如拍攝模式或視頻模式時(shí),前置攝像頭和/或后置攝像頭可以接收外部的多媒體數(shù)據(jù)。每個(gè)前置攝像頭和后置攝像頭可以是一個(gè)固定的光學(xué)透鏡系統(tǒng)或具有焦距和光學(xué)變焦能力。
音頻組件810被配置為輸出和/或輸入音頻信號(hào)。例如,音頻組件810包括一個(gè)麥克風(fēng)(MIC),當(dāng)裝置800處于操作模式,如呼叫模式、記錄模式和語音識(shí)別模式時(shí),麥克風(fēng)被配置為接收外部音頻信號(hào)。所接收的音頻信號(hào)可以被進(jìn)一步存儲(chǔ)在存儲(chǔ)器804或經(jīng)由通信組件816發(fā)送。在一些實(shí)施例中,音頻組件810還包括一個(gè)揚(yáng)聲器,用于輸出音頻信號(hào)。
I/O接口812為處理組件802和外圍接口模塊之間提供接口,上述外圍接口模塊可以是鍵盤,點(diǎn)擊輪,按鈕等。這些按鈕可包括但不限于:主頁按鈕、音量按鈕、啟動(dòng)按鈕和鎖定按鈕。
傳感器組件814包括一個(gè)或多個(gè)傳感器,用于為裝置800提供各個(gè)方面的狀態(tài)評(píng)估。例如,傳感器組件814可以檢測(cè)到裝置800的打開/關(guān)閉狀態(tài),組件的相對(duì)定位,例如該組件為裝置800的顯示器和小鍵盤,傳感器組件814還可以檢測(cè)裝置800或裝置800一個(gè)組件的位置改變,用戶與裝置800接觸的存在或不存在,裝置800方位或加速/減速和裝置800的溫度變化。傳感器組件814可以包括接近傳感器,被配置用來在沒有任何的物理接觸時(shí)檢測(cè)附近物體的存在。傳感器組件814還可以包括光傳感器,如CMOS或CCD圖像傳感器,用于在成像應(yīng)用中使用。在一些實(shí)施例中,該傳感器組件1214還可以包括加速度傳感器,陀螺儀傳感器,磁傳感器,壓力傳感器或溫度傳感器。
通信組件816被配置為便于裝置800和其他設(shè)備之間有線或無線方式的通信。裝置800可以接入基于通信標(biāo)準(zhǔn)的無線網(wǎng)絡(luò),如WiFi,2G或3G,或它們的組合。在一個(gè)示例性實(shí)施例中,通信組件816經(jīng)由廣播信道接收來自外部廣播管理系統(tǒng)的廣播信號(hào)或廣播相關(guān)信息。在一個(gè)示例性實(shí)施例中,該通信組件816還包括近場(chǎng)通信(NFC)模塊,以促進(jìn)短程通信。例如,在NFC模塊可基于射頻識(shí)別(RFID)技術(shù),紅外數(shù)據(jù)協(xié)會(huì)(IrDA)技術(shù),超寬帶(UWB)技術(shù),藍(lán)牙(BT)技術(shù)和其他技術(shù)來實(shí)現(xiàn)。
在示例性實(shí)施例中,裝置800可以被一個(gè)或多個(gè)應(yīng)用專用集成電路(ASIC)、數(shù)字信號(hào)處理器(DSP)、數(shù)字信號(hào)處理設(shè)備(DSPD)、可編程邏輯器件(PLD)、現(xiàn)場(chǎng)可編程門陣列(FPGA)、控制器、微控制器、微處理器或其他電子元件實(shí)現(xiàn),用于執(zhí)行上述輸入表情信息的方法。
在示例性實(shí)施例中,還提供了一種包括指令的非臨時(shí)性計(jì)算機(jī)可讀存儲(chǔ)介質(zhì),例如包括指令的存儲(chǔ)器804,上述指令可由裝置800的處理器820執(zhí)行以完成上述輸入表情信息的方法。例如,該非臨時(shí)性計(jì)算機(jī)可讀存儲(chǔ)介質(zhì)可以是ROM、隨機(jī)存取存儲(chǔ)器(RAM)、CD-ROM、磁帶、軟盤和光數(shù)據(jù)存儲(chǔ)設(shè)備等。
本領(lǐng)域技術(shù)人員在考慮說明書及實(shí)踐本公開后,將容易想到本公開的其它實(shí)施方案。本申請(qǐng)旨在涵蓋本公開的任何變型、用途或者適應(yīng)性變化,這些變型、用途或者適應(yīng)性變化遵循本公開的一般性原理并包括本公開未公開的本技術(shù)領(lǐng)域中的公知常識(shí)或慣用技術(shù)手段。說明書和實(shí)施例僅被視為示例性的,本公開的真正范圍和精神由下面的權(quán)利要求指出。
應(yīng)當(dāng)理解的是,本公開并不局限于上面已經(jīng)描述并在附圖中示出的精確結(jié)構(gòu),并且可以在不脫離其范圍進(jìn)行各種修改和改變。本公開的范圍僅由所附的權(quán)利要求來限制。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!