智能對話裝置、反饋式智能語音控制系統及方法與流程
本發明涉及一種智能對話領域,特別是涉及一種智能對話裝置、反饋式智能語音控制系統及方法。
背景技術:
隨著語音分析技術的發展,現有很多智能人機對話裝置中都帶有語音控制,在現有的語音控制方案中,主要是單向無反饋的語音操控,即通過用戶輸入正確的語音指令,智能人機對話裝置對正確的語音指令進行響應,從而執行響應的操作;但是,當用戶輸入的語音指令有誤時,裝置無法分析用戶真實意圖,進而不能快速、準確地響應用戶,無法執行用戶想要其執行的正確操作,例如,對于某個帶有開關燈功能的智能人機對話裝置,如果該裝置內置的正確語音指令為“開燈”,即如果用戶對該裝置說“開燈”,則該裝置能快速準確地響應用戶的意圖,自動開燈,但是,如果用戶對該裝置說“請開下燈吧”,雖然此時用戶也是想讓該裝置自動開燈,但是由于用戶說的并不是正確語音指令“開燈”,從而導致該裝置無法識別用戶的語音指令,此時該裝置就無法快速、準確地響應用戶的真實意圖,無法執行用戶想要的開燈操作;
由此可知,現有的智能人機對話裝置在語音分析和處理這一塊有很大的技術缺陷,導致無法智能分析用戶語音指令,造成無法快速、準確地預測和響應用戶的真實意圖,并且,也不能在用戶發出錯誤語音指令的情況下對用戶進行指導與提示,告知其正確的語音指令,從而導致現有的智能人機對話裝置語音識別的范圍較窄、識別率較低,用戶使用體驗很差。
技術實現要素:
本發明要解決的技術問題是為了克服現有技術中智能人機對話裝置語音識別的范圍較窄、識別率較低,用戶使用體驗很差的缺陷,提供一種智能對話裝置、反饋式智能語音控制系統及方法。
本發明是通過下述技術方案來解決上述技術問題的:
本發明提供了一種反饋式智能語音控制系統,包括語音輸入模塊、語音識別模塊、數據處理模塊、本地指令庫以及mcu(微控制單元);
所述語音輸入模塊與所述語音識別模塊電連接,所述語音識別模塊與所述數據處理模塊電連接,所述數據處理模塊分別與所述本地指令庫及所述mcu電連接;
所述本地指令庫用于存儲文本指令及對應的控制指令;
所述語音輸入模塊用于采集用戶輸入的語音信息,并傳輸至所述語音識別模塊;
所述語音識別模塊用于將所述語音信息轉換為文本信息,并傳輸至所述數據處理模塊;
所述數據處理模塊用于判斷所述本地指令庫中是否包含與所述文本信息完全相同的文本指令,若否,則對所述文本信息與所述本地指令庫中的文本指令進行模糊匹配,若與一目標文本指令匹配成功,則將與所述目標文本指令對應的目標控制指令傳輸至所述mcu;
所述mcu用于根據所述目標控制指令執行操作。
較佳地,所述文本信息與所述目標文本指令匹配成功包括:
所述目標文本指令的關鍵字均包括在所述文本信息中,或,所述文本信息與所述目標文本指令的相同關鍵字的字數超過第一閾值,或,所述文本信息與所述目標文本指令的相同關鍵字的字數與所述目標文本指令的比值超過第二閾值。
較佳地,所述反饋式語音控制系統還包括語音輸出模塊;
所述數據處理模塊還用于在所述文本信息與所述目標文本指令匹配成功時,將所述目標文本指令傳輸至所述語音輸出模塊,所述語音輸出模塊用于輸出包括所述目標文本指令的提示語音。
較佳地,所述語音識別模塊還包括聲紋識別單元,用于在所述語音識別模塊接收到所述語音信息后,識別用戶的聲紋特征,并判斷識別出的聲紋特征是否與預設聲紋特征匹配,若是,則調用所述語音識別模塊將所述語音信息轉換為文本信息。
較佳地,所述反饋式智能語音控制系統還包括指紋識別模塊,用于對用戶指紋進行識別,并在識別成功之后啟用所述語音輸入模塊采集用戶輸入的語音信息。
較佳地,所述反饋式智能語音控制系統還包括指令增加模塊,用于將所述文本信息及所述文本信息與所述目標文本指令的對應關系增加至所述本地指令庫中進行存儲。
較佳地,所述反饋式智能語音控制系統還包括存儲模塊及統計模塊,所述存儲模塊用于在所述文本信息與所述目標文本指令匹配成功時存儲所述文本信息;
所述統計模塊用于統計所述文本信息的存儲次數,并在判斷所述存儲次數超過第三閾值時,啟用所述指令增加模塊。
較佳地,所述語音識別模塊包括:
第一預存單元,用于預存多個目標詞組及與每個目標詞組對應的同類詞組和近義詞組;
字符串轉換單元,用于將所述語音信息轉換為字符串;
拆分單元,用于將所述字符串拆分為若干詞組;
判斷單元,用于判斷拆分出的詞組是否包括存儲在所述第一預存單元中的目標詞組,并在判斷為是時,獲取與所述拆分出的詞組中的目標詞組對應的同類詞組和近義詞組;
文本信息生成單元,用于對所述拆分出的詞組中的非目標詞組與目標詞組或目標詞組對應的同類詞組和近義詞組進行任意組合,生成多個文本信息,并傳輸至所述數據處理模塊。
較佳地,所述語音識別模塊包括:
第二預存單元,用于預存不同種類的特殊語言的語音信息與一標準語言的語音信息的對應關系;
語言轉換單元,用于在識別出用戶輸入的語音信息為特殊語言的語音信息時,將特殊語言的語音信息轉換為對應的標準語言的語音信息;
文本轉換單元,用于將所述對應的標準語言的語音信息轉換為文本信息,并傳輸至所述數據處理模塊。
較佳地,在所述本地指令庫中,同一個控制指令對應多個文本指令,不同的文本指令用于表征不同的用戶表達習慣。
本發明還提供了一種智能對話裝置,其包括如上所述的反饋式智能語音控制系統。
較佳地,所述智能對話裝置為故事機或點讀機。
本發明還提供了一種反饋式智能語音控制方法,包括以下步驟:
s1、存儲文本指令及對應的控制指令;
s2、采集用戶輸入的語音信息;
s3、將所述語音信息轉換為文本信息;
s4、判斷是否有與所述文本信息完全相同的文本指令,若否,則對所述文本信息與所述文本指令進行模糊匹配,若與一目標文本指令匹配成功,則輸出與所述目標文本指令對應的目標控制指令;
s5、根據所述目標控制指令執行操作。
較佳地,步驟s4中所述文本信息與所述目標文本指令匹配成功包括:
所述目標文本指令的關鍵字均包括在所述文本信息中,或,所述文本信息與所述目標文本指令的相同關鍵字的字數超過第一閾值,或,所述文本信息與所述目標文本指令的相同關鍵字的字數與所述目標文本指令的比值超過第二閾值。
較佳地,步驟s4中在所述文本信息與所述目標文本指令匹配成功時,還輸出包括所述目標文本指令的提示語音。
較佳地,步驟s3包括:
根據所述語音信息識別用戶的聲紋特征,并判斷識別出的聲紋特征是否與預設聲紋特征匹配,若是,則將所述語音信息轉換為文本信息。
較佳地,步驟s2之前還包括:
對用戶指紋進行識別,若識別成功,則執行步驟s2。
較佳地,步驟s5之后還包括:
s6、存儲所述文本信息及所述文本信息與所述目標文本指令的對應關系。
較佳地,步驟s6中包括:
存儲所述文本信息,統計所述文本信息的存儲次數,并在判斷所述存儲次數超過第三閾值時,存儲所述文本信息與所述目標文本指令的對應關系。
較佳地,步驟s3包括:
s311、預存多個目標詞組及與每個目標詞組對應的同類詞組和近義詞組;
s312、將所述語音信息轉換為字符串;
s313、將所述字符串拆分為若干詞組;
s314、判斷拆分出的詞組是否包括存儲在所述預存單元中的目標詞組,并在判斷為是時,獲取與所述拆分出的詞組中的目標詞組對應的同類詞組和近義詞組;
s315、對所述拆分出的詞組中的非目標詞組與目標詞組或目標詞組對應的同類詞組和近義詞組進行任意組合,生成多個文本信息。
較佳地,步驟s3包括:
s321、預存不同種類的特殊語言的語音信息與一標準語言的語音信息的對應關系;
s322、在識別出用戶輸入的語音信息為特殊語言的語音信息時,將特殊語言的語音信息轉換為對應的標準語言的語音信息;
s323、將所述對應的標準語言的語音信息轉換為文本信息,并傳輸至所述數據處理模塊。
較佳地,步驟s1中同一個控制指令對應多個文本指令,不同的文本指令用于表征不同的用戶表達習慣。
本發明的積極進步效果在于:本發明實現了在智能人機對話過程中,當用戶輸入的語音指令有誤時,能夠對語音指令進行進一步分析,從而自動分析和預測用戶的真實意圖,進而能快速、準確地響應用戶的真實意圖,自動執行用戶想要執行的操作,從而提高了語音識別率和識別范圍,同時還可以將正確語音指令反饋提示給用戶,達到了對用戶進行指導的效果,改善了用戶的使用體驗。
附圖說明
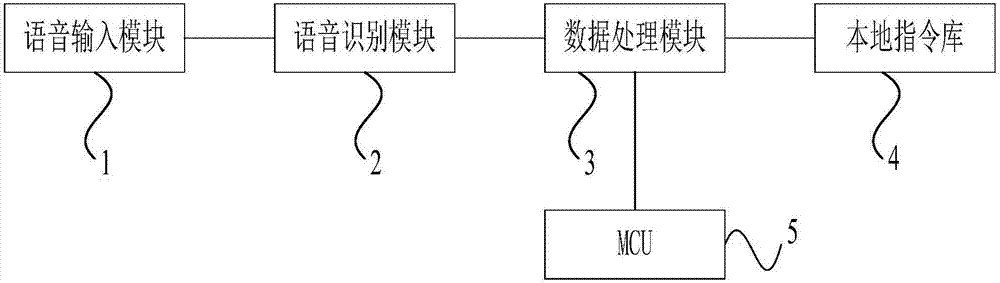
圖1為本發明的實施例1的反饋式智能語音控制系統的模塊示意圖。
圖2為本發明的實施例1的反饋式智能語音控制方法的流程圖。
圖3為本發明的實施例2的反饋式智能語音控制系統的模塊示意圖。
圖4為本發明的實施例2的反饋式智能語音控制方法的流程圖。
圖5為本發明的實施例3的反饋式智能語音控制系統的模塊示意圖。
圖6為本發明的實施例3的反饋式智能語音控制方法的流程圖。
圖7為本發明的實施例4的反饋式智能語音控制系統的語音識別模塊的模塊示意圖。
圖8為本發明的實施例4的反饋式智能語音控制方法中步驟103的具體操作流程圖。
圖9為本發明的實施例5的反饋式智能語音控制系統的語音識別模塊的模塊示意圖。
圖10為本發明的實施例5的反饋式智能語音控制方法中步驟103的具體操作流程圖。
具體實施方式
下面通過實施例的方式進一步說明本發明,但并不因此將本發明限制在所述的實施例范圍之中。
實施例1
如圖1所示,本實施例的反饋式智能語音控制系統包括語音輸入模塊1、語音識別模塊2、數據處理模塊3、本地指令庫4以及mcu5;
其中,所述語音輸入模塊1與所述語音識別模塊2電連接,所述語音識別模塊2與所述數據處理模塊3電連接,所述數據處理模塊3分別與所述本地指令庫4及所述mcu5電連接;
在所述本地指令庫4中,會預先存儲文本指令及對應的控制指令,所述控制指令用于控制所述mcu5執行相應的操作;
在本實施例中,所述語音輸入模塊1具體可包括麥克風,用于采集用戶輸入的語音信息,并傳輸至所述語音識別模塊2;
所述語音識別模塊2用于將所述語音信息轉換為文本信息,并傳輸至所述數據處理模塊;語音識別及語音轉換為文本已經屬于本領域比較成熟的技術,在此就不再贅述;
所述數據處理模塊3則用于判斷所述本地指令庫4中是否包含與所述文本信息完全相同的文本指令,若是,則說明用戶輸入的是正確語音指令,此時就可以和現有技術中一樣響應用戶的正確語音指令,即通過所述mcu5響應與所述文本指令相對應的控制指令,執行相應的操作;
若否,則對所述文本信息與所述本地指令庫4中的文本指令進行模糊匹配,若與一目標文本指令匹配成功,則將與所述目標文本指令對應的目標控制指令傳輸至所述mcu5;
所述mcu5用于根據所述目標控制指令執行操作。
在本實施例中,所述數據處理模塊3可以采用現有的模糊匹配算法來對所述文本信息與所述本地指令庫4中的文本指令進行模糊匹配,在此就不再贅述。
下面舉一個本實施例的反饋式智能語音控制系統的具體應用實例:
例如,在本實施例的反饋式智能語音控制系統中,所述本地指令庫中預先存儲了文本指令“開燈”以及對應的開燈指令,通過所述開燈指令可以控制所述mcu執行開燈操作;
當用戶輸入語音信息“開燈”時,所述語音識別模塊能夠將語音信息“開燈”轉換為文本信息“開燈”,所述數據處理模塊就會判斷出轉換后的文本信息“開燈”與所述本地指令庫中的文本指令“開燈”完全相同,此時,即可判斷出用戶發出的是正確語音指令,從而就可以控制所述mcu執行相應的開燈動作;
當用戶輸入語音信息“請開燈吧”時,所述語音識別模塊能夠將語音信息“請開燈吧”轉換為文本信息“請開燈吧”,所述數據處理模塊就會判斷出轉換后的文本信息“請開燈吧”與所述本地指令庫中的文本指令“開燈”并不相同,此時就會對所述文本信息“請開燈吧”與所述本地指令庫中預先存儲的各個文本指令分別進行模糊匹配,然后確定其與目標文本指令“開燈”匹配成功,并將與所述目標文本指令“開燈”相對應的開燈指令(即目標控制指令)傳輸至所述mcu,所述mcu就會根據開燈指令執行開燈操作;
可見,在本實施例中,當用戶輸入錯誤的語音指令時,本實施例的反饋式智能語音控制系統能夠在將用戶的語音指令轉換為文本信息后,對文本信息作進一步的分析處理,從而能夠準確分析預測用戶的真實意圖,并能夠響應用戶的真實意圖,自動執行用戶想要的操作。
本實施例還提供了一種反饋式智能語音控制方法,其利用本實施例的反饋式智能語音控制系統實現,如圖2所示,包括以下步驟:
步驟101、存儲文本指令及對應的控制指令;
步驟102、采集用戶輸入的語音信息;
步驟103、將所述語音信息轉換為文本信息;
步驟104、判斷是否有與所述文本信息完全相同的文本指令,若否,則對所述文本信息與所述文本指令進行模糊匹配,若與一目標文本指令匹配成功,則輸出與所述目標文本指令對應的目標控制指令;
步驟105、根據所述目標控制指令執行操作。
實施例2
本實施例的反饋式智能語音控制系統與實施例1基本相同,主要區別在于:如圖4所示,本實施例的反饋式智能語音控制系統還包括語音輸出模塊6以及指紋識別模塊7,并且所述語音識別模塊2還包括聲紋識別單元21;
在本實施例的反饋式智能語音控制系統中,在利用所述語音輸入模塊1采集用戶輸入的語音信息之前,可以先通過所述指紋識別模塊7對用戶進行指紋識別,并只有在對用戶進行指紋識別成功之后,才啟用所述語音輸入模塊1,若識別失敗,則不啟用所述語音輸入模塊,這樣指紋識別失敗的用戶就無法輸入語音指令來控制所述反饋式智能語音控制系統,從而本實施例的反饋式智能語音控制系統大大提升了保密性和安全性。
在指紋識別的實施方案中,具體可預先存儲正確的用戶指紋,這樣,在采集到指紋之后,進行指紋比對和匹配即可。
另外,在本實施例中,為了進一步提升保密性和安全性,本實施例中,在所述語音識別模塊2接收到所述語音信息后,會先由所述聲紋識別單元21識別用戶的聲紋特征,并判斷識別出的聲紋特征是否與預設聲紋特征匹配,若是,則調用所述語音識別模塊1將所述語音信息轉換為文本信息并執行后續操作,若否,則不調用所述語音識別模塊1。
由于每個人發出的語音信息都包含有其獨特的聲紋特征,這樣,本實施例中利用所述聲紋識別單元21可以保證,只有聲紋特征匹配的特定用戶發出的語音指令才會被進一步分析,從而提升了保密性和安全性。
另外,在本實施例中,所述數據處理模塊3還用于在所述文本信息與所述目標文本指令匹配成功時,將所述目標文本指令傳輸至所述語音輸出模塊6,所述語音輸出模塊6用于輸出包括所述目標文本指令的提示語音,從而可以將正確語音指令反饋給用戶,以實施例1中的應用實例為例,如果正確語音指令為“開燈”,當用戶輸入語音信息“請開燈吧”,經過上述各個模塊的操作之后,最終所述語音輸出模塊6會將包含正確語音指令的提示信息反饋給用戶,例如具體可以為向用戶語音提示:您是要開燈嗎?如果是的話可以對我說開燈。
在本實施例中,所述數據處理模塊3對所述文本信息與所述本地指令庫4中的文本指令進行的模糊匹配具體可以為:
判斷所述目標文本指令的關鍵字是否均包括在所述文本信息中,或,判斷所述文本信息與所述目標文本指令的相同關鍵字的字數是否超過第一閾值,或,判斷所述文本信息與所述目標文本指令的相同關鍵字的字數與所述目標文本指令的比值是否超過第二閾值;
而所述文本信息與所述目標文本指令匹配成功的情況則具體包括:
所述目標文本指令的關鍵字均包括在所述文本信息中,或,所述文本信息與所述目標文本指令的相同關鍵字的字數超過第一閾值,或,所述文本信息與所述目標文本指令的相同關鍵字的字數與所述目標文本指令的比值超過第二閾值。
本實施例同樣提供了一種反饋式智能語音控制方法,如圖4所示,本實施例的反饋式智能語音控制方法包括以下步驟:
步驟201、存儲文本指令及對應的控制指令;
步驟2011、對用戶指紋進行識別,若識別成功,則執行步驟202;
步驟202、采集用戶輸入的語音信息;
步驟203、根據所述語音信息識別用戶的聲紋特征,并判斷識別出的聲紋特征是否與預設聲紋特征匹配,若是,則將所述語音信息轉換為文本信息;
步驟204、判斷是否有與所述文本信息完全相同的文本指令,若否,則對所述文本信息與所述文本指令進行模糊匹配,若與一目標文本指令匹配成功,則輸出與所述目標文本指令對應的目標控制指令,并輸出包括所述目標文本指令的提示語音;
步驟205、根據所述目標控制指令執行操作。
實施例3
本實施例的反饋式智能語音控制系統與實施例1基本相同,主要區別在于:如圖5所示,本實施例的反饋式智能語音控制系統還包括指令增加模塊8、存儲模塊9以及統計模塊10;
在本實施例中,當所述文本信息與所述目標文本指令匹配成功時,所述存儲模塊9還存儲所述文本信息,并且每當成功匹配一次,所述存儲模塊9就存儲一次所述文本信息;
所述統計模塊10則會統計所述文本信息的存儲次數,并在判斷所述存儲次數超過第三閾值時,啟用所述指令增加模塊8;
所述指令增加模塊8則用于將所述文本信息及所述文本信息與所述目標文本指令的對應關系增加至所述本地指令庫中進行存儲。
本實施例的反饋式智能語音控制系統可以對用戶的發音習慣、說話習慣等進行歸納總結,從而生成全新的、符合用戶習慣的文本指令。同樣以實施例1中的應用實例為例,如果所述本地指令庫中存儲的正確文本指令為“開燈”,但由于用戶說話喜歡用敬詞,因此,每次用戶想要開燈時輸入的語音信息都是“請開燈吧”,這樣,每次所述數據處理模塊3都會對文本信息“請開燈吧”進行模糊匹配并且匹配成功,這樣,在本實施例中,每次匹配成功之后所述存儲模塊9就會存儲一次所述文本信息“請開燈吧”,所述統計模塊10則會統計存儲次數,當存儲次數超過第三閾值時,所述指令增加模塊就會將所述文本信息“請開燈吧”及所述文本信息與所述目標文本指令(即開燈指令)的對應關系增加至所述本地指令庫中進行存儲,由此,原先錯誤的語音指令“請開燈吧”也就變為正確語音指令,當用戶再次輸入語音指令“請開燈吧”以后,就不需要進行模糊匹配,就可以直接控制mcu執行開燈操作。
本實施例還提供了一種智能對話裝置,其包括本實施例所述的反饋式智能語音控制系統,其中,優選地,所述智能對話裝置可以為故事機或點讀機,在本實施例中,通過用戶語音控制故事機或點讀機播放相應的音視頻數據的實現原理與本實施例的反饋式智能語音控制系統完全相同,在此就不再贅述。
本實施例同樣提供了一種反饋式智能語音控制方法,如圖6所示,本實施例的反饋式智能語音控制方法包括以下步驟:
步驟301、存儲文本指令及對應的控制指令;
步驟302、采集用戶輸入的語音信息;
步驟303、將所述語音信息轉換為文本信息;
步驟304、判斷是否有與所述文本信息完全相同的文本指令,若否,則對所述文本信息與所述文本指令進行模糊匹配,若與一目標文本指令匹配成功,則輸出與所述目標文本指令對應的目標控制指令;
步驟305、根據所述目標控制指令執行操作;
步驟306、存儲所述文本信息,統計所述文本信息的存儲次數,并在判斷所述存儲次數超過第三閾值時,存儲所述文本信息與所述目標文本指令的對應關系。
實施例4
本實施例的反饋式智能語音控制系統與實施例1基本相同,主要區別在于:如圖7所示,本實施例的反饋式智能語音控制系統的語音識別模塊2具體包括:第一預存單元21、字符串轉換單元22、拆分單元23、判斷單元24、文本信息生成單元25;
其中,所述第一預存單元21用于預存多個目標詞組及與每個目標詞組對應的同類詞組和近義詞組;
所述字符串轉換單元22用于將所述語音信息轉換為字符串;
所述拆分單元23用于將所述字符串拆分為若干詞組;
所述判斷單元24用于判斷拆分出的詞組是否包括存儲在所述第一預存單元中的目標詞組,并在判斷為是時,獲取與所述拆分出的詞組中的目標詞組對應的同類詞組和近義詞組;
所述文本信息生成單元25用于對所述拆分出的詞組中的非目標詞組與目標詞組或目標詞組對應的同類詞組和近義詞組進行任意組合,生成多個文本信息,并傳輸至所述數據處理模塊。
本實施例中,所述語音識別模塊可以利用上述各個單元對用戶輸入的語音信息進行更進一步地分析,可以根據用戶輸入的語音信息轉換后的字符串中所包括的目標詞組查詢出相對應的同類詞組和近義詞組,并將其與字符串中的非目標詞組進行任意組合,從而實現了用戶說的一句話,最終可以轉換成多個文本信息,然后對每個文本信息進行匹配,只要其中有一個匹配成功,那么用戶發出的語音信息就可以得到響應,從而提高了語音信息匹配成功的可能性,提升了對用戶輸入語音信息的響應成功率。
下面舉一個本實施例的反饋式智能語音控制系統的語音識別模塊的具體應用實例:
例如,所述第一預存單元中預存有目標詞組“謙讓”,以及與其對應的同類詞組“孔融讓梨”和近義詞組“謙虛”;當用戶輸入語音信息“我想聽一個關于謙讓的故事”時,所述字符串轉換單元會將其轉換為字符串“我想聽一個關于謙讓的故事”,然后所述拆分單元會將其依次拆分為若干詞組,例如拆分為“我”、“想聽”、“一個”、“關于”、“謙讓”、“的”、“故事”,其中將字符串拆分為詞組已經屬于本領域比較成熟的現有技術,在此就不再贅述;這樣,所述判斷單元會判斷拆分出的詞組是否包括存儲在預存單元中的目標詞組,經判斷,發現詞組“謙讓”屬于目標詞組,然后就獲取與“謙讓”相對應的同類詞組“孔融讓梨”和近義詞組“謙虛”;接著所述文本信息生成單元就可以對所述拆分出的詞組中的非目標詞組(即包括:“我”、“想聽”、“一個”、“關于”、“的”、“故事”)與目標詞組或目標詞組對應的同類詞組和近義詞組(即包括“謙讓”、“孔融讓梨”、“謙虛”)進行任意組合,生成多個文本信息,當然,優選地,在組合時,各個詞組的初始順序保持不變,這樣,最終會生成三個文本信息:
文本信息一:我想聽一個關于謙讓的故事;
文本信息二:我想聽一個關于孔融讓梨的故事;
文本信息三:我想聽一個關于謙虛的故事;
然后將這三個文本信息傳輸至所述數據處理模塊,所述數據處理模塊會對上述三個文本信息分別進行匹配,而假設本實施例的反饋式智能語音控制系統運行在故事機中,其中故事機中存儲有文本指令“孔融讓梨”和對應的控制指令“語音播放孔融讓梨的故事”,這樣,文本信息二會最終與文本指令“孔融讓梨”匹配成功,從而觸發故事機播放孔融讓梨的故事。
本實施例還提供了一種反饋式智能語音控制方法,其基本步驟與實施例1的反饋式智能語音控制方法基本相同,主要區別在于,如圖8所示,本實施例的反饋式智能語音控制方法的步驟103具體包括:
步驟10311、預存多個目標詞組及與每個目標詞組對應的同類詞組和近義詞組;
步驟10312、將所述語音信息轉換為字符串;
步驟10313、將所述字符串拆分為若干詞組;
步驟10314、判斷拆分出的詞組是否包括存儲在所述預存單元中的目標詞組,并在判斷為是時,獲取與所述拆分出的詞組中的目標詞組對應的同類詞組和近義詞組;
步驟10315、對所述拆分出的詞組中的非目標詞組與目標詞組或目標詞組對應的同類詞組和近義詞組進行任意組合,生成多個文本信息。
實施例5
本實施例的反饋式智能語音控制系統與實施例1基本相同,主要區別在于:如圖9所示,本實施例的反饋式智能語音控制系統的語音識別模塊2具體包括:第二預存單元26、語言轉換單元27以及文本轉換單元28;
其中,所述第二預存單元26用于預存不同種類的特殊語言的語音信息與一標準語言的語音信息的對應關系;
所述語言轉換單元27用于在識別出用戶輸入的語音信息為特殊語言的語音信息時,將特殊語言的語音信息轉換為對應的標準語言的語音信息;
所述文本轉換單元28用于將所述對應的標準語言的語音信息轉換為文本信息,并傳輸至所述數據處理模塊。
在本實施例中,所謂的特殊語言具體可指方言,不同種類的特殊語言即表示不同地區的方言,而所述的標準語言即是指普通話,即本實施例的所述第二預存單元預存有不同的方言的語音信息與普通話的語音信息的對應關系,例如對于同一個語音信息“吃飯”,不同地方的方言所對應的的語音是不同的,而不同的表示“吃飯”的方言均預存在所述第二預存單元中,與標準的普通話語音“吃飯”相對應;
所述語言轉換單元則是在識別出用戶輸入的語音信息是方言時,將其轉換為普通話的語音信息;然后所述文本轉換單元將普通話的語音信息轉換為文本信息,并傳輸至所述數據處理模塊進行匹配;
本實施例的語音識別模塊實現了識別不同地區的用戶輸入語音信息時的方言,并將方言表達的語音信息轉換為普通話對應的標準語音信息進行處理,從而本實施例拓展了能夠處理的語音的種類,提升了用戶的使用體驗。
下面舉一個本實施例的反饋式智能語音控制系統的語音識別模塊的具體應用實例:
例如,所述第一預存單元中預存有不同種類的方言表達“我想聽關于吃飯的相聲”的語音信息,以及普通話表達“我想聽關于吃飯的相聲”的語音信息;當一個上海人用上海話輸入“我想聽關于吃飯的相聲”時,所述語言轉換模塊能夠識別出表達“我想聽關于吃飯的相聲”的語音信息為上海話,并將其轉換為普通話表達的“我想聽關于吃飯的相聲”的語音信息,然后所述文本轉換單元就可以將普通話表達的“我想聽關于吃飯的相聲”的語音信息轉換為文本信息“我想聽關于吃飯的相聲”,并傳輸至所述數據處理模塊進行匹配,而假設本實施例的反饋式智能語音控制系統運行在故事機中,其中故事機中存儲有文本指令“我想聽關于吃飯的相聲”和控制指令“播放一段關于吃飯的相聲”,從而用戶用上海話說出的語音信息“我想聽關于吃飯的相聲”就能夠被成功識別和響應,最終控制故事機播放一段關于吃飯的相聲,從而能夠對用方言發出指令的用戶進行正確的響應。
本實施例還提供了一種反饋式智能語音控制方法,其基本步驟與實施例1的反饋式智能語音控制方法基本相同,主要區別在于,如圖10所示,本實施例的反饋式智能語音控制方法的步驟103具體包括:
步驟10321、預存不同種類的特殊語言的語音信息與一標準語言的語音信息的對應關系;
步驟10322、在識別出用戶輸入的語音信息為特殊語言的語音信息時,將特殊語言的語音信息轉換為對應的標準語言的語音信息;
步驟10323、將所述對應的標準語言的語音信息轉換為文本信息,并傳輸至所述數據處理模塊。
實施例6
本實施例的反饋式智能語音控制系統與實施例1基本相同,主要區別在于:在所述本地指令庫中,同一個控制指令對應多個文本指令,不同的文本指令用于表征不同的用戶表達習慣;本實施例實現了將不同用戶關于同一個控制指令的多個不同的文本指令統一存儲起來,并均與同一個控制指令相對應,這樣,對于具有不同表達習慣的用戶,本實施例的反饋式智能語音控制系統均能夠對其進行正確響應和反饋。
例如,對于同一個控制指令“開燈”,不同用戶可能會有不同的表達習慣,例如包括“開燈”、“光亮一點”、“提高照明度”等等,本實施例的本地指令庫中會將這些不同的表達習慣的文本指令均與同一個控制指令“開燈”進行對應;這樣,無論是哪個表達習慣的用戶,只要其輸入的語音信息轉換為文本信息之后,能夠與本地指令庫中的某一個表征用戶特俗表達習慣的文本指令成功匹配,都能夠實現最終執行用戶想要的控制指令。
本實施例還提供了一種反饋式智能語音控制方法,其基本步驟與實施例1的反饋式智能語音控制方法基本相同,主要區別在于,在本實施例的步驟101中,同一個控制指令對應多個文本指令,不同的文本指令用于表征不同的用戶表達習慣。雖然以上描述了本發明的具體實施方式,但是本領域的技術人員應當理解,這些僅是舉例說明,本發明的保護范圍是由所附權利要求書限定的。本領域的技術人員在不背離本發明的原理和實質的前提下,可以對這些實施方式做出多種變更或修改,但這些變更和修改均落入本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!