圖像生成方法及其裝置與流程
本公開涉及圖像處理及人工智能等領域,尤其涉及一種圖像生成方法及其裝置。
背景技術:
1、相關技術中,可以通過ai(artificial?intelligence,人工智能)繪圖工具基于提示信息生成對應的圖像。例如,midjourney作為當今最流行的ai圖像生成器之一,屬于生成對抗網絡(generative?adversarial?networks,gan)類深度學習模型為基礎的ai繪畫工具,核心技術是文字生成圖像(text-to-image)。用戶需要輸入文字描述,midjourney就能夠將這些語義信息轉換為視覺元素,生成各種類型的圖像,同時可以針對生成結果持續(xù)修改prompt(提示)再生成直到調整到符合預期的效果。
2、但是,相關技術中的ai繪圖工具(如midjourney)的使用門檻較高。例如,midjourney需要使用者對于繪畫技巧、顏色搭配等素養(yǎng)有一定的要求,且生成后的效果可控性不高,需要多次調整prompt以提升效果,導致難以快速準確地獲得符合預期的圖像。另外,相關技術中的ai繪圖工具在人像效果、攝影風格創(chuàng)作中,容易生成離奇的真實性有偏差的效果。
技術實現思路
1、本公開提供一種圖像生成方法及其裝置。
2、根據本公開實施例的第一方面,提供一種圖像生成方法,包括:
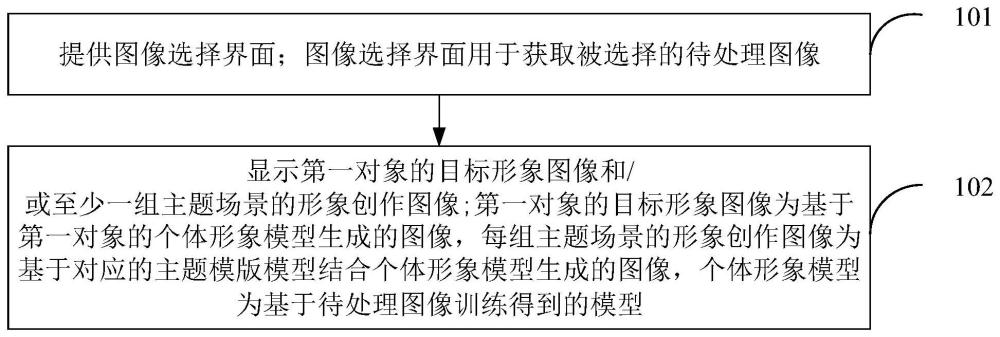
3、提供圖像選擇界面;所述圖像選擇界面用于獲取被選擇的待處理圖像;
4、顯示第一對象的目標形象圖像和/或至少一組主題場景的形象創(chuàng)作圖像;所述第一對象的目標形象圖像為基于所述第一對象的個體形象模型生成的圖像,每組所述主題場景的形象創(chuàng)作圖像為基于對應的主題模版模型結合所述個體形象模型生成的圖像,所述個體形象模型為基于所述待處理圖像訓練得到的模型。
5、結合第一方面的一些實施例,在一些實施例中,該方法還包括:對獲取到的所述待處理圖像進行人臉檢測,從所述待處理圖像中篩選出所述第一對象的圖像;對所述第一對象的圖像進行圖像處理,獲得所述個體形象模型的圖像樣本;基于所述圖像樣本,生成所述第一對象的個體形象模型。
6、結合第一方面的一些實施例,在一些實施例中,所述基于所述圖像樣本,生成所述第一對象的個體形象模型,包括:對所述圖像樣本進行推理,得到所述圖像樣本的描述信息;在所述圖像樣本中添加參考噪聲,得到第一混合噪聲圖像;將所述描述信息和所述第一混合噪聲圖像輸入至預設的擴展模型,獲得所述擴展模型輸出的預測噪聲;根據所述預測噪聲與所述參考噪聲的損失函數,調整所述擴展模型的網絡參數,直至滿足模型訓練結束條件,將訓練好的擴展模型確定為所述第一對象的個體形象模型。
7、結合第一方面的一些實施例,在一些實施例中,所述圖像處理包括以下至少一項:人臉占比檢測處理,用于將人臉占比小于或等于第一閾值的圖像進行過濾;質量檢測處理,用于對模糊數值小于或等于第二閾值的圖像進行過濾;遮擋檢測處理,用于對人臉有遮擋的圖像進行過濾;角度檢測處理,用于對人臉姿態(tài)角度滿足第一條件的圖像進行過濾;人體檢測處理,用于對包含多個人體的圖像進行過濾。
8、結合第一方面的一些實施例,在一些實施例中,該方法還包括:從所述第一對象的圖像中獲取一張參考圖像;對所述參考圖像進行推理,得到所述參考圖像的描述信息;在所述參考圖像中添加參考噪聲,得到第二混合噪聲圖像;將所述參考圖像的描述信息和所述第二混合噪聲圖像輸入至所述第一對象的個體形象模型,獲得所述個體形象模型輸出的預測噪聲;根據所述預測噪聲和所述第二混合噪聲圖像,生成所述第一對象的目標形象圖像。
9、結合第一方面的一些實施例,在一些實施例中,該方法還包括:將預設的至少一個主題模版模型分別與所述個體形象模型進行融合處理,獲得至少一個融合模型;根據所述第一對象的圖像和所述至少一個融合模型,生成所述至少一組主題場景的形象創(chuàng)作圖像。
10、結合第一方面的一些實施例,在一些實施例中,該方法還包括:提供主題模版模型選擇界面;所述主題模版模型選擇界面用于獲取被選擇的主題模版模型;根據所述被選擇的主題模版模型,生成對應主題場景的形象創(chuàng)作圖像。
11、結合第一方面的一些實施例,在一些實施例中,該方法還包括:提供輸入界面;所述輸入界面用于獲取輸入的文本描述信息;基于所述文本描述信息和所述第一對象的個體形象模型,生成對應的圖像。
12、根據本公開實施例的第二方面,提供一種圖像生成裝置,包括:
13、第一提供模塊,用于提供圖像選擇界面;所述圖像選擇界面用于獲取被選擇的待處理圖像;
14、顯示模塊,用于顯示第一對象的目標形象圖像和/或至少一組主題場景的形象創(chuàng)作圖像;所述第一對象的目標形象圖像為基于所述第一對象的個體形象模型生成的圖像,每組所述主題場景的形象創(chuàng)作圖像為基于對應的主題模版模型結合所述個體形象模型生成的圖像,所述個體形象模型為基于所述待處理圖像訓練得到的模型。
15、結合第二方面的一些實施例,在一些實施例中,該裝置還可以包括:人臉檢測模塊,用于對獲取到的待處理圖像進行人臉檢測,從待處理圖像中篩選出第一對象的圖像;圖像處理模塊,用于對第一對象的圖像進行圖像處理,獲得個體形象模型的圖像樣本;第一生成模塊,用于基于圖像樣本,生成第一對象的個體形象模型。
16、結合第二方面的一些實施例,在一些實施例中,第一生成模塊具體用于:對圖像樣本進行推理,得到圖像樣本的描述信息;在圖像樣本中添加參考噪聲,得到第一混合噪聲圖像;將描述信息和第一混合噪聲圖像輸入至預設的擴展模型,獲得擴展模型輸出的預測噪聲;根據預測噪聲與參考噪聲的損失函數,調整擴展模型的網絡參數,直至滿足模型訓練結束條件,將訓練好的擴展模型確定為第一對象的個體形象模型。
17、結合第二方面的一些實施例,在一些實施例中,圖像處理包括以下至少一項:人臉占比檢測處理,用于將人臉占比小于或等于第一閾值的圖像進行過濾;質量檢測處理,用于對模糊數值小于或等于第二閾值的圖像進行過濾;遮擋檢測處理,用于對人臉有遮擋的圖像進行過濾;角度檢測處理,用于對人臉姿態(tài)角度滿足第一條件的圖像進行過濾;人體檢測處理,用于對包含多個人體的圖像進行過濾。
18、結合第二方面的一些實施例,在一些實施例中,該裝置還可以包括:第一獲取模塊,用于從第一對象的圖像中獲取一張參考圖像;推理模塊,用于對參考圖像進行推理,得到參考圖像的描述信息;添加模塊,用于在參考圖像中添加參考噪聲,得到第二混合噪聲圖像;第二獲取模塊,用于將參考圖像的描述信息和第二混合噪聲圖像輸入至第一對象的個體形象模型,獲得個體形象模型輸出的預測噪聲;第二生成模塊,用于根據預測噪聲和第二混合噪聲圖像,生成第一對象的目標形象圖像。
19、結合第二方面的一些實施例,在一些實施例中,該裝置還可以包括:融合模塊,用于將預設的至少一個主題模版模型分別與個體形象模型進行融合處理,獲得至少一個融合模型;第三生成模塊,用于根據第一對象的圖像和至少一個融合模型,生成至少一組主題場景的形象創(chuàng)作圖像。
20、結合第二方面的一些實施例,在一些實施例中,該裝置還可以包括:第二提供模塊,用于提供主題模版模型選擇界面;主題模版模型選擇界面用于獲取被選擇的主題模版模型;第四生成模塊,用于根據被選擇的主題模版模型,生成對應主題場景的形象創(chuàng)作圖像。
21、結合第二方面的一些實施例,在一些實施例中,該裝置還可以包括:第三提供模塊,用于提供輸入界面;輸入界面用于獲取輸入的文本描述信息;第五生成模塊,用于基于文本描述信息和第一對象的個體形象模型,生成對應的圖像。
22、根據本公開實施例的第三方面,提供一種電子設備,包括:
23、處理器;
24、用于存儲處理器可執(zhí)行指令的存儲器;其中,所述指令被所述處理器執(zhí)行,以使所述處理器能夠執(zhí)行上述第一方面所述的方法。
25、根據本公開實施例的第四方面,提供一種可讀存儲介質,當所述存儲介質中的指令由電子設備的處理器執(zhí)行時,使得所述電子設備能夠執(zhí)行上述第一方面所述的方法。
26、根據本公開實施例的第五方面,提供一種計算機程序產品,包括計算機程序,所述計算機程序在被電子設備的處理器執(zhí)行時實現如前述第一方面所述的方法。
27、本公開的實施例提供的技術方案可以包括以下有益效果:
28、通過提供圖像選擇界面,可以使得用戶提供該圖像選擇界面可以選擇用于形象創(chuàng)作的待處理圖像,便于電子設備可以基于該被選擇的待處理圖像生成第一對象的個人形象模型,基于該個人形象模型可以生成該第一對象的目標形象圖像,還可以基于該第一對象的個人形象模型結合主題模版模型生成主題場景的形象創(chuàng)作圖像,在得到第一對象的目標形象和主題場景的形象創(chuàng)作圖像,可以將生成的第一對象的目標形象和/或主題場景的形象創(chuàng)作圖像進行顯示。在整個過程中,無需用戶進行過多操作,對于用戶而言操作簡單,使用門檻較低,可以使得用戶可以快速獲得目標形象圖像及其形象創(chuàng)作圖像。另外,本公開實施例通過采用個性化的個體形象模型生成對應的目標形象圖像以及形象創(chuàng)作圖像,可以提高真人寫真效果的穩(wěn)定性和質量。
29、應當理解的是,以上的一般描述和后文的細節(jié)描述僅是示例性和解釋性的,并不能限制本公開。
- 還沒有人留言評論。精彩留言會獲得點贊!