一種基于數據分解與深度學習的工作面異常來壓預測方法與流程
本發明涉及煤礦回采工作面頂板異常來壓預測領域,尤其涉及一種基于數據分解與深度學習的工作面異常來壓預測方法。
背景技術:
1、煤礦開采往往面臨復雜的地質條件,回采工作面受見方破斷、條帶破碎區、上部采空區、遺留煤柱影響,煤層進入采動影響區域時,受特殊的煤巖賦存條件與重復開采擾動突發異常來壓的影響,回采工作面液壓支架存在壓架隱患。工作面液壓支架工作阻力在線監測系統可以實時分析來壓情況,但無法預測未來的來壓情況,現場工作人員無法提前做出相應準備措施。
技術實現思路
1、發明目的:本發明的目的是提供一種降低數據序列非平穩性和提高預測準確性的基于數據分解與深度學習的工作面異常來壓預測方法。
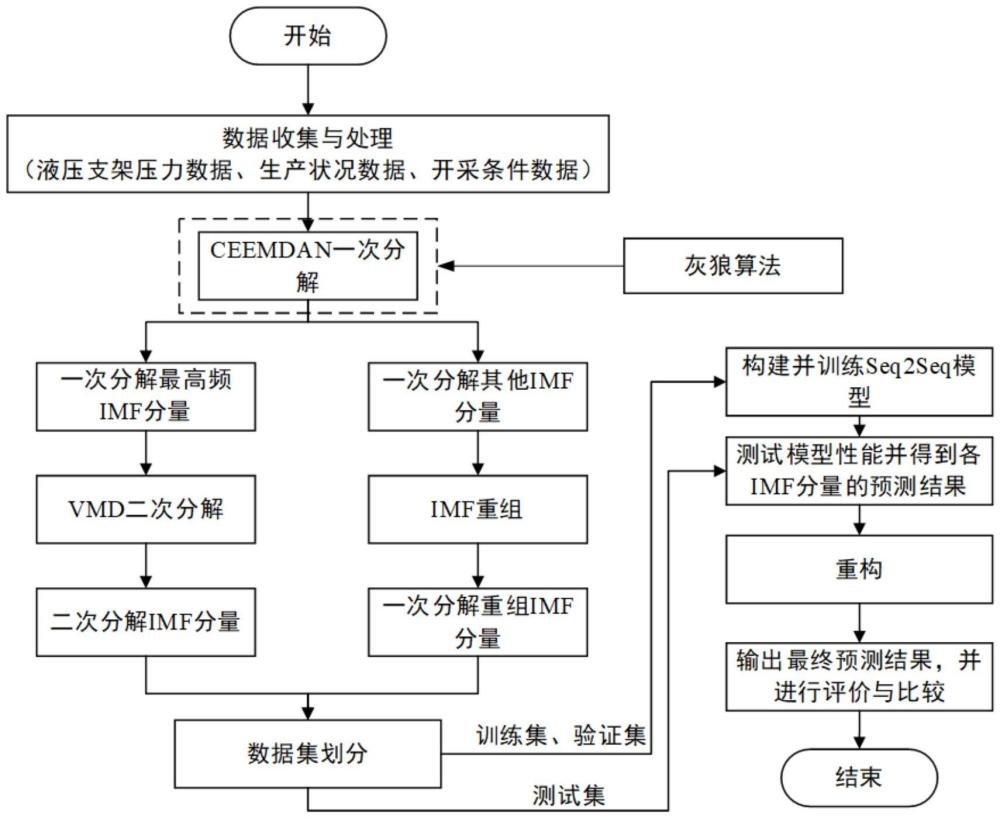
2、技術方案:一種基于數據分解與深度學習的工作面異常來壓預測方法,包括以下步驟:
3、(1)獲取煤礦回采工作面液壓支架工況、生產狀況、開采條件,對上述數據進行缺失值補全、異常值處理,得到工作阻力數據序列;
4、(2)基于步驟(1)獲取的回采工作面液壓支架工作阻力數據序列,采用ceemdan-vmd分解算法將回采工作面液壓支架工作阻力數據序列分解重組為一組imf分量,作為回采工作面液壓支架壓力子序列,使用灰狼算法優化vmd算法的分解數量和懲罰因子;
5、(3)基于步驟(1)得到的回采工作面液壓支架工況、生產狀況、開采條件以及步驟(2)得到的一組imf分量,將上述數據和imf分量分割為訓練集、驗證集和測試集;
6、(4)分別為一組imf分量中每一個子imf分量構建seq2seq模型,使用訓練數據對seq2seq模型進行訓練、測試,得到預測結果;
7、(5)將各子imf分量的預測結果重組得到最終的預測結果,實現煤礦回采工作面液壓支架壓力數據的預測;
8、(6)將seq2seq模型得到的煤礦回采工作面液壓支架壓力數據的預測值進行聚類分析,得到來壓類型。
9、進一步地,所述煤礦回采工作面液壓支架工況包括回采工作面中部液壓支架平均工作阻力、時間加權阻力、初撐力、末阻力、初始增壓階段增阻速率、相對穩定承載階段增阻速率、移架前增壓階段增阻速率、安全閥開啟次數;
10、所述生產狀況包括液壓支架推進距離、循環時間;
11、所述開采條件包括本工作面見方破斷位置、上區段工作面見方破斷位置、條帶破碎區范圍、距離工作面上方采空區遺留煤柱距離、遺留煤柱尺寸范圍、層間距、上方工作面停采時間。
12、進一步地,對獲取的數據進行缺失值補全、異常值處理包括以下步驟:
13、(31)采用基于時間序列特性的插值方法,對原始數據集中的缺失值進行補全,保證數據的時序連續性和一致性;
14、(32)采用異常值監測算法,對補全數據進行識別并標記數據集中的潛在異常值;
15、(33)對于監測到的異常值,進行剔除、替換或修正;
16、(34)對經過缺失值補全和異常值處理后的數據序列,再應用ceemdam-vmd分解算法分解為imf分量。
17、進一步地,所述ceemdan分解算法計算包括以下步驟:
18、(411)對回采工作面液壓支架工作阻力數據序列中的原序列y(t)加上自適應標準正態分布白噪聲yi(t)=y(t)+εoωi(t),i=1,2,…n,其中,yi(t)是在原序列加上自適應標準正態分布白噪聲后的序列,ε0是信噪比,n表示加入白噪聲的次數,ωi(t)為白噪聲序列;
19、(412)對yi(t)執行emd分解直到得到ceemdan的第一個模態分量其中,表示對yi(t)進行第i次emd分解得到的第一個模態分量,計算第一殘差序列
20、(413)使用emd分解序列r1(t)+ωi(t)獲得ceemdan的第二個模態分量其中,e1()表示對括號內的序列進行emd分解得到的第一個模態分量;
21、(414)對于后續的階段k=2,…,n,計算第k個殘差序列重復步驟(413)的計算過程,ceemdan的第k個模態分量
22、(415)重復步驟(414),確保殘差序列不能進一步分解,最終得到k個模態分量,分解的最終殘差信號其中,k代表imf分量數;因此,原序列
23、所述vmd算法計算包括以下步驟:
24、(421)構造變分問題;設原始序列y(t)被分解為l個分量ul(t),l=1,2,...,m,保證分解序列為具有中心頻率ρl的有限帶寬的模態分量,同時各模態的估計帶寬之和最小,約束條件為所有模態之和與原始序列相等,則相應約束變分表達式為:其中,表示最小化以ul,ρl為變量的函數的值;表示對t求偏導數;δ(t)表示狄拉克分布;c表示虛數;ul(t)表示分解得到的第l個分量;
25、(422)求解約束變分表達式;引入懲罰參數α、lagrange乘子λ,將約束變分問題轉變為非約束變分問題,得到增廣lagrange表達式為:
26、
27、(423)求解步驟(422)中增廣lagrange表達式的鞍點;初始化參數ul,ρ2,λ(i)以及迭代次數n,n初值設為0,設置循環過程,令n=n+1,ul,ρ1,λ(t)根據下式更新:
28、
29、
30、
31、其中,分別表示uln+1(t)、y(t)、λ(t)的傅里葉變換,表示第n+1次迭代中第l個分量的中心頻率;γ表示噪聲容忍度;
32、(424)當分量滿足公式時,求解完畢;其中,ζ表示精度收斂判據。
33、進一步地,所述步驟(3)為增加樣本數量,采用滑動窗口法構建樣本,將臨近工作面的imf分量、回采工作面液壓支架工況、生產狀況、開采條件作為輸入,將本工作面的imf分量作為標簽,seq2seq模型的輸入向量x和輸出向量y如下:
34、x=(x1,x2,…,xq)
35、y=(y1,y2,…,yq)
36、xq=(xq,xq+1,…,xn′)
37、yq=(xn′+1),q為樣本總數;n′為樣本數據量,xq,yq分別為第q個樣本的輸入和輸出q=1,2,…,q。
38、進一步地,所述步驟(3)中數據分割包括以下特征:
39、數據分割比例,根據數據的縱梁和模型的復雜度,確定訓練集、驗證集和測試集的比例;
40、時間序列的連續性,考慮到數據的時間序列特性,數據分割采用時間連續的方式進行,確保訓練集、驗證集和測試集中的數據點按時間順序排列;
41、交叉驗證方法,采用時間序列交叉驗證方法,將數據分割成多個訓練或測試對;
42、確保數據代表性,在分割數據時,確保每個訓練集、驗證集、測試集都能夠代表整個數據集的特性,在處理高度不平衡的數據時,采用分層抽樣。
43、進一步地,所述步驟(4)中構建seq2seq模型包括以下步驟:
44、(71)將樣本(xq,yq)輸入seq2seq模型中,seq2seq模型的編碼器由單層lstm單元組成,將輸入序列按照時間順序分步讀入,每一時刻的隱藏層狀態hq都由當前時刻的輸入數據xq與上一時刻的隱藏層狀態hq-1和細胞狀態cq-1共同決定,hq=f(xq,hq-1,cq-1),hq,hq-1分別為q時刻、q-1時刻編碼層的lstm神經元隱藏層狀態,xq為q時刻的輸入,cq-1為q-1時刻編碼層的lstm神經元細胞狀態;
45、(72)lstm單元內部由輸入門、遺忘門和輸出門組成,lstm單元內部計算流程如下:
46、(721)遺忘門決定舍棄多少細胞狀態sq-1:fq=σ(wf(hq-1,xq)+bf);
47、(722)輸入門決定保留多少當前外部輸入數據xq,并生成候選細胞狀態cq:vq=σ(wv(hq-1,xq)+bv)
48、
49、(723)輸出門決定輸出細胞狀態cq的哪些特征,并生成隱藏層狀態hq:oq=σ(w0(hq-1,xq)+b0)
50、hq=oqtanhcq,式中,wf,wv,wc,wo分別為遺忘門、輸入門、輸出門和門控單元的權重向量;bf,bv,bc,bo分別為遺忘門、輸入門、輸出門和門控單元的偏置向量,fq,vq,,oq均為模型的中間參數,σ(·)為sigmoid激活函數,tanh(·)為雙曲正切激活函數;
51、(73)編碼器經過g個時間步的更新,輸入數據被編碼為最終時間步的隱藏層狀態hg,解碼器由單層lstm單元組成,接受編碼器的最終狀態hg作為初始輸入值;解碼器每一時刻隱藏層狀態h′q通過當前時刻的輸入hg與上一時刻的隱藏層狀態h′q-1和細胞狀態c′q-1更新,其表達式如下:h′q=f(hg,h′q-1,c′q-1),h′q,h′q-1分別代表q時刻、q-1時刻解碼層的lstm神經元隱藏層狀態,c′q-1為q-1時刻解碼層的lstm神經元的細胞狀態;
52、(74)解碼層更新h′q-1的具體操作與編碼層更新hq一致,隱藏狀態h′q經全連接層的學習輸出為yq=f(hq),yq為q時刻的輸出,經過分步解碼,形成最終的輸出序列。
53、進一步地,所述灰狼算法的計算步驟包括:
54、(81)參數定義,確定vmd分解過程中的關鍵參數—分解數量k和懲罰因子α作為優化目標;
55、(82)初始化灰狼群體,在合理的參數范圍內隨機初始化一群灰狼,每個個體代表一組可能的k和α的配置;
56、(83)適應度評價,通過定義一個適應度函數來評估每個個體的性能,該適應度函數為基于vmd分解后的imf分量和原始數據序列的重構誤差;
57、(84)社會等級更新,根據適應度評估結果,確定alpha、beta、delta狼,代表當前找到的最佳參數配置,然后,更新種群中其他個體的參數配置,探索最優解;
58、(85)迭代優化,重復執行適應度評價和狼群位置更新步驟,直至滿足終止條件;
59、(86)通過灰狼算法找到的最優k和α值,對原始的回采工作面液壓支架工作阻力數據序列進行vmd分解,以獲取最終的imf分量。
60、進一步地,所述來壓類型根據預測結果歸類為見方形成異常來壓、條帶破碎區形成異常來壓、過采空區形成異常來壓、過遺留煤柱形成異常來壓。
61、本發明與現有技術相比,其顯著效果如下:本發明使用二次分解方法處理空氣質量數據序列,顯著降低了數據序列的非平穩性;構建了seq2seq模型,將生產狀況數據、開采條件數據作為高維特征加入輸入數據中,提高預測結果的準確性;在煤礦回采過程中,能夠基于液壓支架工作阻力監測數據、工作面開采條件數據預測未來一段時間內液壓支架工作阻力,并對異常來壓進行聚類分析,從而為煤礦調整生產作業計劃以滿足回采工作面安全生產需求,同時提供決策支持。
- 還沒有人留言評論。精彩留言會獲得點贊!