一種基于文本語義解讀的配電網(wǎng)項目可研報告分析方法與流程
本發(fā)明涉及文本數(shù)據(jù)處理,具體涉及一種基于文本語義解讀的配電網(wǎng)項目可研報告分析方法。
背景技術:
1、配電網(wǎng)項目可研報告是對擬建設的配電網(wǎng)項目進行全面分析和評估的文件,將文件進行評估是為了論證項目的必要性、技術可行性和經(jīng)濟合理性;目前配電網(wǎng)項目可研報告分析主要依托評審標準進行人工評價,導致整個分析和評價容易受主觀因素影響。考慮其主觀因素導致的差異主要是評審標準通常語義有限,在不同人員對同一報告的解讀可能存在差異的情況下,難以快速識別和建立不同信息之間的關聯(lián)關系,從而導致分析結(jié)果差異較大。其次,當出現(xiàn)大量報告需要評價時,很容易導致報告的解讀耗時耗力,甚至可能因為不同人員撰寫的報告的結(jié)構或格式不一致,直接影響后續(xù)分析和決策。甚至在項目過程中發(fā)現(xiàn)出現(xiàn)問題時,也很難快速追溯某個結(jié)論或決策的依據(jù)。因此,需要改善文本語義的解讀差異,確保提取信息和解讀信息的準確性和一致性。
2、更為重要的是,隨著項目的多樣化,通常需要將一個成功項目的優(yōu)秀示例進行借鑒,傳統(tǒng)的可研報告分析通常局限于某幾個維度,導致不同文件的信息無法有效關聯(lián),從而難以將一個項目的經(jīng)驗快速應用到其他類似項目中。
3、因此,如何協(xié)助項目進行分析,通過計算機系統(tǒng)對文本進行處理,改善信息提取的差異化現(xiàn)象,在大量報告時,建立不同文件的信息關聯(lián)性,是值得研究的。
技術實現(xiàn)思路
1、本發(fā)明的目的在于提供一種基于文本語義解讀的配電網(wǎng)項目可研報告分析方法,期望改善傳統(tǒng)分析方法在信息提取的準確性和一致性、信息關聯(lián)性分析、大量報告處理效率等方面存在明顯缺陷問題。
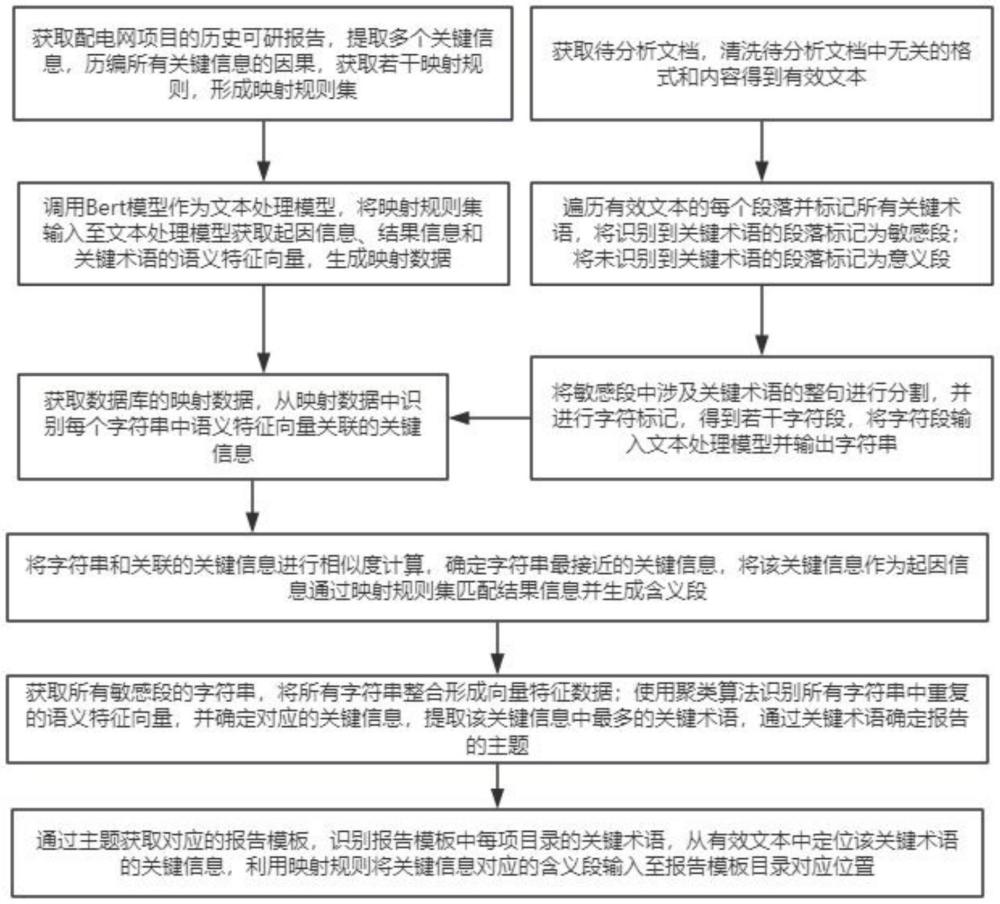
2、為解決上述的技術問題,本發(fā)明采用以下技術方案:一種基于文本語義解讀的配電網(wǎng)項目可研報告分析方法,包括如下步驟:s100,獲取配電網(wǎng)項目的歷史可研報告,提取歷史可研報告中多個關鍵信息,每個關鍵信息中至少包含一個關鍵術語;歷編所有關鍵信息,將任意一個關鍵信息作為起因信息,獲取與該關鍵信息產(chǎn)生映射的關鍵信息作為結(jié)果信息,將因信息與結(jié)果信息形成一項映射規(guī)則;獲取若干映射規(guī)則,形成映射規(guī)則集;其中,關鍵信息為對項目決策和評估具有重要影響的具有含義的語句或段落;其中,關鍵術語為描述或量化關鍵信息的專業(yè)術語和技術指標的詞語。
3、s200,調(diào)用bert模型作為文本處理模型,將映射規(guī)則集輸入至文本處理模型獲取起因信息、結(jié)果信息和關鍵術語的語義特征向量;通過語義特征向量生成對應映射規(guī)則集的映射數(shù)據(jù)并儲存至數(shù)據(jù)庫;其中,映射數(shù)據(jù)包含關鍵術語的語義特征向量,以及起因信息與結(jié)果信息之間的語義特征向量關系;其中,上述關鍵術語的語義特征向量包含關鍵術語出現(xiàn)起始和結(jié)束的索引。
4、s300,獲取待分析文檔;將待分析文檔轉(zhuǎn)換成統(tǒng)一的文本格式;清洗待分析文檔中無關的格式和內(nèi)容得到有效文本,將有效文本執(zhí)行如下步驟:s301,遍歷有效文本的每個段落并標記所有關鍵術語;將識別到關鍵術語的段落標記為敏感段;將未識別到關鍵術語的段落標記為意義段。s302,將敏感段中涉及關鍵術語的整句進行分割,并進行字符標記,得到若干字符段。s303,將字符段輸入文本處理模型并輸出字符串,獲取數(shù)據(jù)庫的映射數(shù)據(jù),從映射數(shù)據(jù)中識別每個字符串中語義特征向量關聯(lián)的關鍵信息,其中,字符串包含關鍵術語的語義特征向量。s304,將字符串和關聯(lián)的關鍵信息進行相似度計算,確定字符串最接近的關鍵信息,將該關鍵信息作為起因信息通過映射規(guī)則集匹配結(jié)果信息并生成含義段。
5、s400,獲取所有敏感段的字符串,將所有字符串整合形成向量特征數(shù)據(jù);使用聚類算法識別所有字符串中重復的語義特征向量,并確定對應的關鍵信息,提取該關鍵信息中最多的關鍵術語,通過關鍵術語確定報告的主題。
6、s500,通過主題獲取對應的報告模板,識別報告模板中每項目錄的關鍵術語,從有效文本中定位該關鍵術語的關鍵信息,利用映射規(guī)則將關鍵信息對應的含義段輸入至報告模板目錄對應位置。
7、作為優(yōu)選,執(zhí)行s100中,收集歷史可研報告中關鍵術語,確定關鍵術語之間的關聯(lián)性,創(chuàng)建關鍵詞庫,將關鍵詞庫中的具有關聯(lián)性的關鍵術語設置運算符指令;當識別到關鍵詞庫的關鍵術語時,通過運算符指令將關聯(lián)性的關鍵詞調(diào)整為一致的關鍵術語。
8、作為優(yōu)選,執(zhí)行s304時,字符串和關鍵信息進行相似度的具體步驟是:
9、步驟一,獲取字符串的語義特征向量。
10、步驟二,獲取與字符串關聯(lián)的關鍵信息的語義特征向量。
11、步驟三,計算字符串與任意一個關鍵信息的相似度,其相似度s的計算公式是:
12、
13、式中,vi為字符串在語義向量中的第i個分量上的值;mi為關鍵信息在語義向量中的第i個分量上的值;為字符串和關鍵信息的點積,為字符串向量的歐幾里得范數(shù),為關鍵信息的歐幾里得范數(shù)。
14、步驟四,預設相似閾值r,將相似度s的值與相似閾值r進行比較;其中,s<r時,則字符串與對應的關鍵信息關聯(lián)錯誤;選擇其他關鍵信息進行重復步驟a;其中,s≥r時,則字符串與對應的關鍵信息關聯(lián)正確,記錄該關鍵信息,并執(zhí)行步驟e。
15、步驟五,確認字符串與所關聯(lián)的關鍵信息均完成相似度計算,選取相似度s中值最高的關鍵信息作為對應字符串最接近的關鍵信息。
16、作為優(yōu)選,執(zhí)行s400時,上述聚類算法采用k-means聚類算法,聚類算法識別向量特征數(shù)據(jù)包括如下步驟:s401,從有效文本中獲取所有字符串;獲取所有字符串對應的語義特征向量;s402,設置聚類的類別并建立類別對應的聚類中心;將分配字符串選擇最接近的聚類中心進行分配,由聚類中心輸出聚類結(jié)果;s403,識別聚類結(jié)果中的關鍵信息,統(tǒng)計每個關鍵信息中的關鍵術語出現(xiàn)頻率,選擇出現(xiàn)次數(shù)最多的關鍵術語。
17、進一步的技術方案是,每個類別預設權重系數(shù),當識別聚類結(jié)果中的關鍵信息中的關鍵術語并不唯一時,基于預設權重系數(shù),對每個候選關鍵術語進行評分,候選術語中選擇具有最高得分的術語作為關鍵術語。
18、作為優(yōu)選,執(zhí)行步驟s200時,建立處理模型,包括如下步驟:s201,將收集到的10份以上可研報告,調(diào)用bert模型,從transformers庫來加載模型輸入的數(shù)據(jù)格式以及bert分詞器的分詞方式;s202,通過bert模型提取每個關鍵術語的語義特征向量;s203,語義特征向量使用預先定義的分類頭進行分類,確定每個關鍵術語的類別;記錄每個關鍵術語在文本中的起始和結(jié)束位置;s204,將提取到的關鍵信息及其類別和位置信息整合成結(jié)構化的數(shù)據(jù)格式。
19、作為優(yōu)選,基于電力點的分詞誤差較大,可能影響到特征抽取的準確性,還包括創(chuàng)建詞塊庫,調(diào)整bert模型中的編碼器將詞塊進行粒度劃分,使每個詞塊包含一個或多個詞語;使用bert模型對每個詞塊進行編碼生成語義特征向量,使一個或多個詞語采用相同的語義特征向量。
20、作為優(yōu)選,分析方法還包括訓練模型,其步驟如下:s701,獲取關鍵信息之間的關系映射,創(chuàng)建起因信息與結(jié)果信息之間的關聯(lián)關系的映射規(guī)則;s702,確定bert模型輸出的語義特征向量的可行性和準確性;s703,選擇已經(jīng)完成標注的歷史可研報告作為訓練數(shù)據(jù),將訓練數(shù)據(jù)輸入模型,由模型識別并提取關鍵術語和關鍵信息,的語義特征調(diào)用進行標注的歷史報告作為訓練數(shù)據(jù);將訓練數(shù)據(jù)輸入到bert模型進行訓練。
21、進一步的技術方案是,還包括如下步驟:使用交叉驗證的方式進行訓練模型的校驗,其中交叉驗證的方式為k折交叉驗證。
22、作為優(yōu)選,執(zhí)行s300之前,提取歷史可研報告的文本結(jié)構,將可研報告按照設定格式分割段落;提取歷史報告的結(jié)構,識別通用的組成部分,基于報告主題創(chuàng)建報告模板。
23、與現(xiàn)有技術相比,本發(fā)明的有益效果至少是如下之一:
24、本發(fā)明通過明確的關鍵信息和關鍵術語,通過識別歷史文本中的關鍵術語并提取關聯(lián)的關鍵信息建立映射規(guī)則,利用映射規(guī)則自動識別起因信息與結(jié)果信息之間的關系,通過bert模型進行語義特征提取;利用bert模型獲取關鍵術語的語義特征向量,利用語義特征向量與關鍵信息建立映射關系。從而使得文本中的專業(yè)術語和技術指標可以轉(zhuǎn)換為可計算的數(shù)值形式,為后續(xù)的數(shù)據(jù)分析和處理提供支持。
25、本發(fā)明對文本處理時,通過標記文本中的關鍵術語,并為進一步分析識別含有關鍵術語的段落作為敏感內(nèi)容,通過對敏感段落中各個語義特征的向量化處理和聚類分析,識別出報告中的主要主題和核心內(nèi)容,從而有助于專注于報告中的關鍵部分,提高處理效率和精確度。
26、本發(fā)明采用機器學習的方式,逐步優(yōu)化模型,實時適應新的數(shù)據(jù)和需求變化,保持系統(tǒng)的先進性和適應性。
27、本發(fā)明還文本語句采用語義特征向量進行逆向識別;采用這種方式提高關鍵術語的關聯(lián)性分析,提高了模型的理解和處理能力,使模型能更準確地識別和分類關鍵術語,從而保證識別起因信息與結(jié)果信息之間的關系更容易建立通用的和映射規(guī)則,能夠?qū)⒁粋€項目的經(jīng)驗快速遷移和應用到其他項目中,提高整體項目管理和決策的效率。通過將文本轉(zhuǎn)化為結(jié)構化的語義特征量,自動識別文本中高敏的語義特征量,報告主題并生成標準化模板。
- 還沒有人留言評論。精彩留言會獲得點贊!