一種融合惡意詞典與Bert預(yù)訓(xùn)練模型的惡意URL檢測(cè)方法
本發(fā)明屬于信息安全,涉及一種融合惡意詞典與bert預(yù)訓(xùn)練模型的惡意url檢測(cè)方法。
背景技術(shù):
1、惡意url通常用于傳播病毒、釣魚(yú)攻擊、信息竊取等行為,給用戶(hù)和企業(yè)帶來(lái)了巨大的損失。盡管目前已有多種惡意url檢測(cè)技術(shù),但大多數(shù)方法仍存在一定的局限性,未能充分捕捉url文本的復(fù)雜性和與惡意詞語(yǔ)之間的關(guān)系。
2、現(xiàn)有的檢測(cè)技術(shù)大多依賴(lài)于靜態(tài)特征或簡(jiǎn)單的規(guī)則匹配,諸如黑名單、關(guān)鍵字匹配等,然而,這些方法往往無(wú)法應(yīng)對(duì)新型惡意url的變種和偽裝。同時(shí),傳統(tǒng)的機(jī)器學(xué)習(xí)方法在特征提取上往往依賴(lài)人工選擇,導(dǎo)致模型的泛化能力不足,難以適應(yīng)快速變化的惡意攻擊模式。
3、近年來(lái),深度學(xué)習(xí)技術(shù)的應(yīng)用為惡意url檢測(cè)帶來(lái)了新的機(jī)遇。尤其是bert預(yù)訓(xùn)練模型在自然語(yǔ)言處理領(lǐng)域取得的顯著成績(jī),顯示了其在理解上下文信息方面的強(qiáng)大能力。
4、然而,單一依賴(lài)bert模型或惡意詞典的檢測(cè)方法仍存在一定的局限性,無(wú)法全面考慮文本的多維特征。
技術(shù)實(shí)現(xiàn)思路
1、有鑒于此,本發(fā)明的目的在于提供一種融合惡意詞典與bert預(yù)訓(xùn)練模型的惡意url檢測(cè)方法。該方法通過(guò)采集敏感詞、色情詞、暴恐詞、涉詐詞、反動(dòng)詞等構(gòu)建惡意詞典,獲取url頁(yè)面文本數(shù)據(jù)并進(jìn)行預(yù)處理,構(gòu)建文本內(nèi)容數(shù)據(jù)集。在此基礎(chǔ)上,設(shè)計(jì)了一個(gè)融合惡意詞典與bert預(yù)訓(xùn)練模型的文本內(nèi)容檢測(cè)網(wǎng)絡(luò),利用bert預(yù)訓(xùn)練模型對(duì)文本進(jìn)行特征提取,生成包含上下文信息的文本向量,并與惡意值權(quán)重相乘得到惡意加權(quán)向量,加權(quán)向量經(jīng)過(guò)多尺度卷積模塊,提取不同尺度下的特征,并通過(guò)softmax輸出最終預(yù)測(cè)的惡意分類(lèi)結(jié)果。最終實(shí)現(xiàn)對(duì)惡意url的準(zhǔn)確分類(lèi)。
2、為達(dá)到上述目的,本發(fā)明提供如下技術(shù)方案:
3、一種融合惡意詞典與bert預(yù)訓(xùn)練模型的惡意url檢測(cè)方法,該方法包括以下步驟:
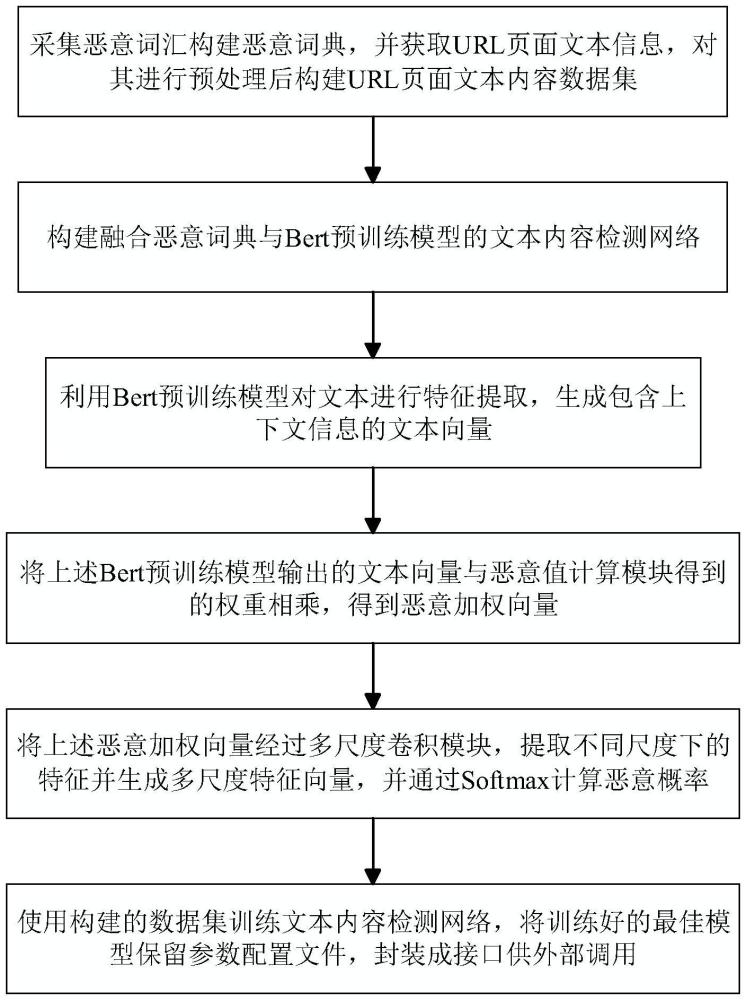
4、s1:采集惡意詞匯構(gòu)建惡意詞典w,并獲取url頁(yè)面文本信息,對(duì)其進(jìn)行預(yù)處理后構(gòu)建url頁(yè)面文本內(nèi)容數(shù)據(jù)集;
5、s2:構(gòu)建融合惡意詞典與bert預(yù)訓(xùn)練模型的文本內(nèi)容檢測(cè)網(wǎng)絡(luò),文本內(nèi)容檢測(cè)網(wǎng)絡(luò)包括輸入層、bert預(yù)訓(xùn)練模型、惡意值計(jì)算模塊、多尺度卷積模塊以及softmax分類(lèi)器;
6、s3:利用bert預(yù)訓(xùn)練模型對(duì)文本進(jìn)行特征提取,生成包含上下文信息的文本向量hl;
7、s4:通過(guò)惡意值計(jì)算模塊得到文本序列的惡意權(quán)重向量,將其與文本向量hl進(jìn)行計(jì)算得到惡意加權(quán)向量h′l;
8、s5:將惡意加權(quán)向量h′l經(jīng)過(guò)多尺度卷積模塊,提取不同尺度下的特征并生成多尺度特征向量m,并通過(guò)softmax計(jì)算惡意概率;
9、s6:使用構(gòu)建的數(shù)據(jù)集訓(xùn)練文本內(nèi)容檢測(cè)網(wǎng)絡(luò),將訓(xùn)練完成后保留參數(shù)配置文件,封裝成接口供外部調(diào)用。
10、進(jìn)一步,在步驟s1中,對(duì)于惡意詞典w,首先收集的惡意詞匯,對(duì)收集的惡意詞匯進(jìn)行處理,形成惡意詞典:
11、w={w1,w2,...,wj,...,wm}
12、其中wj表示第j個(gè)詞語(yǔ),m為惡意詞典中的詞匯總數(shù);
13、對(duì)于url頁(yè)面文本內(nèi)容數(shù)據(jù)集,從公開(kāi)網(wǎng)站中分別獲取惡意和正常url,然后對(duì)獲取的url文本內(nèi)容進(jìn)行預(yù)處理,其中,預(yù)處理操作包括:去掉無(wú)關(guān)詞、去除停用詞、右截?cái)嘁约皹?biāo)注處理,其中,右截?cái)嗍侵笇?duì)長(zhǎng)度不足最大長(zhǎng)度l的語(yǔ)句采用0補(bǔ)齊,對(duì)長(zhǎng)度超過(guò)最大長(zhǎng)度l的語(yǔ)句將l后的字詞截?cái)啵粯?biāo)注是指將惡意url頁(yè)面文本為正類(lèi)1,正常url頁(yè)面文本為負(fù)類(lèi)0;
14、將預(yù)處理后的文本內(nèi)容按照預(yù)設(shè)的惡意和正常url頁(yè)面文本比例以及預(yù)設(shè)的訓(xùn)練集和驗(yàn)證集數(shù)據(jù)量比例劃分為訓(xùn)練集和驗(yàn)證集。
15、進(jìn)一步,在步驟s2中,建立融合惡意詞典與bert預(yù)訓(xùn)練模型的惡意url文本內(nèi)容檢測(cè)網(wǎng)絡(luò),其中,文本內(nèi)容檢測(cè)網(wǎng)絡(luò)包括輸入層、bert預(yù)訓(xùn)練模型、惡意值計(jì)算模塊、多尺度卷積模塊以及softmax分類(lèi)器,輸入層輸入文本內(nèi)容,采用bert預(yù)訓(xùn)練模型對(duì)文本進(jìn)行特征提取,惡意值計(jì)算模塊用于計(jì)算惡意權(quán)重向量,多尺度卷積模塊,提取不同尺度下的特征,并通過(guò)softmax輸出最終預(yù)測(cè)的惡意分類(lèi)結(jié)果。
16、進(jìn)一步,在步驟s3中,bert預(yù)訓(xùn)練模型按照以下步驟對(duì)輸入的文本內(nèi)容進(jìn)行特征提取:
17、s31、將預(yù)處理后的文本進(jìn)行分詞,并在文本的句首使用符號(hào)[cls]進(jìn)行標(biāo)識(shí),句尾使用[sep]進(jìn)行標(biāo)識(shí),得到文本序列t:
18、t={xcls,x1,x2,...,xi,...,xl,xsep}
19、其中文本序列t的長(zhǎng)度為l+2,xi表示文本中第i個(gè)字;
20、s32、文本序列t經(jīng)過(guò)詞向量編碼、句子編碼、位置編碼分別得到詞向量:
21、ewi={ewcls,ew1,ew2,...,ewi,...,ewl,ewsep}
22、句子向量:
23、esi={escls,es1,es2,...,esi,...,esl,essep}
24、位置向量:
25、epi={epcls,ep1,ep2,...,epi,...,epl,epsep}
26、最終bert預(yù)訓(xùn)練模型輸入的向量表示為:ebi=ewi+esi+epi;
27、s33、輸入向量ebi依次傳入多個(gè)編碼層,每個(gè)編碼層均進(jìn)行一次多頭自注意力計(jì)算、層歸一化、殘差連接、全連接層處理,最后生成包含上下文信息的文本向量hl。
28、進(jìn)一步,在步驟s4中,惡意值計(jì)算模塊按照以下步驟計(jì)算惡意權(quán)重向量:
29、s41、惡意值計(jì)算模塊首先將預(yù)處理后的文本數(shù)據(jù)進(jìn)行結(jié)巴分詞,得到待匹配詞集合v和待匹配詞字?jǐn)?shù)集合v′:
30、v={v1,v2,...,vi,...,vn}
31、v′={v′1,v′2,...,v′i,...,v′n}
32、其中vi表示第i個(gè)詞語(yǔ),v′i表示第i個(gè)詞語(yǔ)的字?jǐn)?shù);
33、s42、將待匹配詞和惡意詞典中的惡意詞通過(guò)word2vec模型映射為詞向量計(jì)算待匹配詞與惡意詞之間的相似度,建立惡意詞與待匹配詞之間的映射關(guān)系;惡意詞與待匹配詞相似度計(jì)算公式為:
34、
35、其中,vi表示第i個(gè)詞語(yǔ),wj表示第j個(gè)詞語(yǔ),sim(vi,wj)表示vi與wj之間的詞語(yǔ)相似度;通過(guò)相似度計(jì)算找到惡意詞典中與vi匹配度最高的詞語(yǔ)wj;
36、s43、定義詞惡意值為:
37、
38、其中,wms(vi)代表vi在惡意詞典中的得分,若max_sim(vi)大于等于閾值σ時(shí),則wms(vi)為2v′i;反之,則為v′i;其中v′i表示第i個(gè)詞語(yǔ)的字?jǐn)?shù);
39、將每個(gè)詞的惡意值均分到該詞中的每個(gè)字,字的惡意值表示為:
40、
41、其中,pk表示句子中第k個(gè)字的惡意值,該字屬于詞語(yǔ)vi;句子中每個(gè)字及標(biāo)識(shí)符[cls]、[sep]的惡意值均被計(jì)算,標(biāo)識(shí)符[cls]、[sep]的惡意值默認(rèn)為1;
42、s44、將上述計(jì)算得到的每個(gè)字的惡意值構(gòu)建惡意值向量:
43、p={pcls,p1,p2,...,pk,...,pl,psep}
44、將得到的惡意值向量p進(jìn)行歸一化,得到惡意權(quán)重向量p′,對(duì)于一個(gè)長(zhǎng)度為l的句子,其權(quán)重向量p′中的一項(xiàng)p′k為:
45、
46、最后,將bert預(yù)訓(xùn)練模型輸出的文本向量hl與惡意權(quán)重向量p′相乘得到惡意加權(quán)向量h′l為:
47、h′l=p′hl
48、其中,p′為惡意權(quán)重向量,hl為bert預(yù)訓(xùn)練模型輸出的文本向量。
49、進(jìn)一步,在步驟s5中,多尺度卷積模塊的處理過(guò)程包括:
50、s51、引入通道注意力eca得到通道加權(quán)后的文本向量矩陣h″l;
51、s52、采用不同行維度大小的卷積核對(duì)通道加權(quán)后的文本向量矩陣h″l進(jìn)行卷積,卷積核按滑動(dòng)順序?qū)斎刖渥又械牟糠肿衷~進(jìn)行過(guò)濾并生成特征進(jìn)而得到特征向量ac;
52、s53、通過(guò)多頭自注意力池化保留特征向量中的上下文關(guān)系;
53、s54、將池化后得到的特征向量m通過(guò)全連接層計(jì)算第i個(gè)類(lèi)別的得分zi,從而構(gòu)建得分向量z,最后通過(guò)softmax函數(shù)根據(jù)得分向量z判斷惡意url。
54、進(jìn)一步,在步驟s51中,首先根據(jù)通道數(shù)自適應(yīng)計(jì)算一維卷積的核大小k,核大小k的計(jì)算公式為:
55、
56、其中c表示輸入特征的通道數(shù),γ和β為超參數(shù),|·|odd表示k取奇數(shù);
57、輸入的文本向量矩陣大小為c×l×h;通過(guò)全局平局池化提取全局特征得到1×1×c的向量;進(jìn)行卷積核大小為k的一維卷積操作,捕捉跨通道的交互信息,并得到通道的權(quán)重向量ω;采用sigmoid函數(shù)對(duì)權(quán)重進(jìn)行歸一化處理;將生成的每個(gè)通道權(quán)重與輸入詞向量矩陣對(duì)應(yīng)通道相乘,得到加權(quán)后的文本向量矩陣h″l。
58、進(jìn)一步,在步驟s52中,最終的特征向量ac表示為:
59、
60、特征的計(jì)算公式為:
61、
62、其中,表示卷積核大小為c所生成的第i個(gè)特征,i=1,2,...,l-c+1;為矩陣第i行到i+c-1行,是滑動(dòng)窗口,表示不同位置下的文本向量;w是網(wǎng)絡(luò)中的權(quán)重、b為偏置。
63、進(jìn)一步,在步驟s53中,多頭自注意力計(jì)算為:
64、
65、a=concat(a2,a3,a4)
66、
67、其中,qh、kh、vh表示用于第g個(gè)注意頭的查詢(xún)、鍵和值的向量;為初始化權(quán)重矩陣;t表示向量的轉(zhuǎn)置;a2、a3、a4分別為卷積核大小為2、3、4得到的特征向量,a為特征向量拼接后的矩陣;dk是查詢(xún)、鍵和值的維度;
68、多頭池化計(jì)算為:
69、ph=headh×ug
70、ag=softmax(ph)
71、head′h=agt×headh
72、m=concat(head′1,head′2,...,head′h)
73、其中,ug為初始化參數(shù)向量,將headh與ug進(jìn)行矩陣乘法運(yùn)算,得到聯(lián)合向量ph;利用softmax函數(shù)計(jì)算各行向量之間的概率分布向量ag;agt為向量ag的轉(zhuǎn)置,再將agt與矩陣headh相乘得到向量head′h;將各個(gè)空間所獲取的信息進(jìn)行拼接得到池化后的向量m。
74、進(jìn)一步,在步驟s54中,特征向量m的第i個(gè)類(lèi)別的得分zi為:
75、zi=wim+bi
76、其中zi表示第i個(gè)類(lèi)別的得分,wi和bi為類(lèi)別i所對(duì)應(yīng)的權(quán)重和偏置;
77、則得分向量z表示為:
78、z=[z1,z2,...,zi,...,zα]
79、其中α表示類(lèi)別數(shù),類(lèi)別數(shù)由數(shù)據(jù)標(biāo)注的類(lèi)別分布決定;
80、將得分向量z通過(guò)softmax函數(shù),計(jì)算每個(gè)類(lèi)別的概率:
81、
82、其中qi表示第i個(gè)類(lèi)別的概率;
83、得到長(zhǎng)度為α的概率向量q:
84、q=[q1,q2,...,qi,...,qα]
85、計(jì)算概率向量q中概率值最大的類(lèi)別:
86、imax=argmax(q)
87、其中imax表示最大概率值對(duì)應(yīng)的索引;將imax與s2數(shù)據(jù)標(biāo)注的類(lèi)別匹配,得到檢測(cè)結(jié)果。
88、本發(fā)明的有益效果在于:
89、(1)本發(fā)明針對(duì)深度學(xué)習(xí)惡意url檢測(cè)方法中頁(yè)面文本內(nèi)容無(wú)法充分利用文本中惡意詞信息,設(shè)計(jì)了一種融合惡意詞典與bert預(yù)訓(xùn)練模型的惡意url檢測(cè)方法,對(duì)文本進(jìn)行上下文特征提取,同時(shí)引入惡意詞典進(jìn)行權(quán)重加權(quán)處理,使得惡意特征更加突出;提升了惡意url檢測(cè)的準(zhǔn)確性,能夠更精確地識(shí)別出包含敏感或惡意內(nèi)容的url。
90、(2)本發(fā)明針對(duì)未出現(xiàn)在惡意詞典中的詞語(yǔ)進(jìn)行詞語(yǔ)相似度匹配計(jì)算,即使待匹配詞并非惡意詞的完全匹配,仍可以通過(guò)相似度判斷除潛在的關(guān)聯(lián)性,從而增強(qiáng)了惡意檢測(cè)的覆蓋范圍和靈活性;當(dāng)相似度超過(guò)設(shè)定閾值時(shí),將待匹配詞判定為惡意匹配詞,提高了檢測(cè)的準(zhǔn)確性和魯棒性,有助于識(shí)別出具有變形、同義、或相近表達(dá)的惡意內(nèi)容。
91、本發(fā)明的其他優(yōu)點(diǎn)、目標(biāo)和特征在某種程度上將在隨后的說(shuō)明書(shū)中進(jìn)行闡述,并且在某種程度上,基于對(duì)下文的考察研究對(duì)本領(lǐng)域技術(shù)人員而言將是顯而易見(jiàn)的,或者可以從本發(fā)明的實(shí)踐中得到教導(dǎo)。本發(fā)明的目標(biāo)和其他優(yōu)點(diǎn)可以通過(guò)下面的說(shuō)明書(shū)來(lái)實(shí)現(xiàn)和獲得。
- 還沒(méi)有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!