基于混合深度學習模型和Bootstrap方法的互感器測量誤差區(qū)間預測方法
本發(fā)明涉及電壓互感器誤差預測,具體涉及一種基于混合深度學習模型和bootstrap方法的互感器測量誤差區(qū)間預測方法。
背景技術(shù):
1、在智能電網(wǎng)的測量與保護系統(tǒng)中,電壓互感器作為電力系統(tǒng)中的基礎(chǔ)測量設(shè)備,保障著電力系統(tǒng)的實時監(jiān)控和控制,其測量準確度不僅影響電網(wǎng)的安全可靠運行,同時也對貿(mào)易公平產(chǎn)生直接影響。然而,電壓互感器的測量穩(wěn)定性容易受到多種工業(yè)環(huán)境因素的影響,疊加設(shè)備長期運行導致的老化效應,會逐步削弱互感器的測量性能,導致測量穩(wěn)定性的下降,影響了電力計量的準確性,增加電力系統(tǒng)的運行風險。
2、根據(jù)現(xiàn)行標準,計量器具需要定期進行測量準確度的校準,以確保其測量性能滿足規(guī)范要求。然而,停電校驗的方式要求設(shè)備退出運行,且需對相關(guān)線路進行停電操作。這種校驗方法盡管能夠提供高精度的檢測結(jié)果,但操作復雜,時間、人力成本高,對電網(wǎng)的正常運行造成了干擾。在線校驗技術(shù)雖然不需要停電,但在高壓環(huán)境下通常僅適用于短期監(jiān)測,導致兩次校驗之間存在監(jiān)測“空白”狀態(tài)的情況。
3、近年來,神經(jīng)網(wǎng)絡(luò)作為一種強大的非線性建模工具,在時序預測、信號處理和故障檢測等領(lǐng)域得到了廣泛應用。在智能電網(wǎng)中,基于神經(jīng)網(wǎng)絡(luò)的模型能夠通過分析歷史運行數(shù)據(jù),有效預測設(shè)備未來狀態(tài),繼而及時發(fā)現(xiàn)潛在問題以提升電網(wǎng)運行的可靠性。然而,雖然神經(jīng)網(wǎng)絡(luò)在一定程度上展現(xiàn)了強大的預測能力,但對數(shù)據(jù)質(zhì)量卻有一定的要求,使得在處理非線性和非平穩(wěn)信號時存在顯著局限。
4、首先,單一神經(jīng)網(wǎng)絡(luò)模型在應對非線性和隨機信號時,往往難以兼顧特征提取的深度與準確度。互感器運行在復雜的工業(yè)環(huán)境中,其比差數(shù)據(jù)通常具有顯著的非平穩(wěn)性和隨機性,使單一模型難以全面捕捉數(shù)據(jù)特征。其次,單一神經(jīng)網(wǎng)絡(luò)模型對噪聲干擾和數(shù)據(jù)異常的魯棒性不足,進一步削弱模型的適用性和可靠性。因此,亟需一種可靠的方法對互感器的未來運行狀態(tài)進行建模與預測,以提升測量準確性和運行穩(wěn)定性。
技術(shù)實現(xiàn)思路
1、本發(fā)明一種基于混合深度學習模型和bootstrap方法的互感器測量誤差區(qū)間預測方法,有效提高了預測的確定性。
2、本發(fā)明采取的技術(shù)方案為:
3、基于混合深度學習模型和bootstrap方法的互感器測量誤差區(qū)間預測方法,包括以下步驟:
4、步驟1:采集電壓互感器的運行測量誤差數(shù)據(jù),構(gòu)建數(shù)據(jù)集,并進行自適應噪聲完備集合經(jīng)驗模態(tài)分解(iceemdan)得到的分解信號;
5、步驟2:利用改進的雙向門控循環(huán)單元(tcn)對步驟1中得到的分解信號進行特征提取,并輸出提取后的特征信息ytcn;
6、步驟3:利用雙向門控循環(huán)單元(bigru)對步驟2中得到的特征信息ytcn進行依賴關(guān)系的處理,并輸出綜合特征ybi;
7、步驟4:將步驟3中輸出的綜合特征ybi輸入到多頭注意力機制網(wǎng)絡(luò),進行特征處理,處理后的數(shù)據(jù)經(jīng)過全連接網(wǎng)絡(luò),得到最終的輸出為yout;
8、步驟5:根據(jù)最終的輸出yout計算得到預測誤差yfin,基于改進的bootstrap方法對預測誤差yfin進行統(tǒng)計推斷,得到給定置信水平下的誤差分布區(qū)間,生成區(qū)間預測結(jié)果。
9、所述步驟1中,測量誤差數(shù)據(jù)指的是互感器的比差數(shù)據(jù)。
10、所述步驟1中,構(gòu)建的數(shù)據(jù)集指的是采集后的運行比差數(shù)據(jù)所述步驟1中,自適應噪聲完備集合經(jīng)驗模態(tài)分解(iceemdan)包括如下具體步驟:步驟1.1:通過采集后的比差數(shù)據(jù)與白噪聲序列wj結(jié)合,構(gòu)造新序列公式如下:
11、
12、式中,為原始信號,即采集后的比差數(shù)據(jù);為加入原始信號中的j組白噪聲經(jīng)emd分解后的第一階模態(tài)分量;α0為噪聲強度調(diào)節(jié)系數(shù);為加入噪聲后構(gòu)建的新序列。
13、步驟1.2:對新構(gòu)造的序列應用emd算法計算局部均值,得到第一組殘差r1:
14、
15、式中,表示對序列應用emd算法計算序列的局部均值。
16、上述步驟1.2中,應用emd算法計算局部均值的過程如下:
17、1)計算出新構(gòu)造序列全部極大值和極小值,分別組成極大值集xmax和極小值集xmin;
18、2)對極大值集xmax和極小值集xmin使用樣條函數(shù)進行插值處理,得到的上、下包絡(luò)線xmax(t)、xmin(t);所述樣條函數(shù)是一種通過分段低階多項式平滑地插值數(shù)據(jù)點,確保插值曲線在數(shù)據(jù)點之間光滑過渡的常見的數(shù)學方法;
19、3)計算上、下包絡(luò)線xmax(t)、xmin(t)的局部均值,即步驟1.3:從原始信號中減去第一組殘差,得到第一個模態(tài)函數(shù),記作iimf1:
20、
21、式中,表示采集的比差數(shù)據(jù),即原始信號。
22、此時,第一個模態(tài)函數(shù)已經(jīng)從原始信號中提取出來,代表了信號中的一部分獨立成分。
23、步驟1.4:迭代計算殘差和模態(tài)分量:
24、每次對殘差信號添加一組白噪聲,并應用emd算法計算新的殘差和模態(tài)分量,逐步提取信號中的各個模態(tài)分量;公式如下:
25、
26、式中,ri為此次分解的第i組殘差,表示去除已提取模態(tài)分量后的信號部分;ri-1表示此次分解的第i-1組殘差;αi-1表示第i-1組的噪聲強度調(diào)節(jié)系數(shù);為此次分解的第i個模態(tài)分量;為加入原始信號中的j組白噪聲經(jīng)emd分解后的第i階模態(tài)分量;ri-1表示i-1輪得到的殘差。
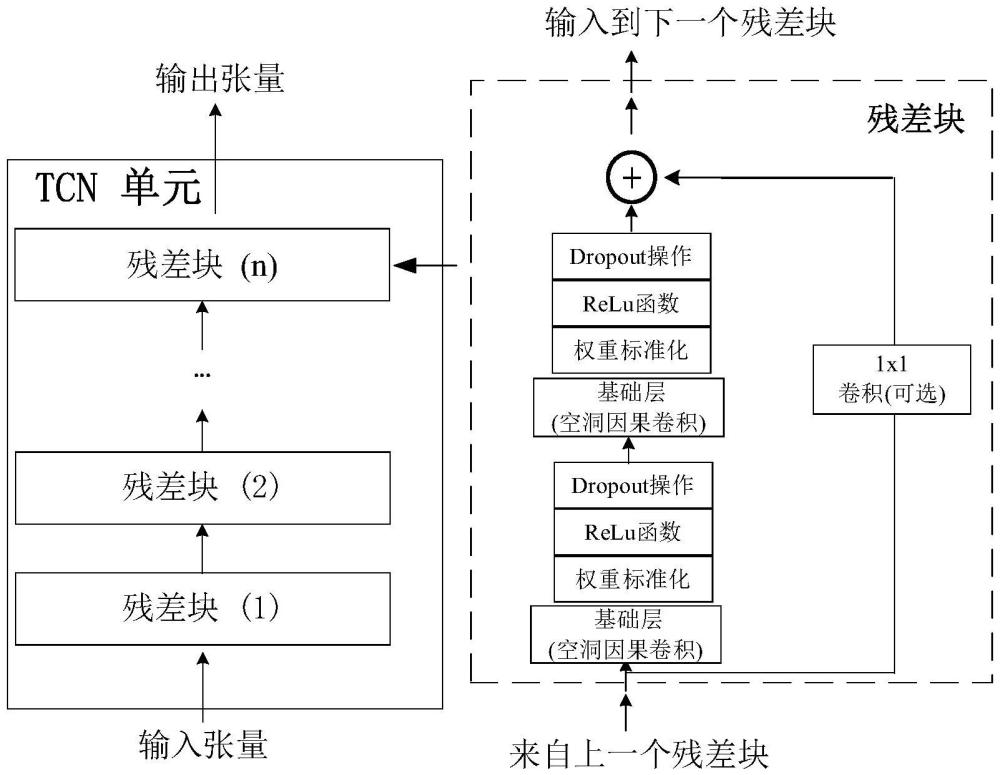
27、分解過程中的噪聲強度調(diào)節(jié)系數(shù)αi用于控制加入白噪聲的比例,其確定依賴于信號的特性,表示為:
28、
29、式中,ε0為首次添加噪聲與被分析信號間信噪比的倒數(shù);e1(wj)代表添加的第j個噪聲的提取的第一個模態(tài)分量;std(e1(wj))代表e1(wj)的標準差;表示原始信號;m為分解的總數(shù)量;λ表示用于計算噪聲強度的信號類型;std(λ)代表λ的標準差;當λ=ri時,噪聲強度調(diào)節(jié)系數(shù)αi直接與第i組殘差信號的標準差相關(guān)。
30、步驟1.5:最終,得到完整的分解結(jié)果:
31、
32、式中,r表示殘差項,表示在分解過程中未能夠分解的最終剩余部分。
33、imfi表示分解后得到的子分量;表示原始信號;m為分解的總數(shù)量。
34、所述步驟2中,改進的時域卷積網(wǎng)絡(luò)單元(tcn)對步驟1中得到的分解信號進行特征的提取,步驟如下:
35、步驟2.1:改進的時域卷積網(wǎng)絡(luò)單元(tcn)接收步驟2中的imfi作為輸入,設(shè)x(i)=imfi,其計算公式如下:
36、
37、式中,為當前s時刻的卷積輸出;x表示輸入的時間序列;fd表示卷積核的權(quán)重;ke為卷積核的大小;d為膨脹系數(shù);s-d·it為卷積核中元素對應的序列;f(it)為卷積核的第it個權(quán)重;it為索引,it∈(0,1,…,ke-1);s為當前時刻。
38、步驟2.2:tcn通過引入殘差連接避免了梯度消失或者梯度爆炸,其計算公式如下:
39、o(i)=relu(x(i)+f(x(i)));
40、式中,o(i)表示殘差塊的輸出;f(x(i))表示卷積操作的輸出;relu表示修正線性單元激活函數(shù);x(i)表示x的第i個輸入信號。
41、步驟2.3:為了兼顧短期和長期依賴關(guān)系的提取,將tcn改為雙路徑結(jié)構(gòu),使用兩個不同感受野的tcn對輸入序列同時進行特征提取,確保兩者關(guān)注不同時間尺度的特征。短期依賴路徑選擇較小的擴張因子和較少的卷積層,感受野較小;長期依賴路徑選擇較大的擴張因子和較深的卷積層,感受野較大;
42、兩條tcn路徑的輸出通過拼接方式融合。雙路徑結(jié)構(gòu)擴張卷積的計算公式如下:
43、
44、式中,fshort(it)和flong(it)分別表示短期路徑和長期路徑的第it個權(quán)重;是短期路徑的特征提取結(jié)果;是長期路徑的特征提取結(jié)果;dshort是短期路徑的擴張因子;dlong是長期路徑的擴張因子;ke為卷積核的大小;s為當前時刻;it表示卷積核中元素的索引。
45、步驟2.4:對短期和長期依賴關(guān)系的tcn的最終輸出進行拼接,計算公式如下:
46、
47、式中,fshort(x(i))代表短期路徑的輸出;flong(x(i))代表長期路徑的輸出;為拼接后的操作;concat代表拼接操作,沿特征維度方向?qū)蓚€輸出組合在一起。
48、所述步驟3中,雙向門控循環(huán)單元(bigru)依賴關(guān)系的處理,步驟如下:
49、步驟3.1:bigru包含正向和反向兩個gru層,分別沿時間正序和逆序處理輸入信號,其計算公式如下:
50、
51、式中,為第i個imf在時間步t的輸入數(shù)據(jù),此時為第i個imf在時間步t-1的隱藏狀態(tài);為更新門向量,控制隱藏狀態(tài)的更新程度;為重置門向量,控制如何組合新輸入和先前的隱藏狀態(tài);為候選隱藏狀態(tài),基于當前輸入和先前隱藏狀態(tài)生成的臨時狀態(tài);為第i個imf在時間步t的正向隱藏狀態(tài);wz、wr、wh分別對應的權(quán)重矩陣;uz、ur、uh分別對應隱藏狀態(tài)到隱藏層的權(quán)重矩陣;bz、br、bh分別對應的偏置向量;σ代表sigmoid激活函數(shù);tanh代表雙曲正切激活函數(shù);⊙代表hadamard乘積。
52、步驟3.2:對序列翻轉(zhuǎn),得到把得到的作為新的輸入,重復步驟3.1,生成反向隱藏狀態(tài)
53、步驟3.3:拼接正向和反向隱藏狀態(tài),則bigru的輸出為:
54、
55、式中,為第i個imf在時間步t上的bigru輸出,通過拼接正向和反向隱藏狀態(tài)得到;[;]為向量拼接操作,將兩個向量按列拼接成一個更長的向量。
56、所述步驟4中,多頭注意力機制網(wǎng)絡(luò)的特征處理,包括如下步驟:
57、步驟4.1:將bi-gru輸出矩陣h(i)映射到查詢、鍵和值:
58、q=h(i)wq
59、k=h(i)wk
60、v=h(i)wv
61、式中,h(i)為第i個imf的bi-gru的輸出矩陣;q,k,v為查詢矩陣、鍵矩陣和值矩陣;wq,wk,wv為映射到查詢、鍵和值的權(quán)重矩陣。
62、步驟4.2:將查詢、鍵和值分割為h個頭,每個頭進行獨立的注意力計算。
63、qh=split(q,h),kh=split(k,h),vh=split(v,h)
64、式中,qh,kh,vh為第h個注意力頭的查詢、鍵和值矩陣;h為注意力頭的總數(shù)量;split(q,h)表示表示將查詢矩陣q按照注意力頭的數(shù)量h拆分成h個子矩陣,分別為每個注意力頭提供查詢矩陣;split(k,h)表示表示將鍵矩陣k按照注意力頭的數(shù)量h拆分成h個子矩陣,分別為每個注意力頭提供鍵矩陣;split(v,h)表示表示將值矩陣v按照注意力頭的數(shù)量h拆分成h個子矩陣,分別為每個注意力頭提供值矩陣。
65、步驟4.3:注意力得分計算:
66、
67、式中,scoresh為第h個注意力頭的得分矩陣,表示查詢與鍵的相似度;為矩陣乘積,計算查詢與鍵的點積相似度;為縮放因子,防止點積值過大。
68、步驟4.4:注意力權(quán)重計算:
69、αh=softmax(scoresh)
70、式中,αh第h個注意力頭的權(quán)重矩陣,表示在值上的加權(quán)系數(shù);softmax函數(shù)的作用是將得分轉(zhuǎn)換為概率分布。
71、步驟4.5:加權(quán)求和值,并拼接與輸出映射:
72、
73、式中,為第h個注意力頭的輸出矩陣;concat的作用是將所有頭的輸出按特征維度拼接;wo是輸出映射的權(quán)重矩陣;vh表示第h個注意力頭的值矩陣;表示第h個注意力頭的加權(quán)輸出;分別表示每個注意力頭的輸出矩陣,表示每個頭獨立計算后的加權(quán)結(jié)果。
74、所述步驟4中,全連接網(wǎng)絡(luò)的計算公式如下:
75、
76、式中,ypred[t]代表在時間步t的預測值;為注意力輸出矩陣在時間步t的特征向量;wfc-out為全連接層的權(quán)重矩陣;bfc-out代表全連接層的偏置向量。此時得到一個imf的預測值;tq表示總的時間步數(shù),即時間序列的長度。
77、根據(jù)步驟1.5得到的不同子分量imfi作為輸入,重復步驟2和步驟3,分別得到不同imfi的預測值。因此最終預測值計算公式為:
78、
79、式中,m仍為步驟一中分解的總數(shù)量;yout為輸出的最終的預測結(jié)果;yipred為第i個imf分量的預測值。
80、所述步驟5中,預測誤差的計算公式如下:
81、
82、式中,yfin為預測殘差;為原始序列。
83、所述步驟5中,bootstrap方法通過對目標數(shù)據(jù)yfin進行多次重抽樣,來統(tǒng)計推斷總體分布特征,將有放回抽樣改為時序抽樣。設(shè)原始樣本為yfin={y1,y2,…,yn},n為樣本的長度。所述步驟5具體包括如下步驟:
84、步驟5.1:計算預測殘差樣本yfin的自相關(guān)函數(shù)(acf),在滯后ka下的自相關(guān)系數(shù)。acf(ka)計算公式定義為:
85、
86、式中,是序列yfin的均值;ka是滯后值;ti為索引;acf(ka)表示是自相關(guān)函數(shù)在滯后ka步下的自相關(guān)系數(shù),用來衡量時間序列中各個時刻之間的相關(guān)性;表示是序列yfin在ti的殘差值;表示是序列yfin在時間步ti+ka的殘差值;n表示序列的總長度,即步驟5中的樣本總數(shù)。
87、步驟5.2:確定塊長度l:
88、l=min{ka:|acf(ka)|<τ}
89、式中,τ是一個預設(shè)的閾值。當|acf(ka)|小于閾值τ時,認為序列在該滯后處的依賴性不顯著。
90、步驟5.3:將yfin分割為長度為l的塊,則分割后的yfin由不同的塊組成:
91、yfin={a1,a2,…,an/l}
92、式中,a為分割的塊的代稱;n/l是需要拼接的塊的數(shù)量,確保樣本長度與原始序列相同。a1,a2,…,an/l是分割后的序列塊,每個塊都包含長度為l的子序列。
93、步驟5.4:從所有塊中隨機有放回抽取,每輪的隨機有放回抽取得到新的一個樣本集c。重復k輪,得到k個樣本集,此時完成時序抽樣方法的樣本選擇。
94、步驟5.5:對于每個bootstrap樣本ck,計算統(tǒng)計量:均值和方差;k個樣本集的總體均值的計算公式如下:
95、
96、總體樣本方差的計算公式如下:
97、
98、式中,表示第k個bootstrap樣本的均值,k=1,2,…,k;表示總體均值;表示總體均值的方差估計;k為重復的輪數(shù),即樣本集的總數(shù)。
99、步驟5.6:根據(jù)樣本分布特性和標準正態(tài)分布的臨界值構(gòu)建預測區(qū)間的上限u和下限l:
100、
101、式中,表示序列的均值;根據(jù)置信水平確定,本發(fā)明的置信水平μ=99%,即α=0.01。步驟5.7:多次重復上述步驟,生成大量bootstrap樣本。具體如下:
102、通過反復從塊中隨機抽取多個樣本,對于每一個樣本集通過步驟5.5和步驟5.6計算一個預測區(qū)間。對于每個樣本集的預測區(qū)間(l,u),檢查真實的總體均值是否落在這個區(qū)間內(nèi)。如果落在區(qū)間內(nèi),視為模型的預測比較準確。最終,統(tǒng)計在k個樣本集的預測區(qū)間中,有多少個包含了真實均值。
103、步驟5.8:計算成功的覆蓋次數(shù)占總次數(shù)的比例,得到覆蓋率。驗證預測區(qū)間與真實值的匹配度,并生成最終的預測區(qū)間。預測區(qū)間的評價指標用如下公式表示:
104、
105、式中,cr表示覆蓋率,即預測區(qū)間覆蓋真實值的比例,值越高表示預測區(qū)間越可靠;aiw表示平均區(qū)間寬度,寬度越小表示預測區(qū)間越精準;li和ui分別是第i個預測區(qū)間的下界和上界;yi表示第i個殘差值;n是步驟5中的樣本總數(shù);代表指示函數(shù),條件成立時為1,否則為0。
106、還包括步驟6:為了進一步提升預測區(qū)間的覆蓋率或緊湊性,提出基于偏態(tài)系數(shù)的動態(tài)優(yōu)化方法,改進分位數(shù)調(diào)整策略,從而提高預測區(qū)間的適應性和準確性。
107、殘差的偏態(tài)系數(shù)計算如下:
108、
109、式中,ss表示偏態(tài)系數(shù);偏態(tài)ss>表示右偏;ss<0表示左偏;ss=0表示對稱分布;yi表示第i個殘差值;表示殘差的均值;n是步驟5中的樣本總數(shù)。
110、步驟7:根據(jù)計算的偏態(tài)結(jié)果,動態(tài)調(diào)整預測區(qū)間的上下界:對于對右偏分布,適當縮小下界分位數(shù),擴大上界分位數(shù);對于對左偏分布,適當擴大下界分位數(shù),縮小上界分位數(shù);對于對稱分布,分位數(shù)保持標準值。公式表達如下:
111、
112、
113、式中,lq表示調(diào)整后的預測區(qū)間的下界分位數(shù);uq表示調(diào)整后的預測區(qū)間的上界分位數(shù);μ表示置信水平。
114、本發(fā)明一種基于混合深度學習模型和bootstrap方法的互感器測量誤差區(qū)間預測方法,技術(shù)效果如下:
115、1)本發(fā)明改進時域卷積網(wǎng)絡(luò)(tcn)采用雙路徑結(jié)構(gòu),分別針對短期依賴和長期依賴關(guān)系進行特征提取,確保模型能夠在不同時間尺度上捕捉互感器運行信號中的重要信息,從而顯著增強了對復雜信號的特征提取能力。并通過雙向門控循環(huán)單元、多頭注意力機制,能夠更精確地提取互感器運行數(shù)據(jù)中的特征,顯著提高了比差預測的準確性。
116、2)本發(fā)明通過自適應噪聲完備集合經(jīng)驗模態(tài)分解iceemdan對序列進行前處理,將復雜信號分解為不同頻幅變化的本征模態(tài)分量,增強了模型對復雜序列的理解能力,同時提高了模型的泛化性能和預測準確性。
117、3)本發(fā)明利用bootstrap方法進行區(qū)間預測,改進的時序抽樣技術(shù)保持了樣本集中數(shù)據(jù)的時間依賴性,提高了區(qū)間預測的魯棒性和適應性。
118、4)本發(fā)明提出了一種基于偏態(tài)系數(shù)動態(tài)調(diào)整分位數(shù)的方法,能夠根據(jù)數(shù)據(jù)分布特性(右偏、左偏或?qū)ΨQ分布)優(yōu)化預測區(qū)間,提高覆蓋率的同時保持較小的區(qū)間寬度。通過動態(tài)優(yōu)化策略,有效避免了傳統(tǒng)靜態(tài)方法在復雜數(shù)據(jù)分布下的局限性,兼顧了預測性能和區(qū)間緊湊性。
119、5)本發(fā)明所提方法提供了一種電壓互感器未來時刻的點預測和區(qū)間預測方法,能夠生成高置信水平的預測區(qū)間(如98%)。對測量誤差分布范圍進行有效統(tǒng)計推斷,為在線監(jiān)測和風險評估提供了數(shù)據(jù)支撐,減少因停電校驗帶來的操作復雜性和經(jīng)濟成本,為智能電網(wǎng)的實時監(jiān)控和貿(mào)易公平性提供技術(shù)保障。同時,還能夠幫助實現(xiàn)潛在故障的早期識別,降低因設(shè)備劣化引發(fā)的安全隱患。
120、6)本發(fā)明步驟6、步驟7中提出通過偏態(tài)系數(shù)調(diào)整預測區(qū)間分位數(shù),動態(tài)優(yōu)化分布特性復雜的數(shù)據(jù),克服了傳統(tǒng)靜態(tài)方法的局限性,同時兼顧預測區(qū)間的覆蓋率和緊湊性,減少寬度冗余。針對不同的分布特性(右偏、左偏或?qū)ΨQ分布),設(shè)計數(shù)據(jù)驅(qū)動的動態(tài)調(diào)整策略,有效提升了區(qū)間建模的魯棒性和泛化能力。上述改進方法能夠有效適應復雜數(shù)據(jù)分布,提高預測區(qū)間的適用性,為機器學習和不確定性量化場景中的區(qū)間優(yōu)化提供了一種高效靈活的解決方案。
- 還沒有人留言評論。精彩留言會獲得點贊!