基于RAG大模型的輔助閱讀方法、系統、設備及存儲介質與流程
本技術涉及自然語言處理,具體涉及一種基于rag大模型的輔助閱讀方法、系統、設備及存儲介質。
背景技術:
1、在全球化進程加速和信息爆炸的時代背景下,人們需要處理大量的多模態數據,包括文檔、圖片、表格、語音和視頻等。傳統的文檔閱讀方式和人工翻譯在處理這些復雜數據時面臨著諸多挑戰。
2、首先,傳統的文檔閱讀方式效率低下,難以快速準確地從大量文檔中獲取所需信息。特別是在處理多語言文檔時,人工翻譯不僅耗時耗力,而且難以保證效率和準確性。此外,直接閱讀翻譯后的文檔還可能因語言差異和文化背景差異而增加理解難度。
3、其次,多模態數據處理也是一個難題。傳統的ocr技術在處理圖片文本時,可能存在準確率不高、處理速度慢的問題。同時,音視頻自動識別技術的準確率也有待提高。這些問題都限制了多模態數據的有效利用。
4、為了解決上述問題,人們開始探索利用人工智能技術來輔助閱讀和理解文檔。隨著人工智能技術的發展,特別是大語言模型的出現,為智能輔助閱讀提供了新的解決方案。然而,現有的智能輔助閱讀系統還存在一些不足。例如,一些系統只能處理單一模態的數據,無法同時處理文檔、圖片、表格、語音和視頻等多種數據。此外,一些系統在處理特定領域或復雜文檔時仍存在理解偏差,缺乏智能輔助和個性化體驗。
5、鑒于此,本技術提出了一種基于rag大模型的輔助閱讀方法、系統、設備及存儲介質,能夠提高信息獲取效率、降低理解難度。
技術實現思路
1、為了解決傳統文檔閱讀對數據處理效率低下、缺乏智能輔助和個性化體驗等問題,本技術提供一種基于rag大模型的輔助閱讀方法、系統、設備及存儲介質,以解決上述技術缺陷問題。
2、根據本技術的第一個方面提出了一種基于rag大模型實現的智能輔助閱讀方法,該方法包括以下步驟:
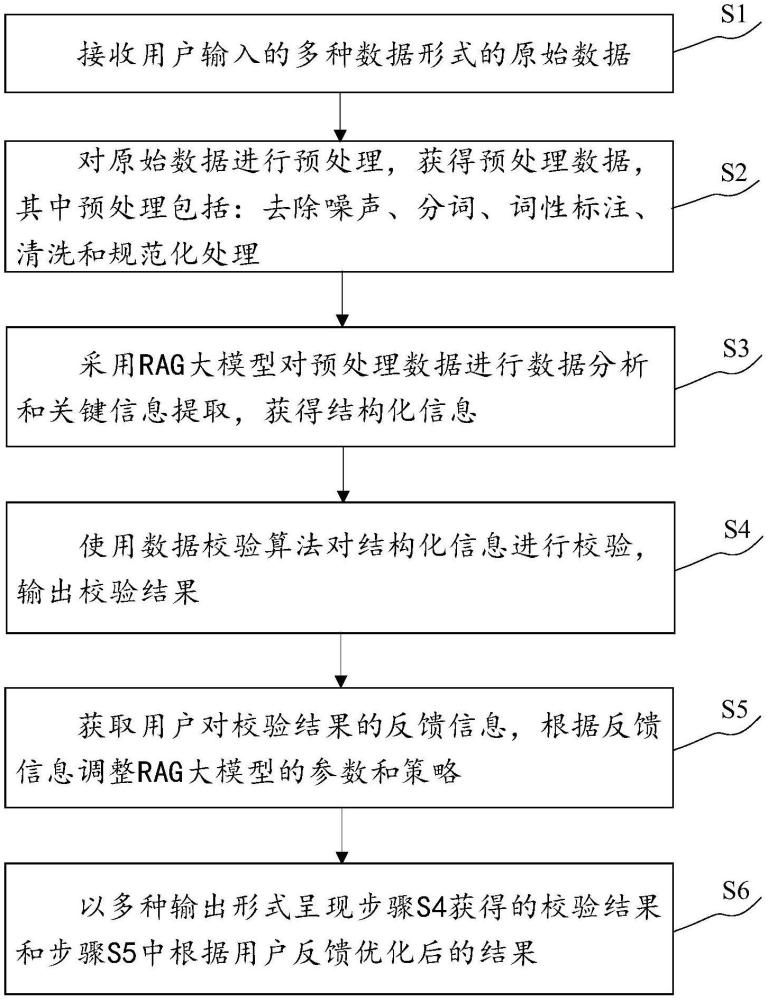
3、s1、接收用戶輸入的多種數據形式的原始數據;
4、s2、對原始數據進行預處理,獲得預處理數據,其中預處理包括:去除噪聲、分詞、詞性標注、清洗和規范化處理;
5、s3、采用rag大模型對預處理數據進行數據分析和關鍵信息提取,獲得結構化信息;
6、s4、使用數據校驗算法對結構化信息進行校驗,輸出校驗結果;
7、s5、獲取用戶對校驗結果的反饋信息,根據反饋信息調整rag大模型的參數和策略;
8、s6、以多種輸出形式呈現步驟s4獲得的校驗結果和步驟s5中根據用戶反饋優化后的結果。
9、優選的,本技術提供的基于rag大模型的輔助閱讀方法,還包括:
10、響應于確定原始數據為圖像,則使用深度學習模型對圖像進行初步的特征提取和分類,識別出圖片中的主要對象和場景;
11、以及采用光學字符識別技術提取圖像中的文本信息,文本信息包括:標題、標簽和注釋;
12、利用對象檢測算法進一步識別圖像中的關鍵元素,關鍵元素包括:人物、物品和標志,并且標注關鍵元素的位置和屬性;
13、結合文本信息和關鍵元素,使用自然語言處理技術生成圖像的描述,以及利用rag大模型從外部知識庫或相關文檔中檢索與圖像內容相關的信息;
14、將生成的圖像的描述和檢索到的與圖像內容相關的信息進行整合,獲得結構化信息。
15、優選的,本技術提供的基于rag大模型的輔助閱讀方法,還包括:
16、響應于確定原始數據為表格,則使用表格解析技術從表格中提取出行、列和單元格數據;
17、對行、列和單元格數據進行清洗和規范化處理,獲得預處理數據;
18、應用數據挖掘技術對預處理數據進行分析,并使用自然語言處理技術生成表格的描述;
19、采用rag大模型從外部知識庫或相關文檔中檢索與表格內容相關的信息;
20、將生成的表格的描述和檢索到的與表格內容相關的信息進行整合,獲得結構化信息。
21、優選的,本技術提供的基于rag大模型的輔助閱讀方法,還包括:
22、響應于確定原始數據為大量的文檔數據,則使用索引技術和查詢優化策略,從大量的文檔數據中檢索與用戶需求相關的信息;
23、以及采用rag大模型從外部知識庫或相關文檔中檢索與用戶需求相關的信息;
24、對檢索到的相關的信息進行內容分析和理解,提取關鍵信息和主題,
25、以及使用自然語言處理技術對檢索到的信息進行語義分析和情感分析;
26、根據用戶需求和數據特點,結合gpt模型生成多種形式的輸出內容,輸出內容包括:摘要、問答對和識圖譜形式;
27、利用rag技術對生成的輸出內容進行校準和調整;
28、將校準和調整后的輸出內容和檢索到的相關的信息進行整合,獲得結構化信息。
29、優選的,在步驟s1中,原始數據包括文檔、圖片、表格、語音和視頻數據。
30、優選的,在步驟s2中,還包括:響應于確定原始數據為語音或視頻數據,則利用語音識別技術對原始數據進行識別,轉換為文字內容。
31、優選的,在步驟s1中,多種數據形式的原始數據從至少一個數據源獲取,數據源包括數據庫、傳感器網絡、用戶輸入接口或網絡服務器。
32、第二方面,本技術提供了一種基于rag大模型實現的智能輔助閱讀系統,該系統包括:
33、數據輸入模塊,配置于接收用戶輸入的多種數據形式的原始數據;
34、預處理模塊,配置于對原始數據進行預處理,獲得預處理數據,其中預處理包括:去除噪聲、分詞、詞性標注、清洗和規范化處理;
35、rag大模型模塊,配置于采用rag大模型對預處理數據進行數據分析和關鍵信息提取,獲得結構化信息;
36、校驗模塊,配置于使用數據校驗算法對結構化信息進行校驗,輸出校驗結果;
37、反饋模塊,配置于獲取用戶對校驗結果的反饋信息,根據反饋信息調整rag大模型的參數和策略;
38、結果輸出模塊,配置于以多種輸出形式呈現校驗模塊獲得的校驗結果和反饋模塊中根據用戶反饋優化后的結果。
39、第三方面,本技術提供了一種終端設備,包括處理器、存儲器以及存儲在存儲器內的計算機程序,計算機程序被處理器執行以實現如上述任意一項的基于rag大模型實現的智能輔助閱讀方法。
40、第四方面,本技術提供了一種計算機可讀存儲介質,介質中存儲有計算機程序,在計算機程序被處理器執行時,實施如上述任意一項的基于rag大模型實現的智能輔助閱讀方法。
41、與現有技術相比,本發明的有益成果在于:
42、(1)本發明直接利用rag大模型對文檔中的圖片和表格進行處理,提高了處理效率和準確性。
43、(2)結合asr等技術,實現對多種數據形式的內容識別提取,幫助用戶快速、準確地理解文檔和數據內容。
44、(3)引入交互式機器學習與用戶反饋循環,使系統能夠不斷學習和優化,提高性能和用戶滿意度。
45、(4)以可視化的方式呈現輸出結果,方便用戶查看和理解。
46、(5)可廣泛應用于文檔閱讀、信息檢索、知識管理等領域,具有較高的實用價值。
- 還沒有人留言評論。精彩留言會獲得點贊!