一種基于信息熵的網絡視頻識別匹配方法與流程
本發明涉及視頻傳輸領域,尤其涉及一種基于信息熵的網絡視頻識別匹配方法。
背景技術:
1、隨著互聯網的不斷發展,全球網民對于視頻業務的需求飛速增長。為了能夠進一步提升用戶的視頻服務體驗,以及互聯網信息安全的需求,運營商及相關網絡管理部門對于特定視頻的識別是當前研究的熱點之一。
2、由于視頻傳輸的數據通常是加密的,因此難以對特定視頻的流量進行簡單直接的識別。同時,網絡視頻一般以切片形式傳輸,音頻和視頻的切片分開,不同的視頻分辨率也對應不同的視頻切片,這使得識別的難度進一步加大。
3、目前公開的文獻中針對網絡視頻識別的方法主要是基于視頻的報文響應的地址、協議、響應時間、視頻序列數長度等作為特征進行識別。
4、現有技術的問題有(1)根據報文響應的地址、協議、響應時間等特征沒有直接依賴于視頻本身的特征,使得識別過程中的誤差較大,容易收到地址變換、網絡條件等變化的干擾。(2)往往簡單依賴握手階段的數據包的特征對數據進行識別,誤差較大,不能充分利用視頻播放中的全部數據(3)用戶對于視頻拖動跳躍播放或者網絡原因導致的包重傳對于識別干擾較大。綜上,目前的方法并不能完美的準確識別網絡視頻識別匹配問題。
技術實現思路
1、鑒于上述問題,提出了本發明以便提供克服上述問題或者至少部分地解決上述問題的一種基于信息熵的網絡視頻識別匹配方法。
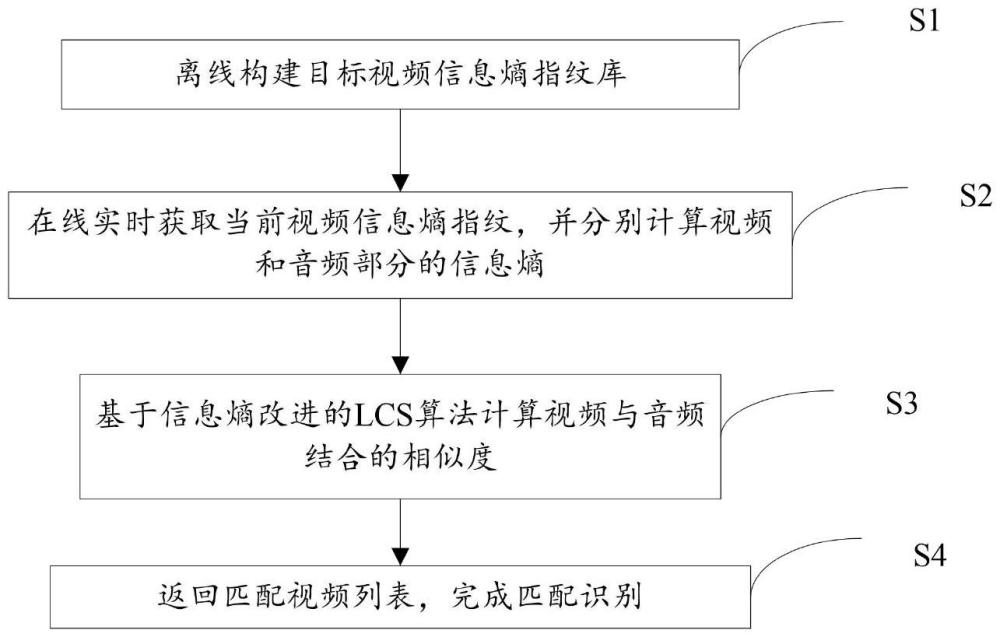
2、根據本發明的一個方面,提供了一種基于信息熵的網絡視頻識別匹配方法,所述匹配方法包括:
3、步驟s1:離線構建目標視頻信息熵指紋庫;
4、步驟s2:在線實時獲取當前視頻信息熵指紋,并分別計算視頻和音頻部分的信息熵;
5、步驟s3:基于信息熵改進的lcs算法計算視頻與音頻結合的相似度;
6、步驟s4:返回匹配視頻列表,完成匹配識別。
7、可選的,所述步驟s1:離線構建目標視頻信息熵指紋庫具體包括:
8、步驟s1.1:搭建一臺可訪問網絡視頻的服務器;
9、步驟s1.2:準備目標視頻的播放列表;
10、步驟s1.3:逐一播放步驟s1.2中所有視頻,對于每個視頻,使用所有分辨率分別播放;
11、步驟s1.4:記錄每個視頻的數據長度序列,并根據參數l進行分類;
12、步驟s1.5:對于每個視頻,每個分辨率,對視頻、音頻特征數據長度進行降序排序后的向量(vn,f,an,f)作為視頻n的指紋加入指紋庫。
13、可選的,所述步驟s1.4:記錄每個視頻的數據長度序列,并根據參數l進行分類具體包括:
14、對于視頻編號為n,分辨率為f,長度大于l的數據i記為vn,f,i,作為視頻特征;對于視頻編號為n的長度小于等于l的數據j記為an,f,j,作為音頻特征。
15、可選的,所述步驟s2:在線實時獲取當前視頻信息熵指紋,并分別計算視頻和音頻部分的信息熵具體包括:
16、步驟s2.1:對于實時的網絡視頻流量,實時記錄數據長度序列,序列長度不超過參數lmax;
17、步驟s2.2:根據參數l進行分類;
18、步驟s2.3:對于視頻的信息熵計算,首先將視頻傳輸塊(chunk)還原為視頻片段,然后使用opencv將幀轉換為灰度圖,并計算和歸一化直方圖,進行每幀的信息熵計算;最后將所有幀的信息熵取平均值;
19、步驟s2.4:對于音頻的信息熵計算,首先計算音頻信號的概率分布,去掉零概率,計算信息熵。
20、可選的,所述步驟s2.2:根據參數l進行分類具體包括:
21、對于大于l的數據進行排序,數組記為vx,對小于等于l的數據進行排序,記為ax,獲得當前播放視頻的編號x的指紋(vx,ax)。
22、可選的,所述步驟s3:基于信息熵改進的lcs算法計算視頻與音頻結合的相似度具體包括:
23、對于視頻指紋庫的中每一個視頻的指紋(vn,f,an,v),和當前匹配視頻指紋(vx,ax)計算相似度。
24、可選的,所述對于視頻指紋庫的中每一個視頻的指紋(vn,f,an,v),和當前匹配視頻指紋(vx,ax)計算相似度具體包括:
25、計算出vn,f和vx的改進最長公共下降子序列,其長度記錄為lcommon_v,且vn,f長度記錄為lvn,f,當前匹配視頻長度記錄為lvx;
26、則視頻x和視頻n的視頻相似度svn,x為lcommon_v/(lvn,f+lvx-lcommon_v);
27、求出an,f和ax的改進最長公共下降子序列,其長度記錄為lcommon_a,且an,f長度記錄為lan,f,當前匹配視頻長度記錄為lax;
28、則視頻x和視頻n的音頻相似度san,x為lcommon_a/(lan,f+lax-lcommon_a);
29、視頻x和視頻n的音頻與視頻結合相似度sn,x的值為wa*san,x+wv*svn,x,其中wa和wv為音頻和視頻的相似度權重。
30、可選的,所述改進最長公共下降子序列的定義為:
31、對于字符串a=[a1,a2…am]和b=[b1,b2…bn],其改進最長公共下降子序列a’=[a’1,a’2…a’k]的定義為,同時滿足以下條件的最長序列:
32、a’是a字符串在不改變字符的相對順序的情況下刪除某些字符后組成的新字符串;
33、存在b’=[b’1,b’2…b’k],且對于任意1≤i≤k,均有|a’i-b’i|≤delta且視頻信息熵(a’i)-視頻信息熵(b’i)|≤deltav或者|a’i-b’i|≤delta且音頻信息熵(a’i)-音頻信息熵(b’i)|≤deltaa,其中delta為誤差范圍值常量,deltav是視頻信息熵誤差常量,deltaa是音頻信息熵誤差常量。
34、可選的,所述改進最長公共下降子序列長度的計算方式為:
35、對于長度m和n的字符串a和b,創建m+1行n+1列的二維數組d,其中d[i][j]表示a1,a2,..ai+1和b1,b2,..bj+1的改進最長公共子序列長度;
36、對于所有的i和j,令d[i][0]和d[0][j]為0;
37、對于所有的大于0的i和j,根據狀態轉移方程計算:
38、如果ai-1-bj-1≤delta那么,對信息熵進行比較,如果視頻信息熵差的絕對值小于deltav,音頻信息熵差的絕對值小于deltaa,那么d[i][j]=d[i-1][j-1]+1;否則,d[i][j]=max(d[i-1][j],d[i][j-1]);
39、最終d[m][n]就是改進最長公共子序列的長度。
40、可選的,所述步驟s4:返回匹配視頻列表,完成匹配識別具體包括:
41、步驟s4.1:根據音頻與視頻結合相似度sn,x按照降序排序,獲得對應的集合vn1,f1,vn2,f2…,完成匹配;
42、步驟s4.2:最有可能匹配的實時視頻為n1,分辨率為f1的視頻,其次為編號n2,分辨率為f2的視頻,依次類推。
43、本發明提供的一種基于信息熵的網絡視頻識別匹配方法,所述匹配方法包括:步驟s1:離線構建目標視頻信息熵指紋庫;步驟s2:在線實時獲取當前視頻信息熵指紋,并分別計算視頻和音頻部分的信息熵;步驟s3:基于信息熵改進的lcs算法計算視頻與音頻結合的相似度;步驟s4:返回匹配視頻列表,完成匹配識別。能夠充分匹配視頻和音頻特征,實現了高效準確的同行分析方法,在不同的序列之間找到隱藏的相似信息,消除復雜網絡環境導致的誤差,提升特定視頻識別匹配的準確率,能夠更好地優化網絡視頻服務,提升視頻鏈路質量。
44、上述說明僅是本發明技術方案的概述,為了能夠更清楚了解本發明的技術手段,而可依照說明書的內容予以實施,并且為了讓本發明的上述和其它目的、特征和優點能夠更明顯易懂,以下特舉本發明的具體實施方式。
- 還沒有人留言評論。精彩留言會獲得點贊!