一種基于PEGASUS模型與動態糾錯的雙階段文本摘要生成方法
本發明涉及文本摘要生成,具體是涉及一種基于pegasus模型與動態糾錯的雙階段文本摘要生成方法。
背景技術:
1、雙階段文本摘要生成任務主要涉及以下四個方面的技術:第一,關鍵句子提取是雙階段摘要生成的基礎任務之一,旨在從原始文本中提取信息密集的重要句子。常用技術包括基于圖的排序算法如textrank、深度學習方法如bert嵌入的相似度比較及機器學習方法如svm。這些方法側重于識別和提取與主題最相關的句子,并在信息提取方面表現出色。第二,文本編碼與理解在雙階段任務中也占據重要地位,特別是深層語義理解方面。bert和transformer等模型廣泛用于此階段,能夠有效捕捉上下文相關信息,從而提升模型對文本意圖和語義理解能力。第三,抽象摘要生成是雙階段過程的第二個重要步驟。通過使用生成式預訓練模型如pegasus或t5,模型可以對提取的關鍵句子進行語義重組和簡化,生成流暢且凝練的摘要。這一階段強調在保留核心信息的同時,生成自然語言文本。第四,模型優化與集成是確保摘要生成質量的重要保障。利用知識蒸餾、對抗訓練和多任務學習等技術,可以提升模型的泛化性能和生成準確性。
2、當前任務的相關中主要存在以下問題:文本主題多樣性導致的句子選擇困難;生成摘要的自然性與準確性之間的平衡問題;存在未登錄詞和暴露偏差的問題;處理長文本時的計算效率問題。
技術實現思路
1、發明目的:針對以上缺點,本發明提供一種準確性高的基于pegasus模型與動態糾錯的雙階段文本摘要生成方法。
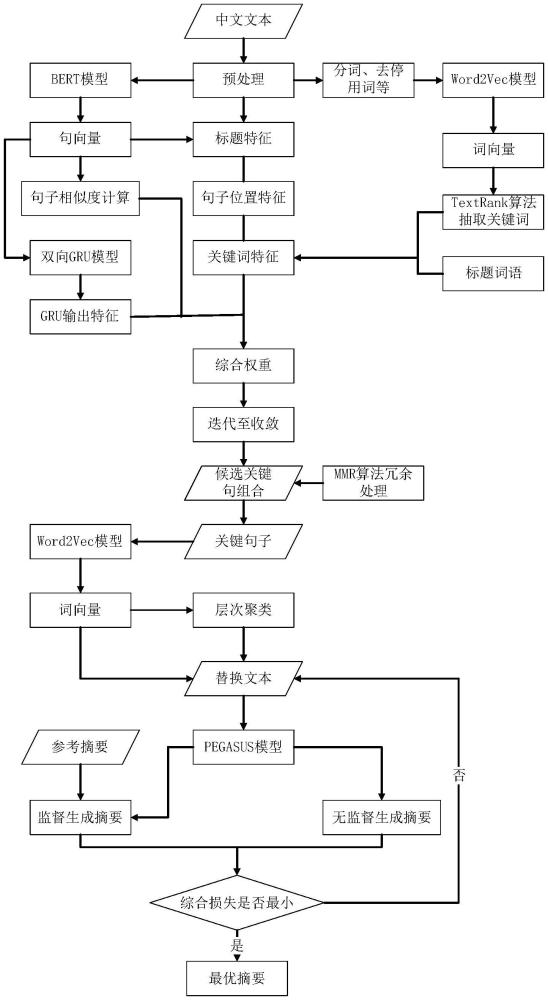
2、技術方案:為解決上述問題,本發明采用一種基于pegasus模型與動態糾錯的雙階段文本摘要生成方法,包括以下步驟:
3、步驟1:獲取待處理的文本數據,并進行預處理,得到標題、句子向量、詞向量、標題詞向量;
4、步驟2:引入標題詞向量進行加權平均計算詞向量的權重,根據詞向量的權重選擇關鍵詞,得到關鍵詞特征;計算句子向量與標題之間的相似度,得到標題特征;對不同位置的句子向量賦予不同的權重,得到句子位置特征;將句子向量通過神經網絡處理,輸出最終語義特征;
5、步驟3:計算句子間的相似度得到句子相似度矩陣;將句子相似度矩陣、關鍵詞特征、標題特征、句子位置特征和最終語義特征進行融合,得到句子特征權重;
6、步驟4:根據句子特征權重對句子進行選取,得到候選關鍵句子;通過mmr算法計算候選關鍵句子的mmr值,將mmr值最高的候選關鍵句子加入關鍵句子集合,迭代計算至句子集合滿足關鍵句子長度或數量要求停止,得到關鍵句子;
7、步驟5:文本數據包括若干文本單元,將關鍵句子通過word2vec模型生成上下文嵌入表示,計算各文本單元間距離,依據文本單元間的距離對文本單元進行層次聚類;
8、步驟6:計算每個聚類中心的相似度來識別潛在的未登錄詞,將未登錄詞標記為錯誤的詞,對標記為錯誤的詞,生成其潛在替代詞的上下文嵌入表示,并根據替代詞的上下文嵌入表示計算替代詞與標記為錯誤的詞的相似度,當相似度高于閾值時,將替代詞替代標記為錯誤的詞,得到替換文本,計算替換文本的替換損失,通過替換損失對替代詞進行糾錯;
9、步驟7:將替換文本輸入訓練好的pegasus模型,輸出摘要;
10、pegasus模型的訓練過程為:獲取訓練數據,訓練數據包括對文本數據處理好的不同替換詞的替換文本以及文本數據對應的參考摘要,將訓練數據中的替換文本輸入pegasus模型,并利用束搜索策略在監督和無監督的情況下輸出生成摘要,計算監督情況下參考摘要與生成摘要間的相似度和無監督情況下不同替換詞后生成摘要間的相似度,整體記作對比損失;
11、通過替換損失和對比損失計算綜合損失,調整各權重系數、動態閾值及相似度閾值,直至綜合損失達到最小或迭代次數達到最大,得到訓練好的pegasus模型。
12、進一步的,所述步驟1中預處理包括:對獲取的文本數據進行去停用詞、分詞、標注詞性,獲得文本數據集;以文本數據集為輸入,采用bert模型生成的句子向量;利用word2vec模型訓練外部數據生成詞向量。
13、進一步的,所述步驟2中,詞向量的權重計算公式為:
14、w(w)=αtf_idf(w,d)+β||vw||+γtr(w)+δit(w)
15、其中,w(w)表示關鍵詞特征權重,||vw||表示詞w的詞向量vw的模長,tr(w)表示textrank算法計算詞w的重要程度,it(w)表示詞w是否屬于標題詞向量的判斷參數,α,β,λ,δ為權重系數;tf_idf(w,d)表示詞w在文本數據中出現的頻率和分布情況,計算公式為:
16、
17、其中,tf_idf(w,d)表示詞w在文本數據中出現的頻率和分布情況,tf(w,d)表示句子s中詞w在文檔d中出現的頻率,df(w)表示詞w在所有文檔中出現的文檔數,n為所有文檔總數;
18、根據句子向量與標題之間的相似度得到標題特征w(st)的計算公式為:
19、w(st)=a·sim(s,title)+b·||vs||
20、其中,sim(s,title)表示句子s和標題title之間的余弦相似度,vs表示為句子s的向量表示,a,b為權重系數;
21、句子位置特征的計算公式為:
22、
23、其中,n為本文段落數,x為首段含有的句子數,y是尾段含有的句子數,i和j是首尾段中句子的位置,e1、e2、β1、β2為權重系數,p表示不同句子位置的參數。
24、進一步的,所述步驟2中,將句子向量通過雙向多層gru神經網絡處理,輸出最終語義特征,具體為:將句子向量輸入到雙向多層gru神經網絡中,被轉換為有序數列xi=(xi,1,xi,2,...,xi,d),序列長度為d,對雙向多層gru神經網絡最后一個隱藏狀態進行處理,得到句子的最終語義特征hi,fin:
25、
26、其中,和表示正向和反向隱藏狀態向量的最后一層輸出。
27、進一步的,所述步驟3中句子特征權重w計算公式為:
28、w=μwconsim+c||w(w)||·hi,fin+dw(st)+qwloc(s)+ρhi,fin
29、其中,wconsim為句子間的相似度矩陣,μ,c,d,q,ρ為權重系數。
30、進一步的,所述步驟4中對句子根據句子特征權重進行由大到小的順序排序,按照比列選取句子作為候選關鍵句子,利用mmr算法,計算候選關鍵句子的相關性及冗余性,得到候選關鍵句子的mmr值,計算公式為:
31、
32、其中,mmr(s)為候選關鍵句子s的mmr值,d為目標摘要,為候選關鍵句子集合,sim(s,d)表示候選關鍵句子s與目標摘要d之間的相似度、sim(s,s’)表示候選關鍵句子s與其他所有候選關鍵句子s’之間的最大相似度、η為權重系數。
33、進一步的,所述步驟6中,計算替換文本與原文本的關鍵句子之間的替換損失,計算公式為:
34、
35、其中,e為原文本的關鍵句子,為替換文本,ei為原文本的關鍵句子中的第i個原詞,為第i個原詞的替代詞,損失函數,m為替代詞個數。
36、進一步的,所述步驟7中監督情況下參考摘要與生成摘要間的相似度包括語義相似度和結構相似度;
37、語義相似度通過余弦相似度表示,計算公式為:
38、lsc(g,r)=1-cos(fg,fr)
39、其中,g表示生成摘要,r表示參考摘要;fg表示生成摘要的嵌入表示,fr表示參考摘要的嵌入表示;
40、結構相似度計算公式為:
41、lst(g,r)=||s(fg)-s(fr)||
42、其中,s(fg)表示生成摘要的嵌入表示的結構特征函數,s(fr)表示參考摘要的嵌入表示的結構特征函數;
43、無監督情況下替換詞后摘要間的相似度計算公式為:
44、
45、其中,gj表示第j個替換詞無監督生成的實例,m表示生成實例的數量;
46、對比損失為:
47、loss2(g,r)=tlsc(g,r)+klst(g,r)+γlcon(g)
48、其中,t、k、γ為權重系數;
49、綜合損失為:
50、
51、其中,θ為權重系數。
52、本發明還采用一種計算機設備,包括存儲器和處理器,所述存儲器存儲有計算機程序,所述處理器執行所述計算機程序時實現上述方法的步驟。
53、本發明還采用一種計算機可讀存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現上述方法的步驟。
54、有益效果:本發明相對于現有技術,其顯著優點是構建動態糾錯機制模塊,動態應用層次聚類,有效的對未登錄詞進行不同替代詞替換,實現摘要的最優選擇;本發明采用無監督和有監督兩種方式下進行摘要生成,構建對比學習框架,為輸出摘要的準確性與自然性提高保障;本發明采用替換損失和對比損失作為綜合損失對模型進行訓練,可以得到表達準確、語句流暢、符合人類閱讀習慣的摘要文本;本發明使用雙向多層gru神經網絡,對關鍵句子提取特征融入語義特征,模型參數少效率高效果好;本發明將文本摘要生成劃分成兩個階段,利用抽取階段對關鍵句子進行抽取整合,優化了文本結構,減少了抽象階段的相對輸入,提高抽象效率與摘要生成的準確性。
- 還沒有人留言評論。精彩留言會獲得點贊!