基于頻域學習的輕量化視頻去噪方法、模型訓練方法及系統
本發明涉及視頻處理,特別涉及視頻去噪,具體為基于頻域學習的輕量化視頻去噪方法、模型訓練方法及系統。
背景技術:
1、移動互聯網時代,高質量視頻是重要的信息傳遞媒介,廣泛應用于國防安全、醫療影像、工業監控、影音娛樂等各個領域。然而,受相機傳感器硬件限制和外部環境因素(如溫度、光照等)的影響,成像的圖像視頻通常包含一定的噪聲分量,破壞圖像或視頻幀的紋理細節,可能導致后續高層圖像視頻處理任務(如分割、檢測、分類等)性能降低。因此,高性能、高效率的視頻去噪技術具有廣闊的應用前景。
2、去噪問題是圖像視頻處理領域基礎的病態逆問題之一,現有的去噪方法可以分為基于模型的方法和基于深度學習的方法。去噪技術初期主要是基于模型的去噪方法,基于模型的圖像去噪方法根據貝葉斯推斷框架,分別構造數據項和先驗項(如非局部均值、稀疏特性、高斯尺度混合等)來獲得目標函數,通過對目標函數迭代求解得到恢復后的結果,與圖像去噪相比,視頻去噪的關鍵是充分利用相鄰幀中的時域信息,因此基于模型的視頻去噪方法一般是以圖像去噪技術為基礎并融合時域相關性得到的。但由于計算過程需要多次迭代才能收斂,并且單一的手工先驗無法充分描述先驗知識,因此基于模型的視頻去噪方法存在推理時間長以及手工先驗建模不準確的問題。
3、隨著硬件資源的蓬勃發展,近些年,基于深度學習的視頻去噪方法通過學習退化數據到標注數據之間的映射關系,以數據驅動的方式獲得了去噪性能的顯著增強,逐漸成為主流的去噪算法。基于神經網絡的視頻去噪方法核心在于構建一個能夠充分學習視頻時空域相關性的網絡結構,其可分為如下兩類:基于殘差和稠密連接的深度卷積網絡去噪方法和基于循環卷積網絡(rnn)的視頻去噪方法。基于殘差和稠密連接的深度卷積網絡去噪方法是圖像去噪方法的擴展,主要包括兩個模塊:時域對齊和空域去噪,通過設計有效的時域對齊和空域去噪子網絡實現視頻去噪。基于rnn的視頻去噪方法利用了rnn較強的時間序列建模能力,有效捕捉視頻相鄰幀的時間相關性,最后得到恢復的視頻幀。現有技術將神經網絡看作是一個黑箱,通過不斷加深加寬網絡結構來提升去噪性能,忽略了計算量的成倍增長,因此現有的基于深度學習的視頻去噪方法通常存在計算量大,難以實際應用的局限。
技術實現思路
1、針對現有技術中存在的問題,本發明提供一種基于頻域學習的輕量化視頻去噪方法、模型訓練方法及系統,該方法能夠降低噪方法的計算量,同時增強視頻序列中每一個視頻幀的恢復質量。
2、本發明是通過以下技術方案來實現:
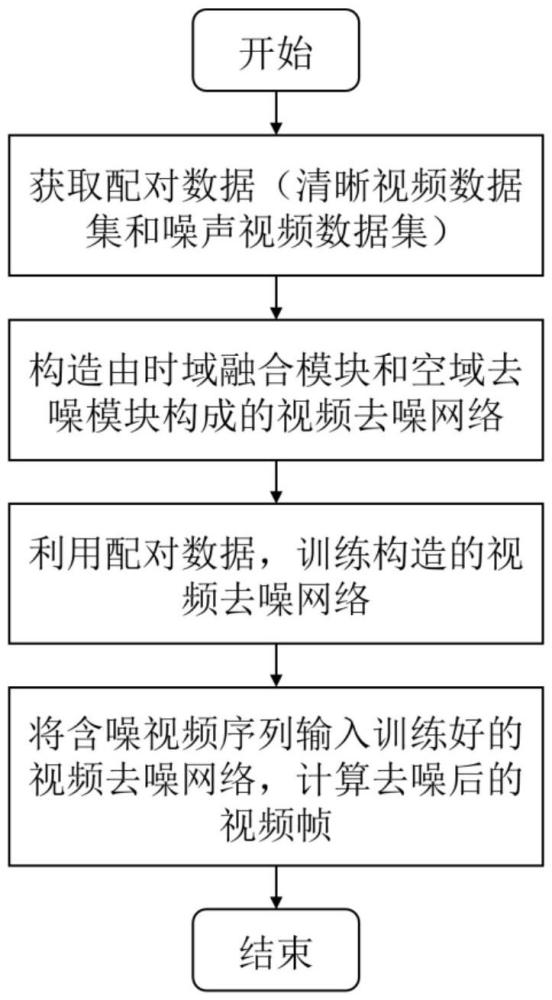
3、第一方面,本技術提供了一種基于頻域學習的輕量化視頻去噪模型訓練方法,包括:
4、獲取清晰視頻集和對應的噪聲視頻集,其中噪聲視頻集是通過對清晰視頻集添加噪聲得到的;
5、以噪聲視頻集作為輕量化視頻去噪模型的輸入,清晰視頻集作為清晰視頻集的標簽,對輕量化視頻去噪模型進行訓練;
6、訓練時,在特征域獲取噪聲視頻集中各視頻幀的特征,在頻率域計算其幅值分量和相位分量的融合權重,然后對所有視頻幀的幅值和相位進行融合,并將融合結果轉換到特征域,得到融合視頻幀;
7、將融合視頻幀和對應的方差圖級聯并輸入加性transformer結構,得到去噪后的視頻幀特征,將去噪后的視頻幀特征轉換到像素域,得到去噪的視頻幀。
8、優選的,所述清晰視頻集添加噪聲,包括:
9、采用高斯分布作為噪聲模型,對清晰視頻集添加高斯噪聲,得到噪聲視頻集。
10、優選的,所述視頻幀特征對應的幅值分量和相位分量的融合權重,包括:
11、根據視頻幀特征獲取其幅值和相位,將所有視頻幀的幅值分量和相位分量分別級聯并輸入卷積網絡,計算每一個視頻幀幅值分量和相位分量的融合權重。
12、優選的,所述融合視頻幀的得到包括:
13、采用點乘操作分別聚合所有視頻幀的幅值和相位的融合權重,根據融合后的幅值和相位,估計融合后的結果,最后通過逆傅里葉變換將融合結果轉換到特征域,得到融合視頻幀;
14、優選的,采用傅里葉變化將視頻幀特征轉換到頻率域;采用逆傅里葉變換將融合結果轉換到特征域。
15、優選的,所述加性transformer模塊包括歸一化層、注意力層、殘差、歸一化層、前饋層和殘差。
16、第二方面,本技術提供了一種基于頻域學習的輕量化視頻去噪模型訓練系統,其特征在于,包括:
17、第一采集模塊,用于獲取清晰視頻集和對應的噪聲視頻集,其中噪聲視頻集是通過對清晰視頻集添加噪聲得到的;
18、訓練模塊,用于以噪聲視頻集作為輕量化視頻去噪模型的輸入,清晰視頻集作為清晰視頻集的標簽,對輕量化視頻去噪模型進行訓練;
19、訓練時,在特征域獲取噪聲視頻集中各視頻幀的特征,在頻率域計算各視頻幀特征對應的幅值分量和相位分量的融合權重,然后對所有視頻幀的幅值和相位進行融合,并將融合結果轉換到特征域,得到融合視頻幀;
20、將融合視頻幀和對應的方差圖級聯并輸入加性transformer結構,得到去噪后的視頻幀特征,將去噪后的視頻幀特征轉換到像素域,得到去噪的視頻幀。
21、第三方面,本技術提供了一種基于頻域學習的輕量化視頻去噪方法,其特征在于,包括:
22、步驟100、獲取噪聲視頻集;
23、步驟200、將獲取的噪聲視頻集輸入至權利要求1-6任一項訓練好的輕量化視頻去噪模型,得到去噪后的視頻集。
24、第四方面,本技術提供了一種基于頻域學習的輕量化視頻去噪系統,其特征在于,包括:
25、第二采集模塊,獲取噪聲視頻集;
26、去噪模塊,用于將獲取的噪聲視頻集輸入至權利要求1-6任一項訓練好的輕量化視頻去噪模型,得到去噪后的視頻集。
27、第五方面,本技術提供了一種電子設備,其特征在于,包括:
28、存儲器,用于存儲計算機程序;
29、處理器,用于執行所述計算機程序時實現權利要求1-6任一項所述基于頻域學習的輕量化視頻去噪模型訓練方法的步驟。
30、與現有技術相比,本發明具有以下有益的技術效果:
31、本發明申請的基于頻域學習的輕量化視頻去噪方法,對時域信息的充分利用是提升視頻去噪性能的關鍵,現有的方法通常使用復雜的運動估計和運動補償的方法或分組融合的方法,導致視頻去噪算法計算量大、去噪能力有限。本發明根據頻域具有全局感受野的特性,在頻域實現相鄰視頻幀的時域融合,在有效利用時域信息的同時大幅降低了計算復雜度,提升了視頻去噪算法的效率;其次,現有的空域去噪方法通常對邊緣紋理特征的處理不足,導致去噪視頻幀的邊緣過于平滑,缺少紋理細節。本發明提出的改進transformer結構具有優異的全局上下文建模能力,能夠妥善恢復視頻幀的紋理細節,另外,本發明提出的加性注意力機制極大降低了算法的內存消耗,進一步增強去噪效率;不同于現有的視頻去噪方法,本發明提出的基于頻域變換的時域融合模塊和基于加性transformer結構的空域去噪結構,大幅節省了計算量,有效提升了視頻去噪方法的速度和性能,可應用于算力有限的場景高效去除視頻噪聲。
32、本技術還提出了一種基于頻域學習的輕量化視頻去噪系統、一種電子設備和一種計算機存儲介質,具備上述基于頻域學習的輕量化視頻去噪方法的全部優勢。
- 還沒有人留言評論。精彩留言會獲得點贊!