一種特征選擇方法、裝置、設備及存儲介質
本發明涉及數據處理,特別是涉及一種特征選擇方法、裝置、設備及存儲介質。
背景技術:
1、在當今世界科技快速發展的背景下,數據的規模和復雜性正在以前所未有的速度增長。分類任務是數據分析的一種基礎且至關重要的形式,準確且高效的分類算法已成為數據科學領域的一個核心研究課題。而隨著數據維度的增加和分類問題復雜性的提升,傳統分類算法面臨著效率低下、易陷入局部最優以及對噪聲數據敏感等問題。
2、特征選擇是數據預處理中的一個重要環節,對于提升分類算法的性能至關重要。高維數據集通常包含大量特征,其中一些特征可能與預測任務無關或冗余。這些不必要的特征不僅會增加模型訓練時的計算負擔,還可能降低分類準確性,因此需要對高維數據集進行特征選擇。
3、元啟發算法是一類從自然過程汲取靈感的優化技術,通過模擬進化過程等自然現象來提供一種強大的全局搜索能力,因其能夠在廣闊的搜索空間中有效地找到最優解而備受科研人員的推崇,廣泛應用于工程優化、數據挖掘和機器學習等領域。近期的研究將重點集中在開發新策略和機制以提高啟發式算法的搜索能力和效率,包括引入各種搜索策略以平衡全局搜索和局部搜索,利用混沌理論和復雜網絡理論來防止早熟收斂,以及采用自適應和學習機制來動態調整算法參數。通過這些改進,研究人員希望使算法能更快地收斂到全局最優解,同時又能保持對復雜問題空間的有效探索。改進后的算法在處理特定問題時表現出了高度的競爭力。
4、指數分布優化器(exponential?distribution?optimizer,edo)作為一種元啟發算法,在多個應用領域中展現出了巨大潛力。edo是一種基于指數概率分布的數學模型提出的優化算法。它初始化一群代表多個指數分布模型的隨機解,每個解的位置代表一個指數隨機變量。edo依據無記憶性、引導解和指數隨機變量間的關系來更新當前解。然而,將edo應用在高維特征選擇問題中,算法往往陷入局部最優解,這阻礙了它們全面探索整個搜索空間的能力,并限制了它們在應對復雜挑戰時的有效性,降低了特征選擇的分類準確性。
技術實現思路
1、本發明提供了一種特征選擇方法、裝置、設備及存儲介質,解決了現有的edo應用在高維特征選擇問題中,算法往往陷入局部最優解,這阻礙了它們全面探索整個搜索空間的能力,并限制了它們在應對復雜挑戰時的有效性的問題。
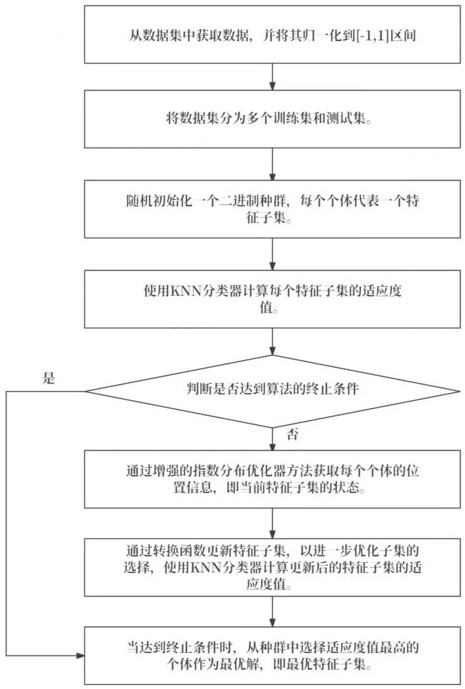
2、第一方面,本發明提供一種特征選擇方法,包括以下步驟:
3、將待處理的高維數據集中的特征子集作為個體,通過多個個體構建初始種群;
4、獲取初始種群中的每個個體的適應度值;
5、通過改進的指數分布優化器對初始種群中的多個個體的位置進行更新,得到新種群;其中,在指數分布優化器中增加水平交叉、垂直交叉和自適應差分進化機制,得到改進的指數分布優化器;所述水平交叉和垂直交叉為通過個體在不同維度特征值的相互交叉結果對個體位置進行更新,所述自適應差分進化機制為通過個體的適應度值動態調整縮放因子,通過縮放因子對個體位置進行更新;
6、獲取新種群的多個個體的適應度值,判斷其是否滿足終止條件,若不滿足,則通過改進的指數分布優化器再次對新種群進行迭代并進行適應度值判斷;若滿足,則從當前種群中選擇適應度值最高的個體作為最優解,即最優特征子集。
7、優選的,所述獲取初始種群中的每個個體的適應度值,具體如下所示:
8、;
9、式中,為適應度值,為分類準確率權重,為分類錯誤率, r為所選特征子集的長度, n為總特征數量,為所選特征數量的權重。
10、優選的,所述通過改進的指數分布優化器對初始種群中的多個個體的位置進行更新,得到新種群,包括以下步驟:
11、通過指數分布優化器、水平交叉、垂直交叉和自適應差分進化機制對初始種群中的每個個體依次進行更新,得到每個個體對應的第一新個體、第二新個體、第三新個體和第四新個體;
12、基于適應度值判斷得到每個個體對應的第一新個體、第二新個體、第三新個體和第四新個體中的最優個體;
13、將初始種群中的每個個體替換為對應的最優個體,得到新種群。
14、優選的,所述基于水平交叉和垂直交叉對初始種群中的任意兩個個體的位置進行更新,得到多個新個體,具體包括:
15、;
16、;
17、式中,和為水平交叉得到的兩個新個體,和為隨機變量,和為父代個體和在第 n維度的特征值,和為隨機變量;
18、;
19、式中,為垂直交叉得到的新個體,和為隨機數,為垂直交叉的交叉率。
20、優選的,所述自適應差分進化機制為通過個體的適應度值動態調整縮放因子,通過縮放因子對個體位置進行更新,具體包括:
21、;
22、式中,和為兩個個體的適應度值, k為縮放因子;
23、;
24、式中,為自適應差分進化機制得到新個體,為待變異父代個體,和為兩個隨機父代個體。
25、優選的,所述獲取初始種群中的每個個體的適應度值以及獲取新種群的多個個體的適應度值之前,還需對初始種群以及新種群的多個個體進行二進制編碼,具體包括:
26、;
27、;
28、式中,表示第 t次迭代中產生的第 i個個體的第 p個特征值,為隨機數,為閾值函數, x為個體在特定維度上的值。
29、優選的,所述終止條件為最大迭代次數或當前適應度值達到設定閾值。
30、第二方面,本發明提供一種特征選擇裝置,包括:
31、構建模塊,用于將待處理的高維數據集中的特征子集作為個體,通過多個個體構建初始種群;
32、獲取模塊,用于獲取初始種群中的每個個體的適應度值;
33、更新模塊,用于通過改進的指數分布優化器對初始種群中的多個個體的位置進行更新,得到新種群;其中,在指數分布優化器中增加水平交叉、垂直交叉和自適應差分進化機制,得到改進的指數分布優化器;所述水平交叉和垂直交叉為通過個體在不同維度特征值的相互交叉結果對個體位置進行更新,所述自適應差分進化機制為通過個體的適應度值動態調整縮放因子,通過縮放因子對個體位置進行更新;
34、迭代模塊,用于獲取新種群的多個個體的適應度值,判斷其是否滿足終止條件,若不滿足,則通過改進的指數分布優化器再次對新種群進行迭代并進行適應度值判斷;若滿足,則從當前種群中選擇適應度值最高的個體作為最優解,即最優特征子集。
35、第三方面,本發明提供一種計算機設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的計算機程序,所述處理器執行所述程序時實現上述的特征選擇方法。
36、第四方面,本發明提供一種計算機可讀存儲介質,所述存儲介質存儲有計算機程序,所述計算機程序被處理器執行時實現上述的特征選擇方法。
37、與現有技術相比,本發明的有益效果是:
38、本發明提出了一種特征選擇方法,通過在指數分布優化器中增加水平交叉、垂直交叉和自適應差分進化機制,得到改進的指數分布優化器,本發明通過多個更新機制對種群中的多個個體的位置進行更新,能夠探索到更多潛在的最優解。進一步的,水平交叉和垂直交叉為通過個體在不同維度特征值的相互交叉結果對個體位置進行更新,自適應差分進化機制為通過個體的適應度值動態調整縮放因子,通過縮放因子對個體位置進行更新。不同的更新機制所更新的個體位置均不相同,本發明中采用不同的更新機制相互協作,可以幫助算法跳出局部最優解,增加了全面探索整個搜索空間的能力,增加了應對復雜挑戰的能力,實現更好的特征選擇效果,提高了特征選擇的分類準確性。
- 還沒有人留言評論。精彩留言會獲得點贊!