一種面向多數據源的數據采集方法與系統與流程
本發明涉及數據采集,具體為一種面向多數據源的數據采集方法與系統。
背景技術:
1、在當今信息化時代,數據已成為企業決策、業務優化及創新發展的關鍵要素。隨著大數據技術的飛速發展,數據的來源日益多樣化,包括但不限于傳感器網絡、社交媒體、企業數據庫、日志文件等。這些多源數據蘊含著豐富的信息,但同時也帶來了數據采集的復雜性和挑戰性。
2、現有的數據采集技術通常缺乏系統的特征提取和數據質量評估機制。特征提取是理解數據源性質、內容及其潛在價值的基礎,而數據質量評估則是確保采集數據準確性、完整性和一致性的關鍵。缺乏這些機制,可能導致采集到的數據無法滿足后續分析或應用的需求,甚至引入錯誤或偏差,影響決策的準確性。數據采集決策過程往往依賴于人工經驗或簡單的規則設定,缺乏智能化和自適應性。在多變的數據環境中,這種靜態的決策方式難以實時響應數據質量的變化,無法動態調整采集策略以優化資源分配和采集效率。
技術實現思路
1、本發明的目的在于提供一種面向多數據源的數據采集方法與系統,以解決上述背景技術中提出的問題。
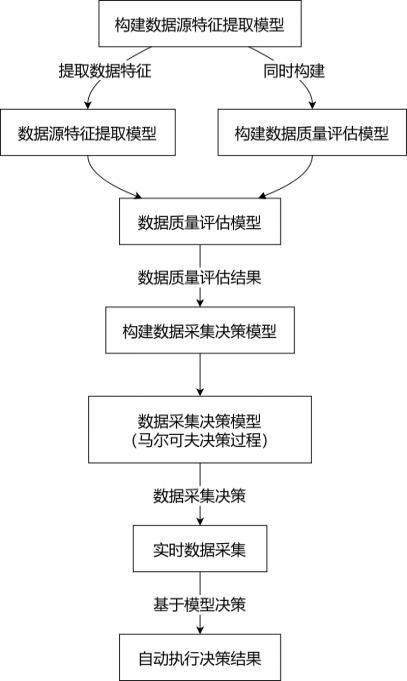
2、為實現上述目的,本發明提供如下技術方案:一種面向多數據源的數據采集方法,所述方法包括:
3、步驟a:構建數據源特征提取模型和數據質量評估模型,所述數據源特征提取模型用于從多個數據源中提取數據特征,所述數據質量評估模型基于數據源特征提取模型的輸出進行數據質量評估;
4、步驟b:構建數據采集決策模型,將數據采集過程建模為馬爾可夫決策過程,用于基于數據質量評估模型的輸出進行數據采集決策;
5、步驟c:基于訓練好的數據源特征提取模型、數據質量評估模型和數據采集決策模型進行實時數據采集,并將決策結果自動執行。
6、優選的,所述數據源特征提取模型采用自注意力機制與圖卷積網絡gcn結合的算法構建,其網絡結構至少包括:
7、輸入層:用于接收模型的訓練數據;
8、隱藏層:包含至少一層自注意力機制層用于提取數據間的相關性特征,后接至少一層gcn隱藏層,每層gcn隱藏層包含若干個gcn單元,用于捕捉數據源的結構信息;
9、輸出層:接收隱藏層的輸出,并通過一個全連接層將網絡的輸出映射到提取的特征向量上。
10、優選的,訓練數據源特征提取模型的步驟包括:
11、初始化自注意力機制和gcn網絡的權重和偏置項,采用xavier初始化方法;
12、采用交叉熵損失函數作為損失函數,用于衡量模型提取特征與真實特征之間的差異;
13、采用反向傳播算法和rmsprop優化算法,根據損失函數計算梯度,并更新自注意力機制和gcn網絡的權重和偏置項,迭代訓練網絡直至損失函數收斂;
14、保存訓練好的模型,作為數據源特征提取模型。
15、優選的,所述數據質量評估模型采用梯度提升決策樹gbdt算法構建,其訓練步驟包括:
16、收集訓練數據,包括歷史數據源特征、歷史數據采集效率、歷史數據質量指標以及對應的實際數據使用效果;
17、將訓練數據中的歷史數據源特征、歷史數據采集效率和歷史數據質量指標作為輸入特征,將對應的數據使用效果作為標簽,構建gbdt算法的訓練樣本集;
18、利用gbdt算法對訓練樣本集進行訓練,通過構建多棵決策樹并集成其輸出結果提高評估準確性;
19、在訓練過程中,通過網格搜索法優化gbdt算法的樹的數量、學習率和最大深度。
20、優選的,所述數據采集決策模型采用深度確定性策略梯度ddpg算法構建。
21、優選的,所述數據采集決策模型的具體定義包括:
22、狀態空間:定義為多數據源的數據質量指標、數據源可用性狀態和數據采集系統狀態的組合;
23、動作空間:定義為可執行的數據源選擇、采集頻率調整和數據預處理操作集合;
24、獎勵函數:根據數據采集效率和數據質量評估結果計算獎勵或懲罰,對提高采集效率和數據質量的操作給予正獎勵,對降低采集效率和數據質量的操作給予懲罰;
25、輸出策略:定義為在當前狀態下選擇最優動作的方法,通過深度強化學習算法不斷優化生成的決策動作。
26、優選的,所述數據質量指標包括數據的完整性、準確性、一致性和時效性;所述數據源可用性狀態包括數據源的在線狀態、響應時間和數據吞吐量;所述數據采集系統狀態包括系統負載、存儲容量和處理能力。
27、優選的,所述可執行的數據源選擇、采集頻率調整和數據預處理操作集合,包括:選擇數據質量高的數據源、調整數據采集的頻率、執行數據清洗和格式化操作、以及數據壓縮和加密處理。
28、優選的,所述獎勵函數的實現方法包括:
29、獲取實時數據采集效率指標;將實時數據采集效率指標與預設的采集效率目標進行對比,計算采集效率偏差;
30、獲取實時數據質量評估結果;將數據質量評估模型輸出的當前數據質量指標與預設的質量標準或歷史質量數據進行對比,計算數據質量偏差;
31、根據采集效率偏差和數據質量偏差計算獎勵或懲罰,具體公式為:
32、r?=?γ?*?(e_target?-?e_current)?-?δ?*?(q_target?-?q_current)
33、其中,r表示獎勵值,e_target和e_current分別表示目標采集效率和當前采集效率,q_target和q_current分別表示目標數據質量和當前數據質量,γ和δ分別為采集效率偏差和數據質量偏差的權重系數,且γ,?δ>0。
34、優選的,一種面向多數據源的數據采集系統,所述系統包括:
35、數據源特征提取模塊,用于從多個數據源中提取數據特征;
36、數據質量評估模塊,連接至所述數據源特征提取模塊,基于數據源特征提取模塊的輸出進行數據質量評估;
37、數據采集決策模塊,連接至所述數據質量評估模塊,將數據采集過程建模為馬爾可夫決策過程,用于基于數據質量評估模塊的輸出進行數據采集決策;
38、執行模塊,連接至所述數據采集決策模塊,用于基于訓練好的數據源特征提取模型、數據質量評估模型和數據采集決策模型進行實時數據采集,并將決策結果自動執行。
39、與現有技術相比,本發明的有益效果是:
40、通過構建數據源特征提取模型,本發明能夠從多個異構數據源中自動提取數據特征,全面理解數據源的性質、內容及潛在價值。數據質量評估模型的引入,確保了采集數據的準確性、完整性和一致性,有效避免了因數據質量問題而導致的決策偏差。這兩個模型的結合使用,大大提高了數據采集的準確性和效率,為后續的數據分析、挖掘和應用提供了高質量的數據基礎。
41、本發明將數據采集過程建模為馬爾可夫決策過程,構建了數據采集決策模型。這一模型能夠根據數據質量評估模型的輸出,實時調整采集策略,優化資源分配。這種智能化的決策方式,使得數據采集過程能夠動態響應數據環境的變化,自動調整采集策略,提高了數據采集的靈活性和自適應性。
- 還沒有人留言評論。精彩留言會獲得點贊!