一種基于深度學(xué)習(xí)的多視角圖片數(shù)據(jù)采集方法與流程
本發(fā)明涉及圖片數(shù)據(jù)采集,尤其涉及一種基于深度學(xué)習(xí)的多視角圖片數(shù)據(jù)采集方法。
背景技術(shù):
1、在計算機視覺領(lǐng)域,圖像采集與處理技術(shù)的快速發(fā)展,使得多視角圖像數(shù)據(jù)的采集成為了一個至關(guān)重要的研究方向。傳統(tǒng)的多視角圖像采集技術(shù)主要依賴于通過多個靜態(tài)攝像頭或圖像采集設(shè)備,在不同視角下捕捉場景的圖像信息。通過從多個視角采集的圖像,結(jié)合計算機視覺中的圖像重建技術(shù),可以生成三維圖像、模型或場景,廣泛應(yīng)用于3d重建、虛擬現(xiàn)實、增強現(xiàn)實、機器人導(dǎo)航、自動駕駛、醫(yī)學(xué)影像等多個領(lǐng)域。然而,現(xiàn)有技術(shù)在多視角圖像采集、圖像重建及其優(yōu)化方面仍然存在一些局限性,亟待改進。
2、目前,傳統(tǒng)的多視角圖像數(shù)據(jù)采集方法多通過相機陣列或手動設(shè)置攝像頭位置的方式進行圖像數(shù)據(jù)的捕獲。這些方法通常依賴人工設(shè)置采集設(shè)備的位置和視角,導(dǎo)致采集過程繁瑣且不易優(yōu)化。此外,攝像頭的角度、焦距等參數(shù)往往是靜態(tài)設(shè)定,缺乏智能化的調(diào)整和優(yōu)化手段。在多視角圖像的預(yù)處理方面,現(xiàn)有技術(shù)大多依賴于傳統(tǒng)的圖像去噪、幾何校正和顏色標(biāo)準(zhǔn)化方法,雖然這些方法可以在一定程度上提高圖像質(zhì)量,但它們往往無法對圖像中的深層次特征進行全面的提取和優(yōu)化。特別是對于復(fù)雜場景中的多視角圖像,現(xiàn)有的預(yù)處理方法往往存在信息丟失和細節(jié)保留不足的問題,無法最大化地提取圖像中的關(guān)鍵信息。
3、在圖像特征提取方面,現(xiàn)有的技術(shù)大多依賴于傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)進行特征學(xué)習(xí)。雖然卷積神經(jīng)網(wǎng)絡(luò)已經(jīng)在圖像分類、目標(biāo)檢測等任務(wù)中取得了顯著的成績,但在多視角圖像的數(shù)據(jù)處理中,傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)存在一定的局限性。特別是在多視角圖像的特征提取過程中,傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)往往不能有效地處理不同視角之間的圖像差異,導(dǎo)致提取出的特征信息不完整,無法準(zhǔn)確捕捉到多視角圖像中的空間關(guān)系和深度信息。此外,傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)通常缺乏自適應(yīng)的特征選擇機制,容易忽略圖像中某些重要區(qū)域的細節(jié),無法滿足對高精度圖像重建的需求。
4、為了解決這些問題,近年來,基于深度學(xué)習(xí)的生成對抗網(wǎng)絡(luò)被廣泛應(yīng)用于圖像重建和生成任務(wù)。生成對抗網(wǎng)絡(luò)通過生成器和判別器的對抗訓(xùn)練,可以在無監(jiān)督的條件下生成高質(zhì)量的圖像。然而,現(xiàn)有的生成對抗網(wǎng)絡(luò)在處理多視角圖像時,往往無法有效融合來自不同視角的圖像特征,導(dǎo)致重建效果不佳。特別是在多視角圖像的三維重建過程中,傳統(tǒng)的生成對抗網(wǎng)絡(luò)通常缺乏空間信息的處理能力,導(dǎo)致生成的圖像在空間結(jié)構(gòu)上存在明顯的失真。因此,如何有效結(jié)合多視角圖像的特征信息,優(yōu)化圖像重建過程,仍然是一個技術(shù)難點。
5、此外,現(xiàn)有的圖像重建方法往往在生成對抗網(wǎng)絡(luò)的訓(xùn)練過程中依賴大量的人工標(biāo)注數(shù)據(jù),且訓(xùn)練時間較長,計算資源消耗大。傳統(tǒng)的生成對抗網(wǎng)絡(luò)模型需要在生成器和判別器之間進行大量的對抗訓(xùn)練,這一過程通常會導(dǎo)致訓(xùn)練不穩(wěn)定和收斂困難。而且,由于訓(xùn)練過程中缺乏有效的監(jiān)督信號,網(wǎng)絡(luò)可能會出現(xiàn)模式崩潰等問題,從而影響圖像生成質(zhì)量和多視角圖像重建的準(zhǔn)確性。
技術(shù)實現(xiàn)思路
1、本發(fā)明的一個目的在于提出一種基于深度學(xué)習(xí)的多視角圖片數(shù)據(jù)采集方法,本發(fā)明通過改進的resnet34網(wǎng)絡(luò)對多視角圖像進行特征提取,并利用注意力機制對特征進行加權(quán),優(yōu)化了傳統(tǒng)網(wǎng)絡(luò)在多視角圖像處理中存在的特征選擇和圖像細節(jié)捕捉不足的問題,將改進生成對抗網(wǎng)絡(luò)應(yīng)用于圖像重建中,利用優(yōu)化的生成器和判別器結(jié)構(gòu),生成圖像,并通過訓(xùn)練過程中的反饋機制,優(yōu)化圖像的細節(jié)和空間結(jié)構(gòu)。
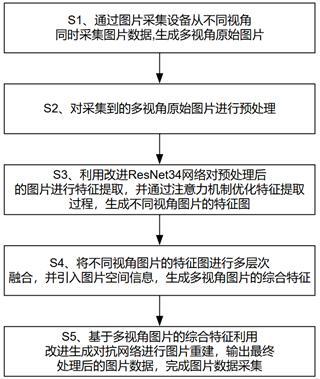
2、根據(jù)本發(fā)明實施例的一種基于深度學(xué)習(xí)的多視角圖片數(shù)據(jù)采集方法,包括如下步驟:
3、s1、通過圖片采集設(shè)備從不同視角同時采集圖片數(shù)據(jù),生成多視角原始圖片;
4、s2、對采集到的多視角原始圖片進行預(yù)處理;
5、s3、利用改進resnet34網(wǎng)絡(luò)對預(yù)處理后的圖片進行特征提取,并通過注意力機制優(yōu)化特征提取過程,生成不同視角圖片的特征圖;
6、s4、將不同視角圖片的特征圖進行多層次融合,并引入圖片空間信息,生成多視角圖片的綜合特征;
7、s5、基于多視角圖片的綜合特征利用改進生成對抗網(wǎng)絡(luò)進行圖片重建,輸出最終處理后的圖片數(shù)據(jù),完成圖片數(shù)據(jù)采集。
8、可選的,所述預(yù)處理包括去噪、幾何校正、顏色標(biāo)準(zhǔn)化和圖片對齊。
9、可選的,所述s3具體包括:
10、s31、構(gòu)建改進resnet34網(wǎng)絡(luò),所述改進resnet34網(wǎng)絡(luò)包括:
11、輸入層,輸入經(jīng)過預(yù)處理的圖片數(shù)據(jù);
12、卷積層,在多個尺度上對輸入圖片數(shù)據(jù)進行多尺度特征提取,捕捉圖片數(shù)據(jù)的局部特征和全局特征,所述卷積層使用的卷積核大小為7×7和3×3;
13、批量歸一化層,對每一層的輸出進行歸一化;
14、激活函數(shù)層,將卷積層的輸出通過relu激活函數(shù)進行非線性激活;
15、殘差塊,通過跳躍連接將輸入直接添加到輸出層,保持信息流暢通,所述改進resnet34網(wǎng)絡(luò)在傳統(tǒng)resnet34網(wǎng)絡(luò)的基礎(chǔ)上,在殘差塊里面引入了可變權(quán)重的殘差連接;
16、池化層,在卷積后應(yīng)用最大池化,選擇每個2×2窗口中的最大值,減小特征圖的尺寸;
17、全連接層,通過對前面層的輸出進行加權(quán)求和并應(yīng)用激活函數(shù),最終將特征映射到目標(biāo)輸出空間;
18、輸出層,生成改進resnet34網(wǎng)絡(luò)的最終結(jié)果;
19、s32、將經(jīng)過預(yù)處理的圖片輸入到改進resnet34網(wǎng)絡(luò)進行特征提取,所述改進resnet34網(wǎng)絡(luò)的每個殘差塊包含兩層卷積層,每層卷積后跟隨批量歸一化和relu激活函數(shù),經(jīng)過卷積操作得到輸出,將輸出通過加法操作與輸入進行融合:
20、;
21、;
22、其中,表示通過改進resnet34網(wǎng)絡(luò)提取到的第k個特征圖,表示第k個卷積核的權(quán)重,表示第k個偏置項,表示輸入圖片,(i,j)表示圖片中每個位置的像素坐標(biāo),m和n表示卷積核的大小,表示卷積層提取的特征圖,表示自適應(yīng)參數(shù);
23、s33、基于注意力機制,通過全連接層對每個特征圖生成注意力權(quán)重向量,并對特征圖進行加權(quán),增強特征圖中的關(guān)鍵信息,生成不同視角圖片的特征圖,所述注意力機制通過自適應(yīng)的方式選擇圖片區(qū)域的關(guān)注程度:
24、;
25、;
26、其中,表示第k個特征圖的注意力權(quán)重向量,σ表示激活函數(shù),表示全連接層的權(quán)重,表示全連接層的偏置,γ表示自適應(yīng)加權(quán)系數(shù),表示加權(quán)后的特征圖。
27、可選的,所述s4具體包括:
28、s41、將不同視角圖片的特征圖進行融合:
29、;
30、其中,表示融合后的特征,表示視角對應(yīng)的權(quán)重系數(shù),通過訓(xùn)練過程得到,n表示視角的個數(shù);
31、s42、通過加入空間信息提高圖片特征對空間結(jié)構(gòu)的感知能力,在特征融合后,將空間信息與融合后的特征進行特征連接操作,得到融合空間信息的空間特征:
32、;
33、其中,表示融合空間信息的空間特征,表示特征連接操作,s(x,y)表示圖片每個像素的空間位置信息;
34、s43、結(jié)合多視角圖片信息、改進注意力機制和空間信息,最終生成多視角圖片的綜合特征:
35、;
36、其中,表示多視角圖片的綜合特征,表示融合空間信息的空間特征。
37、可選的,所述s5具體包括:
38、s51、構(gòu)建改進生成對抗網(wǎng)絡(luò),所述改進生成對抗網(wǎng)絡(luò)包括:
39、卷積層,從多視角圖片的綜合特征中提取局部圖片特征,捕獲低級圖片信息,將輸入的高維特征映射到低維的特征圖;
40、批歸一化層,對中間層輸出進行歸一化;
41、注意力機制層,對圖片中的關(guān)鍵區(qū)域進行加權(quán)處理;
42、解碼層,將卷積層和注意力機制層優(yōu)化的特征映射回高維圖片空間,解碼層通過反卷積操作將特征圖恢復(fù)為最終生成的圖片,并通過上采樣和轉(zhuǎn)置卷積生成圖片;
43、生成器輸出層,輸出生成的圖片;
44、判別器,負責(zé)判定生成器生成的圖片是否接近真實圖片,對比真實圖片與生成圖片之間的差異,輸出真假評分;
45、s52、接收多視角圖片的綜合特征,將多視角圖片的綜合特征輸入至改進生成對抗網(wǎng)絡(luò)的卷積層:
46、;
47、其中,表示第層的輸出特征圖,表示第層卷積核的權(quán)重矩陣,表示第層卷積的偏置向量,表示第層的輸出特征圖,當(dāng)時,即表示輸入的多視角圖片的綜合特征,conv2d表示二維卷積計算操作,表示輸入的多視角圖片的綜合特征;
48、s53、基于輸出特征圖生成查詢矩陣和鍵矩陣:
49、;
50、其中,q表示查詢矩陣,k表示鍵矩陣,表示第層的輸出特征圖,和表示權(quán)重矩陣;
51、s54、通過計算查詢矩陣與鍵矩陣的點積,得到注意力權(quán)重矩陣,進行歸一化處理,將注意力權(quán)重矩陣a與輸入特征圖結(jié)合,得到加權(quán)的輸出特征圖:
52、;
53、;
54、其中,a表示注意力權(quán)重矩陣,表示鍵矩陣的轉(zhuǎn)置,d表示查詢和鍵的維度,softmax表示歸一化,表示加權(quán)的輸出特征圖,v表示值矩陣,表示值矩陣的權(quán)重矩陣;
55、s55、通過解碼層將從注意力機制得到的特征圖解碼為圖片輸出,所述解碼層采用上采樣和卷積操作,包括兩個階段:
56、第一階段,利用反卷積層對輸入的特征圖進行上采樣,恢復(fù)圖片的空間尺寸:
57、;
58、其中,表示恢復(fù)的圖片,deconv表示反卷積操作,和分別表示反卷積的權(quán)重矩陣和偏置項;
59、第二階段,通過激活函數(shù)對恢復(fù)的圖片進行處理,輸出解碼后的圖片:
60、;
61、其中,y表示處理后的圖片,tanh表示非線性激活函數(shù);
62、s56、將解碼后的圖片輸入到判別器中,所述判別器包括卷積層、激活函數(shù)和全連接層,所述判別器的輸出是一個介于0和1之間的值:
63、;
64、其中,d(x)表示判別器的輸出;
65、s57、使用交叉熵損失構(gòu)建判別器的損失函數(shù):
66、;
67、其中,d(x)表示判別器對真實圖片的輸出,d(y)表示判別器對生成圖片的輸出,x表示真實圖片,y表示生成圖片,表示數(shù)據(jù)分布,表示生成分布,表示數(shù)據(jù)分布的期望,表示生成分布的期望,表示判別器的損失函數(shù);
68、s58、使用反向傳播和梯度下降更新生成器和判別器的參數(shù),最小化真實圖片與生成圖片之間的差異,最終輸出生成的圖片數(shù)據(jù)。
69、本發(fā)明的有益效果是:
70、首先,在特征提取和融合過程中,本發(fā)明通過引入改進的resnet34網(wǎng)絡(luò),并結(jié)合注意力機制優(yōu)化特征提取過程,有效克服了傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)在多視角圖像處理中存在的不足,傳統(tǒng)的卷積神經(jīng)網(wǎng)絡(luò)通常在特征提取時對不同視角之間的差異捕捉不完全,導(dǎo)致圖像特征的表達不夠全面,而通過改進的resnet34網(wǎng)絡(luò),在每個殘差塊中引入可變權(quán)重的殘差連接,并結(jié)合注意力機制對關(guān)鍵區(qū)域進行加權(quán),使得不同視角圖像的特征能夠得到更加精確的提取和融合。該方法不僅提高了特征提取的精度,還優(yōu)化了多視角圖像的空間信息感知能力,有效提升了圖像重建的質(zhì)量。
71、其次,在圖像重建階段,本發(fā)明通過采用改進生成對抗網(wǎng)絡(luò)進行圖像三維重建,相較于傳統(tǒng)的生成對抗網(wǎng)絡(luò)方法,具有更高的穩(wěn)定性和更強的圖像生成能力。現(xiàn)有的gan模型在圖像生成過程中,往往由于訓(xùn)練不穩(wěn)定或模式崩潰問題,導(dǎo)致生成的圖像質(zhì)量不穩(wěn)定,甚至出現(xiàn)明顯的失真。通過改進生成對抗網(wǎng)絡(luò)的結(jié)構(gòu),結(jié)合多視角圖像的綜合特征進行訓(xùn)練,能夠有效提高生成圖像的質(zhì)量和細節(jié),確保最終輸出的圖像更為真實、清晰。此外,優(yōu)化后的生成器通過上采樣和轉(zhuǎn)置卷積等操作,將多視角圖像的特征圖映射回高維空間,并通過判別器的對抗訓(xùn)練進一步提升圖像的細節(jié)表現(xiàn),使得圖像生成更加精細且符合實際需求。
72、最后,本發(fā)明通過深度學(xué)習(xí)優(yōu)化圖像特征提取和重建過程,在提高圖像質(zhì)量的同時,大幅度降低了人工干預(yù)的需求,整個過程不僅提升了圖像采集的精度與效率,還增強了圖像數(shù)據(jù)的可靠性和多樣性,使得生成的圖像更加全面、準(zhǔn)確地反映實際場景。
- 還沒有人留言評論。精彩留言會獲得點贊!