一種集群選舉方法及系統與流程
本發明涉及大數據運算領域,更具體地,涉及一種大數據運算的集群選舉方法及系統。
背景技術:
現在的大數據運算各有各的集群處理模式,算法不統一。公司自研的系統甚至沒有做集群,導致當系統崩潰后無法正常工作,影響大數據處理的正常執行。而且現存很多老系統都沒有考慮高可用集群處理方案,或者只采用簡單的vrrp協議進行高可用處理。當虛擬化系統中的控制節點或者網絡節點因為各種原因停止服務時,系統就無法控制虛擬化系統的計算機網絡功能,只能等待服務的恢復。而使用vrrp的方案,一般只有兩臺機器執行熱備模式,容易發生腦裂導致ip沖突,無法正常服務。
技術實現要素:
本發明為克服上述現有技術所述的至少一種缺陷(不足),提供一種使普通非高可用的系統實現高可用功能的集群選舉方法。
本發明還提供一種使普通非高可用的系統實現高可用功能的集群選舉系統。
為解決上述技術問題,本發明的技術方案如下:
一種集群選舉方法,包括:
從服務器無法獲得主服務器的心跳時,從服務器的狀態改為候選服務器,并向其余服務器發出請求選為主服務器的投票請求;
當候選服務器收到超過預設閾值數量的服務器投票,則選舉成為主服務器并更改狀態為主服務器;
當候選服務器在等待投票結果時其他服務器成為主服務器,則候選服務器更改狀態為從服務器;
當沒有任一候選服務器選舉為主服務器時,候選服務器重新發送投票請求直至有一候選服務器成為主服務器為止。
本發明在主服務器停止服務時,采用投票選舉的方式來重新選出主服務器,其他服務器作為從服務器,該方法在不影響原有系統功能前提下,改變原有系統的部署方案,使用分布式選舉協議來組成各種應用集群,使本來不具備高可用的系統具備了高可用能力,此方法對于簡單的應用系統非常適用,不需要在設計階段過多地考慮高可用方案,集中業務實現。
上述方案中,當候選服務器選舉成為主服務器并更改狀態為主服務器后,該新主服務器還向其他服務器發送主服務器心跳,其他服務器收到心跳后更改狀態為從服務器。新主服務器通過發出心跳方式來通知其他服務器,其他服務器可以及時將狀態更改為從服務器,使新的主服務器能夠及時接管服務,使系統恢復正常的工作狀態。
上述方案中,所述預設閾值數量為所有服務器的一半。
上述方案中,候選服務器更改狀態為從服務器后,主服務器和從服務器同步狀態信息。狀態信息的同步不但可以使系統能夠恢復到正常狀態,而且還能夠使系統恢復到停止服務前的狀態,保證信息的完整性。
一種集群選舉系統,包括服務器,服務器包括:
狀態更改模塊,用于當服務器無法獲得主服務器的心跳時,更改狀態為候選服務器;
投票請求模塊,用于向其余服務器發出請求選為主服務器的投票請求;
投票結果接收模塊,用于接收服務器投票結果,當收到超過預設閾值數量的服務器投票時選舉成為主服務器并通知狀態更改模塊更改狀態為主服務器;
狀態更改模塊還用于服務器選舉成為主服務器時更改狀態為主服務器;
主服務器通知模塊,用于獲知其他服務器成為主服務器并通知狀態更改模塊;
狀態更改模塊還用于當獲知其他服務器成為主服務器后更改狀態為從服務器。
本發明的系統在主服務器停止服務時,利用各個模塊基于投票選舉的方式來重新選出主服務器,其他服務器作為從服務器,該系統在不影響原有系統功能前提下,改變原有系統的部署方案,使用投票請求模塊中的分布式選舉協議來組成各種應用集群,使本來不具備高可用的系統具備了高可用能力,此系統對于簡單的應用系統非常適用,不需要在設計階段過多地考慮高可用方案,集中業務實現。
上述方案中,投票請求模塊還用于當狀態更改模塊將狀態改為候選服務器后的一定時間內未再次更改狀態時,重新向其余服務器發出投票請求。設定重新投票請求機制,可以使得系統可以自發性地重新發出投票請求直至重新選出新的主服務器為止,保證系統在停止服務后能選出新服務器來重新啟動系統的服務。
上述方案中,服務器還包括:
心跳發送模塊,用于在狀態更改模塊更改狀態為主服務器后,向其他服務器發送主服務器心跳;
狀態更改模塊還用于在收到新主服務器發送的心跳后更改狀態為從服務器。
設置心跳發送模塊用于向等待選舉結果的服務器發出通知,使其他服務器能夠結束投票請求的過程,重新修改狀態為從服務器,以確保及時重新啟動系統的服務。
上述方案中,所述預設閾值數量為所有服務器的一半。
上述方案中,服務器還包括:
狀態同步模塊,用于在狀態更改模塊更改狀態為從服務器或主服務器后,與其他服務器進行狀態信息同步操作。狀態同步模塊的設置不但可以使系統能夠恢復到正常狀態,而且還能夠使系統恢復到停止服務前的狀態,保證信息的完整性。
與現有技術相比,本發明技術方案的有益效果是:
本發明使用分布式選舉協議來組成大數據運算的集群的高可用方案,其在不影響原有系統功能的前提下,稍微改變了原有系統的部署方案,通過協議選舉主服務器,其余服務器作為從服務器,當主服務器停止服務器時,從服務器沖洗選出主服務器,新的主服務器接管服務,使得普通非高可用的系統實現高可用功能,保證系統崩潰后能夠通過自發性的選舉來恢復系統的正常工作,保證了大數據處理的正常執行。對于簡單的應用系統尤其適用,不需要在設計階段過多考慮高可用方案,實用性強。
附圖說明
圖1為本發明一種集群選舉方法具體實施例的流程圖。
圖2為本發明一種集群選舉系統具體實施例的架構圖。
具體實施方式
附圖僅用于示例性說明,不能理解為對本專利的限制;
為了更好說明本實施例,附圖某些部件會有省略、放大或縮小,并不代表實際產品的尺寸;
對于本領域技術人員來說,附圖中某些公知結構及其說明可能省略是可以理解的。
在本發明的描述中,在本發明的描述中,除非另有說明,“多個”的含義是兩個或兩個以上。
在本發明的描述中,需要說明的是,除非另有明確的規定和限定,術語“安裝”、“連接”應做廣義理解,例如,可以是固定連接,也可以是可拆卸連接,或一體地連接;可以是機械連接,也可以是電連接;可以是直接相連,也可以是通過中間媒介間接連接,可以說兩個元件內部的連通。對于本領域的普通技術人員而言,可以具體情況理解上述術語在本發明的具體含義。
下面結合附圖和實施例對本發明的技術方案做進一步的說明。
實施例1
如圖1所示,為本發明一種集群選舉方法具體實施例的流程圖。參見圖1,本具體實施例一種集群選舉方法的具體步驟包括:
S1.從服務器無法獲得主服務器的心跳時,所有從服務器的狀態改為候選服務器,并向其余服務器發出請求選為主服務器的投票請求。
通常系統啟動或者主服務器掉線時都會導致從服務器無法獲得主服務器的心跳,此時可以通過預設一定的時間閾值或者無法獲得主服務器心跳的次數來給予從服務器等待主服務器心跳的時間,當超過一定的時間閾值或者超過一定次數無法獲得主服務器心跳(如3次無法獲得主服務器心跳)后從服務器仍無法獲得主服務器的心跳時,從服務器即可啟動狀態更改步驟,將其自身狀態修改為候選服務器,并各自向除自身之外的其他服務器發出投票請求。時間閾值的設定一方面可以保證等待心跳的時間,另一方面又可以保證從服務器能夠及時地啟動投票選舉步驟來重新選出主服務器,以保證系統能夠在崩潰后的一定時間內及時恢復正常工作。
S2.當候選服務器收到超過預設閾值數量的服務器投票,則選舉成為主服務器并更改狀態為主服務器;預設的閾值數量可以預先設定,比如設定預設的閾值數量為所有服務器數量的一半,由于此時原主服務器處于掉線狀態,因此,所述所有服務器指的是除掉掉線的原主服務器外的其他所有服務器。通常從服務器發出投票包,其余候選服務器收到投票包后進行是否同意的投票,當總數量超過一半的服務器同意則對應的從服務器被選舉為新的主服務器。
當候選服務器在等待投票結果時其他服務器成為主服務器,則候選服務器更改狀態為從服務器;
當沒有任一候選服務器選舉為主服務器時,候選服務器重新發送投票請求重新執行步驟S2。
在步驟S2中,當候選服務器選舉成為主服務器并更改狀態為主服務器后還執行步驟S3:
S3.該新主服務器還向其他服務器發送主服務器心跳,其他服務器收到心跳后更改狀態為從服務器。此步驟的設置目的在于通過發出心跳方式來通知其他服務器已經選出主服務器,其他服務器可以及時將狀態更改為從服務器,使新的主服務器能夠及時接管服務,使系統恢復正常的工作狀態。
在步驟S3中,候選服務器更改狀態為從服務器后,主服務器和從服務器同步狀態信息。狀態信息的同步指的是主服務器選舉成功后,向各個從服務器同步來自應用系統的狀態信息。狀態信息的同步不但可以使系統能夠恢復到正常狀態,而且還能夠使系統恢復到停止服務前的狀態,保證信息的完整性。
實施例2
本發明還提供一種集群選舉系統來實現非高可用系統的高可用方案。
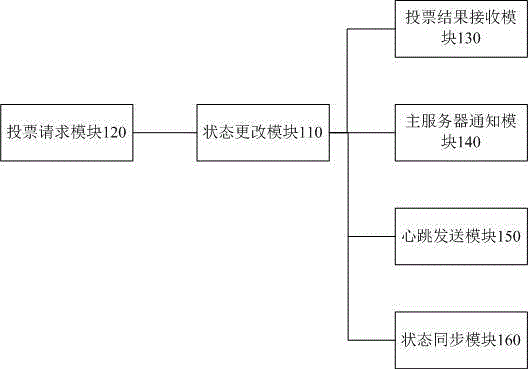
如圖2所示,為本具體實施例一種集群選舉系統的架構圖。參見圖2,本具體實施例一種集群選舉系統具體包括服務器,服務器可以通過選定或者選舉的方式來確定主服務器和從服務器,當主服務器停止服務器時,可以利用本發明的系統來沖洗選舉出主服務器來提供服務。具體地,服務器包括:
狀態更改模塊110,用于當服務器無法獲得主服務器的心跳時,更改狀態為候選服務器;服務器的原狀態為從服務器狀態,系統啟動或者主服務器掉線時都會導致從服務器無法獲得主服務器的心跳,在無法獲得主服務器心跳后,狀態更改模塊110可以通過預設一定的時間閾值來等待主服務器心跳,當超過一定的時間閾值后服務器仍無法獲得主服務器的心跳時,狀態更改模塊110即可進行狀態更改,將服務器的狀態修改為候選服務器。
投票請求模塊120,用于向其余服務器發出請求選為主服務器的投票請求;
投票結果接收模塊130,用于接收服務器投票結果,當收到超過預設閾值數量的服務器投票時將本服務器選舉成為主服務器并通知狀態更改模塊110更改狀態為主服務器;預設的閾值數量可以預先設定,比如設定預設的閾值數量為所有服務器數量的一半。
狀態更改模塊110還用于服務器選舉成為主服務器時更改狀態為主服務器;
主服務器通知模塊140,用于獲知其他服務器成為主服務器并通知狀態更改模塊110;
狀態更改模塊110還用于當獲知其他服務器成為主服務器后更改狀態為從服務器。
考慮到投票選舉并非每次都能夠成功,比如沒有一個服務器收到的服務器投票超過半數服務器時,則會導致沒有一個服務器成功選舉為主服務器。因此,投票請求模塊120還用于當狀態更改模塊110將狀態改為候選服務器后的一定時間內未再次更改狀態時,重新向其余服務器發出投票請求。服務器狀態未再次更改表示仍然處于候選服務器狀態,并未更改為從服務器狀態或者主服務器狀態,即表示仍沒有一個服務器被選舉為新的主服務器。設定重新投票請求機制,可以使得系統可以自發性地重新發出投票請求直至重新選出新的主服務器為止,保證系統在停止服務后能選出新服務器來重新啟動系統的服務。
為了能夠及時通知其他服務器已經選舉出新的主服務器,服務器中還設置了心跳發送模塊150,用于在狀態更改模塊110更改狀態為主服務器后,向其他服務器發送主服務器心跳;
狀態更改模塊110還用于在收到新主服務器發送的心跳后更改狀態為從服務器。
設置心跳發送模塊150用于向等待選舉結果的服務器發出通知,使其他服務器能夠結束投票請求的過程,重新修改狀態為從服務器,以確保及時重新啟動系統的服務。
具體實施過程中,服務器中還包括狀態同步模塊160,用于在狀態更改模塊110更改狀態為從服務器或主服務器后,與其他服務器進行狀態信息同步操作。狀態同步模塊的設置不但可以使系統能夠恢復到正常狀態,而且還能夠使系統恢復到停止服務前的狀態,保證信息的完整性。
本發明使用分布式選舉協議來組成大數據運算的集群的高可用方案,其在不影響原有系統功能的前提下,稍微改變了原有系統的部署方案,通過協議選舉主服務器,其余服務器作為從服務器,當主服務器停止服務器時,從服務器沖洗選出主服務器,新的主服務器接管服務,使得普通非高可用的系統實現高可用功能,保證系統崩潰后能夠通過自發性的選舉來恢復系統的正常工作,保證了大數據處理的正常執行。對于簡單的應用系統尤其適用,不需要在設計階段過多考慮高可用方案,實用性強。
相同或相似的標號對應相同或相似的部件;
附圖中描述位置關系的用于僅用于示例性說明,不能理解為對本專利的限制;
顯然,本發明的上述實施例僅僅是為清楚地說明本發明所作的舉例,而并非是對本發明的實施方式的限定。對于所屬領域的普通技術人員來說,在上述說明的基礎上還可以做出其它不同形式的變化或變動。這里無需也無法對所有的實施方式予以窮舉。凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明權利要求的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!