一種終端音頻播放方法及系統與流程
本發明涉及終端領域,特別涉及一種終端音頻播放方法及系統。
背景技術:
終端(Terminal)也稱終端設備,是計算機網絡中處于網絡最外圍的設備。終端包括計算機、電視機等電子設備,也包括移動終端,譬如手機、平板電腦等電子設備。在日常生活中,人們常用的是移動終端,即可以在移動中使用的計算機設備,其移動性主要體現在移動通信能力和便攜化體積。廣義上講包括手機、筆記本、POS機甚至包括車載電腦。移動終端不僅可以通話、視頻通話、拍照、聽音樂、看視頻、玩游戲,而且可以實現包括定位、信息處理、指紋掃描、身份證掃描、條碼掃描、RFID掃描、IC卡掃描以及酒精含量檢測等豐富的功能。
而現有終端在打電話和聽錄音、視頻的時候,有時候由于環境背景音過大,導致無法聽清說話者的聲音,聲音清晰度不高,給用戶帶來了大大的不便。
因而現有技術還有待改進和提高。
技術實現要素:
鑒于上述現有技術的不足之處,本發明的目的在于提供一種終端音頻播放方法及系統,旨在解決現有終端的聲音清晰度不高的問題。
為了達到上述目的,本發明采取了以下技術方案:
一種終端音頻播放方法,其中,包括:
A、對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征;
B、將所述聲紋特征與預先設置的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。
所述的終端音頻播放方法,其中,在所述步驟A之前,還包括:
A11、預先對多個聲源進行標記,并對各個聲源的音頻數據進行聲紋分析,得到對應的聲紋特征;
A12、將各個聲紋特征及其對應聲源的聲源標記關聯存儲,生成所述聲紋特征庫。
所述的終端音頻播放方法,其中,所述步驟A具體包括:
A21、對所述聲紋特征庫中聲源標記進行選擇;
A22、對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。
所述的終端音頻播放方法,其中,所述步驟B具體包括:
B1、將所述聲紋特征與選擇的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。
所述的終端音頻播放方法,其中,所述步驟A具體包括:
A31、每隔預定時間對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。
一種終端音頻播放系統,其中,包括:
聲紋識別模塊,用于對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征;
聲紋匹配模塊,用于將所述聲紋特征與預先設置的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。
所述的終端音頻播放系統,其中,還包括:
標記分析模塊,用于預先對多個聲源進行標記,并對各個聲源的音頻數據進行聲紋分析,得到對應的聲紋特征;
存儲模塊,用于將各個聲紋特征及其對應聲源的聲源標記關聯存儲,生成所述聲紋特征庫。
所述的終端音頻播放系統,其中,所述聲紋識別模塊包括:
聲源選擇單元,用于對所述聲紋特征庫中聲源標記進行選擇;
聲紋分析單元,用于對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。
所述的終端音頻播放系統,其中,所述聲紋匹配模塊包括:
聲紋匹配單元,用于將所述聲紋特征與選擇的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。
所述的終端音頻播放系統,其中,所述聲紋識別模塊,還用于每隔預定時間對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。
相較于現有技術,本發明提供的終端音頻播放方法及系統,通過對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征;將所述聲紋特征與預先設置的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量;利用聲紋識別技術,確認當前的音頻數據與預存的聲紋特征不匹配時,則降低環境背景音的音量,以達到當前音頻數據的音量明顯高于環境背景音的效果,提高了聲音清晰度,帶來了極大的方便。
附圖說明
圖1為本發明提供的終端音頻播放方法的方法流程圖。
圖2為本發明提供的終端音頻播放系統的結構框圖。
具體實施方式
本發明提供一種終端音頻播放方法及系統。為使本發明的目的、技術方案及效果更加清楚、明確,以下參照附圖并舉實施例對本發明進一步詳細說明。應當理解,此處所描述的具體實施例僅用以解釋本發明,并不用于限定本發明。
本發明提供一種終端音頻播放方法,請參閱圖1,所述終端音頻播放方法,包括以下步驟:
S100、對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征;
S200、將所述聲紋特征與預先設置的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。
下面結合具體的實施例對上述步驟進行詳細的描述。
在所述步驟S100中,對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。本發明的終端可為手機、平板電腦、計算機等,對終端待播放的音頻數據進行聲紋分析,關于聲紋分析此乃現有技術,這樣便可得到待播放的音頻數據的聲紋特征。所謂聲紋(Voiceprint),是用電聲學儀器顯示的攜帶言語信息的聲波頻譜。人類語言的產生是人體語言中樞與發音器官之間一個復雜的生理物理過程,人在講話時使用的發聲器官--舌、牙齒、喉頭、肺、鼻腔在尺寸和形態方面每個人的差異很大,所以任何兩個人的聲紋圖譜都有差異。這樣,不僅指紋,聲紋也可應用于生物識別領域之中,特別是人物識別。
然后在步驟S200中,將其與預先設置的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。也就是說,如果待播放的音頻數據的聲紋特征沒有在預先存儲的聲紋特征庫中,那么就降低該音頻數據的音量,如果在的話,就保持原有音量不變。這樣,便可將不匹配的音頻數據的播放聲音降低,匹配的音頻數據的播放聲音不變,便可突出了匹配的音頻數據聲音,從而提高了聲音清晰度。
舉例來說,若聲紋特征庫中存有音頻中各個聲源(也就是各個人物)的聲紋特征,在音頻播放時,若待播放的音頻數據得到的聲紋特征與聲紋特征庫不匹配,則表明該待播放的音頻數據沒有包含上述各個聲源(也就是各個人物)的聲音,則該音頻數據為環境背景音,將該音頻數據的音頻音量降低,則對應降低了環境背景音,相對地達到了突出人物聲音的效果。關于降低音量具體降低多少,可根據實際需要進行時設置,也可直接靜音,還可采用降低固定音量值。
請繼續參閱圖1,優選地,在所述步驟S100之前,還包括:
S111、預先對多個聲源進行標記,并對各個聲源的音頻數據進行聲紋分析,得到對應的聲紋特征;
S112、將各個聲紋特征及其對應聲源的聲源標記關聯存儲,生成所述聲紋特征庫。
具體來說,關于聲紋特征庫,可采用上述步驟得到,預先采集多個聲源對應的聲紋特征,并且對各個聲源對應進行標記,將標記與聲紋特征關聯存儲,從而得到聲紋特征庫。所述標記可采用文字、圖案、符號和/或數字等。在實際應用時,可采用各個聲源的名字作為標記,將其名字與對應的聲紋特征關聯存儲。譬如通訊錄中各個人物名字及其對應的聲紋特征都存儲在聲紋特征庫中。
進一步地,所述步驟S100具體包括:
S121、對所述聲紋特征庫中聲源標記進行選擇;
S122、對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。
具體來說,就是對聲紋特征庫中的聲源標記進行選擇,實際應用時,可為接受用戶對各個名字的選擇,便可從聲紋特征庫中找到對應的聲紋特征。
進一步地,所述步驟S200具體包括:
S201、將所述聲紋特征與選擇的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。也就是說,識別待播放的音頻數據的聲紋特征,將其與用戶選擇的聲紋特征進行匹配,判斷是否是用戶所期待的或者說用戶所選擇的聲音,若為是,則正常播放,若為否,則調低該音頻數據音量。這樣,可以使得用戶的目標聲源的音量明顯高于環境背景音,提高了聲音清晰度。
優選地,所述步驟S100具體包括:
S131、每隔預定時間對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。具體來說,就是每隔一定時間就對終端待播放的音頻數據進行聲紋分析,然后進行匹配,如果不匹配,表明可能為聲源的環境背景音,進行降音處理;若匹配,則正常播放;這樣,便達到了突顯聲源(也就是正確說話人)聲音的效果。關于預定時間,可根據實際需要進行設置。優選地,由于音頻一幀一幀的數據,可對每一幀的待播放音頻數據進行聲紋分析。
以下以一應用實施例對本發明詳細闡述如下。用戶在終端設備上預存多個說話者(即上述的聲源)的聲紋特征和說話者姓名(即上述的聲源標記)。如果是音視頻播放過程,用戶選擇需要確認的多個說話者的聲紋特征。如果是電話過程,則可根據通訊錄中的姓名匹配終端設備預存的說話者姓名,從而獲取需要確認的說話者聲紋特征。啟動聲紋識別模塊,獲取聲音,該聲音可來自音頻文件,也可來自外界現場聲音。啟動聲紋特征分析。再將獲取的聲紋特征與用戶選擇的說話者聲紋特征相匹配。匹配不成功,則不是說話者說的話,則降低此幀音頻音量。匹配成功,則啟動標記該說話內容的說話者姓名。在音視頻播放或電話的每一幀播放時,判斷該幀是說話人說的話,還是環境背景音。如果確認是說話者說的話,則保持此幀音頻音量為音頻播放音量。如果不是說話者說的話,則降低此幀音頻音量,從而達到了突出說話人聲音的效果。
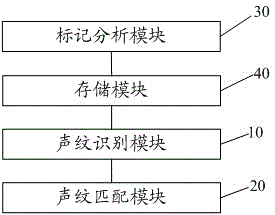
基于上述實施例提供的終端音頻播放方法,本發明還提供一種終端音頻播放系統。請參閱圖2,所述終端音頻播放系統包括:
聲紋識別模塊10,用于對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征;
聲紋匹配模塊20,用于將所述聲紋特征與預先設置的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。
請繼續參閱圖2,進一步地,所述的終端音頻播放系統,還包括:
標記分析模塊30,用于預先對多個聲源進行標記,并對各個聲源的音頻數據進行聲紋分析,得到對應的聲紋特征;
存儲模塊40,用于將各個聲紋特征及其對應聲源的聲源標記關聯存儲,生成所述聲紋特征庫。
進一步地,所述聲紋識別模塊10包括:
聲源選擇單元,用于對所述聲紋特征庫中聲源標記進行選擇;
聲紋分析單元,用于對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。
進一步地,所述聲紋匹配模塊20包括:
聲紋匹配單元,用于將所述聲紋特征與選擇的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量。
進一步地,所述聲紋識別模塊10,還用于每隔預定時間對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征。
由于所述終端音頻播放系統的具體原理和詳細技術特征在上述終端音頻播放方法實施例中已詳細闡述,在此不再贅述。
上述功能模塊的劃分僅用以舉例說明,在實際應用中,可以根據需要將上述功能分配由不同的功能模塊來完成,即劃分成不同的功能模塊,來完成上述描述的全部或部分功能。
本領域普通技術人員可以理解上述實施例方法中的全部或部分流程,是可以通過計算機(或移動終端)程序來指令相關的硬件完成,所述的計算機(或移動終端)程序可存儲于一計算機(或移動終端)可讀取存儲介質中,程序在執行時,可包括上述各方法的實施例的流程。其中的存儲介質可以為磁碟、光盤、只讀存儲記憶體(ROM)或隨機存儲記憶體(RAM)等。譬如,聲紋特征庫也可存儲在與終端數據交互的服務器中。
綜上所述,本發明提供的一種終端音頻播放方法及系統,通過對終端待播放的音頻數據進行聲紋分析,得到對應的聲紋特征;將所述聲紋特征與預先設置的聲紋特征庫進行匹配,若匹配成功,則保持所述音頻數據的播放音量;若匹配不成功,則降低所述音頻數據的播放音量;利用聲紋識別技術,確認當前的音頻數據與預存的聲紋特征不匹配時,則降低環境背景音的音量,以達到當前音頻數據的音量明顯高于環境背景音的效果,提高了聲音清晰度,帶來了極大的方便。
可以理解的是,對本領域普通技術人員來說,可以根據本發明的技術方案及其發明構思加以等同替換或改變,而所有這些改變或替換都應屬于本發明所附的權利要求的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!