基于可疑行為識別的通訊詐騙實時檢測方法和系統與流程
本發明涉及通訊詐騙檢測領域,尤其涉及一種針對移動電話端的基于機器學習分析可疑行為的通訊詐騙實時檢測方法和系統。
背景技術:
近幾年來,得益于電信領域的高速發展,移動通訊已經成為了人們生活和工作中不可缺少的一部分。據工信部統計,截止到2016年7月份,中國移動電話的總用戶數達到13.04億戶,其中包含4g用戶數6.46億戶。然而,伴隨著移動通訊帶來的不僅是便利,也同樣帶來了諸多問題。
移動通訊技術在給我們工作生活帶來便利的同時,也給不法分子的行騙打開了方便之門,這其中就以通訊詐騙最為普遍。通訊詐騙指不法分子通過電話、短信等移動通訊方式,設計騙局,通過編造的虛假內容騙取受騙人的信任后,向受騙人索取個人隱私信息或誘導受騙人執行特定的指令,最終給受騙人帶來相應的損失。通訊詐騙直接威脅到了民眾的信息與財產的安全,給我們的生活造成了極大的安全隱患。大部分通訊詐騙的案例當中,當行騙人詐騙成功后,相關機構很難從詐騙案件中留下的線索去追回損失,因為詐騙人通常通過一些無記名、冒名或公共電話行騙,并且留下的信息也是經過層層設計,很難從中追查到具體的線索。
面對猖狂的通訊詐騙,目前的防詐騙手段主要集中于提高民眾自身警惕性和提升防詐騙打擊力度兩方面。其中,提高民眾自身警惕性的主要方法是公安機構及相關電信機構,定期整理通訊詐騙的案件,分析其行騙流程后將其特征整理為教育資料,再通過電視、講座、宣傳冊以及app等形式去提醒、教育民眾,以此提高民眾的防詐騙意識,使得民眾在收到類似詐騙電話時能夠保持足夠的警惕性,減少不必要的損失。而在提升打擊力度方面,主要是電信機構配合公安機關,加強監測機制,利用立法、建立黑名單等手段,減少通訊詐騙案件的發生。
然而,面對通訊詐騙手段的層出不窮和手法的不斷更新,上述現有方案都不能及時有效的跟上行騙者的步伐。提高民眾自身的警惕性依賴于相關機構對詐騙案例信息的分析整理,以及宣傳教育流程,一般而言,案例資料的整理是在詐騙案件發生后才能進行,加上宣傳教育也要花費較長的時間,這無疑帶給騙子一個空窗期,只要不斷改變行騙流程,就可以較為完美的繞開這種防詐騙方式。同時,民眾自身的文化修養層次不齊,難以保證每一個人都能有一個較高的警惕性。而在提升打擊力度方面,現有的方法依賴于政府機構和商業公司的配合,且需要投入大量的人力物力,如果要通過該方法快速且有效的打擊通訊詐騙,需要消耗大量的社會資源,而如果在此投入過多的資源,則會嚴重影響整個電信行業的正常發展。因此,目前尚缺乏防通訊詐騙的技術解決方案,能夠快速有效且不需要消耗較多社會資源,實現對日益猖狂的通訊詐騙進行有力打擊。
技術實現要素:
為了克服上述現有技術的不足,本發明提供了一種基于可疑行為識別的通訊詐騙實時檢測方法和系統,通過分析陌生來電的通話語音和短信內容,檢測其異常的、可疑的行為來進行詐騙預測。其中,來電語音通過語音轉文字技術將來電主叫方的通話內容轉變成文字信息,與短信內容同時使用自然語言處理技術提取動作行為特征,并判斷對話中出現的動作行為特征中是否有包含隱私信息詢問和惡意命令等在內的可疑行為的可能性,若存在一定數量的可疑行為則會實時提醒用戶。本發明所實現的實時詐騙通話識別方法,可減少防范意識較差的用戶被欺詐的可能性。
本發明提供的技術方案是:
一種基于可疑行為識別的通訊詐騙實時檢測方法,包括離線模型訓練階段與實時詐騙檢測階段;
離線模型訓練階段包含動作特征識別訓練、動作特征風險預測訓練兩部分。在動作特征識別訓練訓練中,接收經過時間分段標注的用戶語音、短信以及其參照結果,其中語音內容需要經過預處理,使用語音轉文本工具進行轉換,得到一個語音轉文字的信息,本方法將文本化的語音和短信,合并作為動作特征識別訓練的數據集。在訓練時首先對輸入的文本信息采用hmm、crf等機器學習算法針對文本進行分詞、詞性標注、語法樹分析以及實體識別的訓練并得到動作行為三元組,該元組包含動作的主體、動作的類型和實體信息三部分內容,用于表示雙方交流中出現的某一個動作行為的特征,識別出來的三元組使用輸入的參照結果來衡量準確度,最后得到一個可以用于識別文本中的動作特征識別模型。在動作特征風險預測的訓練方面,需要接收已經標注好風險值的動作特征三元組,以及可疑行為規則,使用線性回歸等機器學習方法進行訓練,得到動作特征風險預測模型。動作特征識別模型和動作特征風險預測模型在離線訓練好后,會集成在客戶端中實時使用。
實時通訊詐騙檢測階段通過監聽來電主叫方的通話語音和短信內容,并使用集成在客戶端中的已訓練好的離線模型來進行詐騙檢測。客戶端首先將語音內容轉換為文本,并連同短信內容一起轉化為時間序列的文本數據,使用離線訓練好的動作特征識別模型對這些文字內容進行分詞、詞性標注、語法樹分析的工作,并且輸出動作行為三元組,該序列中的所有文本都會進行如上的元組識別過程,隨后客戶端會使用離線計算好模型中的動作特征風險預測部分,計算當前行為的危險程度分值,每一個動作的危險程度分值按時間順序計算,根據場景模式的不同的,當分數達到一定的程度后,將會觸發相應的提醒事件。
針對上述基于可疑行為識別的防通訊詐騙方法,進一步地,所述離線模型第一階段的訓練,動作特征識別訓練的具體執行如下步驟:
11)接受通話錄音數據、短信及其兩者對應的標注內容信息,通過標注內容里的時間信息,將通話錄音進行分段,每段包含講話人完整的一句話,使用語音轉文本的工具將語音內容轉變為文本信息,稱為錄音文本;隨后結合時間信息,將語音轉換后的文本和短信放到一起,構成一個按照時間先后排序的時間序列數組,稱為通訊序列數據,并且關聯該通訊序列數據在標注信息中的動作實體信息(人工標注的正確動作實體信息,用于模型訓練),生成數據集。
12)將得到的數據集按照一定比例分為訓練集和測試集,并利用機器學習的方法訓練得到實體識別的模型,隨后使用測試集輸入到該模型中得到預測結果集,通過計算準確度、召回率以及f值的方式來評估識別效果。在實體識別模型的訓練過程中,需要使用步驟11)已標注好的參考實體信息,根據通訊時間訓練信息,利用實體識別模型學習如何從中提取動作實體信息。
13)多次重復步驟12),再選出f值最高的模型作為最終的實體識別模型。
在上述的動作特征識別訓練階段,進一步地,步驟12)所述的實體識別模型的內容包含:文本分詞、詞性標注、語法樹構建、實體搜索步驟。文本內容首先進行分詞,將文本內容轉化成詞的序列后進行詞性標注,使得每個詞都獲得一個對應的詞性,隨后根據分詞結果和詞性標注結果,生成語法樹,在語法樹上進行搜索存在的實體信息。
針對上述基于可疑行為識別的防通訊詐騙方法,進一步地,所述離線模型第二階段的訓練,動作特征風險預測訓練的具體執行步驟如下:
21)根據歷史案例和資料整理得到通訊詐騙中的關鍵特征規則,特征規則是由一系列的動作行為構成,其中每個動作行為都使用一個三元組來描述,該三元組包含動作的主體、動作的類型和實體信息。這些通訊詐騙中整理出來的關鍵規則特征,都需要通過具有相關領域知識的人員(專家)確定一個隔離閾值m,并且每一條規則手工指定一個危險分數,該分數需要大于m且小于等于1,表示其該規則可能出現在通訊詐騙中的可能性;
22)在整理通訊詐騙的關鍵特征規則以外,需要同時加入不存在通訊詐騙行為的正常規則,表達的方式和上述21)的方式一樣,無詐騙行為的征程規則仍然是由一系列的動作構成,每個動作使用一個三元組表示,同時這里的危險分數被設定為0;
23)將上述21)和22)的兩部分數據隨機排序并構成一個規則識別數據集,將混合后的規則識別數據集再次隨機劃分為訓練數據集和測試數據集,利用訓練數據集和機器學習的回歸方法訓練得到動作特征風險預測模型。然后將測試數據集輸入該預測模型得到預測結果集,通過計算r2和均方誤差來評估模型的預測效果。
24)多次重復步驟23),并選出r2最高且均方誤差最小的模型,作為最終的動作特征風險預測模型。
在上述的規則識別模型的訓練階段,進一步地,步驟21)和步驟22)所述的規則危險分數適用于表現該規則有詐騙風險的可信度,分數取值為0到1,0代表完全無風險,1代表風險最大,一般來說,為了保證有詐騙風險和無詐騙風險兩類規則的清楚區分,需要設立一個隔離閾值m,即存在詐騙風險的規則至少都會比沒有詐騙風險的規則在評分上高m。
所述23)中的r2計算方法如式1:
其中,yi表示危險分數的真實值,
均方誤差通過式2計算得到:
其中,n表示測試數據集中數據個數,常數2用于簡化后續求導運算,yi表示詐騙概率真實值,
針對上述基于可疑行為識別的防通訊詐騙方法,進一步地,所述實時通訊詐騙檢測的具體執行步驟如下:
31)用戶下載客戶端軟件,并且在移動電話端上完成相應的安裝、配置以及授權。
32)當用戶收到陌生來電時,客戶端軟件將會監聽來自主叫方的通話語音,以及短信信息。其中針對語音內容,客戶端軟件將會通過語音轉文字技術將語音轉變為對應的文字信息,隨后將這兩部分的文字信息進行相應的文字信息修正以及預處理,隨后按照時間發生先后實時的輸出。
33)當客戶端獲得當前實時輸出的文本信息后,利用已經離線訓練好的動作特征識別模型,在文字信息上抽取主叫方通話行為動作實體,抽取結果是三元組<動作主體,動作類型,實體信息>,該三元組表示主叫方和被叫方通話中出現的某一個具體動作以及動作的主體和對象。
34)客戶端把所有動作行為的特征三元組按照時間先后放入一個時序數組,稱為通訊序列數據,并且按順序利用離線訓練好的動作特征風險預測器進行檢索和預測,判別該動作其是否屬于某種可疑行為。
35)當客戶端軟件從時序行為數組中每識別出一個可疑行為后,將會同時獲得一個危險性打分,并累加到當前可疑行為總分當中,根據用戶設定的場景模式,當總分達到某設定的相應閾值時,會觸發相應等級的提醒事件。
36)云端服務器會定期的根據最新加入的數據,而對動作特征識別模型和動作特征風險預測器進行相應的更新,為了保證識別效果,客戶端將會定時同云端數據庫進行通訊,當云端離線模型發生變動后,客戶端將會從云端下載最新的模型文件替換本機客戶端的離線模型,保證實際使用的體驗。
一般地,訓練可以使用諸如adaboost、線性回歸、人工神經網絡ann等機器學習回歸方法,以及如word2vec、lda等在內的一些詞嵌入方法來將詞匯轉化成數值的方法來訓練該預測模型,此后,使用測試集輸入到訓練出的模型中得到預測結果,并且使用r2和均方誤差兩個指標來計算預測結果的好壞,評估模型的性能。
本發明還提供一種通訊詐騙實時檢測系統,是基于可疑行為識別的防通訊詐騙系統,包括:離線模型訓練模塊和實時防詐騙檢測模塊;其中:
離線模型訓練模塊包括動作特征識別訓練器和風險預測訓練器,動作特征識別訓練器對通話訓練數據和可疑規則數據進行預處理后,通過自然語言對文本內容進行分詞、詞性標注及語法樹構建;隨后從語法樹中提取文本中包含動作的三元組信息作為特征后,結合訓練數據已標注的特征共同進行訓練并得到動作特征識別模型;然后使用風險預測訓練器進行訓練,選取r2最高且平均誤差最小的模型作為最終訓練得到的風險預測模型。
實時防詐騙檢測模塊集成在客戶端軟件中,利用離線模型訓練模塊訓練得到的動作特征識別模型和風險預測模型,通過監聽用戶來電通話內容和短信內容,實時預測用戶通話詐騙的風險程度,并按照不同的場景規則,實時提醒用戶;包括語音轉文本模塊、對話內容處理模塊和實時詐騙識別模型;語音轉文本模塊用于來自通話中的語音內容經過語音轉文本,得到相應的通話文字內容;對話內容處理模塊用于接收語音轉文字模塊所識別得到的通話文字內容,并且監聽用戶的短信內容并將短信的內容按照時間插入到整個對話時間線當中,并設定所得到的對話的id(如設定m作為id的標識符);實時詐騙識別模型使用離線模塊訓練好的動作特征識別模型和風險預測模型,實時接收由對話內容處理模塊按照時間順序輸出的對話條目信息,實時地進行詐騙風險的預測:首先調用動作特征識別模型提取每一個對話條目的動作特征三元組;隨后使用風險預測模型實時計算該句對話的詐騙風險值;將每一個條目的風險值累加計算,得到在當前的最新時刻的分值,用于衡量總體風險值。
與現有技術相比,本發明的有益效果是:
本發明提供一種移動電話的基于可疑行為識別的防通訊詐騙的方法與系統,利用歷史通訊詐騙案例中學習詐騙識別特征規則,并且將此規則集成到客戶端軟件中,用戶可以通過在移動電話上安裝客戶端軟件的方式獲得通訊防詐騙保護。客戶端通過實時監聽陌生來電主叫方的語音和短信,其中語音部分通過語音轉文本工具轉化為文字信息后,使用動作特征識別模型獲得通訊內容對應的動作序列,其中每一個動作采用三元組的形式進行描述,通過這個動作序列和內置的動作特征風險預測器,實時評估通話及短信中每個動作特征存在詐騙行為的程度,如果當前的風險系數超過一定閾值,將會以合適的方式提醒用戶。本發明可以實現快速準確的防通訊詐騙檢測,提供給民眾一個通訊保障,減少民眾個人隱私流失的可能性,并保證了民眾的自有資金安全。
附圖說明
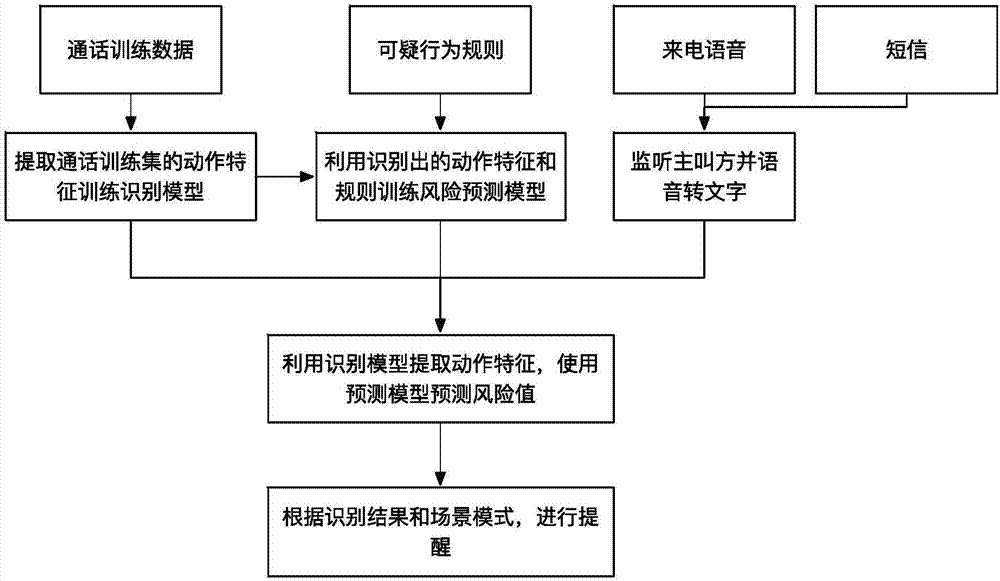
圖1是本發明提供的基于可疑行為識別的防通訊詐騙方法的流程框圖。
圖2是本發明實施例提供的基于可疑行為識別的防通訊詐騙系統的結構框圖。
圖3是本發明實施例根據文本語料進行分詞及語法分析過程的示意圖。
具體實施方式
下面結合附圖,通過實施例進一步描述本發明,但不以任何方式限制本發明的范圍。
本發明提供一種基于可疑行為識別的防通訊詐騙方法,通過識別通話語音以及短信內容,并使用自然語言處理技術提取主叫方語音當中的動作行為特征,每個行為特征以一個三元組的形式表達,通話中的所有行為特征都會一一進行可疑行為識別并且計算相應的風險預測分值,通過該分值實現通訊詐騙行為的檢測和提醒。
圖1是基于可疑行為識別的防通訊詐騙方法的流程框圖;圖2是基于可疑行為識別的通訊防詐騙系統的結構框圖。
實施例提供的基于可疑行為識別的防通訊詐騙系統以通話訓練數據、可疑行為規則、來電監聽語音以及短信內容作為數據輸入,包括離線訓練的動作特征識別模塊、風險預測模塊,以及實時的防詐騙檢測模塊。整個系統的流程如下:
系統流程分為離線模型訓練與實時防詐騙檢測階段:離線模型訓練階段主要是利用通話及短信訓練數據訓練動作特征識別模型,然后再結合可疑行為識別規則訓練風險預測模型;實時防詐騙檢測模塊利用上述的離線模型,根據來電主叫方的語音內容進行通訊詐騙檢測。
離線模型訓練階段首先根據已經標注好的通話及短信內容進行動作特征識別模型的訓練。在該階段,接收基于文本格式的對話信息,識別對話中出現的動作特征信息,提取特征后訓練識別模型。在訓練完成識別模型之后,再結合可疑行為規則數據,共同訓練一個利用動作特征和可疑行為規則實現的詐騙風險預測模型。動作特征識別模型和詐騙風險預測模型,將會集成到客戶端軟件中供用戶在通話中進行實時的詐騙檢測。
實時的防通訊詐騙模塊將會集成在手機客戶端當中,當安裝了客戶端的手機收到陌生來電時,客戶端軟件將會監聽對方的語音內容,通過語音轉文字技術將語音內容轉化為文字,并讀取相關號碼的來往短信內容,然后利用已經集成在客戶端中的動作特征識別模型提取動作特征,隨后把提取出來的動作特征輸入到風險預測模型,為每一個動作特征計算一個風險預測值,并且按照一定規則累加到總體風險值當中,而當總體風險值超過一定閾值后,將會觸發提醒事件,提醒注意用戶鑒別是否為詐騙電話。
具體地,系統的執行流程如圖1所示,包括如下步驟:
首先,離線模型分為基于通話訓練數據的動作特征提取識別模型,以及再加入可疑規則數據的風險預測模型。首先需要根據通話訓練數據對動作特征提取識別模型進行訓練,訓練完成后將該部分模型的輸出,以及可疑行為規則的數據,同時作為風險預測模型的輸入進行風險預測模型的訓練。當這兩部分的模型都訓練完成后,將會將其集成到客戶端軟件中,以提供客戶端軟件實時使用。
當用戶接聽了未知來電的時候,客戶端軟件將會自動監聽主叫方的通話內容以及短信內容,其中,通話語音將實時轉化為文字信息,語音和短信對應的文字信息則會調用集成在客戶端軟件中已訓練好的離線模型進行識別。首先,這些文字信息需要進行預處理,隨后調用動作識別模型,從文本內容中提取出所有的動作行為特征,隨后將這些動作行為特征傳遞給風險預測模塊,計算每一個動作行為特征的風險值。所有動作特征的風險值,都會按照場景模式的不同,累加到總的風險值中,當風險值達到場景模式中設置的某些閾值時,將會觸發對應的提醒事項。
本實施例提供的基于可疑行為識別的防通訊詐騙系統中,各個模塊的操作通過與其他相關模塊進行信息交互來完成,下面分別對不同的模塊進行具體說明。
s1)離線模型訓練模塊
離線訓練模塊的主要功能是接收通話訓練數據以及可疑規則數據,對數據進行預處理后,通過自然語言對文本內容進行分詞、詞性標注以及語法樹構建,通過動作特征識別器,使用語法樹的方式從中提取文本中包含動作的三元組信息作為特征,然后再使用風險預測訓練器進行訓練,并且選取r2最高且平均誤差最小的模型作為最終的離線模型。具體來說,該部分包含動作特征識別訓練器和風險預測訓練器兩個子模塊:
s11)動作特征識別器
動作特征識別器主要接受基于文本格式的已標注通話訓練數據。其中語音部分對應的數據維度如表1所示。
表1通話訓練數據格式舉例
如表1所示,語音部分對應的數據維度包括通話id、通話類型、開始時間、結束時間、通話內容以及動作特征。其中,通話id標識某一特定的通話,所有該通話內的數據都使用一個共同的id,通話內容是在該條數據的開始時間至結束時間之間,通話方在通話中說話的內容;動作特征是一個三元組,用于描述一個特定的動作的主體是誰、動作是什么的以及行動的對象是誰,三元組具體的內容和結構如表2所示。
表2動作三元組結構
接收到通話訓練數據,首先將文本形式的通話和短信內容進行分詞,并且進行詞性標注和詞與詞之間的語法樹分析(或稱為句子結構分析)。其中,分詞是指將文本內容從句子的形式,轉變為一個個獨立的詞語;詞性標注的工作是已為分好的詞語,標注特定的、符合其含義的詞性;語法樹分析的工作則是找到這句話的主語、賓語、謂語等語法結構,形成一個語法樹,圖3是通話文本內容經過文本處理后的示意圖。隨后,通過相應的算法從通話內容對應的文本樹當中抽取動作特征三元組,然后根據實際的動作特征三元組計算誤差值,并且整個流程通過不斷的訓練參數,最終選擇一個誤差最小的模型作為最后模型。
s12)風險預測訓練器
風險預測器的主要功能是,接收包含動作特征識別出動作特征三元組的通話訓練數據集和可疑行為規則并合并形成一個數據集,利用該數據集進行風險預測模型訓練。其中,特征規則的構成和上述的動作特征形式近似,都為一個三元組,且三元組的構造都是動作主體、動作內容和相關實體。特征規則三元組和動作特征三元組的區別在于動作特征三元組里面的內容是一些相對具體的詞,而特征規則的三元組里面的內容是泛化的、包含一系列具體的詞的集合。具體的特征規則構造結合和實例如表3所示。
表3特征規則三元組結構
訓練的過程,需要首先將上述通話訓練數據集和特征規則合并成一個數據集,合并后的數據集按照一定比例,劃分為訓練集和測試集,一般來說,訓練集的數據量要大于測試數據集的數據量,訓練集用于訓練預測模型,測試集用于檢驗模型的預測效果和調節參數。一般來說,訓練可以使用諸如adaboost、線性回歸、人工神經網絡ann等機器學習回歸方法,以及如word2vec、lda等在內的一些詞嵌入方法來將詞匯轉化成數值的方法來訓練該預測模型,此后,使用測試集輸入到訓練好的模型中得到預測結果,并且使用r2和均方誤差兩個指標來計算預測結果的好壞,評估模型的性能。
在本實施例當中,采用word2vec將文本內容轉換成數值特征,并用線性回歸方程的方法作為實例,說明風險預測模型的訓練過程。word2vec是一種利用深度學習的思想,通過模型的訓練,將文本內容簡化為k維向量空間中的向量,使得我們可以基于文本做包含聚類、同義詞等工作。
此處以采用線性回歸算法為例,說明詐騙風險預測模型的訓練步驟。
上述步驟8中,預測器根據當前的參數w和b估算預測值的公式為式3:
其中xj為當前訓練迭代時采樣的訓練數據集di中第j條訓練數據,w和b為線性回歸模型里面的兩個參數,w的維度和數據集里xj的特征維度一致,b為一個單值;
上述步驟10中,計算預測值和真實值的誤差的公式為式4:
其中εi表示風險預測期在當前訓練迭代時的誤差,
上述步驟11中,確定當且步驟更新參數時所使用的學習率的計算公式是式5:
lri=max(minlr,lr0*decay_ratei-1)(式5)
lri其中代表當前的學習率,max()代表選擇二者最高的函數,minlr為指定的一個最小學習率,而lr0代表初始學習率,decay_rate代表學習率的衰減程度。
上述步驟12中,根據當前學習率和誤差對參數w進行更新的公式是式6:
其中lri為當前的學習率,εi為當前的平均誤差,
上述步驟13中,根據但錢學習率和誤差對參數b進行更新的公式是式7:
其中lri為當前的學習率,εi為當前的平均誤差,
s2)實時防詐騙模塊
實時防詐騙模塊是集成在客戶端軟件當中的,實時防詐騙模塊利用離線訓練模塊訓練好的模型,并通過監聽用戶來電通話內容和短信內容,實時的預測用戶通話詐騙的風險程度,并按照不同的場景規則,實時的提醒用戶。
s21)語音轉文本模塊
實時防詐騙模塊的輸入來自用戶的通話或者短信,其中短信直接是以文本形式表述,不需要做額外的處理,但是來自通話中的語音內容并不能直接使用,必須要經過語音轉文本的工作。
語音轉文本模塊的語音輸入來自于客戶端監聽的語音對話內容,并且調用相應的算法和模型輸出識別的結果。輸出的結果,按照句子為單位,并且在構造id時使用d作為標識符,分別輸出這句話的開始時間、結束時間、文本內容、說話人等信息,具體的形式和示例如表4所示。
表4語音轉文本輸出示例
s22)對話內容處理模塊
為了提高識別的準確性,本發明提出的行為檢測模塊在檢測語音的同時,也會同時讀取短信內容,用以加強詐騙行為檢測的準確性。對話內容處理模塊接收語音轉文字模塊所識別出來文字內容,并且監聽用戶的短信內容并將短信的內容按照時間插入到整個對話時間線當中,并且以m作為id的標識符。例如,針對上述表4語音轉文本的通話識別結果,再經過對話內容處理模塊后,將會加入短信結果,并入表5所示。
表5對話內容處理后結果實例
s23)實時詐騙識別模型
實時詐騙識別模型是使用離線模塊訓練好的動作特征識別模型以及風險預測模型,并實時接收由對話內容處理模塊按照時間順序輸出的對話條目信息,實時的進行詐騙風險的預測。實施詐騙識別模型,首先調用動作特征識別模型提取每一個對話條目的動作特征三元組,隨后使用風險預測模型實時的計算該句對話的詐騙風險值。實時詐騙模型將會將每一個條目的風險值,按照一定方法累加計算,使得在當前的最新時刻都有一個可以衡量總體風險值的分值。實時防詐騙模型的識別示意可如表6所示:
表6實時防詐騙工作格式舉例
其中上表6中的對話內容部分同表5對應id,總風險預測值的計算方式如式8:
total_scoret=α*total_scoret-1+β*current_score(式8)
其中total_scoret表示在時刻時候的累加分數值,由上一時刻的分數total_scoret-1和當前時刻動作特征產生的分數current_score的加權求和而成,α和β分別為上一時刻分值total_scoret-1和當前新增特征對應分值current_score的系數。在表6中,α和β的系數分別為0.667和0.9。
下面結合實施例說明本發明的具體實施步驟:
在離線模型訓練階段,收集100條詐騙及100條正常的通訊對話內容(其中每個內容包含若干語音和短信),并將其作為訓練數據集。首先使用文本預處理模塊對這些數據進行預處理,然后將數據輸入到動作特征提取器進行訓練并且得到每個通訊記錄的動作特征集合,并將這些動作特征數據輸入到風險預測訓練器,并進行訓練。結合線性回歸的方法,設定迭代次數為2000,并使用如上的算法1進行訓練,最后選擇誤差最小時的參數作為最終參數,并得到模型,供客戶端使用。
在實時預測階段,客戶端(安卓)需要申請用戶手機的短信讀取權限以及電話聲音錄音權限,在用戶接收到未接來電時,將會通過這兩個權限獲取對話語音和短信,然后利用離線模型訓練得到的模型進行預測。
為驗證本方法的有效性,通過真人場景模擬的方式,模擬詐騙和非詐騙場景的對話與短信,并使用本文提出的方法進行預測,利用本文所提出的方法在詐騙場景的對話中均會發出相應的提示信息,說明本方法能夠識別一定程度的通訊詐騙信息。
需要注意的是,公布實施例的目的在于幫助進一步理解本發明,但是本領域的技術人員可以理解:在不脫離本發明及所附權利要求的精神和范圍內,各種替換和修改都是可能的。因此,本發明不應局限于實施例所公開的內容,本發明要求保護的范圍以權利要求書界定的范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!