一種基于流數據分析的Web攻擊實時在線檢測系統的制作方法
本發明涉及一種基于流數據分析的web攻擊實時在線檢測系統。
背景技術:
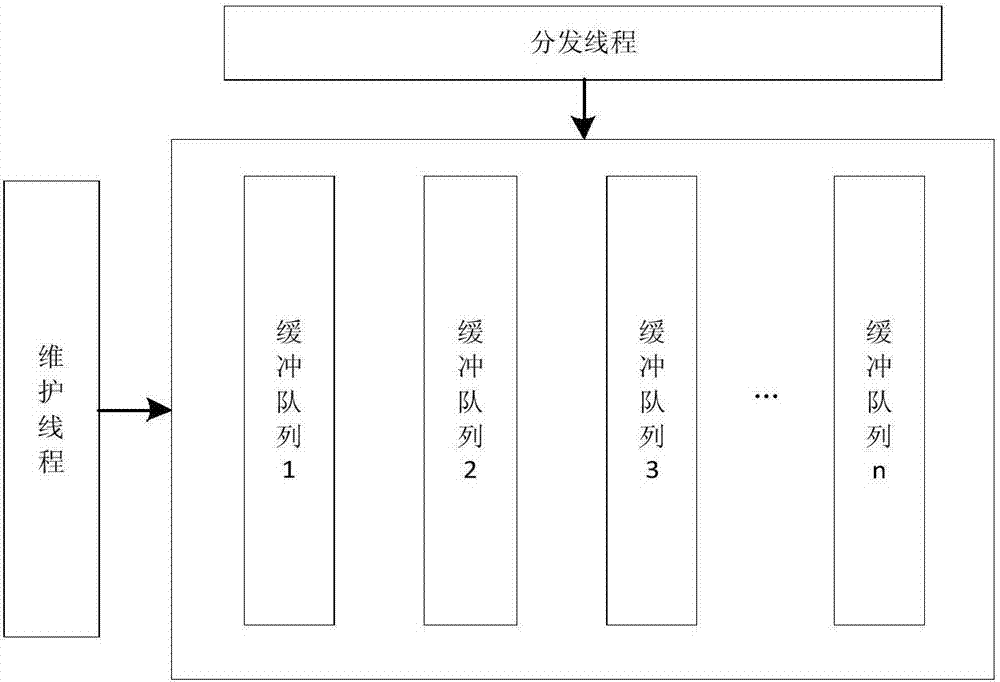
:隨著web技術的發展,大量的信息系統部署在網絡上對外提供服務。信息系統在為信息發布和交互帶來便利的同時,針對系統的web攻擊越來越多,系統安全已成為一個日益重要的問題。根據國家互聯網應急中心發布《中國互聯網站發展狀況及其安全報告(2016)》顯示,針對信息系統的sql注入、網頁篡改、網站后門等web攻擊事件層出不窮,黨政機關、科研機構、重要行業單位網站是黑客組織攻擊的重點目標。對于采用技術手段繞過防火墻的入侵攻擊,防火墻無法檢測和告警。信息系統的應用服務器有記錄用戶訪問行為的日志數據,包括用戶操作行為、訪問請求和系統錯誤異常等。因此要全面掌握系統安全狀況,及時定位web攻擊,實時分析信息系統日志數據非常必要。黑客在獲得控制權后會立即竊取篡改數據或實施破壞行為,完成攻擊后很有可能清除入侵痕跡。因此,第一時間發現web攻擊行為十分重要,特別是對于規模龐大的信息系統或者數據中心,web攻擊檢測方法必須要支持海量的日志數據實時在線檢測。當前關于web攻擊的檢測方法側重于研究攻擊檢測方法的準確性和完備性。專利(cn201510889266.0)“一種web攻擊檢測方法和裝置”公開了一種web攻擊檢測方法。該方法實現了基于url正常行為模型的web攻擊檢測。但是該方法沒有考慮web攻擊的實時檢測需求,難以滿足海量日志數據分析的實時性要求。技術實現要素:針對以上問題,本發明提出了一種基于流數據分析的web攻擊實時在線檢測系統。包括采用多緩存隊列,在線采集和分發應用服務器日志數據;采用集群式處理架構設計,動態調配分析節點負載,保障海量日志數據分析的實時性和可靠性;采用基于動態時間窗口的流數據分析方法,實時檢測攻擊事件。本發明能夠提高應用服務器日志分析處理能力和時效性,提高web攻擊檢測的及時性,提高信息系統的安全性。為了實現上述技術目的,本發明的技術方案是,一種基于流數據分析的web攻擊實時在線檢測系統,包括日志數據采集客戶端、日志數據緩存集群和流數據檢測集群;所述的日志數據采集客戶端是將信息系統應用服務器日志封裝成syslog消息格式的客戶端軟件;所述的日志數據緩存集群由至少兩個日志數據緩存模塊組成,通過以太網與日志數據采集客戶端、流數據檢測集群連接;所述的流數據檢測集群由至少兩個流數據檢測模塊組成;所述的日志數據緩存模塊包括分發線程、維護線程和至少一個緩沖隊列;分發線程接收來自日志數據采集客戶端的syslog消息,并轉化為統一格式的消息對象,再將消息對象分發到緩存隊列,維護線程用于清理緩沖隊列中不符合要求的消息對象;所述的流數據檢測模塊包括流數據生產模塊、流數據一級處理模塊、流數據二級處理模塊和流數據三級處理模塊;流數據生產模塊提取日志數據緩存模塊的消息對象,并轉化為統一格式的流數據單元;流數據一級處理模塊采用wu-manber多模匹配算法檢測流數據單元中是否含有攻擊特征關鍵字,將含有特征關鍵字的流數據單元發送到流數據二級處理模塊中;流數據二級處理模塊采用流數據分析模型,去除重復的攻擊事件,統計攻擊次數,并將融合的攻擊事件檢測結果發送至流數據三級檢測模塊;流數據三級檢測模塊將檢測結果存入關系數據庫中。所述的一種基于流數據分析的web攻擊實時在線檢測系統,所述的分發線程將syslog消息轉化成格式為<消息頭,消息體>,表示為<head,body>的統一格式的消息對象。所述的一種基于流數據分析的web攻擊實時在線檢測系統,所述的分發線程根據消息對象根據分配函數,將消息對象分發到第i個緩存隊列,分配函數公式如下:i=|h(head)|%n其中h(head)為消息對象頭字符串的哈希值,n為緩沖隊列的個數。所述的一種基于流數據分析的web攻擊實時在線檢測系統,維護線程清理緩沖隊列中不符合要求的消息對象,是從緩沖隊列中刪除距離當前時間超過維護線程時間閾值t1的消息對象,其中維護線程時間閾值t1是在系統啟動初始化時進行設置的。所述的一種基于流數據分析的web攻擊實時在線檢測系統,所述的流數據生產模塊包括至少一個處理單元、流數據維護線程和流數據緩沖隊列;所述的處理單元用于提取日志數據緩存模塊中的消息對象,并轉換成流數據單元;流數據緩沖隊列的一個元素為一個流數據單元,隊列長度根流數據單元的規模進行配置;流數據維護線程用于從流數據緩沖隊列中刪除日志時間距離當前時間超過流數據維護線程時間閾值t3的消息對象,其中流數據維護線程時間閾值t3是在系統啟動初始化時進行設置的。所述的一種基于流數據分析的web攻擊實時在線檢測系統,所述的處理單元由至少一個流數據提取線程和主管線程組成,流數據提取線程用于一一對應的提取日志數據緩存模塊的緩沖隊列中的信息對象,即流數據提取線程i僅用于提取緩沖隊列i中的消息對象,所述的主管線程負責創建和維護流數據提取線程。所述的一種基于流數據分析的web攻擊實時在線檢測系統,所述的流數據二級處理模塊包括流數據分析模型、過程對象維護線程和過程對象隊列;所述的流數據分析模型用于統計和融合檢測結果;過程對象隊列中以一個過程對象為一個元素,隊列長度根據對象的規模進行配置,過程對象維護線程用于從過程對象隊列中刪除距離當前時間超過過程對象維護線程時間閾值t2的過程對象,其中過程對象維護線程時間閾值t2是在系統啟動初始化時進行設置的。所述的一種基于流數據分析的web攻擊實時在線檢測系統,所述的流數據分析模型采用如下步驟建立:步驟1,計算其中一個流數據單元中server_port、server_ip、client_ip三個屬性組合字符串的hash值,并在過程對象隊列中查找是否存在具有相同的hash值的過程對象,如果找到相同過程對象v,轉到步驟2;如果沒有找到,則轉到步驟3;步驟2,更新所有過程對象中的時間窗口屬性值,方法如下:δt=asctime-c_timeti=tavg+σ(t)其中c_time為標識時間,用于標識過程對象v的最后更新時間;ti為過程對象v的時間窗口屬性;c_time和ti均是系統啟動初始化時設置;δt是時間差,tavg是時間窗口平均值,[t1,t2...tr]為過程對象隊列中所有過程對象的ti屬性的集合,r是過程對象隊列的長度,σ(t)是事件窗口的均方誤差,asctime為訪問時間;計算流數據單元u的asctime屬性值與過程對象v的c_time屬性值之間的差值,并根據差值更新過程對象v的count屬性值,方法如下:更新過程對象v的c_time為asctime,如果count大于統計閾值c,則轉到步驟4,否則轉向步驟1,其中count為計數器;步驟3,由過程對象維護線程創建一個新的過程對象,設置count屬性值為1,標識c_time時間設置為asctime,轉到步驟1;步驟4,將過程對象v發送至流數據三級檢測模塊,轉到步驟1。本發明的技術效果在于,采用多緩存隊列,實時在線采集信息系統應用日志,能夠防止黑客完成攻擊后清除日志數據;采用集群框架設計,整個安全日志數據處理流程由志數據緩存集群和流數據檢測集群組成,能夠實現負載均衡和解決單點故障,提高數據處理的實時性和可靠性;采用基于動態時間窗口的流數據分析方法,能夠根據不同的場景,動態調整時間窗口閾值,提高數據融合的準確性。附圖說明圖1為本發明實施例的基于流數據分析的web攻擊實時在線檢測方法框架示意圖;圖2為圖1中日志緩存模塊框架圖;圖3為圖1中流數據檢測模塊框架圖。具體實施方式下面結合附圖對本發明作進一步說明。本實施例通過以下過程實現,第一步,首先搭建web攻擊實時在線檢測系統,系統由日志數據采集客戶端、日志數據緩存集群和流數據檢測集群組成。日志數據采集客戶端是一種將信息系統應用服務器日志封裝成syslog(是一種用來在互聯網協議的網絡中傳遞記錄檔訊息的標準)消息格式的客戶端軟件,常見的開源syslog軟件有nxlog和evtsys,本發明在windows和linux主機使用syslog軟件的是nxlog。日志數據緩存集群由k個(k>1)日志數據緩存模塊組成,通過以太網與日志數據采集客戶端、流數據檢測集群連接。流數據檢測集群由r個(r>1)流數據檢測模塊組成。日志數據緩存模塊由分發線程、維護線程和n個(n≥1)緩沖隊列組成。分發線程從tcp數據通信鏈路中接收來自日志數據采集客戶端的syslog消息,并轉化為統一格式的消息對象,格式為<消息頭,消息體>,表示為<head,body>,再將消息對象根據分配函數,分發到第i個緩存隊列,分配函數公式如下:i=|h(head)|%n其中h(head)為消息頭字符串的哈希值。緩沖隊列的一個元素為一個syslog消息對象,隊列長度根據消息對象的規模進行配置,隊列長度設置為50000000。維護線程根據時間閾值t1的配置,清理緩沖隊列的數據,即從緩沖隊列中刪除距離當前時間超過t1的消息對象,釋放內存空間。流數據檢測模塊由流數據生產模塊、流數據一級處理模塊、流數據二級處理模塊和流數據三級處理模塊組成。流數據生產模塊提取日志數據緩存模塊的消息對象,并轉化為統一格式的流數據單元。流數據一級處理模塊采用wu-manber多模匹配算法檢測流數據單元中是否含有攻擊特征關鍵字,將含有特征關鍵字的流數據單元發送到流數據二級處理模塊中。流數據二級處理模塊采用基于時間窗口的流數據分析模型,分析檢測結果,并將流數據單元發送至流數據三級檢測模塊。流數據三級檢測模塊將檢測結果存入關系數據庫中。流數據二級處理模塊由流數據分析模型、過程對象維護線程和過程對象隊列組成。流數據分析模型統計和融合檢測結果。過程對象隊列的一個元素為一個過程對象,隊列長度根據對象的規模進行配置,通常一個過程對象隊列最大接收規模為1000個每秒,隊列長度設置為1000。過程對象維護線程根據時間閾值t2的配置,清理過程對象隊列的數據,即從過程對象隊列中刪除距離當前時間超過t2的消息對象,釋放內存空間。流數據分析模型采用如下步驟建立:步驟1,計算其中一個流數據單元中server_port、server_ip、client_ip三個屬性組合字符串的hash值,并在過程對象隊列中查找是否存在具有相同的hash值的過程對象,如果找到相同過程對象v,轉到步驟2;如果沒有找到,則轉到步驟3;步驟2,更新所有過程對象中的時間窗口屬性值,方法如下:δt=asctime-c_timeti=tavg+σ(t)其中c_time為標識時間,用于標識過程對象v的最后更新時間;ti為過程對象v的時間窗口屬性;c_time和ti均是系統啟動初始化時設置;δt是時間差,tavg是時間窗口平均值,[t1,t2...tr]為過程對象隊列中所有過程對象的ti屬性的集合,r是過程對象隊列的長度,σ(t)是事件窗口的均方誤差,asctime為訪問時間;計算流數據單元u的asctime屬性值與過程對象v的c_time屬性值之間的差值,并根據差值更新過程對象v的count屬性值,方法如下:更新過程對象v的c_time為asctime,如果count大于統計閾值c,則轉到步驟4,否則轉向步驟1,其中count為計數器;步驟3,由過程對象維護線程創建一個新的過程對象,設置count屬性值為1,標識c_time時間設置為asctime,轉到步驟1;步驟4,將過程對象v發送至流數據三級檢測模塊,轉到步驟1。流數據生產模塊由m個(m≥1)個處理單元、流數據維護線程和流數據緩沖隊列組成。其中處理單元負責提取日志數據緩存模塊中的消息對象,并轉換成流數據單元。處理單元由n個(n≥1)流數據提取線程和主管線程組成,流數據提取線程與日志數據緩存模塊的緩沖隊列為一一對應關系,即流數據提取線程i只能提取緩沖隊列i中的消息對象,主管線程負責創建和維護流數據提取線程。流數據緩沖隊列的一個元素為一個流數據單元,隊列長度根流數據單元的規模進行配置,隊列長度設置為100000000。流數據維護線程根據時間閾值t3的配置清理流數據緩沖隊列的數據,即從流數據緩沖隊列中刪除日志時間距離當前時間超過t3的消息對象,釋放內存空間。第二步,初始化多源安全日志采集系統。2.1在日志源安裝syslog客戶端軟件,。2.2為流數據分析模型預設一個標識時間c_time,預設一個時間窗口tp。2.3設置維護線程的時間閾值t1為24小時,設置對象維護線程的時間閾值t2為5分鐘,設置流數據維護線程的時間閾值t3為24小時,第三步,syslog客戶端啟動syslog程序,向日志數據緩存模塊發送日志數據。日志數據緩存模塊的分發線程根據分配函數,將日志數據轉化為消息對象并發送至緩沖隊列,維護線程判斷緩沖隊列中消息對象消息頭的時間屬性值距離當前時間的值是否大于閾值t1,如果大于,則刪除該消息對象。第四步,流數據生產模塊的主管線程根據緩沖隊列的數量,創建流數據提取線程。流數據提取線程提取緩沖隊列中的消息對象,轉化為統一格式的流數據單元,并放入流數據緩沖隊列。流數據維護線程判斷流數據緩存隊列中流數據對象的asctime屬性值距離當前時間的差值是否大于閾值t3,如果大于,則刪除該流數據對象。第五步,流數據一級處理模塊調用wu-manber多模匹配算法檢測流數據單元中是否含有攻擊特征關鍵字,如果含有,將流數據單元發送到流數據二級處理模塊。第六步,流數據二級處理模塊采用流數據分析模型,去除重復的攻擊事件,統計攻擊次數,將融合的攻擊事件檢測結果發送至流數據三級處理模塊。第七步,流數據三級處理模塊將檢測結果存入關系數據庫中。圖1是本發明涉及的基于流數據分析的web攻擊實時在線檢測方法框架示意圖,系統由日志數據采集客戶端、日志數據緩存集群和流數據檢測集群組成。日志數據采集客戶端是一種將信系統應用服務器日志封裝成syslog(是一種用來在互聯網協議的網絡中傳遞記錄檔訊息的標準)消息格式的客戶端軟件,常見的開源syslog軟件有nxlog和evtsys,本發明在windows和linux主機使用syslog軟件的是nxlog。日志數據緩存集群由k個(k>1)日志數據緩存模塊組成,通過以太網與日志數據采集客戶端、流數據檢測集群連接。流數據檢測集群由r個(r>1)流數據檢測模塊組成。圖2是圖1中日志緩存模塊框架圖,日志數據緩存模塊由分發線程、維護線程和n個(n≥1)緩沖隊列組成。分發線程從tcp數據通信鏈路中接收來自日志數據采集客戶端的syslog消息,并轉化為統一格式的消息對象,格式為<消息頭,消息體>,表示為<head,body>,再將消息對象根據分配函數,分發到第i個緩存隊列,分配函數公式如下:i=|h(head)|%n其中h(head)為消息頭字符串的哈希值。緩沖隊列的一個元素為一個syslog消息對象,隊列長度根據消息對象的規模進行配置,隊列長度設置為50000000。維護線程根據時間閾值t1的配置,清理緩沖隊列的數據,即從緩沖隊列中刪除距離當前時間超過t1的消息對象,釋放內存空間。圖3是圖1中流數據檢測模塊框架圖,流數據檢測模塊由流數據生產模塊、流數據一級處理模塊、流數據二級處理模塊和流數據三級處理模塊組成。流數據生產模塊提取日志數據緩存模塊的消息對象,并轉化為統一格式的流數據單元。如下表1所示,流數據單元包括訪問時間、客戶端ip、服務端ip、服務端端口、請求方法、返回狀態碼、用戶代理、cookie、訪問路徑和請求參數、鏈接網址、設備名稱、設備ip12個數據字段。表1流數據單元格式流數據一級處理模塊采用wu-manber多模匹配算法檢測流數據單元中是否含有攻擊特征關鍵字,將含有特征關鍵字的流數據單元發送到流數據二級處理模塊中。流數據二級處理模塊采用基于時間窗口的流數據分析模型,分析檢測結果,并將流數據單元發送至流數據三級檢測模塊。流數據三級檢測模塊將檢測結果存入關系數據庫中。流數據二級處理模塊由流數據分析模型、過程對象維護線程和過程對象隊列組成。流數據分析模型統計和融合檢測結果。過程對象隊列的一個元素為一個過程對象,隊列長度根據對象的規模進行配置,通常一個過程對象隊列最大接收規模為1000個每秒,隊列長度設置為1000。如下表2所示,過程對象包括哈希鍵值、時間窗口、計數器、標識時間4個數據字段。過程對象維護線程根據時間閾值t2的配置,清理過程對象隊列的數據,即從過程對象隊列中刪除距離當前時間超過t2的消息對象,釋放內存空間。表2過程對象格式屬性屬性名稱hash_keyhashcode(server_port+server_ip+client_ip)t時間窗口count計數器c_time標識時間當前第1頁12
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1