一種基于知識蒸餾的挖礦流量早期檢測方法與流程
本發明涉及流量分析和網絡安全,特別是涉及一種基于知識蒸餾的挖礦流量早期檢測方法。
背景技術:
1、
2、泛濫的挖礦行為消耗大量能源,對環境和健康造成危害,違背節能減排、可持續發展的理念。因此,及時對挖礦行為進行檢測識別,并進行合理限制和政策監管,能有效抑制虛擬貨幣挖礦活動的能源消耗。
3、針對挖礦行為的檢測方法大致可分為基于主機端和基于網絡流量端兩種方法。基于主機的挖礦行為模型主要應用于終端主機,該方法旨在提取主機系統的調用與操作作為主要特征以檢測系統中可能存在的挖礦活動。基于主機的檢測方法可以精確地識別目標主機中是否存在挖礦行為,但該方法只能檢測單一目標主機,當需要檢測的主機數量較多時,則難以部署。遇到檢測工具需要維護升級的問題,則進一步增加了維護成本。
4、基于網絡流量的挖礦行為檢測具備靈活、易部署的優點,但由于網絡流量和通信協議的復雜性,相關工作仍存在以下問題:
5、1)深度包檢測方法難以建立完備指紋庫。傳統的基于深度包檢測的方法將數據包明文與已知的挖礦協議指令進行規則匹配進行挖礦流量檢測需要頻繁維護,但用于挖礦行為的私有協議種類繁多,難以建立完備的指紋庫。傳統方法還需要大量人工輔助維護相關數據庫,此外,礦池只需更改協議指令就能繞過檢測。
6、2)構建挖礦流量統計特征依賴專家知識。現有的挖礦流量特征構建通常依賴專家的專業知識知識,常見挖礦流量檢測方法會提取流中包間隔特征、包大小特征和包速率特征等特征,或是構建獨有特征用于表示挖礦流量特點。這類特征提取方法存在一定的主觀性和局限性,不同專家對挖礦流量的特征有不同的理解和提取方式,導致檢測側重不同,最終可能影響實際檢測結果的波動。
7、3)基于統計的流量特征導致實時檢測效果不佳:基于網絡流量統計特征的檢測方法在實時檢測中效果不佳,存在高誤報率的現象。統計特征通常基于完整的三元組流或五元組流,在實時檢測中很難獲取完整的流,因此嚴重影響統計特征的準確性,導致檢測精度降低。
技術實現思路
1、本發明的內容在于提出一種基于知識蒸餾的挖礦流量早期檢測方法,以解決上述技術問題。本方法旨在利用盡可能少的流量早期數據包在會話建立初期實現對挖礦行為快速、準確地檢測挖礦流量。
2、本發明所采用的技術方案是:提取流量早期基本特征彌補統計特征的不足,并利用知識蒸餾技術在不增加模型復雜度的情況下進一步提取早期基本特征中的時序特征以提升檢測準確率。
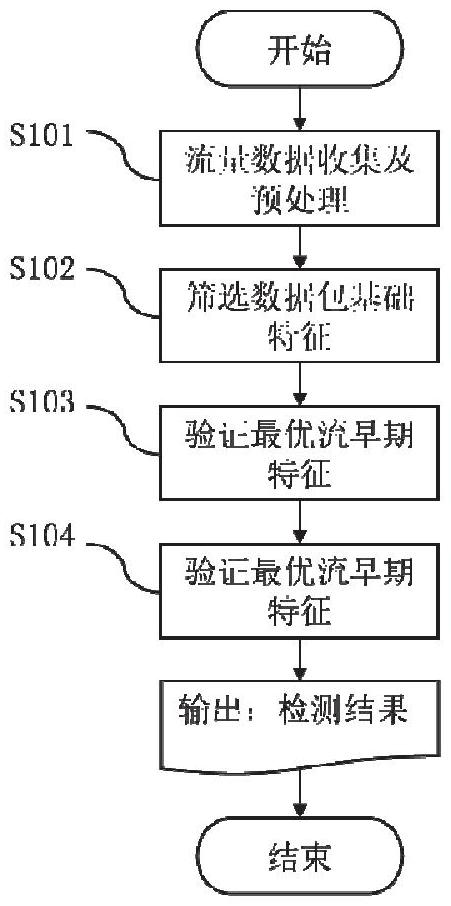
3、為了實現上述目的,本發明包括以下步驟:
4、1)流早期特征提取方法:
5、步驟s101:流量數據收集及預處理;收集明文和加密挖礦流量,以及正常網絡活動如網頁瀏覽、網絡聊天、在線會議等背景流量構建流量數據集d1,并對原始流量數據集d1進行數據包級別預處理,從而構建流量基礎特征數據集d2;
6、步驟s102:篩選數據包基礎特征;通過過濾式,包裹式和嵌入式三類特征特征選擇方法評估流量基礎特征數據集d2中基本特征在挖礦流量檢測任務上的重要性,篩選出最適用于挖礦流量檢測任務的基本特征;
7、步驟s103:驗證最優流早期特征;在經典機器學習算法上對前十個數據包級別的流早期特征進行多次實驗,并通過wilcoxon符號秩檢驗篩選出性能最優的流早期特征,構建最優流早期特征數據集d3;
8、2)基于知識蒸餾的挖礦行為檢測模型:
9、步驟s104:構建基于知識蒸餾的卷積神經網絡流量檢測模型;根據最優流早期特征數據集d3預訓練教師模型,利用卷積神經網絡的特征圖與時序模型的輸出特征構建指導函數,通過引入指導函數對主損失函數進行參數優化,并調整指導參數以確保模型在挖礦流量檢測中的最佳性能。
10、進一步的,所述步驟s101具體為:
11、步驟s201:收集挖礦流量,包括明文挖礦流量和加密挖礦流量。所述明文挖礦流量的有效載荷信息未加密,可被直接讀取用于檢測,所述加密挖礦流量則經過tls或ssl協議加密。
12、步驟s202:收集背景流量;包括自動化工具selenium產生的批量訪問網頁流量,以及正常用戶產生的網絡聊天和在線會議流量,并結合挖礦流量構成流量數據集d1;
13、步驟s203:預處理數據包級別的基礎特征,選擇適合流量檢測任務的部分基礎特征。在流量數據集d1中,剔除數據包原始信息中的mac地址、ip地址、端口、序列號、確認號等不適用特征,提取剩余的數據包基礎特征,構建流量基礎特征數據集d2;
14、進一步的,所述步驟s102具體為:
15、步驟s301:過濾式特征選擇方法利用方差差異、卡方分布、相關系數三種統計方法評估流量基礎特征數據集d2基礎特征重要性。
16、步驟s302:包裹式特征選擇方法利用遞歸特征消除方法在svm、lda、sgd模型中進行特征選擇,對流量基礎特征數據集d2基本特征進行排序。
17、步驟s303:嵌入式特征選擇方法結合決策樹、隨機森林和集成決策樹的adaboost算法計算流量基礎特征數據集d2的基礎特征重要性。
18、步驟s304:根據九種方法中基本特征在挖礦流量檢測任務中重要性的綜合排序,選出最適合挖礦流量檢測的基礎特征。
19、進一步的,步驟s103具體為:
20、步驟s401:將原始數據根據五元組進行劃分,通過觀察總結挖礦流量和背景流量的通信規律后,提取流早期數據包的有效負載長度和包方向,以及經過篩選的基本特征,依次構建包含不同數據包個數的流早期特征。
21、步驟s402:針對前十個數據包級別的流早期特征,在rf、svm、lda、nb和knn五種經典的機器學習算法上進行多次實驗,記錄模型性能指標。
22、步驟s403:運用wilcoxon符號秩檢驗驗證相鄰級別流早期特征的性能差異,篩選出最佳流早期特征,構成最優流早期特征數據集d3。
23、進一步的,所述步驟s104具體為:
24、步驟s501:被劃分成流按順序排列的流量數據包可以被認為是時間序列數據的一種特例,lstm或gru能夠有效捕捉挖礦流量的時序特征。利用最優流早期特征數據集d3預訓練基線模型,并選擇合適的時序模型和卷積神經網絡分別作為教師模型和學生模型;
25、步驟s502:卷積神經網絡中的特征圖和時序模型的輸出特征可分別可以用批處理大小(b)、通道數(c)、高度(h)、寬度(w)表示為:
26、oc∈r(b×c×h×w)
27、os∈r(h×b(c×w))
28、兩類模型的訓練方式也存在差異,導致卷積層和時序模型的輸出特征存在差異。為方便準確計算兩種特征之間的距離度量,將它們轉換為相同大小的二維數據,具體表示為:
29、fc=linear(oc),fc∈r(b×(c×h×w))
30、fs=reshape(os),fs∈r(b×(c×h×w))
31、其中,linear函數是可學習的線性投影,由1×1卷積實現。1×1卷積會對特征圖每個位置上的通道進行加權求和,最終轉換為一個單通道的輸出。linear函數可以有效保留特征信息,并使得卷積與時序輸出特征對齊。reshape函數則是將時序輸出轉換為類似圖像輸出,并計算特征差異構成指導函數:
32、lguide=||fc-fs||2
33、步驟s503:訓練產生的主損失函數是由cnn完成檢測分類任務產生,獲取它的時序輸出用于指導任務。用lcls表示cnn在進行檢測分類任務時自主學習局部特征產生的交叉熵損失函數,即主損失函數。將經過提取的局部信息特征與全局信息特征間的差異加入主損失函數中,使得cnn在更新參數中學習到數據的時序特征。訓練中的最終損失函數由cnn的主損失函數和指導函數兩個部分組成:
34、l=lcls-β·lguide
35、其中,指導參數β是一個根據實踐經驗設定的超參數,使用網格搜索算法調整指導參數,確保模型在挖礦流量檢測任務中的最佳表現。
36、相對于現有技術,本發明發具有以下優點:
37、1)本發明提出的流量特征提取方法能夠同時檢測明文挖礦流量和加密挖礦流量,能夠不依賴于指紋庫,能夠有效應對協議的多樣性,從而提高了檢測的覆蓋范圍和靈活性;
38、2)本文發明僅使用會話早期的四個非零數據包的原始數據,避免了對統計特征的依賴,簡化了數據處理過程,同時使得早期特征具備流量的基本特征和時序特征,增強了檢測的實時性和準確性;
39、3)使用知識蒸餾方法在降低模型復雜度的情況下,進一步提取流量基本特征和時序特征,實現快速檢測。
- 還沒有人留言評論。精彩留言會獲得點贊!