一種字幕生成模型設計方法、裝置、存儲介質和程序產品與流程
本發明涉及自然語言處理,尤其涉及一種字幕生成模型設計方法、裝置、存儲介質和程序產品。
背景技術:
1、字幕制作在影視制作中占有重要位置。好的字幕對文字準確性、可讀性等提出了較高的要求,即要求字幕的內容沒有錯誤,同時字幕展示的時間與音頻內容相對應。
2、現有技術將語音識別應用到字幕制作中,用于將音頻內容自動轉換成相應的文字,但是自動識別的內容往往無法滿足字幕的準確性要求。為此,現有技術通過給定正確的內容和語音,輸出準確的字幕。
3、然而上述現有技術生成的字幕仍存在可讀性方面的問題,即實際應用中,字幕單行顯示的字數往往存在限制,在字數限制下,不進行內容編排而直接按照音頻時序輸出字幕往往導致字幕不符合語言習慣,影響字幕的可讀性。
技術實現思路
1、針對現有技術存在的不足,本發明提出一種字幕生成方法、裝置、存儲介質和程序產品,在生成字幕的過程中充分利用人聲檢測和分詞技術,生成的字幕綜合考慮實際的語音停頓及文本語言習慣,使生成的字幕與音頻呈現更高的匹配度,且字幕文字更加易讀;本發明同時考慮了設備限制或人為規定的字幕單行最大限制字數,進一步提高了生成字幕的可讀性。
2、本發明中使用的相關名詞含義如下:字幕成果代表由本發明得到的最終成果;字幕成果由字幕文字及對應的時間戳構成;時間戳代表某個對象在原始音頻中對應的起始時間和結束時間,這個對象可以是字幕字詞,也可以是分段語音。
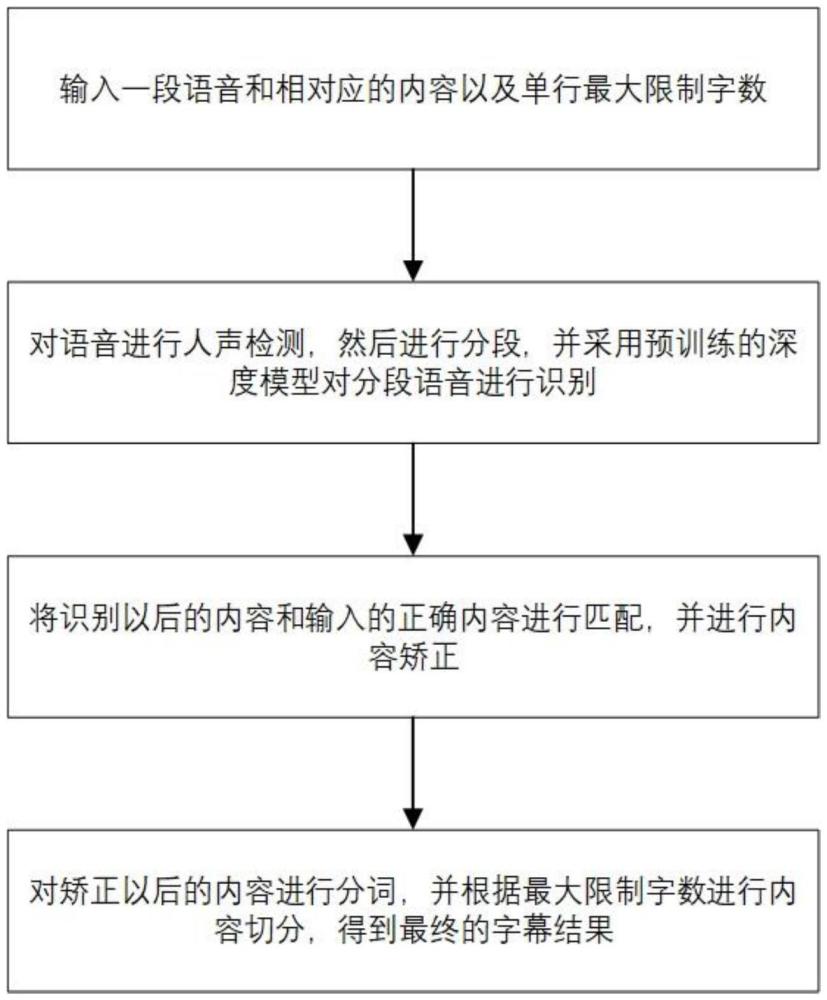
3、第一方面,本發明提供一種字幕生成模型設計方法,包括以下步驟:
4、輸入一段語音和對應的正確內容,以及字幕單行最大限制字數;
5、使用基于深度學習的人聲檢測模型,對輸入的語音進行人聲檢測,得到初始語音片段及相應時間戳;
6、對初始片段進行后處理,得到分段語音及相應時間戳;
7、將分段語音輸入到預訓練的深度模型進行語音識別,得到識別文字以及每個文字對應的時間戳;
8、使用所述正確內容與識別文字進行匹配、校正,得到字幕文字;
9、根據字幕單行最大限制字數,對字幕文字進行分行、整合,得到最終字幕成果。
10、作為本發明的進一步改進,所述字幕單行最大限制字數為一個根據顯示設備或者用戶需求確定的字數。
11、作為本發明的進一步改進,所述使用基于深度學習的人聲檢測模型,對輸入的語音進行人聲檢測,得到初始語音片段及相應時間戳,包括:
12、將輸入的語音切割成預設大小的片段,輸入到人聲檢測模型中;
13、通過人聲檢測模型的輸出結果進行人聲判別;
14、將連續存在人聲的片段合并,得到初始語音片段及相應時間戳。
15、作為本發明的進一步改進,所述對初始片段進行后處理,得到分段語音及相應時間戳,包括:
16、設置閾值;
17、通過所述閾值進行判別、處理,刪除過短的片段,合并時間間隔較短的片段。
18、作為本發明的進一步改進,所述根據字幕單行最大限制字數,對字幕文字進行分行、整合,包括:
19、計算每個分段語音對應的字幕文字字數;
20、若字數沒有超過字幕單行最大限制字數,則直接使用該分段語音的時間戳和對應的字幕文字生成單行字幕成果;
21、若某分段語音對應的字幕文字超過字幕單行最大限制字數,則通過分行、整合操作生成字幕成果。
22、作為本發明的進一步改進,所述分行、整合操作,包括:
23、為需要分行的分段語音設置子分段;
24、對分段語音對應的字幕文字進行分詞,得到分詞列表及其中每個詞的時間戳;
25、將分詞列表中的詞依序放入子分段中,并控制子分段長度不大于字幕單行最大限制字數;
26、整合子分段及相應時間戳,得到單行字幕成果;
27、整合單行字幕成果,得到最終字幕成果。
28、作為本發明的進一步改進,所述整合子分段及相應時間戳,包括根據子分段中每個詞的時間戳,獲取子分段在原始音頻中的時間戳。
29、第二方面,本發明提供一種計算機裝置,包括存儲器、處理器及存儲在存儲器上的計算機程序,所述處理器執行所述計算機程序以實現第一方面所述方法的步驟。
30、第三方面,本發明提供一種計算機可讀存儲介質,其上存儲有計算機程序,該計算機程序被處理器執行時實現第一方面所述方法的步驟。
31、第四方面,本發明提供一種計算機程序產品,該計算機程序被處理器執行時實現第一方面所述方法的步驟。
32、與現有技術相比,本發明提出一種字幕生成方法、裝置、存儲介質和程序產品,在生成字幕的過程中充分利用人聲檢測和分詞技術,生成的字幕綜合考慮實際的語音停頓及文本語言習慣,使生成的字幕與音頻呈現更高的匹配度,且字幕文字更加易讀;本發明同時考慮了設備限制或人為規定的字幕單行最大限制字數,進一步提高了生成字幕的可讀性。
技術特征:
1.一種字幕生成模型設計方法,其特征在于,包括以下步驟:
2.根據權利要求1所述的方法,其特征在于,所述字幕單行最大限制字數為一個根據顯示設備或者用戶需求確定的字數。
3.根據權利要求1所述的方法,其特征在于,所述使用基于深度學習的人聲檢測模型,對輸入的語音進行人聲檢測,得到初始語音片段及相應時間戳,包括:
4.根據權利要求1所述的方法,其特征在于,所述對初始片段進行后處理,得到分段語音及相應時間戳,包括:
5.根據權利要求1所述的方法,其特征在于,所述根據字幕單行最大限制字數,對字幕文字進行分行、整合,包括:
6.根據權利要求5所述的方法,其特征在于,所述分行、整合操作,包括:
7.根據權利要求6所述的方法,其特征在于,所述整合子分段及相應時間戳,包括根據子分段中每個詞的時間戳,獲取子分段在原始音頻中的時間戳。
8.一種計算機裝置,包括存儲器、處理器及存儲在存儲器上的計算機程序,其特征在于,所述處理器執行所述計算機程序以實現權利要求1-7中的任一項所述方法的步驟。
9.一種計算機可讀存儲介質,其上存儲有計算機程序,其特征在于,該計算機程序被處理器執行時實現權利要求1-7中的任一項所述方法的步驟。
10.一種計算機程序產品,其特征在于,該計算機程序被處理器執行時實現權利要求1-7中的任一項所述方法的步驟。
技術總結
本發明提供一種字幕生成模型設計方法、裝置、存儲介質和程序產品,涉及自然語言處理技術領域。其中,字幕生成模型設計方法包括:輸入一段語音和對應的正確內容,以及字幕單行最大限制字數;使用基于深度學習的人聲檢測模型進行人聲檢測;使用預訓練的深度模型進行語音識別;使用所述正確內容與識別文字進行匹配、校正,得到字幕文字;根據字幕單行最大限制字數,對字幕文字進行分行、整合,得到最終字幕成果。本發明生成的字幕綜合考慮實際的語音停頓及文本語言習慣,字幕與音頻呈現更高的匹配度,且字幕文字更加易讀;本發明同時考慮了設備限制或人為規定的字幕單行最大限制字數,進一步提高了生成字幕的可讀性。
技術研發人員:虞釘釘,徐清,曹培,沈旭立,羅粵清,周邦健
受保護的技術使用者:華院計算技術(上海)股份有限公司
技術研發日:
技術公布日:2025/4/24
- 還沒有人留言評論。精彩留言會獲得點贊!