一種針對腦力疲勞的語音疲勞度檢測方法與流程
本發明涉及語音處理識別領域,具體涉及一種針對腦力疲勞的語音疲勞度檢測方法。
背景技術:
疲勞是人類機體復雜的生理心理變化過程,屬于人體機能自然的自我保護機制,可以分為兩種:生理疲勞和心理疲勞,分別指體力或腦力到達一定階段時出現的正常生理現象。人體疲勞的加深會引起運動能力和工作效率降低、差錯事故增多,甚至使人體出現器質性疾病。顯然,了解人體疲勞程度對不同人群的身體健康、安全生產、安全工作(例如安全操作、安全駕駛)等方面的影響具有十分重要的作用。
目前,學術界針對疲勞度的檢測可以分為主觀檢測和客觀檢測這兩種方法。主觀檢測即根據主觀調查表、自我記錄表以及睡眠習慣調查表和斯坦福睡眠尺度表來檢測受試者的疲勞程度。這種通過主觀感受進行的疲勞度檢測技術帶有的主觀因素較多,說服力不夠。客觀檢測即利用儀器、設備等工具對人體的心理、生理以及生化方面的參數進行檢測,如:(1)檢測表面肌電信號、腦電信號及心電信號等生理信號;(2)檢測血睪酮、血尿素及血紅蛋白等生化指標。這種通過測量生理指標進行的疲勞度檢測技術已經比較成熟,但是在實際運用上卻美中不足,存在一些不可操作性。首先,疲勞度檢測需具有實時性,但是通過生化指標測疲勞,需要一定的化驗時間,且帶有一定的侵入性;表面肌電信號、腦電信號以及心電信號等接觸式的生理參數測量方法,雖免去化驗時間,但是其接觸性會導致受試者的反感,并且檢測設備在一定程度上會限制受試者的活動,甚至影響其運動時的表現,采集到的數據將受到儀器本身的禁錮,從而導致生理信號分析結果的有效性產生偏差;當然,復雜、高精度的設備也需要大量的投資和維護,這并非疲勞度檢測的初衷。
因此,基于語音分析的疲勞度檢測應運而生。通過語音傳遞信息是常用的一種信息交換方式,語音中通常攜帶有一定量的信息,其中也包括疲勞度的相關信息。基于語音信號處理的疲勞度檢測可避免上述方法中存在的各種問題。首先,語音檢測疲勞只需采集人的聲音信號來進行訓練識別,語音信號中包含的豐富信息,并且相對于其他生理參數,語音信號更容易被獲取得到;簡單的錄音設備也避免了復雜的儀器接觸給受試者帶來的巨大心理壓力,從一定程度上使得分析結果的客觀性得到了提高。綜上,語音信號具有實時性高、維護簡單、性價比高的優勢。
學術界基于語音分析的疲勞度檢測研究主要集中在運動疲勞、駕駛疲勞的特定情境下,對單純腦力疲勞的研究少之又少。因此,如何提供一種針對腦力疲勞的語音疲勞度檢測方法,是本領域技術人員所要解決的問題。
技術實現要素:
本發明的發明目的是提供一種針對腦力疲勞的語音疲勞度檢測方法。
為達到上述發明目的,本發明采用的技術方案是:一種針對腦力疲勞的語音疲勞度檢測方法,包括如下步驟:
步驟一、選取人數相等的男性和女性受試者;
步驟二、參照疲勞度量表將受試者持續的疲勞感知人為劃分為3個疲勞度等級,并在0度疲勞狀態、稍疲勞狀態以及精疲力竭狀態下的語音錄制,并創建語料庫,所述語料庫中包括運動疲勞語料和腦力疲勞語料;
步驟三、對語料庫中的語料進行標記,包括語料種類編號、受試者性別、受試者年齡和疲勞等級;
步驟四、根據心率與腦力疲勞度的相關性驗證受試者的腦力疲勞等級;
步驟五、提取語料庫中語料的語音特征參數,包括語音段短時平均能量、語音段短時平均過零率、語音段語速、回答反應時長和基頻;
步驟六、利用支持向量機進行同性別內腦力疲勞檢測,并利用遷移學習進行跨性別間腦力疲勞檢測,得出被檢測者的疲勞等級。
上文中,所述疲勞度量表為疲勞量表-14(fatiguescale-14,fs-14),是1992年由英國king’scollegehospital心理醫學研究室的t.chalder及queenmary’suniversityhospital的g.berelowitz等許多專家等共同編制的、可有效反映腦力疲勞程度的主觀疲勞量表。
上述技術方案中,所述步驟一中,男性受試者為不少于15人,女性受試者為不少于15人。
對于所述男性和女性受試者的人數,本發明不做具體限定,典型但非限制性的可以是15人、20人、25人、30人、35人、40人、45人、50人、55人、60人等等,且受試者人數越多,語料庫越豐富,腦力疲勞的檢測越準確。
優選地,所述步驟一中,男性受試者為15~30人,女性受試者為15~30人。
進一步地,所述步驟二中,每位受試者錄制4~7條運動疲勞語料和3~6條腦力疲勞語料。
優選地,所述步驟二中,每位受試者錄制4條運動疲勞語料和3條腦力疲勞語料。
進一步地,所述步驟二中,所述疲勞度量表中0分對應0度疲勞狀態,1~4分對應稍疲勞狀態,5~6分對應精疲力竭狀態。
進一步地,所述步驟六中,利用支持向量機進行同性別內腦力疲勞檢測的步驟包括:
(1)準備數據集;
(2)設置合適的svm類型并設置對應的參數;
(3)選擇合適的核函數并設置對應的參數;
(4)對訓練集進行訓練獲取支持向量機的模型;
(5)利用步驟(4)中所得模型進行預測。
優選地,所述步驟六中,采用tradaboost算法進行跨性別間腦力疲勞檢測。
由于上述技術方案運用,本發明與現有技術相比具有下列優點:
本發明采用主觀疲勞量表將連續的腦力疲勞簡化為若干個明確的疲勞度等級,從而建立有效腦力疲勞語料庫,并采用心率驗證疲勞狀態標注的準確性,再利用支持向量機進行同性別內腦力疲勞檢測,以及利用遷移學習進行跨性別間腦力疲勞檢測,實現針對腦力疲勞的語音疲勞度檢測。
附圖說明
圖1是本發明實施例一的方法流程圖。
圖2是本發明實施例一的步驟三中語料庫命名示意圖。
圖3是本發明實施例一的腦力疲勞狀態下心率隨疲勞度變化情況示意圖。
圖4是本發明實施例一中受試者為女性時基于svm的同性別內腦力疲勞度識別率部分數據示意圖。
圖5是本發明實施例一中基于tradaboost的跨性別間腦力疲勞度識別準確率的部分數據示意圖。
具體實施方式
下面結合附圖及實施例對本發明作進一步描述:
實施例一:
參見圖1所示,一種針對腦力疲勞的語音疲勞度檢測方法,包括如下步驟:
步驟一、選取15為男性受試者和15位女性受試者;
步驟二、參照疲勞度量表將受試者持續的疲勞感知人為劃分為3個疲勞度等級,并在0度疲勞狀態、稍疲勞狀態以及精疲力竭狀態下的語音錄制,并創建語料庫,所述語料庫中包括運動疲勞語料和腦力疲勞語料;
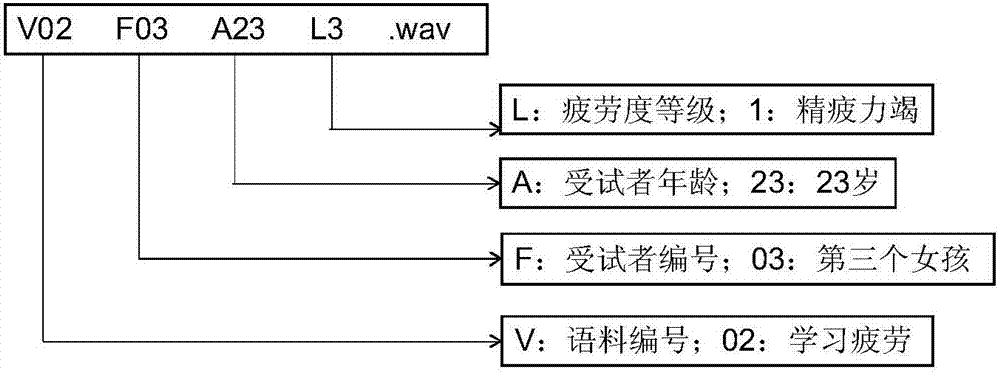
步驟三、對語料庫中的語料進行標記,包括語料種類編號v、受試者性別f、受試者年齡a和疲勞等級l;
步驟四、根據心率與腦力疲勞度的相關性驗證受試者的腦力疲勞等級;
步驟五、提取語料庫中語料的語音特征參數,包括語音段短時平均能量、語音段短時平均過零率、語音段語速、回答反應時長和基頻;
步驟六、利用支持向量機進行同性別內腦力疲勞檢測,并利用遷移學習進行跨性別間腦力疲勞檢測,得出被檢測者的疲勞等級。
上文中,所述疲勞度量表為疲勞量表-14(fatiguescale-14,fs-14),是1992年由英國king’scollegehospital心理醫學研究室的t.chalder及queenmary’suniversityhospital的g.berelowitz等許多專家等共同編制的、可有效反映腦力疲勞程度的主觀疲勞量表,參見表1。
表1疲勞量表-14(fs-14)
其中,14個條目分別從不同角度反映疲勞的輕重,受試者只需根據實際情況回答“是”或“否”。總分值最高為14分,分值越高,則表示疲勞越嚴重;反之,疲勞感越輕。同理,若只針對腦力疲勞,則總分值最高為6分,分值越高表示疲勞越深;反之越輕。
基于fs-14量表通過受試者的主觀感受將人體腦力疲勞劃分為3類:0分對應自然狀態,即0度疲勞狀態;1-4分對應稍疲勞狀態;5-6對應精疲力竭狀態。
本實施例中,所述步驟二中,每位受試者錄制4條運動疲勞語料共120條;以及3條腦力疲勞語料,共90條。其中,語音錄制包括第一部分的朗讀和第二部分的問答,問答的問題是由實驗員事先設計好的常識性問題,受試者正常作答即可。
步驟三中,對語料庫中的語料進行標注,其規則參見表2和圖2所示。
表2語料庫中語料標注規則
上述語料庫中腦力疲勞的問答環節是用于提取反應時時長的重要語音段,針對腦力疲勞,主要的加工標注工作就是通過人耳將朗讀段跟回答問題的銜接處、每個問題結束和開始回答的點標注出來,以便后續特征參數的提取。
所述步驟四中,利用心率隨疲勞度變化的趨勢進行客觀的疲勞度分類驗證,參見圖3所示,受試者的心率隨腦力疲勞程度變化的趨勢與理論值相符,因此,基于主觀疲勞量表的疲勞度等級劃分具有有效性,后續可利用語料庫進行語音疲勞度檢測的研究。
所述步驟六中,利用支持向量機進行同性別內腦力疲勞檢測的步驟包括:
(1)準備數據集。其使用的訓練數據和校驗數據格式為:<label><index1>:<value1><index2>:<value2>等,則本發明中分別建立了訓練集特征向量(train_vector),訓練集特征標簽向量(train_label_vector),測試集特征向量(test_vector)及測試集特征標簽向量(test_label_vector)。為了避免訓練模型時為計算核函數而計算內積時引起數值計算的困難,對訓練集特征向量和測試集特征向量都事先進行了歸一化。其中用于訓練的語音特征參數用排列組合(22*3種)的方法分別進行測試,以獲取不同特征參數組合的疲勞度識別率。
(2)設置合適的svm類型并設置對應的參數。“-s”用于設置svm類型,其中:0對應c-svc;1對應v-svc;2對應一類svm;3對應
(3)選擇合適的核函數并設置對應的參數。“-t”是livsvm中用于設置核函數類型的參數,分別有線性(0)、多項式(1)、rbf函數(2)、sigmoid(3)。本發明針對rbf核函數涉及到的參數有:gamma函數(-g)。
(4)對訓練集進行訓練獲取支持向量機的模型。函數形式為:
算法1libsvm訓練算法描述
modle=svmtrain(train_label_vector,train_vector,'libsvm_options')
其中,train_label表示訓練集特征標簽向量,train_vector為訓練集特征向量,libsvm_options則為包括步驟(2)、(3)中需要設置的參數的訓練集參數。
(5)利用上述模型進行預測。
算法2libsvm識別算法描述
[predict_label,accuracy,decision_values]=
svmpredict(test_label_vector,test_vector,model,'libsvm_options')
其中,predict_label是通過訓練模型預測得到的測試集的標簽向量,accuracy是一個三維向量,上至下依次是:分類準確率、平均平方誤差及平方相關系數。前者是分類問題中的參數指標,后兩者均用于回歸問題中。
腦力疲勞研究中,單性別受試者男女各15人,疲勞程度分為3級,故可用于訓練和測試的樣本各45條。本發明進行了三種訓練-測試模式的識別率比較,以此得到識別效果最好的訓練-測試樣本比例。本發明在進行實驗數據對比時,為簡化參數形式,將短時平均能量縮寫為e,基頻為p,語速為s,喘息段時長為w,短時平均能量為z,反應時為r。部分數據如圖4所示。
通過觀察基于svm的腦力疲勞識別效果,不難發現:橫向對比各特征組合下不同訓練-測試模型的疲勞度識別效果,識別率最好往往出現在訓練12-測試3的情況下,說明訓練參數越多,訓練出的分類器分類效果越好;縱向觀察各訓練-測試模型下不同特征參數組合的疲勞識別效果,所有特征參數綜合起來得到的識別率略低于60%,由于實施例中受試者數量不足,導致樣本數據數量不夠大,所以相比較運動疲勞而言,多特征組合識別疲勞效果的能力較弱,由短時平均能量和反應時這兩種特征參數組合對腦力疲勞具有最好的識別效果,為76.3%,并且在不同的訓練-測試模型中,訓練12-測試3模型的識別效果最好,其識別率接近90%;觀察單特征對腦力疲勞識別的效果,可以看出,短時平均過零率的識別效果最佳。后續的工作中將增加受試樣本的個數,以達到更好的訓練效果。
采用tradaboost算法,用于跨性別遷移學習。
其具體的流程為:
算法3tradaboost算法描述
輸入:輔助樣例空間大量標注的訓練數據集ta,
目標樣例空間少量標注的訓練數據集tb,
目標樣例空間大量未標注的測試數據集s,
基本分類算法learner,
迭代次數n
初始化:
1.初始化權重向量w1;
2.設置
fort=1,……,n,
1.設置權重分布
2.調用learner,根據ta和tb合并后的訓練數據t,權重pt以及未標注數據s,得到在目標空間的分類器ht,并計算ht在tb上的錯誤率:
3.令
輸出:最終分類器hf:
參見圖5所示,縱向比較不同特征參數組合的遷移學習準確率,可以發現eprs、prs、eps、ps等特征參數的組合在跨性別間腦力疲勞度檢測具有最好的識別率,故可以推斷:男聲、女聲這兩個不同領域共享知識主要集中在語速隨疲勞度的變化上;橫向比較每行的準確率,用男聲預測女聲效果不佳,但是女聲預測男聲具有較高的準確率,即大量的女聲數據加上少量的男聲數據,能有效預測剩余的男聲數據,實現跨性別疲勞度檢測且效果比svm的跨性別疲勞度檢測更有說服力。
- 還沒有人留言評論。精彩留言會獲得點贊!