基于SGCN圖神經網絡學習的抑郁癥檢測方法和系統
本發明涉及圖神經網絡學習,具體地,涉及一種基于sgcn圖神經網絡學習的抑郁癥檢測方法和系統。
背景技術:
1、為了更好地理解和處理抑郁癥,研究人員在過去幾十年中進行了廣泛的研究。目前關于抑郁癥的研究涉及的技術有:(1)神經影像學研究:神經影像學技術,如功能性磁共振成像(fmri)、腦電圖(eeg)和正電子發射斷層顯像術(pet)等,這些技術允許研究人員觀察和分析抑郁癥患者大腦的結構和功能差異,從而揭示其病理機制。(2)分子生物學和基因研究:分子生物學和基因研究有助于揭示抑郁癥的遺傳基礎和與其相關的分子機制。通過研究基因表達、單核苷酸多態性等,研究人員可以鑒定與抑郁癥發病風險和病程預測相關的基因變異。(3)環境和心理社會因素研究:除了遺傳因素外,環境和心理社會因素也在抑郁癥的發生和發展中起著關鍵作用。研究人員通過調查、問卷調查和心理評估等手段,分析不同環境和心理社會因素對抑郁癥的影響,如壓力、社交支持、童年創傷等。(4)藥物治療研究:藥物治療是常用的抑郁癥治療方法之一。研究人員通過進行臨床試驗和藥物療效研究,探索和評估各種抗抑郁藥物的療效和安全性,以及其對患者癥狀和生活質量的影響。(5)心理療法研究:心理療法被廣泛應用于抑郁癥的治療,包括認知行為療法、插圖療法和心理動力學治療等。研究人員對不同心理療法的有效性和機制進行研究,以便為患者提供更個體化和有效的治療方案。
2、專利文獻cn111447874a(申請號:cn201880078144.5)公開了一種判別裝置、抑郁癥狀的判別方法、抑郁癥狀的水平的判斷方法、抑郁癥患者的分類方法、抑郁癥狀的治療效果的判斷方法和腦活動訓練裝置。專利文獻cn111141863a(申請號:cn201811314630.0)公開了一種抑郁癥診斷標志物及其制備方法。以上兩個發明主要是腦科學和藥物兩個方面提出,但沒有從行為學和從機器學習語音這個角度進行分析。
技術實現思路
1、針對現有技術中的缺陷,本發明的目的是提供一種基于sgcn圖神經網絡學習的抑郁癥檢測方法和系統。
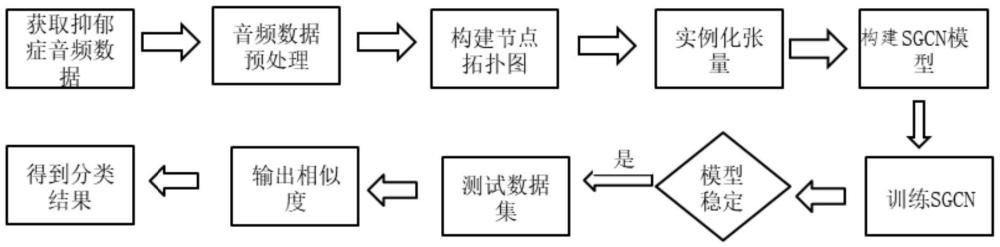
2、根據本發明提供的基于sgcn圖神經網絡學習的抑郁癥檢測方法,包括:
3、步驟1:收集被試者的語音樣本;
4、步驟2:對采集到的語音樣本進行預處理,包括去除噪聲、標準化音頻級別和降低語音的頻帶范圍;
5、步驟3:從預處理后的語音樣本中提取相關特征;
6、步驟4:在提取到的特征中,根據抑郁癥相關研究的先驗知識和特征重要性,進行特征選擇或降維處理;
7、步驟5:使用已標記的訓練集,建立一個用于抑郁癥檢測的機器學習模型;
8、步驟6:通過交叉驗證和參數調整對模型進行優化,使用指標,包括準確率、召回率和f1得分進行性能評估;
9、步驟7:使用獨立的測試集對優化的模型進行評估,計算混淆矩陣、roc曲線和auc來評估模型的整體分類效果;
10、步驟8:通過將模型嵌入到實際應用中,包括移動應用程序或在線平臺,驗證其在真實世界中的可行性和效果。
11、優選地,所述步驟1包括:使用包括麥克風和移動應用程序在內的數據采集設備來記錄被試者的語音,確保采集環境安靜,并注明每位被試者的年齡、性別和抑郁癥病情。
12、優選地,所述步驟2包括:僅選擇同時具有標簽、生理和行為信息和特征的個體;如果特征集中某一通道的空缺數據超過一半,則刪除該通道;如果一行中的空缺數據少于一半,則使用該行中其他通道的平均值填充空缺;將不同通道的權重從高到低累加,直至權重和達到0.5的閾值,然后取被累加的通道值的平均;過濾掉絕對值大于100的數據,并用該特征的中位數替代。
13、優選地,所述步驟4包括:刪除與相關性無關的信息,包括患者編號和語音持續時間;基于行為和生理信息構建鄰接矩陣,使用皮爾遜系數計算每個患者與其他所有患者之間的相關性,如果系數超過設定的閾值,則在鄰接矩陣中將兩個患者視為相關,并創建無向連接。
14、優選地,所述步驟5包括:
15、使用sgcn訓練模型,對輸入的語音數據進行分析研判,實現抑郁預測功能,包括:將音頻文件轉換成圖結構,然后使用圖卷積神經網絡gcn提取特征并訓練模型;使用求和式gcn作為output函數,并從多個向量或多個特征中提取更綜合的表示來完成二分類任務,gcn的函數為:其中,為鄰接矩陣;為度矩陣;h(l)為每一層的節點表示;σ表示激活函數;w(l)表示網絡中第l層的網絡權重矩陣;
16、采用三層結構,過程為:得到graph節點的特征表示x,計算機鄰接矩陣將其輸入三層gcn網絡中,得到每個標簽的預測結果:其中,和分別第一層和第二層的權重值矩陣;x表示特征矩陣;a表示鄰接矩陣;softmax()、relu()為激活函數;
17、通過二分類交叉熵進行抑郁癥和非抑郁癥的分類,表達式為:
18、
19、其中,yi為樣本i的標簽值,pi表示為樣本i預測為正類的概率,n為該批次預測的樣本量。
20、根據本發明提供的基于sgcn圖神經網絡學習的抑郁癥檢測系統,包括:
21、模塊m1:收集被試者的語音樣本;
22、模塊m2:對采集到的語音樣本進行預處理,包括去除噪聲、標準化音頻級別和降低語音的頻帶范圍;
23、模塊m3:從預處理后的語音樣本中提取相關特征;
24、模塊m4:在提取到的特征中,根據抑郁癥相關研究的先驗知識和特征重要性,進行特征選擇或降維處理;
25、模塊m5:使用已標記的訓練集,建立一個用于抑郁癥檢測的機器學習模型;
26、模塊m6:通過交叉驗證和參數調整對模型進行優化,使用指標,包括準確率、召回率和f1得分進行性能評估;
27、模塊m7:使用獨立的測試集對優化的模型進行評估,計算混淆矩陣、roc曲線和auc來評估模型的整體分類效果;
28、模塊m8:通過將模型嵌入到實際應用中,包括移動應用程序或在線平臺,驗證其在真實世界中的可行性和效果。
29、優選地,所述模塊m1包括:使用包括麥克風和移動應用程序在內的數據采集設備來記錄被試者的語音,確保采集環境安靜,并注明每位被試者的年齡、性別和抑郁癥病情。
30、優選地,所述模塊m2包括:僅選擇同時具有標簽、生理和行為信息和特征的個體;如果特征集中某一通道的空缺數據超過一半,則刪除該通道;如果一行中的空缺數據少于一半,則使用該行中其他通道的平均值填充空缺;將不同通道的權重從高到低累加,直至權重和達到0.5的閾值,然后取被累加的通道值的平均;過濾掉絕對值大于100的數據,并用該特征的中位數替代。
31、優選地,所述模塊m4包括:刪除與相關性無關的信息,包括患者編號和語音持續時間;基于行為和生理信息構建鄰接矩陣,使用皮爾遜系數計算每個患者與其他所有患者之間的相關性,如果系數超過設定的閾值,則在鄰接矩陣中將兩個患者視為相關,并創建無向連接。
32、優選地,所述模塊m5包括:
33、使用sgcn訓練模型,對輸入的語音數據進行分析研判,實現抑郁預測功能,包括:將音頻文件轉換成圖結構,然后使用圖卷積神經網絡gcn提取特征并訓練模型;使用求和式gcn作為output函數,并從多個向量或多個特征中提取更綜合的表示來完成二分類任務,gcn的函數為:其中,為鄰接矩陣;為度矩陣;h(l)為每一層的節點表示;σ表示激活函數;w(l)表示網絡中第l層的網絡權重矩陣;
34、采用三層結構,過程為:得到graph節點的特征表示x,計算機鄰接矩陣將其輸入三層gcn網絡中,得到每個標簽的預測結果:其中,和分別第一層和第二層的權重值矩陣;x表示特征矩陣;a表示鄰接矩陣;softmax()、relu()為激活函數;
35、通過二分類交叉熵進行抑郁癥和非抑郁癥的分類,表達式為:
36、
37、其中,yi為樣本i的標簽值,pi表示為樣本i預測為正類的概率,n為該批次預測的樣本量。
38、與現有技術相比,本發明具有如下的有益效果:
39、(1)針對語音信號特征,采用gcn處理,能夠利用節點之間的連接和圖結構信息進行消息傳遞和特征聚合,通過考慮節點的鄰居節點特征和關系,gcn能夠更全面地捕捉節點的上下文信息;
40、(2)本發明針對抑郁癥的語音診斷問題,提供一種基于圖神經網絡進行預測的方法,可用于不同場景病人的數據聯合訓練模型,可以保證數據的完備性、隱私性和較高地預測準確性和快速診斷,探討抑郁癥與語音交叉的關系,并利用語音分析技術來輔助抑郁癥的診斷、預測和治療,通過語音分析和機器學習方法在抑郁癥領域的應用將能夠提供更準確、實時且非侵入性的評估手段,從而幫助醫生和患者更好地理解和管理抑郁癥。
- 還沒有人留言評論。精彩留言會獲得點贊!