一種預(yù)測多肽在不同血液環(huán)境中的穩(wěn)定性的深度學(xué)習(xí)算法的制作方法
本發(fā)明屬于多肽藥物研發(fā),具體涉及一種預(yù)測多肽在不同血液環(huán)境中的穩(wěn)定性的深度學(xué)習(xí)算法。
背景技術(shù):
1、多肽和蛋白質(zhì)藥物因具備獨特的優(yōu)點,在生物醫(yī)藥領(lǐng)域的發(fā)展中占據(jù)了重要地位。至今,已有近80種多肽藥物被批準(zhǔn)用于臨床治療各種疾病。然而,盡管多肽藥物在臨床上取得了顯著成就,但進(jìn)入臨床試驗的新多肽藥物數(shù)量并未呈現(xiàn)相同的增長趨勢。多肽極易被體內(nèi)的蛋白酶水解,特別是在血漿中,這種不穩(wěn)定性嚴(yán)重阻礙了生物活性肽轉(zhuǎn)化為藥物先導(dǎo)物的進(jìn)程。因此,多肽在血漿中的穩(wěn)定性成為臨床應(yīng)用中的一個重要考量因素,對于多肽藥物的研發(fā)來說,準(zhǔn)確預(yù)測其在血漿中的穩(wěn)定性至關(guān)重要。
2、傳統(tǒng)上,多肽穩(wěn)定性的預(yù)測主要依賴于實驗方法,如血漿穩(wěn)定性試驗和酶解試驗。這些方法雖然較為準(zhǔn)確的可以獲得相應(yīng)多肽的穩(wěn)定性表現(xiàn),但耗時且成本高昂,不適合高通量篩選和大規(guī)模研究。目前,已有機器學(xué)習(xí)算法可以用于預(yù)測多肽在血漿中的穩(wěn)定性,但是這些模型在構(gòu)建訓(xùn)練數(shù)據(jù)時,往往會忽視了測試物種和測試環(huán)境可能帶來的巨大差異。這種顯著的差異可能會導(dǎo)致訓(xùn)練好的模型錯誤地選擇了不合適的先導(dǎo)化合物,進(jìn)而造成后續(xù)多肽藥物開發(fā)的失敗。其次在以往的多肽穩(wěn)定性或其他性質(zhì)預(yù)測模型中,研究者們普遍傾向于采用相對簡單的低維特征來表征多肽,并將這些特征作為輸入信息用于模型訓(xùn)練。然而,這些方法存在一個顯著的局限性,即它們往往忽略了多肽特有的3d結(jié)構(gòu)信息。考慮到目前多肽在血液中的穩(wěn)定性預(yù)測存在的現(xiàn)實應(yīng)用問題,亟需一種從多維度出發(fā),綜合考慮不同物種血液和實驗條件的多模態(tài)計算方法。
技術(shù)實現(xiàn)思路
1、針對上述問題,本發(fā)明的目的在于提供一種預(yù)測多肽在不同血液環(huán)境中的穩(wěn)定性的深度學(xué)習(xí)算法。
2、具體技術(shù)方案如下:
3、一種預(yù)測多肽在不同血液環(huán)境穩(wěn)定性的深度學(xué)習(xí)算法,包括如下步驟:
4、步驟一,獲取多肽在血漿中穩(wěn)定性數(shù)據(jù)集;
5、步驟二:對步驟一中收集到的數(shù)據(jù)進(jìn)行清洗和整理,不符合要求的數(shù)據(jù)包括:1.排除缺少半衰期數(shù)據(jù)或不確定半衰期數(shù)據(jù)的肽;2.排除無法確定相對應(yīng)序列信息的肽;3,排除具有復(fù)雜修飾且無法通過smiles碼有效表征的肽,如含有聚乙二醇修飾或與蛋白質(zhì)、脂質(zhì)等大分子載體結(jié)合的肽。
6、步驟三:在完成數(shù)據(jù)清洗和整理后,利用chemdraw和rdkit,為所有多肽添加了smiles編碼表示。
7、步驟四:在完成步驟三后,運用alphafold2、highfold、rdkit等工具為每個多肽構(gòu)建三維結(jié)構(gòu)模型。
8、步驟五:使用rdkit計算多肽的理化性質(zhì),并通過隨機森林算法篩選出對多肽血液穩(wěn)定性有重要影響的前140個特征并對其進(jìn)行保留。
9、步驟六:完成前面所有處理步驟后,按照多肽在血液中的半衰期是否大于1個小時,將數(shù)據(jù)分穩(wěn)定和不穩(wěn)定兩類。并將數(shù)據(jù)劃分為訓(xùn)練集和測試集,用于模型的訓(xùn)練和測試。
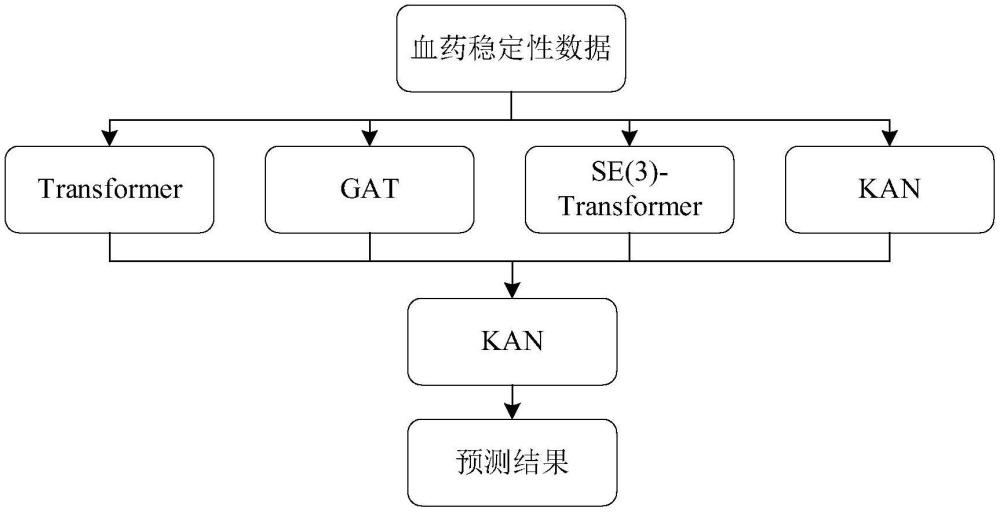
10、步驟七:對預(yù)處理完成的數(shù)據(jù),構(gòu)建一個多模態(tài)模型pepmsnd進(jìn)行訓(xùn)練,該模型包括:用于接收零維特征的kan模塊、處理一維特征的transformer模塊、分析二維特征的gat模塊以及解析三維特征的se(3)-transformer模塊。
11、步驟八:對于多模態(tài)模型pepmsnd的四個模塊(kan、transformer、gat、se(3)-transformer)的輸出,首先各自乘以一個可學(xué)習(xí)的權(quán)重w,然后將這四個加權(quán)后的輸出進(jìn)行拼接。
12、步驟九:將拼接后的輸出作為kan模型的輸入,并加入物種和實驗環(huán)境的特征信息,最終通過降維處理生成一維輸出,代表多肽在血液中的穩(wěn)定性置信度。
13、步驟十:在完成模型訓(xùn)練后,使用測試集對多模態(tài)模型pepmsnd的性能進(jìn)行評估。評估指標(biāo)包括acc(準(zhǔn)確率),precision(精準(zhǔn)率),recall(召回率),f1-score(f1-分?jǐn)?shù)),auc(曲線下面積),mcc(馬修斯相關(guān)系數(shù))。
14、進(jìn)一步地,步驟一的多肽在血漿中穩(wěn)定性數(shù)據(jù)集從peplife,thpdb,drugbank,pubmed等公共數(shù)據(jù)庫以“多肽”、“半衰期”、“血液”作為關(guān)鍵詞進(jìn)行搜索并收集獲得;
15、進(jìn)一步地,步驟四具體包括:對于僅含有天然氨基酸且不含修飾的線性多肽,使用alphafold2進(jìn)行3d結(jié)構(gòu)的生成;而對于僅含有天然氨基酸且不含修飾的環(huán)狀多肽,使用highfold進(jìn)行生成。對于含有復(fù)雜修飾的肽由于目前蛋白質(zhì)預(yù)測工具的限制,使用rdkit(版本2023.3.2)生成了每個環(huán)肽的3d結(jié)構(gòu)。先為每條肽段生成5000個構(gòu)象,接下來利用uff力場對5000個構(gòu)象進(jìn)行結(jié)構(gòu)優(yōu)化,最后選取勢能最低的結(jié)構(gòu)作為多肽的最終構(gòu)象。
16、進(jìn)一步地,步驟五具體包括:首先剔除那些在多肽分子間保持恒定值的描述符,以減少冗余信息。隨后,基于剩余的描述符,構(gòu)建了一個隨機森林模型。通過評估隨機森林模型的特征重要性,篩選出前140個最具影響力的分子描述符作為模型的輸入特征。此外,還通過one-hot編碼的方式引入了物種和實驗環(huán)境信息,作為額外的輸入特征。
17、進(jìn)一步地,步驟七具體包括:1.使用步驟五得到的140個分子描述符以及引入的物種和實驗環(huán)境信息,總共142個特征,以n×142的大小輸入到kan模型中。2.對所有多肽的smiles碼進(jìn)行擴充,使其長度達(dá)到1024,以n×1024的大小輸入到transformer模型中。3.對于gat的輸入,采用dgl?python包生成分子圖,并將其輸入到gat。4.從每個多肽的pdb文件中提取坐標(biāo),作為se(3)-transformer的輸入。
18、進(jìn)一步地,步驟八具體包括:將kan、transformer、gat、se(3)-transformer四個模塊的輸出大小都調(diào)整為n×128。然后將這四個模塊的輸出分別與對應(yīng)的可學(xué)習(xí)權(quán)重w1、w2、w3、w4相乘。接著將加權(quán)后的輸出拼接起來,形成一個大小為n×512的矩陣,最后,將這個矩陣輸入到后續(xù)的kan模型中。
19、進(jìn)一步地,步驟九具體包括:將步驟八獲得的n×512大小的矩陣先通過kan線性層的傳遞,降維為n×8大小的矩陣。然后通過one-hot編碼的方式引入物種和實驗環(huán)境信息,拼接到n×8大小的矩陣上,形成n×10大小的矩陣。最終通過降維處理生成一維輸出,代表多肽在血液中的穩(wěn)定性置信度。將置信度的閾值設(shè)定為0.5,其中當(dāng)置信度大于0.5則認(rèn)為是穩(wěn)定,反之則為不穩(wěn)定。
20、進(jìn)一步地,步驟十采用acc,precision,recall,f1-score,auc,mcc對模型的性能進(jìn)行評估,具體計算公式如下所示:
21、
22、
23、其中真正例tp、真負(fù)例tn、假正例fp和假負(fù)例fn分別用來表示每種類別的計數(shù)。
24、本發(fā)明的有益效果在于:一方面在構(gòu)建數(shù)據(jù)集時,對多肽穩(wěn)定性數(shù)據(jù)按照物種和實驗環(huán)境進(jìn)行了詳細(xì)的標(biāo)記和分類,這解決了原有方法中忽視測試物種和測試環(huán)境差異的問題。另一方面本發(fā)明采用了多模態(tài)模型pepmsnd,整合了多肽的四個維度信息(零維特征、一維特征、二維特征和三維特征)。通過這種方式,可以從全方位、多維度來理解和評估多肽在血液中的穩(wěn)定性影響因素,提高了預(yù)測的準(zhǔn)確性和泛化能力。本發(fā)明所設(shè)計的預(yù)測多肽在不同血液環(huán)境穩(wěn)定性的算法將極大促進(jìn)多肽類藥物的研究速度,降低該類藥物的研發(fā)成本。
- 還沒有人留言評論。精彩留言會獲得點贊!