智能語音評測方法及系統與流程
本發明涉及語音識別技術領域,具體來說涉及一種智能語音評測方法及系統。
背景技術:
隨著語音識別技術的不斷成熟,涉及到信號處理、自然語言理解、人工智能、數據挖掘和及其學習等多個學科的智能語音評測技術也得到了越來越廣泛的應用。例如,智能輔助教學系統班班通項目在各個中小學的推廣,普通話口語考試系統在全國的普及等。其中,智能語音評測就是利用計算機自動或半自動地對人的語音進行標準程度的評估和發音缺陷的檢測。如何提供檢測系統的穩定性、評測打分的準確性是智能語音評測的關鍵,也受到了越來越多的關注。
現有的口語評測方案,目的是給出一個以音素為基本單位的分數,在計算這個分數時,假設有一個GMM(高斯混合模型:Gaussian Mixture Model)+HMM(隱馬爾可夫模型:Hidden Markov Model)模型能夠很好地根據某些聲學片段來確定這些片段對應的似然概率,然后通過似然差來衡量對應音素的發音質量。上述口語評測方案,質量主要依賴于聲學模型的質量,而聲學模型的質量主要依賴于數據訓練的質量,好的或標準的訓練數據能夠得到高質量的聲學模型,進而得到高準確度的評測結果或評測分值。
然而將上述的口語評測方案用于口語考試評測時,該標準的聲學模型對于利用其他語種來翻譯閱讀時,比如在英語口語考試中,應試者利用中文朗讀英文,例如用“惡狗”代替“ago”進行發音朗讀,標準的聲學模型依然會給出較高的評測分值。這是由于利用其它語種閱讀時,聲學模型對該音頻進行音素提取時,被提取的音素與聲學模型中的標準發音非常相近,所以評測模型會給出較高的評測分值,而該較高的評測分值并不符合口語考試的評測要求,現有的口語評測方案不能解決這一問題。
技術實現要素:
鑒于上述情況,本發明提供一種智能語音評測方法及系統,解決了現有口語評測方案對利用其它語種閱讀形成的語音給出較高的評測分值而不符合口語評測要求的技術問題,達到針對利用其它語種閱讀的情況、及時發現并避免給予較高的評測分值的目的。
為實現上述目的,本發明采取的技術方案是:
一種智能語音評測方法,包括以下步驟:
a.提供第一訓練數據集,所述第一訓練數據集包括測試語種數據集和對比語種數據集,所述測試語種數據集和對比語種數據集均包括音頻數據、文本數據及其對應的音素集合;提供所述音素集合之間的映射關系;
b.訓練深度神經網絡,利用所述第一訓練數據集對深度神經網絡進行訓練,以形成深度神經網絡模型;
c.提供第二訓練數據集,對深度神經網絡進行訓練,所述第二訓練數據集包括至少兩種語種數據集,定義一種語種數據集為測試語種數據集,其他語種數據集為對比語種數據集,所述測試語種數據集和對比語種數據集分別輸入到所述深度神經網絡中進行訓練,所述測試語種數據集和對比語種數據集均包括音頻數據、文本數據及其對應的音素集合;
d.獲取待評測語音,提取所述待評測語音的特征序列,將所述特征序列輸入到所述深度神經網絡模型中;對所述待評測語音進行識別以形成音素序列;
e.輸出對應所述音素序列的評測分值;
f.比較以及處理所述評測分值,輸出評測結果。
本發明智能語音評測方法的進一步改進在于,在所述步驟f中,通過線性融合或非線性融合的方式對所述評測分值進行處理。
本發明智能語音評測方法的進一步改進在于,在步驟a中,不同語種發音相似的音素映射成一套音素集合,發音不能映射的音素標記為單獨的音素。
本發明智能語音評測方法的進一步改進在于,所述測試語種數據集為英文,所述對比語種數據集包括中文,中文帶調音素和英文音素映射為一套音素集合。
本發明智能語音評測方法的進一步改進在于,在所述步驟b中,還包括提取所述第一訓練數據集的梅爾頻譜倒譜系數特征或線性預測系數特征或梅爾濾波系數特征。
本發明智能語音評測方法的進一步改進在于,在所述步驟e中,還包括輸出:
第一類節點:對應為使用所述第一訓練數據集進行訓練后的輸出評測分值;
第二類節點:對應為使用所述測試語種數據集進行訓練后的輸出評測分值;
第三類節點:對應為使用所述對比語種數據集進行訓練后的輸出評測分值。
本發明智能語音評測方法的進一步改進在于,在所述步驟e中,利用后驗概率特征,通過映射得到所述音素序列的評測分值。
此外,本發明還提供一種智能語音評測系統,包括:
數據輸入模塊,與特征提取模塊連接,用于將第一訓練數據集和第二訓練數據集傳送至所述特征提取模塊;與音素映射模塊連接,用于將第一訓練數據集和第二訓練數據集傳送至所述音素映射模塊;
音素映射模塊,與深度神經網絡模塊連接,用于將所述第一訓練數據集和第二訓練數據集測試語種數據集的音素集合進行映射,傳送至所述深度神經網絡模塊;
語音接收模塊,與特征提取模塊連接,用于獲取待評測語音,并傳送至所述特征提取模塊;
特征提取模塊,與所述深度神經網絡模塊連接,用于提取所述第一訓練數據集和第二訓練數據集的特征序列以及所述待評測語音的特征序列,傳送至所述深度神經網絡模塊;
深度神經網絡模塊,與解碼網絡模塊及輸出節點模塊連接,經訓練后形成深度神經網絡模型,與解碼網絡模塊連接,傳送至所述輸出節點模塊;
解碼網絡模塊,與所述輸出節點模塊及語音接收模塊連接,用于對所述待評測語音進行識別以形成音素序列,傳送至所述輸出節點模塊;
輸出節點模塊,與優化融合模塊連接,用于輸出所述音素序列對應的評測分值,傳送至所述優化融合模塊;
優化融合模塊,與評分模塊連接,用于處理經所述輸出節點模塊輸出的評測分值,傳送至所述評分模塊;
評分模塊,用于輸出對應所述待評測語音的評測結果。
本發明智能語音評測系統的進一步改進在于,所述第一訓練數據集包括測試語種數據集和對比語種數據集,且所述測試語種數據集和對比語種數據集一同被傳送至所述音素映射模塊。
本發明智能語音評測系統的更進一步改進在于,所述第二訓練數據集包括測試語種數據集和對比語種數據集,所述測試語種數據集和對比語種數據集分別被傳送至所述音素映射模塊。
本發明的有益效果在于,本發明通過提供包括測試語種數據集和對比語種數據集的第一訓練數據集對深度神經網絡進行訓練,形成深度神經網絡模型,并對所述深度神經網絡模型分別喂入測試語種數據集和對比語種數據集進行訓練,所述深度神經網絡模型的輸出層輸出包括對應上述三類訓練數據集的評測分值,通過比較以及處理所述評測分值再輸出評測結果,達到了口語評測中對利用其它語種進行閱讀的情況、及時發現并避免給予較高的評測分值的技術效果。
附圖說明
圖1是本發明智能語音評測系統的結構示意圖。
圖2是本發明智能語音評測方法的流程示意圖。
附圖標記與部件的對應關系如下:
10-深度神經網絡模型,101-輸出節點,S11-第一訓練數據集,S12-第二訓練數據集,S10-音素集合,S13-特征序列,S0-待評測語音,S1-特征序列,S2-音素序列,S3-評測分值,S-評測結果,1-訓練數據使用的模塊連接關系,2-測試數據使用的模塊連接關系。
具體實施方式
為利于對本發明的了解,以下結合附圖及實施例進行說明。
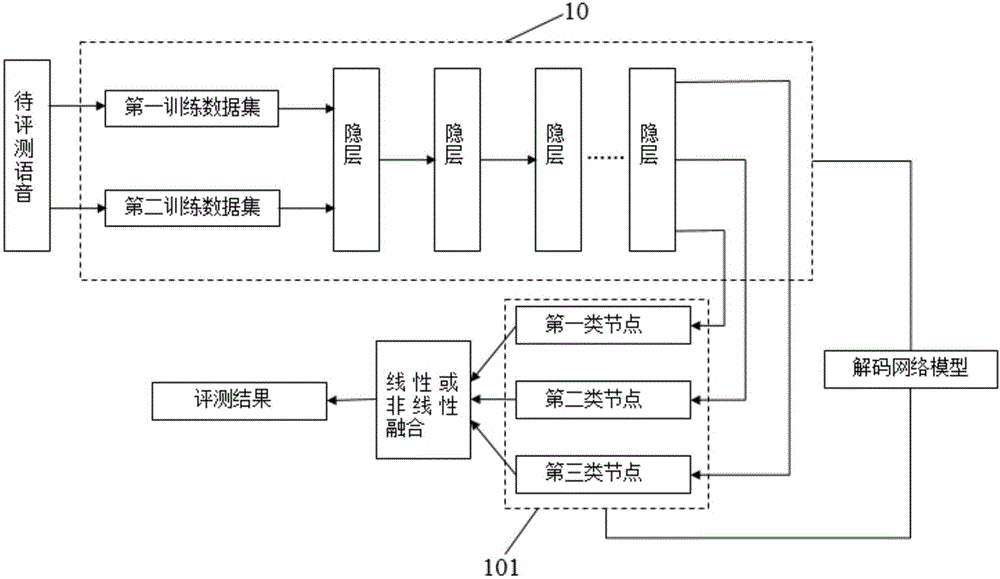
本發明提供一種智能語音評測方法及系統,旨在解決現有的口語評測方案對利用其它語種閱讀形成的語音給出較高的評測方案而不符合評測要求的問題。參閱圖1,所述智能語音評測系統包括:
數據輸入模塊,與特征提取模塊連接,用于將第一訓練數據集S11和第二訓練數據集S12傳送至特征提取模塊;與音素映射模塊連接,用于將第一訓練數據集S11和第二訓練數據集S12傳送至所述音素映射模塊;
音素映射模塊,與深度神經網絡模塊連接,用于將所述第一訓練數據集S11和第二訓練數據集S12的音素集合進行映射,映射后的音素集合S10傳送至所述深度神經網絡模塊;
語音接收模塊,與特征提取模塊連接,用于獲取待評測語音S0,并傳送至所述特征提取模塊;
特征提取模塊,與所述深度神經網絡模塊連接,用于提取第一訓練數據集S11和第二訓練數據集S12的特征序列S13和所述待評測語音S0的特征序列S1,傳送至所述深度神經網絡模塊,音素集合S10和特征序列S13共同訓練深度神經網絡模塊的參數;
深度神經網絡模塊,與解碼網絡模塊及輸出節點模塊連接,經訓練后形成深度神經網絡模型,傳送至所述輸出節點模塊;
解碼網絡模塊,與所述輸出節點模塊及語音接收模塊連接,用于對所述待評測語音進行識別以形成音素序列S2,傳送至所述輸出節點模塊;
具體的,智能語音評測系統是將待評測語音S0的特征序列S1輸入到深度神經網絡模型中以對其進行解碼,將評測語音S0的文本輸送到解碼網絡模塊進行解碼以獲取音素序列S2。
輸出節點模塊,與優化融合模塊連接,用于輸出所述音素序列對應的評測分值S3,傳送至所述優化融合模塊;
優化融合模塊,與評分模塊連接,用于處理經所述輸出節點模塊輸出的評測分值S3,傳送至所述評分模塊;
評分模塊,用于輸出對應所述待評測語音的評測結果S。
其中,第一訓練數據集S11包括測試語種數據集和對比語種數據集,所述測試語種數據集和對比語種數據集一同被傳送至所述特征提取模塊;第二訓練數據S12亦包括測試語種數據集和對比語種數據集,但是第二訓練數據S12包括的測試語種數據集和對比語種數據集是分別傳送至特征提取模塊,第一訓練數據S11是第二訓練數據S12包括的測試語種數據集和對比語種數據集的疊加,以在輸出節點模塊中,輸出對應于第一訓練數據的用于對待評測語音進行音素切分的評測分值。
圖1中訓練數據使用的模塊連接關系1指示在對深度神經網絡模塊進行訓練時,訓練數據用到的模塊連接關系;測試數據使用的模塊連接關系2指示待評測語音S0進行評測時,使用的模塊連接關系。
本發明所提供的智能語音評測系統,并不限于兩種語種的評測分類,即所述對比語種數據集可以是多種語種的數據集合,可依據實際需要,對深度神經網絡模型喂入多語種的訓練數據,以獲取與各語種相對應的評測分值。
此外,參閱圖2,本發明還提供一種智能語音評測方法,所述方法包括以下步驟:
a.提供第一訓練數據集,所述第一訓練數據集包括測試語種數據集和對比語種數據集,所述測試語種數據集和對比語種數據集均包括音頻數據、文本數據及其對應的音素結合;提供所述音素集合之間的映射關系;
b.訓練深度神經網絡,利用所述第一訓練數據集對深度神經網絡進行訓練,以形成深度神經網絡模型10;
c.提供第二訓練數據集,對深度神經網絡進行訓練,所述第二訓練數據集包括至少兩種語種數據集,定義一種語種數據集為測試語種數據集,其他語種數據集為對比語種數據集,所述測試語種數據集和對比語種數據集分別輸入到所述深度神經網絡中進行訓練,所述測試語種數據集和對比語種數據集均包括音頻數據、文本數據及其對應的音素集合;
d.獲取待評測語音,提取所述待評測語音的特征序列,將所述特征序列輸入到所述深度神經網絡模型中;對所述待評測語音進行識別以形成音素序列;
e.輸出對應所述音素序列的評測分值;
f.比較以及處理所述評測分值,輸出評測結果。
于本發明智能語音評測方法中,深度神經網絡模型10包括多層隱層,以對輸入的第一訓練數據S11和第二訓練數據S12進行非線性映射,和輸出節點層共同通過梯度下降法(Back Propagation),更新隱層參數,各隱層作用相同,且為順序處理關系。
于本發明智能語音評測方法中,提供音素集合的映射關系中,不同語種發音相似的音素映射成一套音素集合,發音不能映射的音素標記為單獨的音素,若測試語種為英語,對比語種為中文,則中文帶調音素可以映射到英文不帶調音素上。例如,英文音素的ei,對應的發音相似的中文帶調音素為ei1,ei2,ei3,ei4,它們發音相似,可以映射為一套音素。對所述第一訓練數據集提取MFCC(梅爾頻譜倒譜系數)或者PLP(線性預測系數)或者FB(梅爾濾波系數)特征以訓練所述深度神經網絡;深度神經網絡模型10與其輸出節點101還連接有解碼網絡模型,所述解碼網絡模型是利用所述文本信息生成,用于對所述語音信息進行識別以形成音素序列。
深度神經網絡模型10的輸出節點101分為三類:
第一類節點:對應為使用所述第一訓練數據集進行訓練后的輸出評測分值;
第二類節點:對應為使用所述測試語種數據集進行訓練后的輸出評測分值;
第三類節點:對應為使用所述對比語種數據集進行訓練后的輸出評測分值。
上述三類節點的單元可以為音素聚類后的狀態級別,也可以是音素級別;上述三類節點是利用后驗概率特征,通過映射以得到所述音素序列的評測分值。具體的,根據待評測語音S0經過深度神經網絡模型10之后,輸出待評測語音S0的好壞的概率值,待評測語音S0說的好,即音素序列S2與所述測試語音數據集的音素序列比較相近,則后驗概率高,待評測語音S0說的不好,即音素序列S2與所述測試語音數據集的音素序列相差較大,則后驗概率低。后驗概率還可能為負值,范圍可以是-20~10,最終的音素打分都是大于0的值。
對上述三類節點的評測分值進行比較及處理,主要是通過線性融合或非線性融合的方式進行的。例如,定義第一類節點輸出的評測分值為第一分值Score1,定義第二類節點輸出的評測分值為第二分值Score2,定義第三類節點輸出的評測分值為第三Score3,若第二分值Score2的分值很高,第三分值Score3的分值很低,則可以判斷獲取的語音為使用測試語種數據集對應的語音,輸出第二分值Score2為評測結果;若第二分值Score2與第三分值Score3的分數相近,則在對評測分值進行處理時,需對第二分值Score2和第三分值Score3進行加權處理以降低第三分值Score3對評測結果的影響,將加權處理后的結果作為評測結果進行輸出;若第二分值Score2的分值很低,第三分值Score3的分值很高,則基本可以判斷所獲取的待評測語音為利用其它語種形式閱讀形成,此時亦需要對第二分值Score2和第三分值Score3進行加權處理以輸出正確的評測結果。
對于第一分值Score1、第二分值Score2和第三分值Score3這三個評測分值,還可以利用線性疊加的原理進行處理,下面給出簡單的實施例:
第三分值Score3較高,第二分值Score2較低:評測結果S=a*(Score2+Score3),a取值為0.1或0.2;
第三分值Score3高,第二分值Score2偏高,但比第三分值Score3低:評測結果S=a*(Score2+Score3),a取值為0.3或0.4;
第三分值Score3很低,第二分值Score2很高:評測結果S=a*(Score1+Score2),a取值為0.5。這種情況說明待測試語音S0說的較為標準,第一分值Score1會較高。
如取第三分值Score3為80,第二分值Score2位70,則評測結果S=0.3*(80+70)=45,輸出評測結果為45。
計算評測結果S的方式并不限于此,也可利用復雜的計算公式,或是根據不同分數段設計不同的回歸系數,可根據預期的評測結果來設置相應的算法。
以上結合附圖及實施例對本發明進行了詳細說明,本領域中普通技術人員可根據上述說明對本發明做出種種變化例。因而,實施例中的某些細節不應構成對本發明的限定,本發明將以所附權利要求書界定的范圍作為本發明的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!