聲音處理系統以及聲音處理方法與流程
本申請要求2016年3月8日申請、申請號為2016-044653的日本專利申請的優先權,其全部內容通過引用并入本文。
本發明涉及聲音處理系統,特別涉及能夠針對來自用戶的反問快速地應答的聲音處理系統。
背景技術:
伴隨聲音識別技術的發展,車內空間內的聲音用戶接口的利用正在增加。另一方面,車內空間是噪音多的環境,需要強勁地識別噪音。另外,要求構筑以有多次反問為前提的系統。
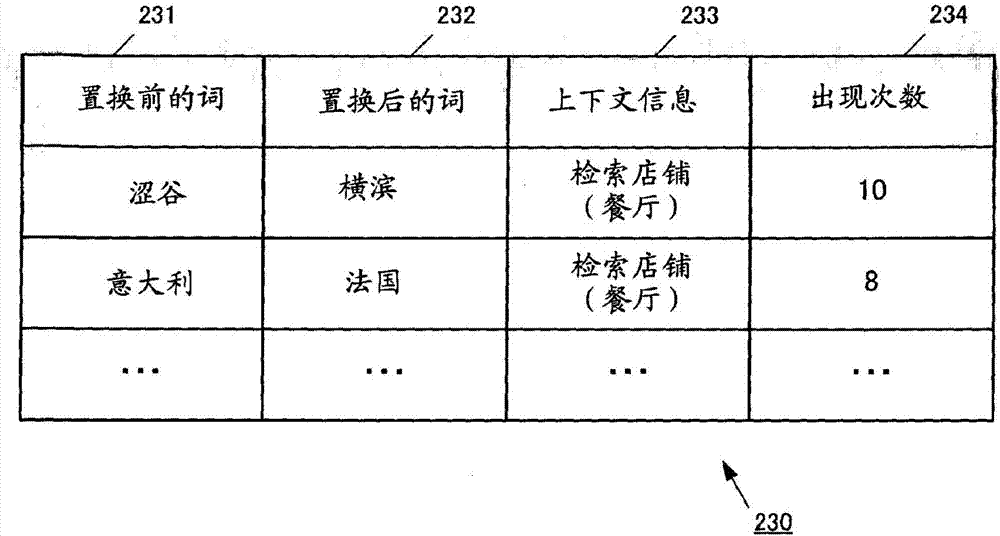
在此,“反問”是指,關于a要求之后的“不是a,而是b的情況?”這樣的發聲。例如,“檢索澀谷附近的意大利餐廳”這樣的要求之后的、“不是澀谷而是橫浜的話是怎么樣?”、“代替意大利餐廳而檢索法國餐廳”這樣的發聲相當于“反問”。
在美國專利號no.7353176、美國專利號no.8036877、美國專利號no.8515752中公開了考慮上下文來掌握反問的內容并準確地處理的內容。
然而,美國專利號no.7353176、美國專利號no.8036877、美國專利號no.8515752是以能夠應對反問為主要目標的發明,并未公開使反問處理快速化。
技術實現要素:
本發明的目的在于在聲音處理系統中,能夠針對反問的要求快速地應答。
本發明的聲音處理系統具備:聲音取得單元,取得用戶的發聲;聲音識別單元,識別聲音取得單元取得的發聲的內容;執行單元,根據所述聲音識別單元的結果執行處理;以及決定單元,決定代替某個詞的詞的候補。而且,在由所述聲音識別單元識別出包括第1詞的要求的情況下,通過所述執行單元執行包括所述第1詞的要求并將處理結果提供給所述用戶,并且通過所述決定單元決定作為所述第1詞的代替候補的第2詞,通過所述執行單元還執行代替所述第1詞而包括所述第2詞的要求并將處理結果存儲到存儲單元。
在本發明中,優選為在由所述聲音識別單元識別出包括所述第1詞的要求之后識別出代替所述第1詞而包括所述第2詞的要求的情況下,所述執行單元取得所述存儲單元中存儲的處理結果并提供給所述用戶。
這樣,利用決定單元決定成為反問的候補的詞的對,預先執行與反問的候補有關的處理并存儲結果,從而能夠縮短實際發生了將第1詞置換為第2詞的反問時的處理時間。
在本發明中,所述決定單元能夠將在從所述用戶取得了包括某個詞的要求之后從所述用戶取得了代替所述某個詞而包括其它詞的要求的次數,按照所述某個詞和所述其它詞的對存儲,將與輸入的詞成對的詞中的所述次數是閾值以上的詞決定為所述輸入的詞的代替候補。在此,“從所述用戶取得了代替所述某個詞而包括其它詞的要求的次數”可以是取得了指示為進行代替所述某個詞而包括其它詞的要求的發聲的次數。即,決定單元優選為將關于a的要求之后的、“代替a而b的情況?”那樣的反問的次數針對用語a和b的對進行存儲。此外,決定單元存儲的上述次數未必僅根據實際用戶的發聲內容來決定,關于設想為反問的頻度高的用語對,也可以將上述次數預先設定得較大。
另外,在本發明中,決定單元還能夠將某個詞和該詞的代替候補關聯起來存儲,將與輸入的詞關聯起來存儲的詞決定為該輸入的詞的代替候補。另外,決定單元也可以根據詞匯辭典判斷用語的類似性,將與輸入的詞類似的詞決定為代替候補。不論在哪一個情況下,都優選為還考慮發聲中的上下文來決定代替候補。
另外,在本發明中,還優選為在所述用戶在包括所述第1詞的要求之后代替包括所述第1詞的要求而發聲了包括所述第2詞的要求的情況下,所述聲音識別單元根據包括所述第1詞的要求的上下文信息決定所述第2詞的屬性,進行所述第2詞的識別。
雖然有同一詞根據上下文不同而具有不同的含意的情況,但在代替包括第1詞的要求而發聲了包括第2詞的要求的情況下,設想第1詞和第2詞具有相同的屬性。因此,通過考慮包括第1詞的要求的上下文信息,能夠精度良好地求出第2詞的屬性,能夠精度良好地識別第2詞。
根據本發明,在聲音處理系統中,能夠針對反問的要求快速地應答。
參照附圖,本發明的進一步特征將從以下具體實施例的描述中變得清晰。
附圖說明
圖1是示出實施方式的聲音處理系統的結構例的圖。
圖2是示出實施方式的詞對存儲部的例子的圖。
圖3是示出實施方式的聲音處理方法的流程的流程圖。
圖4是示出實施方式的聲音處理方法的流程的流程圖。
具體實施方式
以下,參照附圖,說明本發明的示例性的實施方式。此外,以下的說明示例地說明了本發明,本發明不限于以下的實施方式。
<反問>
在說明本實施方式的聲音處理系統之前,說明“反問”。設想用戶的發聲內容是針對聲音處理系統要求某種處理的狀況。例如,考慮進行“檢索澀谷附近處的意大利餐廳”這樣的要求的狀況。在之后用戶進行“檢索橫浜附近處的意大利餐廳”這樣的要求的情況下,考慮為“不是澀谷而是橫浜的話是怎么樣?”這樣發聲。在本說明書中,這樣將包括某個詞a的要求/指示之后的“不是a而是b的情況?”那樣的發聲稱為“反問”。在上述例子中,除了變更“澀谷”這樣的詞的反問以外,還設想將“意大利”變更為“法國”的反問。即,反問的模式設想與某個要求中包含的詞的數量相當的量。
<系統結構>
圖1是示出本實施方式的聲音處理系統的系統結構的圖。本實施方式的聲音處理系統是通過聲音處理服務器200識別車輛100內的用戶的發聲,并執行與發聲內容對應的處理來對車輛100內的用戶提供處理結果的系統。
車輛100具備包括聲音取得部110和信息提供部120的信息處理裝置(計算機)。信息處理裝置包括運算裝置、存儲裝置、輸入輸出裝置等,通過由運算裝置執行存儲裝置中保存的程序來提供下述的功能。
聲音取得部110由一個或者多個麥克風或者麥克風陣列構成,取得用戶發出的聲音。聲音取得部110取得的聲音通過無線通信被發送到聲音處理服務器200。此外,聲音取得部110不需要將所取得的聲音原樣地發送到聲音處理服務器200,而可以取得聲音的特征量并僅發送特征量。信息提供部120是用于將車輛100從聲音處理服務器200取得的信息提供給用戶的裝置,包括圖像顯示裝置、聲音輸出裝置等。
聲音處理服務器200具備包括聲音識別部210、執行部220、詞對存儲部230、決定部240的信息處理裝置(計算機)。信息處理裝置包括運算裝置、存儲裝置、輸入輸出裝置等,通過由運算裝置執行存儲裝置中保存的程序來提供下述的功能。
聲音識別部210是用于識別從車輛100的聲音取得部110發送的聲音,并掌握其內容(文本)以及含意的功能部。聲音識別部210根據詞匯辭典、語言模型,進行聲音識別。作為具體的聲音識別手法,能夠利用現有的任意的手法。在圖中記載為聲音識別部210僅從1臺車輛100取得聲音,但還能夠從許多車輛100取得聲音并識別。
此外,聲音識別部210在識別反問的發聲時,優選為根據反問之前的發聲內容的上下文來決定并識別反問中包含的詞的屬性等。在反問中被置換的詞是在同一上下文中使用的詞,所以能夠通過使用上下文信息來更高精度地識別反問中包含的詞。
執行部220是執行與利用聲音識別部210進行聲音識別的結果對應的處理的功能部。例如,如果用戶的發聲是要求取得滿足預定的條件的信息的發聲,則執行部220從檢索服務器300取得滿足該條件的信息,并發送給車輛100。
執行部220在從用戶受理了要求的情況下,推測所設想的反問,并執行與推測出的反問的要求對應的處理,將處理結果存儲到存儲部(未圖示)。即,執行部220預取(先取)所推測的反問的要求的結果。然后,在實際從用戶接受到反問的情況下,如果已預取到結果,則將其結果發送到車輛100。另外,執行部220在發生了反問的情況下,將哪個詞被哪個詞置換的情況記錄到詞對存儲部230。關于這些處理的詳細內容后述。
詞對存儲部230存儲反問中的置換前的詞和置換后的詞的對的出現次數。圖2是示出詞對存儲部230的表格結構的圖。詞對存儲部230保存置換前的詞231、置換后的詞232、上下文信息233、出現次數234。置換前的詞231是通過反問置換前的詞,置換后的詞232是通過反問置換后的詞。上下文信息233是確定發聲中的上下文的信息。出現次數234是通過利用上下文信息233確定的上下文而置換前的詞231被置換后的詞232置換的反問出現的次數。
此外,不需要僅根據實際發生的反問來決定詞對存儲部230中的出現次數。例如,在要求“檢索a”之后發生了“不是a而是b的情況?”這樣的反問的情況下,增加將詞a置換為詞b的反問的出現次數。此時,也可以增加將詞b置換為詞a的反問的出現次數。另外,在進而接下來繼續了“c的情況?”這樣的反問的情況下,增加將詞a置換為詞c的反問的出現次數。此時,除了增加將詞a置換為詞c的反問的出現次數以外,還可以增加將詞b置換為詞c的反問、將詞c置換為詞a的反問、將詞c置換為詞b的反問的出現次數。這是因為考慮在發生反問的情況下成為反問的對象的詞是可相互置換的緣故。
決定部240是在取得了來自用戶的發聲時,推測用戶的發聲的反問的功能部。決定部240參照詞對存儲部230,推測在反問中哪個詞被置換為哪個詞。具體而言,決定部240參照詞對存儲部230,將用戶的發聲中包含的詞以及該發聲的上下文中出現次數是閾值以上的詞對推測為在反問中被置換的詞對。在有多個閾值以上的詞對的情況下,詞候補決定部240選擇所有詞對即可。但是,也可以僅選擇居上位的預定數個的詞對。
<處理內容>
首先,參照圖3、圖4說明本實施方式的聲音處理系統中的處理。最初,在步驟s102中,聲音取得部110取得用戶的發聲并發送給聲音識別部210,聲音識別部210識別發聲的內容。在此,假設從用戶接受到“檢索從a到c的路徑”這樣的發聲。實際上,a、c是具體的地名、店鋪名等。另外,以下將該發聲表示為{a、c}。
在步驟s104中,聲音識別部210臨時地存儲當識別出發聲{a、c}時得到的上下文信息、各詞的領域。
在步驟s106中,執行部220執行與發聲{a、c}對應的處理,將其結果發送到車輛100。具體而言,執行部220對檢索服務器300發出求從a到c的路徑的要求,取得其結果。然后,執行部220將從檢索服務器300得到的處理結果發送到車輛100。在車輛100中,信息提供部120對用戶提供處理結果。
在步驟s108中,決定部240決定針對發聲{a、c}設想的反問中的候補詞。例如,決定對發聲{a、c}內的詞a進行置換的詞的候補集合{bi}。具體而言,決定部240參照詞對存儲部230,將置換前的詞是詞a且上下文信息與發聲{a、c}的上下文信息(已在s104中存儲)一致的記錄項中所包含的置換后的詞,決定為候補詞。在該說明中,僅說明置換詞a的候補詞,但同樣地決定置換詞c的候補詞也是優選的。
在步驟s110中,執行部220關于置換詞a的詞的候補集合{bi}的各個,進行與發聲內容{bi、c}對應的處理,即“檢索從bi到c的路徑”這樣的處理,并存儲到存儲裝置中。與步驟s102同樣地,通過對檢索服務器300發出要求來進行路徑的檢索即可。
在步驟s112中,取得來自用戶的反問的發聲,并識別其內容。在此,設想用戶反問“不是從a而是從b1的話是怎么樣?”的情況。以下,將這樣的反問表示為(a、b1)。聲音識別部210在識別詞b1時,考慮在步驟s104中存儲的發聲{a、c}的上下文信息、領域,來決定詞b1的屬性信息。例如,詞b1有具有地名和店鋪名等多個含意的情況,但聲音識別部210考慮發聲{a、c}的上下文信息等來能夠判斷為反問(a、b1)中的詞b1表示地名。
在步驟s114中,聲音處理服務器200更新詞對存儲部230。具體而言,將與置換前的詞是“a”、置換后的詞是“b1”、上下文信息是發聲{a、c}的上下文信息相應的記錄項的出現次數增加1。在不存在這樣的記錄項的情況下,新制作該記錄項而將其出現次數設為1即可。此時,也可以將置換前的詞是“b1”且置換后的詞是“a”的記錄項的出現次數增加1。這是因為考慮反問的詞的對是可雙向地交換的。
在步驟s116中,執行部220判斷是否已存儲(已預取){b1、c}即“從b1向c的路徑的檢索”的處理結果。如果已存儲,則執行部220從存儲部取得其結果,發送到車輛100。如果未已存儲,則執行{b1、c}的處理,并將其處理結果發送到車輛100。在車輛100中,信息提供部120對用戶提供該處理結果。
<本發明的有利的效果>
根據本發明,在受理了基于來自用戶的聲音的要求時,預想發生反問,預先執行與預想的反問對應的處理來預取結果。因此,在實際發生了反問時,無需進行處理就能夠立即返回結果。如本實施方式那樣,在針對外部服務器發出要求來進行處理的情況下花費幾秒程度的時間,但通過預取來能夠將該時間縮短為小于1秒。即,能夠使反問時的應答快速化。
另外,根據實際發生的反問次數來決定成為反問的對象的詞,所以能夠提高推測精度。如本實施方式那樣,在聲音處理服務器200一并處理來自多個車輛100的聲音的情況下,能夠存儲更多的反問的歷史,所以能夠進行精度更良好的推測。
另外,在發生了反問的情況下,利用反問之前的發聲的上下文信息、領域來識別反問中包含的詞的屬性信息,所以能夠進行精度良好的聲音識別。在車輛內由于道路噪聲等的影響而取得的聲音有時變得不清楚,但通過這樣利用上下文信息,在車輛內也能夠進行精度良好的聲音識別。
<變形例>
在上述實施方式中,根據實際產生的反問的次數推測成為反問的對象的詞,但成為反問的對象的詞的推測方法不限于上述方法。例如,決定部240也可以構成為具有詞匯辭典,在反問之前的發聲的上下文中,將與該發聲中包含的詞的類似度是閾值以上的詞推測為反問對象的詞。這樣,也能夠得到與上述同樣的效果。
另外,在反問對象的詞的推測中,重視進行該發聲的用戶的歷史也是優選的。在上述說明中,聲音處理服務器200將從各種車輛(用戶)得到的反問的發生次數存儲于詞對存儲部230中,但對每個用戶的反問次數進行計數,并根據用戶的反問次數推測反問也是優選的。由此,能夠進行反映了每個用戶的特征的推測。
在上述實施方式中,設想了車輛內的利用,但本發明的聲音處理系統的利用場景不限于車輛內,而能夠在任意的環境中利用。另外,以聲音取得部(麥克風)設置于車輛且聲音識別部和執行部設置于服務器的、所謂中心型的聲音處理系統為例子進行了說明,但既可以將這些所有功能包含于1個裝置來實施本發明,也可以通過以與上述不同的方式分擔了功能的結構來實施本發明。
- 還沒有人留言評論。精彩留言會獲得點贊!