智能語音交互方法及裝置與流程
本發明涉及語音信號處理領域,具體涉及一種智能語音交互方法及裝置。
背景技術:
隨著人工智能相關技術的日益成熟,人們的生活開始走向智能化,各種智能設備逐漸進入人們的日常生活中,如智能車機。語音交互作為智能設備應用中主流的交互方式之一,其方便快捷的優勢有目共睹,然而其交互的效果受環境影響較大,雖然現在已有較多成熟的技術方案提升語音交互的效果,但對于較為復雜的交互環境,其準確性還是難以得到很高的保證。如在車載環境下,受以下因素的影響:用戶離車機麥克風一般有一定的距離、車載環境下存在各種噪聲(如胎噪、空調噪聲、外界噪聲等)、用戶表達多樣化,對于用戶的交互語音可能會做出錯誤的理解,從而導致車機做出錯誤的響應,帶來較差的用戶體驗。
技術實現要素:
本發明實施例提供一種智能語音交互方法及裝置,以提高對人機交互語音理解的正確率,提升用戶體驗。
為此,本發明提供如下技術方案:
一種智能語音交互方法,所述方法包括:
獲取人機交互語音數據;
對所述人機交互語音數據進行語義理解,得到當前語義理解結果;
判斷所述當前語義理解結果是否可信,并對可信語義理解結果做出響應;
當語義理解結果不可信時,基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正,得到校正后的語義理解結果;然后對所述校正后的語義理解結果做出響應。
優選地,所述方法還包括:
接收交互語音數據;
判斷所述交互語音數據的類型,所述交互語音數據的類型包括:人人交互數據和人機交互數據;
如果所述交互語音數據為人人交互數據,則對所述人人交互數據進行處理,并存儲處理后的人人交互數據的相關信息。
優選地,所述方法還包括:預先構建語音交互環境判斷模型;
所述判斷所述交互語音數據的類型包括:
提取所述交互語音數據的類別特征;
將所述類別特征輸入所述語音交互環境判斷模型,根據所述語音交互環境判斷模型的輸出判斷所述交互語音數據的類型。
優選地,所述類別特征包括以下任意兩種或多種:是否有喚醒詞、喚醒后間隔時間、與上一句時間間隔、與上一句內容的關聯度、聲源定位信息。
優選地,所述人人交互數據的相關信息包括:人人交互數據產生的時間信息及對人人交互數據進行處理后得到的處理結果;
所述對所述人人交互數據進行處理包括:
對所述人人交互數據進行語音識別,得到識別文本;
對所述識別文本進行語義理解,得到所述人人交互數據對應的語義理解結果;
所述存儲處理后的人人交互數據的相關信息包括:
將所述人人交互數據產生的時間信息、語義理解結果存儲到數據庫中。
優選地,所述基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正,得到校正后的語義理解結果包括:
在所述數據庫中搜索得到數條在預設時間內與所述當前語義理解結果相關的所述人人交互數據的相關信息,并將所述相關信息作為候選校準信息;
對于每個候選校準信息,依次用該候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息,得到候選語義理解結果,并計算替換得分,每個語意槽信息對應語義理解結果中的一部分;
將總替換得分最高的候選語義理解結果作為校正結果。
優選地,所述方法還包括:預先構建數據相關性判斷模型;
所述在所述數據庫中搜索得到數條在預設時間內與所述當前語義理解結果相關的所述人人交互數據的相關信息,并將所述相關信息作為候選校準信息包括:
將人機交互數據的識別文本的文本向量、數據庫中人人交互數據的識別文本的文本向量、人人交互數據產生的時間信息和人機交互數據產生的時間信息輸入所述數據相關性判斷模型,得到數據庫中各人人交互數據的相關信息與該人機交互數據的相關性;
將不超過設定個數的相關性最高的人人交互數據的相關信息或者相關性大于設定閾值的人人交互數據的相關信息作為候選校準信息。
優選地,所述方法還包括:預先構建語義槽替換判斷模型,預先設定各語義槽的權重;
所述依次用該候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息,得到候選語義理解結果,并計算替換得分包括:
將候選校準信息中的各語義槽信息、當前語義理解結果中對應的各語義槽信息、人人交互數據產生的時間信息、人機交互數據產生的時間信息和當前車機狀態輸入所述語義槽替換判斷模型,得到候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息的概率;
將各概率的加權和作為候選語義理解結果的得分。
優選地,所述人人交互數據包括以下任意一種或多種:
乘客交談語音數據、乘客電話語音數據、乘客視頻語音數據。
相應地,本發明還提供了一種智能語音交互裝置,所述裝置包括:
獲取模塊,用于獲取人機交互語音數據;
語義理解模塊,用于對所述人機交互數據進行語義理解,得到當前語義理解結果;
可信度判斷模塊,用于判斷所述當前語義理解結果是否可信;
校正模塊,用于當語義理解結果不可信時,基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正,得到校正后的語義理解結果;
響應模塊,用于對可信語義理解結果做出響應或者對所述校正后的語義理解結果做出響應。
優選地,所述裝置還包括:
語音接收模塊,用于接收交互語音數據;
類型判斷模塊,用于判斷所述交互語音數據的類型,所述交互語音數據的類型包括:人人交互數據和人機交互數據;
處理模塊,用于在所述交互語音數據為人人交互數據時,對所述人人交互數據進行處理;
存儲模塊,用于存儲處理后的人人交互數據的相關信息。
優選地,所述裝置還包括:
語音交互環境判斷模型構建模塊,用于預先構建語音交互環境判斷模型;
所述類型判斷模塊包括:
特征提取單元,用于提取所述交互語音數據的類別特征;
類型輸出單元,用于將所述類別特征輸入所述語音交互環境判斷模型,根據所述語音交互環境判斷模型的輸出判斷所述交互語音數據的類型。
優選地,所述人人交互數據的相關信息包括:人人交互數據產生的時間信息及對人人交互數據進行處理后得到的處理結果;
所述處理模塊包括:
文本獲取單元,用于對所述人人交互數據進行語音識別,得到識別文本;
語義理解單元,用于對所述識別文本進行語義理解,得到所述人人交互數據對應的語義理解結果;
所述存儲模塊具體用于將所述人人交互數據產生的時間信息、語義理解結果存儲到數據庫中。
優選地,所述校正模塊包括:
候選校準信息獲取單元,用于在所述數據庫中搜索得到數條在預設時間內與所述當前語義理解結果相關的所述人人交互數據的相關信息,并將所述相關信息作為候選校準信息;
替換得分計算單元,用于對于每個候選校準信息,依次用該候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息,得到候選語義理解結果,并計算替換得分,每個語意槽信息對應語義理解結果中的一部分;
校正結果獲取單元,用于將總替換得分最高的候選語義理解結果作為校正結果。
優選地,所述裝置還包括:
數據相關性判斷模型構建模塊,用于預先構建數據相關性判斷模型;
所述候選校準信息獲取單元包括:
相關性獲取子單元,用于將人機交互數據的識別文本的文本向量、數據庫中人人交互數據的識別文本的文本向量、人人交互數據產生的時間信息和人機交互數據產生的時間信息輸入所述數據相關性判斷模型,得到數據庫中各人人交互數據的相關信息與該人機交互數據的相關性;
候選校準信息獲取子單元,用于將不超過設定個數的相關性最高的人人交互數據的相關信息或者相關性大于設定閾值的人人交互數據的相關信息作為候選校準信息。
優選地,所述裝置還包括:
語義槽替換判斷模型構建模塊,用于預先構建語義槽替換判斷模型;
權重設定模塊,用于預先設定各語義槽的權重;
所述替換得分計算單元包括:
替換概率獲取子單元,用于將候選校準信息中的各語義槽信息、當前語義理解結果中對應的各語義槽信息、人人交互數據產生的時間信息、人機交互數據產生的時間信息和當前車機狀態輸入所述語義槽替換判斷模型,得到候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息的概率;
候選得分獲取子單元,用于將各概率的加權和作為候選語義理解結果的得分。
本發明實施例提供的智能語音交互方法及裝置,在獲取人機交互語音數據之后,對所述人機交互語音數據進行語義理解,得到當前語義理解結果,然后判斷所述當前語義理解結果是否可信,并對可信語義理解結果做出響應,當語義理解結果不可信時,基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正,得到校正后的語義理解結果;然后對所述校正后的語義理解結果做出響應。由于現有車載環境下的智能交互方法,只利用了人機交互信息,例如上一次人機交互時的交互信息,然而車內用戶與其他乘客交談,與他人打電話等過程中都隱含著與車機業務相關的信息,本發明采用人人交互數據的相關信息來校正人機交互中意圖理解,例如,駕駛員通過語音設定導航目的地之前的一段時間內,可能會與其他乘員討論要去的地方(即導航的目的地),當噪聲等環境因素導致人機交互的語義理解結果不可信時,可以根據駕駛員與其他乘員討論產生的人人交互數據進行校正,得到校正后的語義理解結果,并進行響應。這樣可以更加全面的利用現有的車載環境下的交互信息,提高對人機交互語音理解的正確率,提升用戶體驗。
進一步地,本發明實施例提供的智能語音交互方法及裝置,還給出了人人交互數據的相關信息的獲取方法;接收交互語音數據,包括人人交互和人機交互,然后對該交互語音數據進行分類來獲取人人交互數據,這樣的好處是這兩種數據的相關性更高,使得獲取的人人交互數據的校正參考價值更高。
進一步地,本發明實施例提供的智能語音交互方法及裝置,還預先構建了語音交互環境判斷模型,利用該模型可以準確判斷接收的交互語音數據的類型。
進一步地,本發明實施例提供的智能語音交互方法及裝置,還提供了基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正的具體方法,通過對語義槽信息進行替換,并計算替換得分,這樣可以量化替換的效果,便于根據得分準確判斷該替換過程是否提升了語義理解結果的可信度。
進一步地,本發明實施例提供的智能語音交互方法及裝置,從存儲的相關信息中篩選出相關性高的相關信息作為候選校準信息,這樣有效減少了校正數據的數量,且有效排除了不相關信息,有助于提升校正的準確度。
進一步地,本發明實施例提供的智能語音交互方法及裝置,還設定了各語義槽的權重:給更重要的語義槽設定更大的權重,有助于提升人機交互語音理解的正確率。
附圖說明
為了更清楚地說明本申請實施例或現有技術中的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明中記載的一些實施例,對于本領域普通技術人員來講,還可以根據這些附圖獲得其他的附圖。
圖1是本發明實施例智能語音交互方法的一種流程圖;
圖2是本發明實施例對所述當前語義理解結果進行校正的一種流程圖;
圖3是本發明實施例獲取候選校準信息的一種流程圖;
圖4是本發明實施例獲取候選語義理解結果并計算替換得分的一種流程圖;
圖5是本發明實施例智能語音交互裝置的第一種結構示意圖;
圖6是本發明實施例智能語音交互裝置的第二種結構示意圖;
圖7是本發明實施例類型判斷模塊的一種結構示意圖;
圖8是本發明實施例相關信息獲取模塊的一種結構示意圖;
圖9是本發明實施例校正模塊的一種結構示意圖。
具體實施方式
為了使本技術領域的人員更好地理解本發明實施例的方案,下面結合附圖和實施方式對本發明實施例作進一步的詳細說明。
現有車載環境下的智能交互方法,在進行語義理解時,一般是針對該輪交互進行語義理解。然而在一些人機交互的環境中,還會有一些人人交互的語音,而這些人人交互的語音通常會包含有與人機交互內容相關的信息,比如車內用戶與其他乘客交談、或者與他人打電話過程中大都隱含著與車機業務相關的信息,這些信息對提升人機交互中意圖理解有較大幫助。為此,本發明實施例提供一種智能交互方法及裝置,利用多重語音信息輔助用戶意圖理解完成智能交互,由于充分利用了各種可利用的信息,因此,可進一步提高語義理解的準確性,提升用戶體驗。
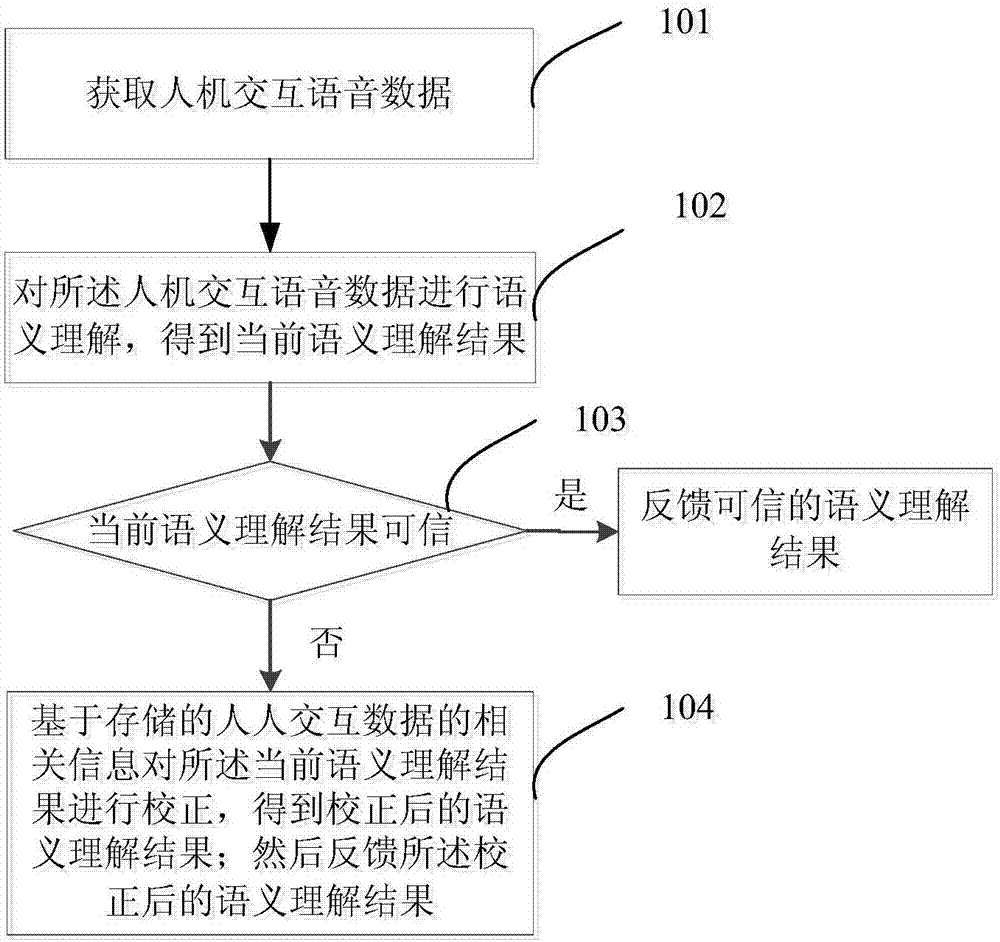
如圖1所示,是本發明實施例智能語音交互方法的一種流程圖,包括以下步驟:
步驟101,獲取人機交互語音數據。
在本實施例中,該人機交互數據可以是包括喚醒詞的人機交互數據,當然,也可以是通過其它現有技術獲取的人機交互數據,在此不做限定。
需要說明的是,所述人機交互語音數據是指去除噪聲后的有效語音數據。而且,在人機交互的場景下,時常還會存在人人交互的語音,因此,在本發明實施例中,在接收到人機交互語音數據的同一時間段內,還可能會存在人人交互數據。比如,在車載環境下,所述交互語音數據可以是用戶與車機的人機交互數據,以及車內的人人交互數據,如乘客交談語音數據、乘客電話語音數據、乘客視頻語音數據等,該人人交互數據中可能包含可對人機交互數據進行校正的有用信息。
在一個具體實施例中,所述方法還包括:
首先,接收交互語音數據,該交互語音數據可以為通過麥克風等裝置采集的語音數據。由于一段時間內的語音數據可能包含人機交互數據和人人交互數據。因此,在接收到交互語音數據后,判斷所述交互語音數據的類型。具體可以采用現有技術中確定人機交互數據的方法確定人機交互數據,例如,將同一時間段內的非人機交互數據的語音數據作為人人交互數據即可。
如果是人人交互數據,可以將其存入相應的數據庫中,以便后續利用這些人人交互數據對人機交互語音數據進行語義理解得到的語義理解結果進行校正。此外,在實際應用中,也可以預先構建人人交互數據庫,然后通過分類、語義理解等技術手段從該數據庫中篩選出用于校正的候選人人交互數據,在此不做限定。
進一步地,本發明還可以對得到的人人交互數據進行處理,以獲取所述人人交互數據的相關信息。例如,如果所述交互語音數據為人人交互數據,則對所述人人交互數據進行處理,并存儲處理后的人人交互數據的相關信息。
人人交互數據產生的時間信息可以根據接收交互語音數據的時間來得到。其中,對人人交互數據進行處理具體可以包括:首先對所述人人交互數據進行語音識別,得到識別文本,然后對所述識別文本進行語義理解,得到所述人人交互數據對應的語義理解結果,語義理解過程可以同現有技術,當然,也可以與人機交互數據的語義理解過程相同。所述存儲處理后的人人交互數據的相關信息包括:將所述人人交互數據產生的時間信息、語義理解結果存儲到數據庫中。
相應地,在存儲時,為了后續查找方便,可以將上述時間信息、語義理解結果等信息做成數據索引結構,進行存儲。
在其他實施例中,還可以通過預先訓練的語音交互環境判斷模型來判斷所述交互語音數據的類型,這樣可以有效提升判斷語音數據的類型的準確度。例如,在接收到交互語音數據后,對該交互語音數據類型的判斷可以利用分類或回歸模型如cnn(卷積神經網絡)、dnn(深度神經網絡)、rnn(循環神經網絡)、svm(支持向量機)等來進行判斷。
比如,可以預先構建語音交互環境判斷模型,該模型的具體構建過程如下步驟:
(1)確定語音交互環境判斷模型的拓撲結構。
其中,所述類別特征包括以下任意兩種或多種:是否有喚醒詞、喚醒后間隔時間、與上一句時間間隔、與上一句內容的關聯度、聲源定位信息。具體地,模型的輸入可以是提取的類別特征:是否有喚醒詞(可以為1維向量,如有喚醒詞為1,沒有為0)、喚醒后間隔時間、與上一句時間間隔、與上一句內容的關聯度(可以為語義理解結果的相似度,例如文本向量的相似度)、聲源定位信息(比如,在車載環境,可以為一個5維的向量,每一維分別表示主駕駛、副駕駛、后左、后中、后右)等。需要說明的是,輸入的類別特征都是以vad(語音端點檢測)斷句后一個句子為分析對象。
模型的輸出可以是交互語音數據的類型,如輸出為2個節點,分別為人人交互數據和人機交互數據,屬于哪種類型哪種輸出為1,否則為0;當然,模型的輸出也可以是所屬環境的概率。
(2)收集大量交互語音數據作為訓練數據,并對所述訓練數據進行交互環境標注。
(3)提取所述訓練數據的類別特征。
(4)利用所述類別特征及標注信息訓練得到模型參數。
相應地,在利用該語音交互環境判斷模型對接收的交互語音數據進行類型判斷時,需要提取所述交互語音數據的類別特征;然后將提取的類別特征輸入該語音交互環境判斷模型,根據語音交互環境判斷模型的輸出判斷所述交互語音數據的類型。如果采用回歸模型,則模型的輸出為所屬環境的概率,選取概率最大的環境對應的語音數據類型作為所述交互語音數據的類型。
步驟102,對所述人機交互語音數據進行語義理解,得到當前語義理解結果。
對人機交互數據進行語義理解,需要先對人機交互數據進行語音識別,得到識別文本,然后再對所述識別文本進行語義理解,得到語義理解結果,所述語義理解結果包括語義理解內容及對應的置信度。
所述語音識別可采用現有相關技術,在此不再詳細描述,所述語義理解可以采用與對人人交互數據進行語義理解同樣的方法。
具體地,語義理解結果可以包括語義理解結果對應的置信度,以及以下任意一種或多種:意圖類別、原始語義和詞集語義。其中,意圖類別為:人機數據的意圖歸類,如查詢目的地、路況、天氣、聽音樂等,具體可根據收集的現有網絡數據及對應的標定結果訓練意圖類別判斷模型,該意圖類別判斷模型可以為回歸模型也可以為分類模型,本實施例以svm為例進行說明,其輸入為人人交互數據的文本向量,輸出為意圖判斷結果。原始語義可采用現有語義理解相關技術實現,如基于文法網絡等,需要說明的是:此處文本語義理解可以是利用歷史人機交互數據的語義理解,也可以是不考慮歷史人機交互數據的語義理解,對此本案不做限定。詞集語義為利用已知的同義詞、集合詞關系,對原始語義進行歸一化。比如用戶說的目的地是“kfc”,根據同義詞關系,映射成目的地“肯德基”,通過詞集語義映射后的目的地信息能更好的作為poi搜索的條件,另外,詞集語義映射還包括對poi的類型進行確定,比如道路,火鍋店,公園等(利用更多的poi類型信息做到更精確的搜索)。需要說明的是,采用詞集語義相對于采用原始語義能提升最終結果的可信度。
步驟103,判斷所述當前語義理解結果是否可信,并對可信語義理解結果做出響應。
具體地,可以根據各語義理解結果的置信度來判斷對應的語義理解結果是否可信,如果語義理解結果對應的置信度大于設定閾值,則確定該語義理解結果可信;否則確定該語義理解結果不可信。所述閾值可以根據實際應用情況和/或大量實驗、經驗確定。
對可信語義理解結果做出響應可以根據應用需要而定,可以有多種響應方式,比如,根據所述語義理解結果生成響應文本,并通過語音播報的方式將所述響應文本反饋給用戶;再比如,可以是執行語義理解結果對應的動作等。
步驟104,基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正,得到校正后的語義理解結果;然后對所述校正后的語義理解結果做出響應。
具體地,如圖2所示,是本發明實施例對所述當前語義理解結果進行校正的一種流程圖,可以包括以下步驟:
步驟201,在所述數據庫中搜索得到數條在預設時間內與所述當前語義理解結果相關的所述人人交互數據的相關信息,并將所述相關信息作為候選校準信息。
例如,可以為在預設時間內,與當前語義理解結果的文本向量的相似距離小于預設閾值的人人交互數據的相關信息,當然,也可以采用訓練的模型來確定候選校準信息,在此不做限定。
步驟202,對于每個候選校準信息,依次用該候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息,得到候選語義理解結果,并計算替換得分,每個語意槽信息對應語義理解結果中的一部分。
步驟203,將總替換得分最高的候選語義理解結果作為校正結果。
需要說明的是,校正后的語義理解結果的響應方式可以同步驟105,在此不再詳述。
本發明實施例提供的智能語音交互方法及裝置,在獲取人機交互語音數據之后,對所述人機交互語音數據進行語義理解,得到當前語義理解結果,然后判斷所述當前語義理解結果是否可信,并對可信語義理解結果做出響應,當語義理解結果不可信時,基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正,得到校正后的語義理解結果;然后對所述校正后的語義理解結果做出響應。由于現有車載環境下的智能交互方法,只利用了人機交互信息,然而車內用戶與其他乘客交談,與他人打電話等過程中都隱含著與車機業務相關的信息,本發明在噪聲等環境因素導致人機交互的語義理解結果不可信時,可以根據人人交互數據的語義理解結果對人機交互數據的語義理解結果進行校正,得到校正后的語義理解結果,并進行響應。這樣可以更加全面的利用現有的車載環境下的交互信息,提高對人機交互語音理解的正確率,提升用戶體驗。
如圖3所示,是本發明實施例獲取候選校準信息的一種流程圖。在本實施例中,所述方法還包括:預先構建數據相關性判斷模型。所述在所述數據庫中搜索得到數條在預設時間內與所述當前語義理解結果相關的所述人人交互數據的相關信息,并將所述相關信息作為候選校準信息包括:
步驟301,將人機交互數據的識別文本的文本向量、數據庫中人人交互數據的識別文本的文本向量、人人交互數據產生的時間信息和人機交互數據產生的時間信息輸入所述數據相關性判斷模型,得到數據庫中各人人交互數據的相關信息與該人機交互數據的相關性。
具體地,可通過回歸模型(如dnn、rnn等)得到預設時間內每條人人數據與當前人機交互數據的相關性。以dnn為例,模型的輸入為當前人機交互數據的文本向量、人人交互數據的文本向量、人人交互數據時間和人機交互數據實際,輸出為人人交互數據與當前人機交互數據的相關性,可以是一個0-1之間的值。
步驟302,將不超過設定個數的相關性最高的人人交互數據的相關信息或者相關性大于設定閾值的人人交互數據的相關信息作為候選校準信息。
具體地,將相關性大于設定閾值的對應人人交互數據的相關信息作為當前人機交互語義理解結果相關的數個候選人人交互數據的相關信息。此外,為了簡化計算,也可以是時間相近的數條人人交互數據,在此不做限定。
如圖4所示,是本發明實施例獲取候選語義理解結果并計算替換得分的一種流程圖。在本實施例中,所述方法還包括:預先構建語義槽替換判斷模型,預先設定各語義槽的權重。所述依次用該候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息,得到候選語義理解結果,并計算替換得分包括:
步驟401,將候選校準信息中的各語義槽信息、當前語義理解結果中對應的各語義槽信息、人人交互數據產生的時間信息、人機交互數據產生的時間信息和當前車機狀態輸入所述語義槽替換判斷模型,得到候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息的概率。
其中,語義理解結果校正主要指利用人人交互數據對應語義槽信息校正當前人機交互數據對應語義槽信息。語義槽信息反應的就是語義理解結果中的一個個信息。
具體地,通過神經網絡模型(如dnn、cnn、rnn等)來判斷候選校準信息的每個語義槽能否將對應人機交互數據的語義槽替換,以dnn網絡為例,模型的輸入為當前人機交互數據每個語義槽信息(如目的地)、候選校準信息對應的每個語義槽信息(對應為人人交互數據的目的地)、當前人機交互數據時間、候選校準信息對應的人人交互數據時間、當前車機狀態(如導航界面、音樂界面);輸出為人人交互數據的各語義槽信息替換對應人機交互數據的各語義槽信息的概率(0-1之間)。其中,語義槽替換判斷模型的訓練過程可以同現有的神經網絡模型訓練方法,在此不再詳述。
步驟402,將各概率的加權和作為候選語義理解結果的得分。
每個候選校準信息對應替換后(即校正后)的一個語義理解結果,該語義理解結果得分為替換后每個語義槽的得分加權和,根據槽信息的重要程度設定不同槽的權重,也可以設定各語義槽的權重都為1,其中,權重可以根據經驗設定或者通過大量現有網絡數據訓練模型得到,如導航時,出發地、目的地對應的語義槽的權重應該高于途徑地對應的語義槽的權重。在這里,被替換的語義槽的替換得分為上述替換概率,未替換的語義槽的替換得分為1。根據數個候選校準信息,校正當前人機交互數據的語義理解結果得到替換得分,選擇對應總替換得分最高的語義理解結果作為最終當前人機交互語義理解結果。
以下舉例進行說明:當前人機交互數據語義理解結果:出發點—北京、目的地—南昌、意圖—導航,如果語義理解結果為不可信,則需要對人機交互數據的語義結果進行校正。
根據數據相關性判斷模型,得到2個對應的人人交互數據的相關信息作為候選校準信息,分別為:1、出發點—天津、目的地—南京、意圖—導航,2、出發點—北京、目的地——南京、意圖—導航。
根據語義槽替換判斷模型得到候選校準信息1中,出發點對應替換得分為0.3、目的地對應替換得分為0.8、意圖替換得分為1,則根據候選校準信息1校正后的語義理解結果得分為2.1分。候選校準信息2中,出發點對應替換得分為1、目的地對應替換得分為0.8、意圖替換得分為1,則根據候選校正信息2校正后的語義理解結果得分為2.8分。則最后將基于候選校準信息2校正后的語義理解結果作為可信度最高的語義理解結果,然后進行響應。
本發明實施例提供的智能語音交互方法,還提供了基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正的具體方法,通過對語義槽信息進行替換,并計算替換得分,這樣可以量化替換的效果,便于根據得分準確判斷該替換過程是否提升了語義理解結果的可信度。
相應地,本發明還提供了一種智能語音交互裝置,如圖5所示,是本發明實施例智能語音交互裝置的第一種結構示意圖。所述裝置包括:
獲取模塊501,用于獲取人機交互語音數據。
語義理解模塊502,用于對所述人機交互數據進行語義理解,得到當前語義理解結果。
可信度判斷模塊503,用于判斷所述當前語義理解結果是否可信。
校正模塊504,用于當語義理解結果不可信時,基于存儲的人人交互數據的相關信息對所述當前語義理解結果進行校正,得到校正后的語義理解結果。
響應模塊505,用于對可信語義理解結果做出響應或者對所述校正后的語義理解結果做出響應。
在本實施例中,為了提升判斷語音數據的類型的準確度,所述裝置還可以包括:
語音接收模塊,用于接收交互語音數據。
類型判斷模塊5012,用于判斷所述交互語音數據的類型,所述交互語音數據的類型包括:人人交互數據和人機交互數據。
處理模塊5013,用于在所述交互語音數據為人人交互數據時,對所述人人交互數據進行處理。
存儲模塊,用于存儲處理后的人人交互數據的相關信息。
如圖6所示,是本發明實施例智能語音交互裝置的第二種結構示意圖。在實際應用中,可以通過預先構建的語音交互環境判斷模型來判斷所述交互語音數據的類型,具體地,所述裝置還包括:
語音交互環境判斷模型構建模塊601,用于預先構建語音交互環境判斷模型。
在本實施例中,如圖7所示,是本發明實施例類型判斷模塊5012的一種結構示意圖,其中,所述類型判斷模塊5012包括:
特征提取單元50121,用于提取所述交互語音數據的類別特征。
類型輸出單元50122,用于將所述類別特征輸入所述語音交互環境判斷模型,根據所述語音交互環境判斷模型的輸出判斷所述交互語音數據的類型。
其中,所述人人交互數據的相關信息包括:人人交互數據產生的時間信息及對人人交互數據進行處理后得到的處理結果。
如圖8所示,是本發明實施例處理模塊5013的一種結構示意圖,所述處理模塊5013包括:
文本獲取單元50131,用于對所述人人交互數據進行語音識別,得到識別文本。
語義理解單元50132,用于對所述識別文本進行語義理解,得到所述人人交互數據對應的語義理解結果。需要說明的是,語義理解模塊可以與語義理解單元為同一功能塊,在此不做限定。
所述存儲模塊具體用于將所述人人交互數據產生的時間信息、語義理解結果存儲到數據庫中。
進一步地,本發明還給出了校正模塊504的具體結構,如圖9所示,是本發明實施例校正模塊504的一種結構示意圖,所述校正模塊504包括:
候選校準信息獲取單元5041,用于在所述數據庫中搜索得到數條在預設時間內與所述當前語義理解結果相關的所述人人交互數據的相關信息,并將所述相關信息作為候選校準信息。
替換得分計算單元5042,用于對于每個候選校準信息,依次用該候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息,得到候選語義理解結果,并計算替換得分,每個語意槽信息對應語義理解結果中的一部分。
校正結果獲取單元5043,用于將總替換得分最高的候選語義理解結果作為校正結果。
優選地,所述裝置還包括:
數據相關性判斷模型構建模塊901,用于預先構建數據相關性判斷模型。
其中,所述候選校準信息獲取單元5041包括:
相關性獲取子單元50411,用于將人機交互數據的識別文本的文本向量、數據庫中人人交互數據的識別文本的文本向量、人人交互數據產生的時間信息和人機交互數據產生的時間信息輸入所述數據相關性判斷模型,得到數據庫中各人人交互數據的相關信息與該人機交互數據的相關性。
候選校準信息獲取子單元50412,用于將不超過設定個數的相關性最高的人人交互數據的相關信息或者相關性大于設定閾值的人人交互數據的相關信息作為候選校準信息。
此外,所述裝置還可以包括:
語義槽替換判斷模型構建模塊902,用于預先構建語義槽替換判斷模型。
權重設定模塊903,用于預先設定各語義槽的權重。
所述替換得分計算單元5042包括:
替換概率獲取子單元50421,用于將候選校準信息中的各語義槽信息、當前語義理解結果中對應的各語義槽信息、人人交互數據產生的時間信息、人機交互數據產生的時間信息和當前車機狀態輸入所述語義槽替換判斷模型,得到候選校準信息中的各語義槽信息替換當前語義理解結果中對應的語義槽信息的概率。
候選得分獲取子單元50422,用于將各概率的加權和作為候選語義理解結果的得分。
本發明實施例提供的智能語音交互裝置,與現有技術相比,還包括:校正模塊504,由于現有車載環境下的智能交互方法,只利用了人機交互信息,然而車內用戶與其他乘客交談,與他人打電話過程中都隱含著與車機業務相關的信息,本發明基于存儲的人人交互數據的相關信息對提升人機交互中意圖理解有較大幫助,如果人機交互信息數據的語義理解結果不可信,則校正模塊504會對所述當前語義理解結果進行校正,得到校正后的語義理解結果。這樣可以更加全面的利用現有的車載環境下的交互信息,提高對人機交互語音理解的正確率,提升用戶體驗。
本說明書中的各個實施例均采用遞進的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。尤其,對于裝置實施例而言,由于其基本相似于方法實施例,所以描述得比較簡單,相關之處參見方法實施例的部分說明即可。以上所描述的裝置實施例僅僅是示意性的,其中所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部模塊來實現本實施例方案的目的。本領域普通技術人員在不付出創造性勞動的情況下,即可以理解并實施。
以上對本發明實施例進行了詳細介紹,本文中應用了具體實施方式對本發明進行了闡述,以上實施例的說明只是用于幫助理解本發明的方法及裝置;同時,對于本領域的一般技術人員,依據本發明的思想,在具體實施方式及應用范圍上均會有改變之處,綜上所述,本說明書內容不應理解為對本發明的限制。
- 還沒有人留言評論。精彩留言會獲得點贊!