音頻轉(zhuǎn)手語方法、裝置、設備、可讀存儲介質(zhì)和程序產(chǎn)品與流程
本申請涉及音頻處理,特別是涉及一種音頻轉(zhuǎn)手語方法、裝置、設備、可讀存儲介質(zhì)和程序產(chǎn)品。
背景技術:
1、為了增強網(wǎng)絡的無障礙性,使聽障人士在瀏覽包含音頻內(nèi)容的網(wǎng)站時能更好地理解和接收信息,傳統(tǒng)方法中,主要在服務器中處理實時音頻轉(zhuǎn)手語,然而,這種方法存在延時高、資源消耗大等問題,尤其是在實時交互場景下表現(xiàn)不佳。此外,手語動畫的生成往往局限于離線處理,無法滿足實時性要求。
技術實現(xiàn)思路
1、基于此,有必要針對上述技術問題,提供一種能夠提高音頻轉(zhuǎn)手語的實時性的音頻轉(zhuǎn)手語方法、裝置、計算機設備、計算機可讀存儲介質(zhì)和計算機程序產(chǎn)品。
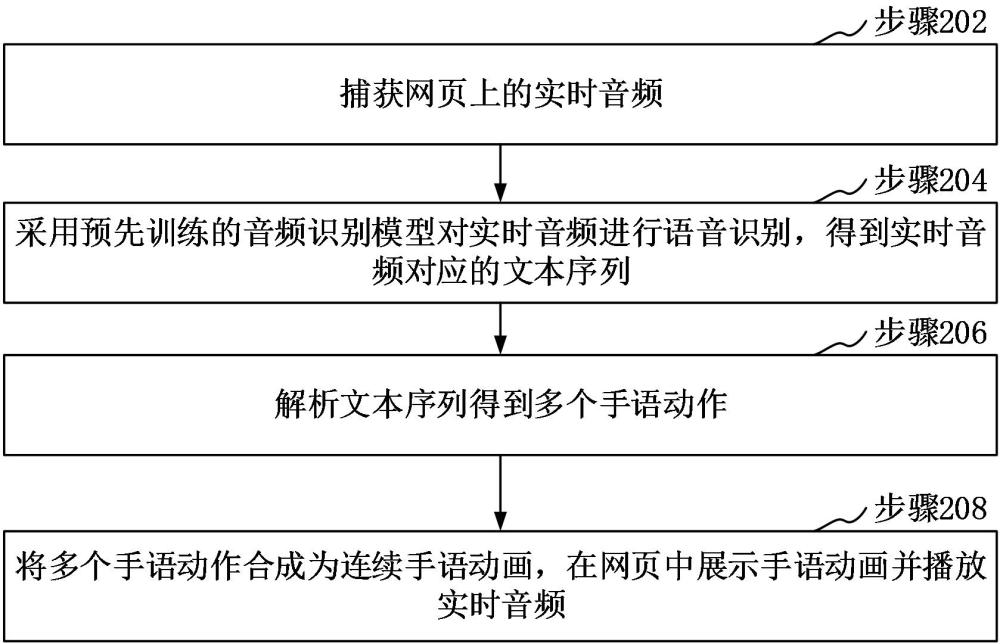
2、第一方面,本申請?zhí)峁┝艘环N音頻轉(zhuǎn)手語方法,包括:
3、捕獲網(wǎng)頁上的實時音頻;
4、采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列;
5、解析文本序列得到多個手語動作;
6、將多個手語動作合成為連續(xù)手語動畫,在網(wǎng)頁中展示手語動畫并播放實時音頻。
7、在其中一個實施例中,采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列,包括:
8、對實時音頻進行預處理,預處理包括噪聲抑制、自動增益控制以及回聲消除;
9、采用預先訓練的音頻識別模型對預處理后的音頻進行語音識別,得到實時音頻對應的文本序列。
10、在其中一個實施例中,采用預先訓練的音頻識別模型對預處理后的音頻進行語音識別,得到實時音頻對應的文本序列,包括:
11、對預處理后的音頻進行特征提取,得到音頻識別模型可理解的特征向量;
12、采用預先訓練的音頻識別模型對特征向量進行語音識別,得到實時音頻對應的文本序列。
13、在其中一個實施例中,解析文本序列得到多個手語動作,包括:
14、對文本序列進行文本預處理,得到多個處理后的文本詞,文本預處理包括文本清洗、詞法分析、語法分析、命名實體識別;
15、將每個處理后的文本詞轉(zhuǎn)換為對應的語義向量;
16、通過預先訓練的序列到序列模型將多個語義向量轉(zhuǎn)化為動作序列;
17、基于動作序列,確定多個手語動作。
18、在其中一個實施例中,基于動作序列,確定多個手語動作,包括:
19、獲取預設手語詞匯庫,預設手語詞匯庫中存儲了手語詞匯與手語動作的對應關系;
20、基于預設手語詞匯庫,將動作序列中的具有組合關系的多個動作映射為對應的手語動作,得到多個手語動作。
21、在其中一個實施例中,音頻轉(zhuǎn)手語方法還包括:
22、渲染手語動畫,并在網(wǎng)頁中展示渲染后的手語動畫。
23、第二方面,本申請還提供了一種音頻轉(zhuǎn)手語裝置,包括:
24、捕獲模塊,用于捕獲網(wǎng)頁上的實時音頻;
25、識別模塊,用于采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列;
26、解析模塊,用于解析文本序列得到多個手語動作;
27、展示模塊,用于將多個手語動作合成為連續(xù)手語動畫,在網(wǎng)頁中展示手語動畫并播放實時音頻。
28、第三方面,本申請還提供了一種計算機設備,包括存儲器和處理器,存儲器存儲有計算機程序,處理器執(zhí)行計算機程序時實現(xiàn)以下步驟:
29、捕獲網(wǎng)頁上的實時音頻;
30、采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列;
31、解析文本序列得到多個手語動作;
32、將多個手語動作合成為連續(xù)手語動畫,在網(wǎng)頁中展示手語動畫并播放實時音頻。
33、第四方面,本申請還提供了一種計算機可讀存儲介質(zhì),其上存儲有計算機程序,所述計算機程序被處理器執(zhí)行時實現(xiàn)以下步驟:
34、捕獲網(wǎng)頁上的實時音頻;
35、采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列;
36、解析文本序列得到多個手語動作;
37、將多個手語動作合成為連續(xù)手語動畫,在網(wǎng)頁中展示手語動畫并播放實時音頻。
38、第五方面,本申請還提供了一種計算機程序產(chǎn)品,包括計算機程序,該計算機程序被處理器執(zhí)行時實現(xiàn)以下步驟:
39、捕獲網(wǎng)頁上的實時音頻;
40、采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列;
41、解析文本序列得到多個手語動作;
42、將多個手語動作合成為連續(xù)手語動畫,在網(wǎng)頁中展示手語動畫并播放實時音頻。
43、上述音頻轉(zhuǎn)手語方法、裝置、計算機設備、計算機可讀存儲介質(zhì)和計算機程序產(chǎn)品,通過捕獲網(wǎng)頁上的實時音頻;采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列;解析文本序列得到多個手語動作;將多個手語動作合成為連續(xù)手語動畫,在網(wǎng)頁中展示手語動畫并播放實時音頻。上述方案,由于實時音頻的語音識別、文本序列解析、手語動畫的合成均在網(wǎng)頁所在的終端中進行,避免了在服務器中處理帶來的延時問題,有利于提升音頻轉(zhuǎn)換手語的實時性;同時,預先訓練的音頻識別模型為深度學習模型,引入深度學習模型進行語音識別,可顯著提高語音識別的效率,進一步提升了音頻轉(zhuǎn)換手語的實時性。
技術特征:
1.一種音頻轉(zhuǎn)手語方法,其特征在于,所述方法包括:
2.根據(jù)權利要求1所述的方法,其特征在于,所述采用預先訓練的音頻識別模型對所述實時音頻進行語音識別,得到所述實時音頻對應的文本序列,包括:
3.根據(jù)權利要求2所述的方法,其特征在于,所述采用預先訓練的音頻識別模型對預處理后的音頻進行語音識別,得到所述實時音頻對應的文本序列,包括:
4.根據(jù)權利要求1所述的方法,其特征在于,所述解析所述文本序列得到多個手語動作,包括:
5.根據(jù)權利要求4所述的方法,其特征在于,所述基于所述動作序列,確定多個手語動作,包括:
6.根據(jù)權利要求1所述的方法,其特征在于,所述方法還包括:
7.一種音頻轉(zhuǎn)手語裝置,其特征在于,所述裝置包括:
8.一種計算機設備,包括存儲器和處理器,所述存儲器存儲有計算機程序,其特征在于,所述處理器執(zhí)行所述計算機程序時實現(xiàn)權利要求1至6中任一項所述的方法的步驟。
9.一種計算機可讀存儲介質(zhì),其上存儲有計算機程序,其特征在于,所述計算機程序被處理器執(zhí)行時實現(xiàn)權利要求1至6中任一項所述的方法的步驟。
10.一種計算機程序產(chǎn)品,包括計算機程序,其特征在于,所述計算機程序被處理器執(zhí)行時實現(xiàn)權利要求1至6中任一項所述的方法的步驟。
技術總結
本申請涉及一種音頻轉(zhuǎn)手語方法、裝置、設備、可讀存儲介質(zhì)和程序產(chǎn)品。所述方法包括:捕獲網(wǎng)頁上的實時音頻;采用預先訓練的音頻識別模型對實時音頻進行語音識別,得到實時音頻對應的文本序列;解析文本序列得到多個手語動作;將多個手語動作合成為連續(xù)手語動畫,在網(wǎng)頁中展示手語動畫并播放實時音頻。采用本方法能夠提高音頻轉(zhuǎn)手語的實時性。
技術研發(fā)人員:江宜舟,楊超,王宇,陳敏
受保護的技術使用者:天翼云科技有限公司
技術研發(fā)日:
技術公布日:2025/3/20
- 還沒有人留言評論。精彩留言會獲得點贊!