一種美聲共鳴特征提取方法
本發明涉及一種美聲唱法識別方法,具體涉及一種美聲共鳴特征提取方法。
背景技術:
1、美聲唱法是一種區別于其他音樂流派的優美的共鳴唱法,演唱者在發聲時被要求盡可能結合頭腔共鳴、胸腔共鳴、口腔共鳴和鼻腔共鳴,做到上下共鳴的均衡,這些腔體的組合使美聲唱法圓潤飽滿,同時,也是美聲唱法區別于流行、民族等音樂流派的關鍵因素。
2、在美聲的發聲訓練中,初學者往往不能很好的運用各個共鳴腔,導致發聲錯誤。在沒有老師的指導下,學生很難通過自己的歌唱準確判斷出發聲錯誤,也不能及時調整錯誤的共鳴位置,而且目前還沒有可以判斷共鳴腔錯誤的聲樂教學系統。
3、所以,研究美聲中的共鳴腔運用不僅可以提高聲樂訓練效率,而且對推動歌唱訓練與信號處理技術的交叉發展具有重要意義。
技術實現思路
1、本發明的目的在于提供一種美聲共鳴特征提取方法,該方法通過對比標準與非標準美聲女高音發聲信號,提取梅爾頻率倒譜系數,有效的區分科學發聲與錯誤發聲,對美聲發聲訓練起到輔助教學作用。
2、本發明的目的是通過以下技術方案實現的:
3、一種美聲共鳴特征提取方法,該方法包括以下步驟:
4、步驟1:對某美聲初學者和教師進行高音信號采集,對采集到的聲音信號進行端點切割,去除聲音樣本中的噪聲段與靜音段,得到無干擾的美聲信號。
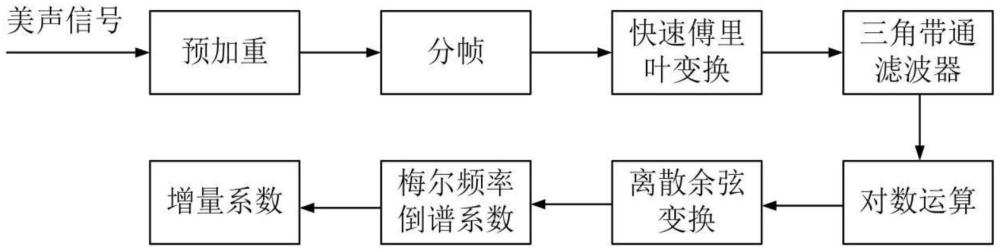
5、步驟2:通過離散傅里葉變換將時域信號轉換到頻域中并保留幅度譜,使用mel濾波器將線性頻率轉換為非線性分布的mel頻率,應用離散余弦變換(dct)計算每個濾波器組輸出的對數能量。
6、步驟3:將提取到的梅爾頻率倒譜系數特征參數使用relieff算法進行降維
7、步驟4:在支持向量機中選用交叉驗證法和測試集劃分法,對數據進行分類。
8、所述步驟2中,進一步包括:
9、2.1離散傅里葉變換:
10、
11、其中n為快速傅里葉變換的點數,s(n)為分幀后的信號,得到的p(n)為信號能量譜。
12、2.2語音信號在經過快速傅里葉變換后,將會得到一個由復數矩陣組成的能量譜,對上述能量譜采用取平方的方式保留幅度譜,計算幅度譜:
13、p(n)=p2(n)
14、2.3計算mel濾波,mel濾波器由m個三角形帶通濾波器組成,中心頻率為fm,m=1,2,...,m通常m取值為22-26,這組濾波器可以將線性頻率轉換為非線性分布的mel頻率。三角濾波器的頻率響應定義為:
15、
16、計算每個濾波器組輸出的對數能量:
17、
18、2.4得到的能量em進行離散余弦變換,便得到mfcc的特征參數:
19、
20、所述步驟3中,進一步包括:
21、首先將所有因子的預測權重w設為0,接下來,算法通過迭代在樣本集中隨機抽取一個樣本r,再從與r同一類的樣本中找出r的k個鄰近樣本集合,設為h;從與r不同類的樣本中找出k個鄰近樣本集合,根據其所屬類c的不同定義為m(c),更新每個特征的權重值:
22、
23、
24、其中,diff(a,r1,r2)表示為樣本r1與r2在特征a上的差值,mj(c)表示為與r不同類樣本中第j個最鄰近樣本,m為迭代次數。
25、特征a分為兩種情況,若特征a為離散型,則:
26、
27、若特征a為連續型,則:
28、
29、其中max(fj)和min(fj)分別代表了特征a的最大值和最小值。
30、對以上更新權重值的過程迭代m次,求得n個特征的權重w={w1,w2,...,wn},根據權重大小對特征進行從大到小的排列,便得到了特征對樣本分類能力由強至弱的排序。
31、所述步驟4中,進一步包括:使用支持向量機對數據進行分類,本研究采用交叉驗證的方法,將數據樣本中的80%作為訓練集,剩余的20%作為測試集,經過5折重復交叉驗證,得到全部測試樣本的識別率和平均值。
32、本發明的有益效果是:
33、本發明通過對比標準與非標準美聲女高音發聲信號并提取梅爾頻率倒譜系數,能夠清晰地分辨出科學發聲與錯誤發聲情況。這使得教師在美聲發聲訓練教學過程中,可以依據準確的判斷結果,有針對性地對學生進行指導,糾正錯誤發聲習慣,幫助學生更快、更有效地提升發聲水平,讓教學更具科學性和精準性。
技術特征:
1.一種美聲共鳴特征提取方法,其特征在于,所述方法包括以下步驟:
2.根據權利要求1所述的一種美聲共鳴特征提取方法,其特征在于,所述步驟2中對能量譜取平方保留幅度譜的操作,突出信號在頻域的幅度信息,計算每個濾波器組輸出的對數能量,得到的對數能量作為一種有效的特征表示,反映出不同頻段內信號能量的分布情況,捕捉到頻率特征。
3.根據權利要求1所述的一種美聲共鳴特征提取方法,其特征在于,所述步驟2的實現過程為:
4.根據權利要求1所述的一種美聲共鳴特征提取方法,其特征在于,所述步驟3中使用relieff算法作為特征選擇算法,通過對特征參數的權重進行計算,在高維特征樣本中選取權重大的特征,移除權重小的特征,從而降低特征維度;其過程包括:
5.根據權利要求1所述的一種美聲共鳴特征提取方法,其特征在于,所述步驟4中支持向量機對數據進行分類,采用交叉驗證的方法,將數據樣本中的80%作為訓練集,剩余的20%作為測試集,經過5折重復交叉驗證,得到全部測試樣本的識別率和平均值。
技術總結
本發明一種美聲共鳴特征提取方法,涉及一種美聲唱法識別方法,該方法首先分別采集標準與非標準美聲高音發聲樣本,并對聲音信號預加重、分幀和加窗;其次,通過離散傅里葉變換將時域信號轉換到頻域中并保留幅度譜,使用若干個由三角形帶通濾波器組成Mel濾波器,將線性頻率轉換為非線性分布的Mel頻率,計算每個濾波器組輸出的對數能量,對得到梅爾頻率倒譜系數使用ReliefF算法進行降維;然后,使用支持向量機進行特征分類。本發明通過對比美聲教師與美聲初學者的發聲信號,有效的區分科學發聲與錯誤發聲,提高系統的識別性能,對美聲發聲訓練起到輔助教學作用。
技術研發人員:張凱,初琦,李冰,高淑芝
受保護的技術使用者:沈陽化工大學
技術研發日:
技術公布日:2025/4/28
- 還沒有人留言評論。精彩留言會獲得點贊!