監測風電機組狀態的方法及系統與流程
本發明屬于風力發電
技術領域:
,尤其涉及一種監測風電機組狀態的方法及系統。
背景技術:
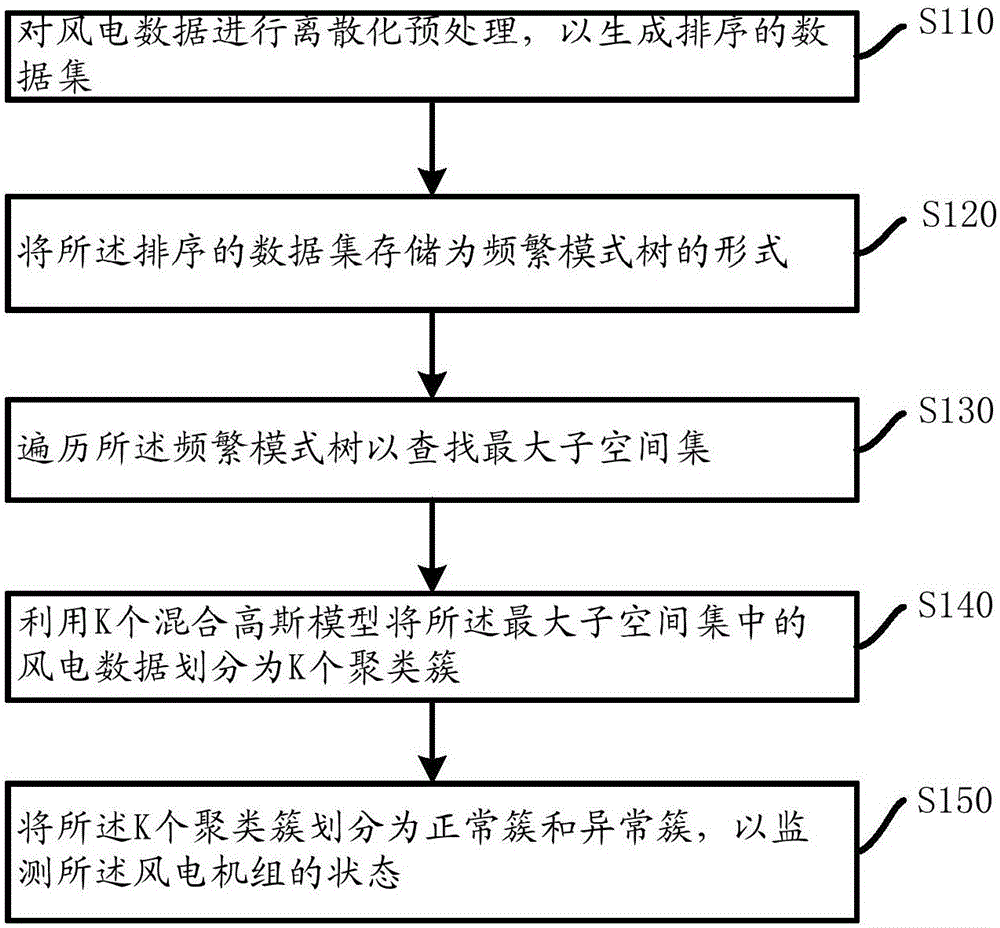
:風能作為一種清潔的可再生能源,不僅有利于改善環境污染問題而且可以有效的調節能源結構,受到世界各國越來越多的重視,風力發電是目前電力領域發展最快的發電方式之一。監測風電機組(風機)的狀態有利于用戶及時了解風機的運行,從而根據其狀態進行控制。例如,當風機處于異常狀態時,可以控制風電機組的最大出風力,從而提高風電機組的效率,節約成本。然而,在現有技術中,風機異常狀態的監測以識別處偏離正常功率曲線范圍的數據為目標,將該部分數據定義為異常點,并監測正常數據和異常數據的整體數據分布以評估風機的異常狀態。這種方法具有片面性和不準確性,這主要體現在以下方面:其一,這種方法主要以分析功率-風速二維屬性的數據分布形式,沒有充分考慮其他屬性與異常數據的關聯性,例如,強風、雨雪等氣候因素以及風機自身的偏航系統和變漿系統等,而這些因素導致實際輸出功率和預期的輸出功率之間存在偏差,使正常數據范圍內分布著雜亂的異常點。因此,導致異常狀態識別率低,尤其對于大量的風電數據,由于其它屬性所決定的異常點變多,更進一步降低異常狀態的識別率;其二,對于風電數據中的異常數據挖掘,在現有技術中,通常采用APRIORI自連接方式尋找最大子空間,在每個子空間中遍歷連通的密集網格單元作為聚類簇,這種方式需要多次訪問風電數據庫,并且時間復雜度較高,此外,現有技術中采用的例如K-Means等聚類方法,聚類結果精度不高,尤其是在數據屬性不斷增加時,在多維空間下數據分布稀疏,無法有效的進行多維聚類,因此,不能識別某些特定的數據分布狀態。因此,需要對現有技術進行改進,以解決上述至少一個問題。技術實現要素:本發明的目的是解決上述現有技術中的缺陷,提供一種的新的監測風電機組狀態的方法。根據本發明的一個方面,提供了一種監測風電機組狀態的方法,該方法包括:步驟1:對風電數據進行離散化預處理,以生成排序的數據集,所述排序的數據集包括根據所述風電數據的屬性劃分的多個區間;步驟2:將所述排序的數據集存儲為頻繁模式樹的形式;步驟3:遍歷所述頻繁模式樹以查找最大子空間集;步驟4:利用多維聚類方法將所述最大子空間集中的風電數據劃分為多個聚類簇;以及步驟5:將所述多個聚類簇劃分為正常簇和異常簇,以監測所述風電機組的狀態。優選地,其中,所述風電數據的屬性包括風電機組的功率、風速、環境溫度、葉片對風的角度、齒箱溫度中的一種或多種。優選地,步驟1包括:將所述風電數據劃分為多個不相交的區間并計算每個區間的頻繁度;選擇高于頻繁度閾值的區間;以及計算所選擇的區間的頻繁度并按照頻繁度從高到低的順序排序,以形成排序的數據集。優選地,在步驟3中,采用從左至右,從下向上的順序來遍歷所述頻繁模式樹。優選地,在步驟4中,對于所述最大子空間集中的每個子空間執行以下步驟:定義K個混合高斯模型;對于所述每個子空間中的風電數據計算由K個高斯模型產生的概率;基于計算的概率將所述每個子空間中的風電數據劃分到K個聚類簇中。優選地,基于所述風電數據的屬性的數量和/或所述每個子空間中風電數據的數量調整K的取值。優選地,步驟5還包括將所述正常簇和異常簇分別相加來去除冗余數據。根據本發明的第二方面,提供了一種監測風電機組狀態的系統。該系統包括:用于對風電數據進行離散化預處理,以生成排序的數據集的單元,所述排序的數據集包括根據所述風電數據的屬性劃分的多個區間;用于將所述排序的數據集存儲為頻繁模式樹的形式的單元;用于遍歷所述頻繁模式樹以查找最大子空間集的單元;用于利用多維聚類方法將所述最大子空間集中的風電數據劃分為多個聚類簇的單元;以及用于將所述多個聚類簇劃分為正常簇和異常簇,以監測所述風電機組的狀態的單元。優選地,所述風電數據的屬性包括風電機組的功率、風速、環境溫度、葉片對風的角度、齒箱溫度中的一種或多種。優選地,基于所述風電數據的屬性的數量和/或所述每個子空間中風電數據的數量調整聚類簇的數量。與現有技術相比,本發明的優點在于:可以針對多維屬性的風電數據進行聚類,從而提高了風電機組狀態監測的有效性;通過多維聚類方法對風電數據進行多維聚類,能夠有效的挖掘風電數據的特征,進一步提高了風電機組狀態監測的準確率;利用頻繁模式樹的存儲結構有利于向處理大數據擴展。附圖說明以下參照附圖對本發明實施例作進一步說明,其中:圖1示出了根據本發明一個實施例的監測風機狀態的方法的流程圖。圖2示出了根據本發明一個實施例的對風電數據預處理之后的示意圖。圖3示出了根據本發明一個實施例的采用FP-tree存儲風電數據的示意圖。圖4(a)至圖4(c)示出了根據本發明一個實施例的遍歷FP-tree的過程示意圖。具體實施方式為了對本發明的技術特征、目的和效果有更加清楚的理解,現參照附圖對本發明提出的監測風電機組狀態的方法進一步詳細說明圖1示出了根據本發明一個實施例的監測風機狀態的方法的流程圖。1)步驟S110,對風電數據進行離散化預處理,以生成排序的數據集,所述排序的數據集包括根據所述風電數據的屬性劃分的多個區間。在一個實施例中,離散化預處理可以包括將風電數據劃分為多個不相交的區間并計算每個區間的頻繁度;選擇高于頻繁度閾值的區間;以及計算所選擇的區間的頻繁度并按照頻繁度從高到低的順序排序,以形成排序的數據集。下面以數據采集與監視控制系統(SCADA,SupervisoryControlAndDataAcquisition)采集的風電數據為例介紹預處理的過程。該SCADA數據中包含不同采集時刻下風機的功率、風速、環境溫度等多個屬性。步驟1a):將采集的風電數據的每一維屬性下的值域劃分為范圍相等的多個區間,對于同一屬性下的不同區間以當前屬性名標識,并且不同區間以數字標序。通過這種方式可以將整個風電數據集劃分為多個不相交的區間,將落在同一區間的數據點以該區間標識表示。具體而言,以風速屬性對應的數據集U={x1,x2,.....xi}為例,首先,將值域范圍(例如,風速的值域范圍可以是0-16米/秒)劃分為ε個間隔{wind1,wind2,......windε},如果x1在wind1對應的值域范圍內,則將x1標記為wind1,并將落在wind1區間的數據都記為wind1。類似地,可以根據屬性離散化整個風電數據集。圖2列出了通過上述方法將風電數據集離散之后的示意圖。如圖2所示,風電數據中每個屬性對應的值域范圍均被離散為ε個區間,在圖2中,示出了的屬性包括風速(wind)、風機的功率(power)、葉片對風的角度(angle)。在另外一個示例中,風電數據的屬性可以包括但不限于風機的功率、風速、環境溫度、葉片對風的角度、齒箱溫度等中的一種或多種。步驟1b):可以根據頻繁度閾值將風電數據劃分為高頻繁度區間與低頻繁度區間,對高頻繁度區間中的數據進行存儲。在本文中頻繁度(frequencydegree)定義為離散后的數據占所有離散數據的百分比。其中,number(I)表示被計算頻繁度的離散數據在整個數據集中的數目;number(D)表示整個數據集離散數據數目;frequencydegree(I)為所計算的離散數據在整個離散數據集中所占百分比。例如,如果劃分區間后的數據集為{wind1;wind2;wind3},wind1=[x2],wind2=[x3,x4,x5,x5],wind3=[x7,x8,x9,x9,x9],因此,整個數據集的離散數據的數目number(D)是10,則有:x5的頻繁度為2/10;x2、x3、x4、x7、x8的頻繁度均是1/10;x9的頻繁度是3/10。當然也可以采用百分比來表示頻繁度。然后,計算離散后每個區間的頻繁度。例如,wind1區間包括一個數據,其區間的頻繁度是1/10,wind2區間包含4個數據,其區間頻繁度是4/10,類似地wind3的區間頻繁度為5/10。基于與區間的頻繁度閾值的比較將區間劃分為高頻繁度區間與低頻繁度區間。例如,如果區間的頻繁度閾值設置為20%,則wind1歸屬于低頻繁度區間,wind2、wind3歸屬于高頻繁度區間。然后,刪除低頻繁度單元,并且去掉高頻繁度區間的數字標識。對其它屬性的風電數據進行類似處理。之后,計算每個屬性下各頻繁區間中的數據與所有高頻繁區間的比值。例如,刪除低頻繁度區間之后,wind2區間的頻繁度是4/9,wind3區間的頻繁度是5/9。在上述過程中,頻繁度閾值可以是用戶給定的閾值,閾值的范圍可以根據所處理數據的數量或數據的分布狀態而選取不同的值。例如,閾值范圍為0%至40%。通過選擇適當的閾值,可以去除對統計結果意義不大的數據,從而減小數據存儲和統計的計算量。類似地,可以對包含多維屬性的風電數據進行同樣的離散化過程,并將處理后的數據集以每行為一條數據,其中,不同的行的表示在不同時刻的風電數據。將每條數據以區間頻繁度從高到低排序。如下表1所示。表1預處理后的數據示例FrequentitemsFrequentitems(F)1wind1power3gl5ang3windglpowerang2wind1temper2gear4ang3windtempergearang3power2ang3temper3powerangtemper4power2ang3temper3powerangtemper其中,wind表示風速;power表示風電機組的功率;temper表示環境溫度;ang表示葉片對風的角度;gear表示齒箱溫度;gl表示葉片的角度。在表1中,左部分的頻繁項(frequencyitems)為刪除低頻繁度區間的數據集;右半部分(F)為去掉區間標識后并根據頻繁度由高到低排序的數據集。上述以SCADA數據為例介紹了風電數據的離散化的過程,本領域的技術人員應當理解,上述過程同樣適應于通過其他方式獲得的風電數據。并且對區間的具體劃分方式以及頻繁度的衡量標準也不限于上述的過程,其變化或變型也在本發明的范圍內,例如,將區間劃分為取值范圍不相等的區間。2)步驟S120,將排序的數據集存儲為頻繁模式樹的形式。頻繁模式樹(簡稱FP-Tree)使用緊縮的數據結構來存儲查找頻繁項所需要的全部信息,例如可以包括頻繁項的名稱并可以計算其頻繁度。FP-tree的存儲結構所占用的內存空間與樹的深度和寬度成比例,樹的深度是單個數據記錄所含項目數量的最大值,樹的寬度是平均每層所含項目的數量,由于在風電數據處理中,存在大量的共享頻繁項,所以樹的大小通常比原數據庫要小很多,此外,采用FP-tree的存儲結構尋找最大子空間時,只需訪問一次數據庫,因此,其相對于諸如APRIORI傳統的尋找子空間的方式有較大的優勢。圖3示出了將表1的風電數據的頻繁區間存儲為FP-tree的形式。它由一個根節點root和包含表1中各頻繁區間的子樹構成,圖3中樹的最左側分支對應表1中的右半部分的第一行,樹的最右側分支對應表1中右半部分的第三行和第四行,樹的中間分支對應表1中右半部分的第二行。FP-tree及其存儲的具體過程屬于現有技術,在此不再贅述。3)步驟S130,遍歷所述頻繁模式樹以查找最大子空間集。此步驟通過遍歷樹來識別包含簇的子空間集,或稱最大子空間集,其中識別出的每個子空間包括符合約束條件的多維屬性的風電數據區間。在一個實施例中,可以采用從左至右,從下向上的順序來遍歷頻繁模式樹。下面結合圖4(a)至圖4(c)的三個示例來說明遍歷的具體過程和原則,為便于說明遍歷的原則和過程,用葉子節點(leaf)和父節點(ancestor)來表示FP-tree結構中的節點,而沒有列出節點中存儲的頻繁項名稱。而為了清楚起見,在圖4(a)至圖4(c)標注了各個節點中存儲的項的頻繁度與閾值u的比較,例如,圖4(a)中僅有中間分支的葉子節點的頻繁度小于閾值u,其他的項均大于閾值u。第一步:遍歷FP-Tree樹最左端葉子節點,根據公式(1)計算當前節點的頻繁度。例如,計算當前節點頻繁度占所有節點頻繁度的百分比。如果大于用戶設定閾值u,則將該葉子節點作為初始節點,向上遍歷父節點直至root,將同一樹干上節點對應的屬性作為最大子空間,如果頻繁度小于閾值u,則訪問下一個葉子節點,以此類推訪問所有葉子節點。第二步:將上述頻繁度小于閾值u的葉子節點刪除,并將其父節點作為新的葉子節點,按照第一步的遍歷過程尋找子空間。第三步:識別子空間主要在于尋找初始節點,初始節點不能是遍歷過的節點,同時不能是離根節點最近的節點,否則,需刪除此次遍歷過程。第四步:遞歸執行該過程,直至尋找到所有子空間為了進一步理解上述遍歷規則,繼續參照圖4(a)至圖4(c)進行說明。在圖4(a)中,第一個和第三個葉子節點頻繁度均大于用戶設定頻繁度閾值u,則以此兩個葉子節點為初始節點向上遍歷至根節點;而在圖4(b)中,第二個葉子節點頻繁度小于閾值u,則刪除該葉子節點,將其父節點作為新的葉子節點;在圖4(c)中,第二個葉子節點頻繁度小于閾值u,則將其父節點作為新的葉子節點,然而,該父節點是遍歷過的節點,那么刪除此次遍歷,第三個葉子節點頻繁度同樣小于閾值u,則將其父節點作為新的葉子節點,因為父節點是離根節點最近的節點,那么刪除此次遍歷。根據上述遍歷FP-Tree過程可以求出所有符合約束條件(即大于閾值u)的子空間,或稱最大子空間。圖4(a)至圖4(c)中以相對粗線標識的路徑分別示出了三種示例下最終確定的最大子空間。頻繁度閾值u可以控制遍歷FP-tree所輸出的子空間的數量。例如,較大的頻繁度閾值u將會輸出較少的子空間,相反,較小的頻繁度閾值會輸出較多的子空間。通過FP-tree進行存儲和查詢子空間的方式可以節省存儲空間并減少對風電數據集進行掃描的次數。此外,通過設置適當的閾值u可以控制輸出的子空間的數量,從而在保證在異常數據點挖掘結果正確的情況下,盡量減小數據處理的負擔。4)步驟S140,利用K個混合高斯模型將所述最大子空間集中的風電數據劃分為K個聚類簇。在此步驟中,將S130中輸出的最大子空間集與風電數據集作為求子空間聚類簇的輸入。所謂聚類就是按照一定的標準將數據子空間進行區分和分類的過程。通過數學方法處理將數據進行分割,使每個數據類(聚類簇)內部之間的相關性比其他對象之間的相關性高,各個聚類簇之間的相異性較高。在此實施例中,采用混合高斯模型來進行聚類。例如,定義多個混合高斯模型,對每個最大子空間進行高斯聚類以識別每個最大子空間的聚類簇。所謂混合高斯模型就是指對樣本數據的概率密度分布進行估計,而估計的模型是幾個高斯模型加權和。每個高斯模型就代表了一個類。將樣本中的數據分別在多個高斯模型上投影,就會分別得到在各個類上的概率。然后,將概率的大小作為聚類的依據。這種基于概率模型的聚類方法可以較好的適用于挖掘潛在的簇,通過增加高斯模型的個數,可以逼近任何數據的概率分布。具體而言,定義K個混合高斯模型,公式如下:其中,K為高斯模型的數量,πk為選擇權重,μk為方差,∑k為均值。求和式的各項結果分別代表樣本x屬于各個類的概率。將上一步求得的最大子空間集合定義為U={U1,U2,U3,...Un},其中n為子空間的數量;每一個子空間定義為Ui={A1,A2,A3,...Am},i∈[1,n],m為每個子空間的屬性個數。將子空間集合和風電數據集依次輸入混合高斯模型,在每個子空間下將數據集劃分為K個簇。首先,初始化各個高斯模型的初始參數,其次,計算每個高斯模型的權值,迭代該兩個步驟直至收斂。具體參見下文。對于子空間集合U={U1,U2,U3,...Un}迭代執行以下步驟:step1:對于子空間Ui={A1,A2,A3,...Am},i∈[1,n],其中的第j條數據xi,由第K個高斯模型產生的概率為:數據點xi被劃分到產生它概率大的模型中,且將其他數據點依次劃分到K個模型中,即:劃分到K個簇中。step2:根據上一步計算結果,重新計算每一個高斯模型的參數,公式如下:πk=Nk/N(7)step3:直至高斯模型參數收斂,則停止迭代。由于在不同的子空間下數據分布不同,組成子空間屬性較多時,數據會分布稀疏;屬性較少時數據分布相對緊密。通過設置適當的K值可以控制每個子空間下聚類簇的數量,即可以控制不同類型的數據分布情況下,將每個子空間劃分為緊密/稀疏度合適的聚類簇。通過step1-至step3將輸出每一個子空間的聚類簇,作為下一步步驟S150中進行簇劃分和簇合并的輸入。5)步驟S150中,將所述K個聚類簇劃分為正常簇和異常簇,以監測所述風電機組的狀態。例如,設置概率閾值參數Eq將每個子空間下的聚類簇劃分為大的密集簇和小的稀疏簇。例如,可以初步將大的密集的簇定義為正常的簇,小的稀疏的簇和不屬于任何簇的數據定義為異常的簇。在一個實施例中,還可以將所有子空間的正常簇和異常簇分別相加以去除冗余數據,實現簇合并。在正常簇與異常簇中仍然存在冗余數據的情況下,還可以再次利用高斯模型將冗余數據進行分類。通過這種方式,可以進一步提高異常數據的識別率。如果設置了較大的K值,也就是在每個子空間下有較多的聚類簇,這時通過設置較小的參數Eq,可以減少正常數據被誤識別為異常數據的可能性。雖然這會導致每個子空間下只能識別一部分異常數據,但通過多個子空間異常識別情況的疊加,就可以良好的監測風電機組異常運行狀態。綜上所述,采用混合高斯模型進行聚類的方法,可以通過增加高斯模型的數量來逼近任何的概率分布,可以通過設置適當的概率閾值來控制每個子空間下聚類簇的數量,從而減少正常數據被識別為異常數據的可能性,以便更好的監測風電機組的異常狀態。與根據本發明的監測風電機組狀態的方法向對應,本發明還提供一種監測風電機組狀態的系統。該系統包括:用于對風電數據進行離散化預處理,以生成排序的數據集的單元,所述排序的數據集包括根據所述風電數據的屬性劃分的多個區間;用于將所述排序的數據集存儲為頻繁模式樹的形式的單元;用于遍歷所述頻繁模式樹以查找最大子空間集的單元;用于利用多維聚類方法將所述子空間集中的風電數據劃分為多個聚類簇的單元;以及用于將所述多個聚類簇劃分為正常簇和異常簇,以監測所述風電機組的狀態的單元。在一個實施例中,所述風電數據的屬性包括風電機組的功率、風速、環境溫度、葉片對風的角度、齒箱溫度中的一種或多種。在一個實施例中,基于所述風電數據的屬性的數量和/或所述每個子空間中風電數據的數量調整聚類簇的數量。本領域技術人員應當明白,可以通過各種方式來實現上述單元。例如,可以通過指令配置處理器來實現。例如,可以將指令存儲在ROM中,并且當啟動設備時,將指令從ROM讀取到可編程器件中來實現上述模塊。例如,可以將上述模塊固化到專用器件(例如ASIC)中。可以將上述模塊分成相互獨立的單元,或者可以將它們合并在一起實現。上述單元可以通過上述各種實現方式中的一種來實現,或者可以通過上述各種實現方式中的兩種或更多種方式的組合來實現。以上已經描述了本發明的各實施例,上述說明是示例性的,并非窮盡性的,并且也不限于所披露的各實施例。在不偏離所說明的各實施例的范圍和精神的情況下,對于本
技術領域:
的普通技術人員來說許多修改和變更都是顯而易見的。本文中所用術語的選擇,旨在最好地解釋各實施例的原理、實際應用或對市場中的技術改進,或者使本
技術領域:
的其它普通技術人員能理解本文披露的各實施例。本發明的范圍由所附權利要求來限定。當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1