核心詞識(shí)別方法及裝置與流程
【技術(shù)領(lǐng)域】
本申請(qǐng)涉及互聯(lián)網(wǎng)技術(shù)領(lǐng)域,尤其涉及一種核心詞識(shí)別方法及裝置。
背景技術(shù):
在互聯(lián)網(wǎng)搜索領(lǐng)域中,用戶輸入搜索詞(query),搜索引擎根據(jù)用戶輸入的搜索詞進(jìn)行搜索并向用戶返回搜索結(jié)果。在搜索過程中,搜索引擎一般采用核心詞匹配原理進(jìn)行搜索,即識(shí)別查詢?cè)~中的核心詞,以及待搜索內(nèi)容(例如文檔或產(chǎn)品標(biāo)題)中的核心詞,然后計(jì)算核心詞之間的相關(guān)性作為查詢?cè)~與待搜索內(nèi)容之間的相關(guān)性,根據(jù)查詢?cè)~與待搜索內(nèi)容之間的相關(guān)性返回搜索結(jié)果。
在現(xiàn)有技術(shù)中,最常用的核心詞識(shí)別方法主要包括以下步驟:以單詞(word)為粒度,對(duì)每個(gè)單詞進(jìn)行詞性標(biāo)注;利用線下預(yù)先生成的核心詞詞性標(biāo)注規(guī)則來匹配查詢?cè)~中的核心詞;統(tǒng)計(jì)核心詞的詞頻等特征,并利用機(jī)器學(xué)習(xí)模型(例如svm模型)對(duì)核心詞進(jìn)行優(yōu)化。
在上述核心詞識(shí)別方法中,詞性標(biāo)注規(guī)則是基于正常語言模型順序設(shè)置的(例如,正常產(chǎn)品的標(biāo)題都是“形容詞1+形容詞2+形容詞3…+產(chǎn)品名稱”),但是目前好多文檔或產(chǎn)品的標(biāo)題并不是按正常語言模型順序,例如“l(fā)unchboxplastic”,就是把產(chǎn)品名稱(lunchbox)放在前面,而修飾短語(plastic)放在后面,按照現(xiàn)有詞性標(biāo)注規(guī)則,上述plastic會(huì)被識(shí)別為名詞,并最終被識(shí)別為核心詞,實(shí)際上這是錯(cuò)誤的,導(dǎo)致核心詞識(shí)別不夠精準(zhǔn)。
技術(shù)實(shí)現(xiàn)要素:
本申請(qǐng)的多個(gè)方面提供一種核心詞識(shí)別方法及裝置,用以提高核心詞識(shí) 別的精準(zhǔn)度。
本申請(qǐng)的一方面,提供一種核心詞識(shí)別方法,包括:
對(duì)待處理文本進(jìn)行分詞處理,以獲得所述待處理文本包含的分詞片段;
查詢預(yù)先建立的分詞修飾詞典,以確定所述待處理文本包含的分詞片段之間的修飾關(guān)系;
根據(jù)所述待處理文本包含的分詞片段之間的修飾關(guān)系,確定所述待處理文本中的核心詞。
本申請(qǐng)的另一方面,提供一種核心詞識(shí)別裝置,包括:
分詞處理模塊,用于對(duì)待處理文本進(jìn)行分詞處理,以獲得所述待處理文本包含的分詞片段;
關(guān)系確定模塊,用于查詢預(yù)先建立的分詞修飾詞典,以確定所述待處理文本包含的分詞片段之間的修飾關(guān)系;
短語確定模塊,用于根據(jù)所述待處理文本包含的分詞片段之間的修飾關(guān)系,確定所述待處理文本中的核心詞。
在本申請(qǐng)中,對(duì)待處理文本進(jìn)行分詞處理,獲得待處理文本包含的分詞片段,之后,查詢預(yù)先建立的分詞修飾詞典,確定待處理文本包含的分詞片段之間的修飾關(guān)系,根據(jù)待處理文本包含的分詞片段之間的修飾關(guān)系,確定待處理文本中的核心詞。本申請(qǐng)基于分詞片段之間的修飾關(guān)系確定核心詞,由于分詞片段之間的修飾關(guān)系并不受文本中詞語之間先后順序的限定,所以能夠解決現(xiàn)有技術(shù)方案中詞性標(biāo)注規(guī)則對(duì)正常語言模型順序嚴(yán)重依賴的問題,有利于提高核心詞識(shí)別的精準(zhǔn)度。
【附圖說明】
為了更清楚地說明本申請(qǐng)實(shí)施例中的技術(shù)方案,下面將對(duì)實(shí)施例或現(xiàn)有技術(shù)描述中所需要使用的附圖作一簡(jiǎn)單地介紹,顯而易見地,下面描述中的附圖是本申請(qǐng)的一些實(shí)施例,對(duì)于本領(lǐng)域普通技術(shù)人員來講,在不付出創(chuàng)造 性勞動(dòng)的前提下,還可以根據(jù)這些附圖獲得其他的附圖。
圖1為本申請(qǐng)一實(shí)施例提供的核心詞識(shí)別方法的流程示意圖;
圖2為本申請(qǐng)另一實(shí)施例提供的建立分詞詞庫的方法的流程示意圖;
圖3為本申請(qǐng)又一實(shí)施例提供的建立的分詞修飾詞典的方法的流程示意圖;
圖4為本申請(qǐng)又一實(shí)施例提供的核心詞識(shí)別裝置的結(jié)構(gòu)示意圖;
圖5為本申請(qǐng)又一實(shí)施例提供的核心詞識(shí)別裝置的結(jié)構(gòu)示意圖。
【具體實(shí)施方式】
為使本申請(qǐng)實(shí)施例的目的、技術(shù)方案和優(yōu)點(diǎn)更加清楚,下面將結(jié)合本申請(qǐng)實(shí)施例中的附圖,對(duì)本申請(qǐng)實(shí)施例中的技術(shù)方案進(jìn)行清楚、完整地描述,顯然,所描述的實(shí)施例是本申請(qǐng)一部分實(shí)施例,而不是全部的實(shí)施例。基于本申請(qǐng)中的實(shí)施例,本領(lǐng)域普通技術(shù)人員在沒有做出創(chuàng)造性勞動(dòng)前提下所獲得的所有其他實(shí)施例,都屬于本申請(qǐng)保護(hù)的范圍。
在現(xiàn)有核心詞識(shí)別方法中,由于詞性標(biāo)注規(guī)則是基于正常語言模型順序設(shè)置的,但是目前好多文檔或產(chǎn)品的標(biāo)題并不是按正常語言模型順序,這導(dǎo)致現(xiàn)有核心詞識(shí)別方法識(shí)別出的核心詞有可能是錯(cuò)誤的,導(dǎo)致核心詞識(shí)別不夠精準(zhǔn)。
針對(duì)上述問題,本申請(qǐng)?zhí)峁┮环N核心詞識(shí)別方法,主要原理是:預(yù)先建立分詞修飾詞典,用于存儲(chǔ)分詞片段之間的修飾關(guān)系;在對(duì)待處理文本進(jìn)行核心詞識(shí)別時(shí),查詢分詞修飾詞典,確定待處理文本包含的分詞片段之間的修飾關(guān)系,基于待處理文本包含的分詞片段之間的修飾關(guān)系,確定待處理文本中的核心詞。由于分詞片段之間的修飾關(guān)系并不受文本中詞語之間先后順序的限定,所以能夠解決現(xiàn)有技術(shù)方案中詞性標(biāo)注規(guī)則對(duì)正常語言模型順序嚴(yán)重依賴的問題,有利于提高核心詞識(shí)別的精準(zhǔn)度。
下面將通過具體實(shí)施方式對(duì)本申請(qǐng)技術(shù)方案進(jìn)行詳細(xì)說明。
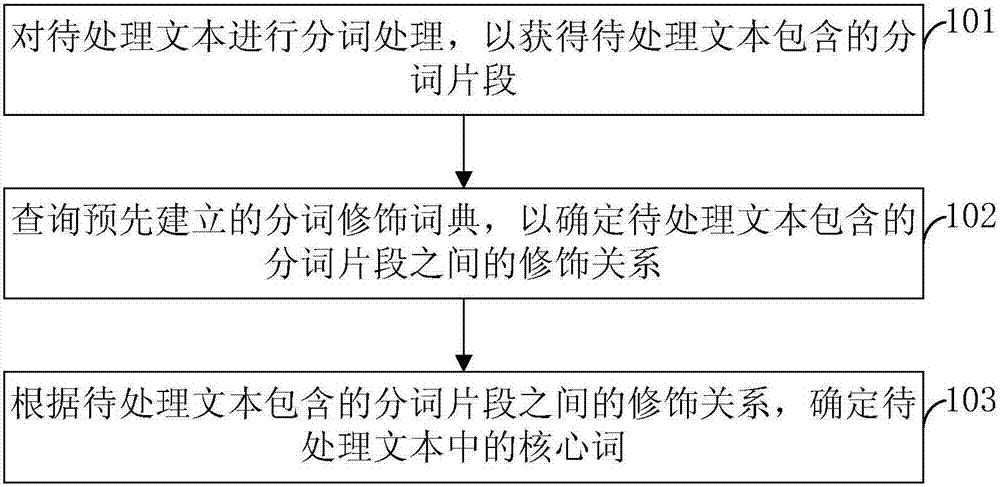
圖1為本申請(qǐng)一實(shí)施例提供的核心詞識(shí)別方法的流程示意圖。如圖1所示,該方法包括:
101、對(duì)待處理文本進(jìn)行分詞處理,以獲得待處理文本包含的分詞片段。
102、查詢預(yù)先建立的分詞修飾詞典,以確定待處理文本包含的分詞片段之間的修飾關(guān)系。
103、根據(jù)待處理文本包含的分詞片段之間的修飾關(guān)系,確定待處理文本中的核心詞。
本實(shí)施例提供一種核心詞識(shí)別方法,可由核心詞識(shí)別裝置來執(zhí)行,用以更加精準(zhǔn)地進(jìn)行核心詞識(shí)別。本實(shí)施例提供的核心詞識(shí)別方法可應(yīng)用于各種需要識(shí)別核心詞的場(chǎng)景中,例如互聯(lián)網(wǎng)搜索領(lǐng)域。
以互聯(lián)網(wǎng)搜索領(lǐng)域?yàn)槔诵脑~識(shí)別裝置可作為搜索引擎中的一個(gè)功能模塊實(shí)現(xiàn),或者,也可以獨(dú)立于搜索引擎但與搜索引擎相互通信,用以對(duì)用戶輸入的搜索詞或待搜索網(wǎng)絡(luò)對(duì)象的描述信息進(jìn)行核心詞識(shí)別。
具體的,核心詞識(shí)別裝置首先獲取需要進(jìn)行核心詞識(shí)別的文本,為便于描述,將需要進(jìn)行核心詞識(shí)別的文本稱為待處理文本。以互聯(lián)網(wǎng)搜索領(lǐng)域?yàn)槔幚砦谋究梢允怯脩糨斎氲乃阉髟~,或者是待搜索網(wǎng)絡(luò)對(duì)象的描述信息。以互聯(lián)網(wǎng)搜索領(lǐng)域中的電子商務(wù)場(chǎng)景為例,待搜索網(wǎng)絡(luò)對(duì)象一般為電商平臺(tái)提供的商品或服務(wù),而待搜索網(wǎng)絡(luò)對(duì)象的描述信息包括但不限于:商品或服務(wù)的標(biāo)題、關(guān)鍵詞、用戶評(píng)論、詳情信息等中的至少一個(gè)。
可選的,在獲得待處理文本之后,可以對(duì)待處理文本進(jìn)行預(yù)處理。所述預(yù)處理包括以下至少一種操作:大小寫統(tǒng)一;去掉亂碼;去掉特殊的標(biāo)點(diǎn)符號(hào);以及英文的去詞干等。其中,在對(duì)待處理文本進(jìn)行核心詞識(shí)別之前,對(duì)待處理文本進(jìn)行預(yù)處理,使得待識(shí)別文本比較規(guī)范,有利于提高后續(xù)識(shí)別核心詞的精準(zhǔn)度。
在獲得待處理文本后,核心詞識(shí)別裝置對(duì)待處理文本進(jìn)行分詞處理,以獲得待處理文本包含的分詞片段。
在本實(shí)施例中,核心詞識(shí)別裝置可以采用任何分詞處理方式對(duì)待處理文 本進(jìn)行分詞處理。在一種較為簡(jiǎn)單的實(shí)施方式中,核心詞識(shí)別裝置可以采用較為常見的以單詞(word)為粒度的分詞工具,對(duì)待處理文本進(jìn)行分詞處理,從而獲得單詞粒度的分詞片段。
在以單詞為粒度對(duì)待處理文本進(jìn)行分詞處理的基礎(chǔ)上,由于切分粒度較細(xì),核心詞識(shí)別裝置最終識(shí)別出的核心詞大多也是單詞,這有可能導(dǎo)致核心詞識(shí)別錯(cuò)誤,例如對(duì)于“bodykit”識(shí)別出的核心詞是“kit”,對(duì)于“dinnerset”識(shí)別出的核心詞是“set”,而實(shí)際上“bodykit”和“dinnerset”的語義表達(dá)更加準(zhǔn)確,所以作為核心詞更為合適。
基于上述考慮,在一優(yōu)選實(shí)施方式中,核心詞識(shí)別裝置以短語(phrase)為粒度,對(duì)待處理文本進(jìn)行分詞處理,以獲得待處理文本包含的分詞片段。在以短語為例的分詞處理中,所述分詞處理實(shí)際上是指短語切分,所述切分出的分詞片段實(shí)際上是分詞短語。例如,對(duì)于“bodykit”和“dinnerset”不會(huì)被切分為單詞,而是視為短語。具體的,核心詞識(shí)別裝置可以采用n-gram模型對(duì)待處理文本進(jìn)行短語切分,以獲得待處理文本包含的分詞短語。其中,n-gram模型中常用的有uni-gram,bi-gram或tri-gram。
另外,從具體處理過程來看,核心詞識(shí)別裝置可以根據(jù)預(yù)先建立的分詞詞庫,對(duì)待處理文本進(jìn)行分詞處理,以獲得待處理文本包含的分詞片段。具體的,核心詞識(shí)別裝置可以采用正向最大匹配規(guī)則或逆向最大匹配規(guī)則,查詢預(yù)先建立的分詞詞庫,以獲得待處理文本包含的分詞片段。
在繼續(xù)介紹本實(shí)施例提供的核心詞識(shí)別方法之前,先對(duì)預(yù)先建立分詞詞庫的過程進(jìn)行說明。
本實(shí)施例的分詞詞庫可以采用現(xiàn)有建立分詞詞庫的方法來建立,關(guān)于現(xiàn)有建立分詞詞庫的方法可參見現(xiàn)有技術(shù),本實(shí)施例對(duì)此不做詳述。
除了采用現(xiàn)有方法建立分詞詞庫之外,本實(shí)施例還提供一種建立分詞詞庫的方法,如圖2所示,該方法包括:
201、對(duì)日志語料庫中的用戶歷史點(diǎn)擊日志進(jìn)行分詞處理,以獲得候選分詞片段。
202、計(jì)算候選分詞片段的語義特征,語義特征用于表達(dá)候選分詞片段在語法語義上的獨(dú)立表達(dá)能力。
203、根據(jù)候選分詞片段的語義特征,確定候選分詞片段中具有獨(dú)立語義的分詞片段。
204、將具有獨(dú)立語義的分詞片段加入分詞詞庫。
例如,可以獲取一段時(shí)間范圍的用戶歷史點(diǎn)擊日志構(gòu)成日志語料庫。所述一段時(shí)間范圍可以是最近一個(gè)月內(nèi)、最近半年內(nèi)、或者指定三個(gè)月內(nèi)等。
在互聯(lián)網(wǎng)搜索領(lǐng)域中,一般會(huì)通過用戶點(diǎn)擊日志記錄用戶提交的搜索詞以及用戶點(diǎn)擊該搜索詞對(duì)應(yīng)的某個(gè)搜索結(jié)果而返回的文檔信息。其中,用戶歷史點(diǎn)擊日志中記錄有某個(gè)歷史時(shí)間段內(nèi)用戶提交的搜索詞與用戶點(diǎn)擊該搜索詞對(duì)應(yīng)的某個(gè)搜索結(jié)果而返回的文檔信息。
在建立分詞詞庫的過程中,首先對(duì)日志語料庫中的用戶歷史點(diǎn)擊日志進(jìn)行分詞處理,以獲得候選分詞片段。
在本實(shí)施例中,可以采用任何分詞處理方式對(duì)用戶歷史點(diǎn)擊日志進(jìn)行分詞處理。在一種較為簡(jiǎn)單的實(shí)施方式中,可以采用較為常見的以單詞(word)為粒度的分詞工具,對(duì)用戶歷史點(diǎn)擊日志進(jìn)行分詞處理,從而獲得單詞粒度的分詞片段。
其中,考慮到以單詞為粒度的分詞處理,其切分粒度較細(xì),分詞片段是單詞,其語義表達(dá)可能不夠準(zhǔn)確,所以在一優(yōu)選實(shí)施方式中,以短語(phrase)為粒度,對(duì)用戶歷史點(diǎn)擊日志進(jìn)行分詞處理,以獲得候選分詞片段。在以短語為例的分詞處理中,所述分詞處理實(shí)際上是指短語切分,所述切分出的分詞片段實(shí)際上是分詞短語。具體的,可以采用n-gram模型對(duì)用戶歷史點(diǎn)擊日志進(jìn)行短語切分,以獲得用戶歷史點(diǎn)擊日志包含的分詞短語。
在獲得候選分詞片段之后,計(jì)算候選分詞片段的語義特征,這里的語義特征主要用于表達(dá)候選分詞片段在語法語義上的獨(dú)立表達(dá)能力,而不是簡(jiǎn)單的詞頻等特征信息。
較為優(yōu)選的,上述能夠表達(dá)候選分詞片段在語法語義上的獨(dú)立表達(dá)能力 的語義特征包括但不限于以下至少一種:點(diǎn)間互信息(point-wisemutualinformation,pmi)特征、點(diǎn)間相對(duì)熵(pointkullback–leibler,pkl)特征以及表達(dá)質(zhì)量特征。則計(jì)算候選分詞片段的語義特征具體為:計(jì)算候選分詞片段的pmi特征、pkl特征以及表達(dá)質(zhì)量特征中的至少一種語義特征。
pmi特征:可以根據(jù)候選分詞片段在日志語料庫中的出現(xiàn)概率、左鄰分詞片段在日志語料庫中的出現(xiàn)概率以及右鄰分詞片段在日志語料庫中的出現(xiàn)概率,計(jì)算候選分詞片段的pmi特征。其中,pmi特征可以反映各個(gè)相鄰分詞片段之間的共現(xiàn)程度,即結(jié)合度。
具體的,可以根據(jù)公式(1),計(jì)算候選分詞片段的pmi特征。
在上述公式(1)中,f1表示候選分詞片段的pmi特征;v表示候選分詞片段;ul表示左鄰分詞片段;ur表示右鄰分詞片段;p(v)表示候選分詞片段在日志語料庫中的出現(xiàn)概率;p(ul)表示左鄰分詞片段在日志語料庫中的出現(xiàn)概率;p(ur)表示右鄰分詞片段在日志語料庫中的出現(xiàn)概率。
pkl特征:可以根據(jù)候選分詞片段在日志語料庫中的出現(xiàn)概率、左鄰分詞片段在日志語料庫中的出現(xiàn)概率以及右鄰分詞片段在日志語料庫中的出現(xiàn)概率,計(jì)算候選分詞片段的pkl特征。其中,pkl特征反映分詞片段作為一個(gè)具有獨(dú)立語義的分詞片段的完整性,即體現(xiàn)了是否需要結(jié)合一個(gè)分詞片段左右相鄰的分詞片段才能形成具有獨(dú)立語義的分詞片段。
具體的,可以根據(jù)公式(2),計(jì)算候選分詞片段的pkl特征。
上述公式(2)中,f2表示候選分詞片段的pkl特征,其它各參數(shù)的含義與公式(1)中相應(yīng)參數(shù)的含義相同,在此不再贅述。
上述左鄰分詞片段是指日志語料庫中位于候選分詞片段左側(cè)且與所述候選分詞片段相鄰的分詞片段,相應(yīng)的,右鄰分詞片段是指日志語料庫中位 于候選分詞片段右側(cè)且與所述候選分詞片段相鄰的分詞片段。
表達(dá)質(zhì)量特征:可以根據(jù)預(yù)先指定的質(zhì)量因素與質(zhì)量得分之間的對(duì)應(yīng)關(guān)系,計(jì)算候選分詞片段的表達(dá)質(zhì)量特征。
例如,這里綜合以下幾個(gè)方面的質(zhì)量因素:
是否是停用詞(stopword),例如是否是‘iam’等詞,如果候選分詞片段不是停用詞,對(duì)應(yīng)一質(zhì)量得分,例如5分,如果候選分詞片段是停用詞,則對(duì)應(yīng)另一質(zhì)量得分,例如-1分;
逆向文件頻率(inversedocumentfrequency,idf),不同idf值對(duì)應(yīng)不同的質(zhì)量得分,一般來說idf越大,對(duì)應(yīng)的質(zhì)量得分越小;
是否帶有特殊的標(biāo)點(diǎn)符號(hào),例如雙引號(hào),括號(hào)等,如果候選分詞片段不帶有特殊的標(biāo)點(diǎn)符號(hào),則對(duì)應(yīng)一質(zhì)量得分,例如3分,如果候選分詞片段帶有特殊的標(biāo)點(diǎn)符號(hào),則對(duì)應(yīng)另一質(zhì)量得分,例如-1分。
上述質(zhì)量得分的取值僅是一種示例性說明,并不限于上述取值,具體可根據(jù)應(yīng)用場(chǎng)景適應(yīng)性設(shè)置。
基于上述,可以將候選分詞片段與上述三個(gè)質(zhì)量因素進(jìn)行比較,并根據(jù)比較結(jié)果,將相應(yīng)質(zhì)量得分進(jìn)行相加,獲得候選分詞片段的最終質(zhì)量得分,以作為表達(dá)質(zhì)量特征。
基于上述候選分詞片段的語義特征,確定候選分詞片段中具有獨(dú)立語義的分詞片段。例如,可以利用機(jī)器學(xué)習(xí)模型,綜合判斷候選分詞片段成為一個(gè)具有獨(dú)立語義的分詞片段的概率,然后基于該概率最終確定候選分詞片段是否為具有獨(dú)立語義的分詞片段。
其中,機(jī)器學(xué)習(xí)模型的算法的原理可以表示為下述公式(3):
prop(m)=f(f1,...,fn)(3)
在上述公式(3)中,m表示候選分詞片段;prop(m)表示候選分詞片段m成為一個(gè)具有獨(dú)立語義的分詞片段的概率;f()表示機(jī)器學(xué)習(xí)模型使用的算法函數(shù);fi表示第i個(gè)語義特征,1≤i≤n,n為自然數(shù)。這里的算法函數(shù)f()可以 是隨機(jī)森林(randomforest,rf)算法或邏輯回歸(logisticregression,lr)算法。
在確定候選分詞片段中具有獨(dú)立語義的分詞片段之后,可以將具有獨(dú)立語義的分詞判斷加入分詞詞庫。
在本實(shí)施例提供的建立分詞詞庫的方法中,一方面以短語為粒度進(jìn)行分詞處理,將短語作為最小粒度,使得基于分詞詞庫識(shí)別出的核心詞屬于短語級(jí)別的,有利于提高識(shí)別核心詞的精準(zhǔn)度,另一方面基于pmi特征、pkl特征以及表達(dá)質(zhì)量特征等挖掘分詞詞庫,有利于提高識(shí)別出的具有獨(dú)立語義的分詞片段的精準(zhǔn)度。
返回參見圖1,在獲得待處理文本包含的分詞片段之后,核心詞識(shí)別裝置查詢預(yù)先建立的分詞修飾詞典,以確定待處理文本包含的分詞片段之間的修飾關(guān)系。
在介紹詳細(xì)如何查詢預(yù)先建立的分詞修飾詞典,以確定待處理文本包含的分詞片段之間的修飾關(guān)系之前,首先對(duì)預(yù)先建立分詞修飾詞典的過程進(jìn)行詳細(xì)說明。
如圖3所示,建立分詞修飾詞典的方法流程包括:
301、對(duì)日志語料庫中的每條用戶歷史點(diǎn)擊日志,從用戶歷史點(diǎn)擊日志中提取具有獨(dú)立語義的分詞片段形成分詞片段集合。
302、對(duì)每個(gè)分詞片段集合,確定該分詞片段集合中的核心分詞片段和修飾分詞片段,將該分詞片段集合中的核心分詞片段分別與該分詞片段集合中的修飾分詞片段進(jìn)行組合,以獲得該分詞片段集合包含的分詞片段對(duì),生成該分詞片段集合包含的分詞片段對(duì)對(duì)應(yīng)的修飾信息,修飾信息包括修飾關(guān)系指向信息和修飾程度得分中的至少一個(gè)。
303、對(duì)所有分詞片段集合包含的分詞片段對(duì)進(jìn)行合并處理,并將合并后的分詞片段對(duì)以及合并后的分詞片段對(duì)對(duì)應(yīng)的修飾信息加入分詞修飾詞典中。
例如,可以獲取一段時(shí)間范圍的用戶歷史點(diǎn)擊日志構(gòu)成日志語料庫。所 述一段時(shí)間范圍可以是最近一個(gè)月內(nèi)、最近半年內(nèi)、或者指定三個(gè)月內(nèi)等。
在互聯(lián)網(wǎng)搜索領(lǐng)域中,一般會(huì)通過用戶點(diǎn)擊日志記錄用戶提交的搜索詞以及用戶點(diǎn)擊該搜索詞對(duì)應(yīng)的搜索結(jié)果而返回的文檔信息。其中,用戶歷史點(diǎn)擊日志中是指記錄某個(gè)歷史時(shí)間段內(nèi)用戶提交的搜索詞與用戶點(diǎn)擊該搜索詞對(duì)應(yīng)的搜索結(jié)果而返回的文檔信息。
在建立分詞修飾詞典的過程中,首先對(duì)日志語料庫中的日志進(jìn)行整理,按照搜索詞與用戶點(diǎn)擊行為形成一條條的用戶歷史搜索日志,其中,用戶針對(duì)歷史搜索詞對(duì)應(yīng)的搜索結(jié)果的一次點(diǎn)擊,形成一條用戶歷史搜索日志。然后,對(duì)每條用戶歷史搜索日志,從該用戶歷史點(diǎn)擊日志中提取具有獨(dú)立語義的分詞片段形成分詞片段集合。
其中,上述從用戶歷史點(diǎn)擊日志中提取具有獨(dú)立語義的分詞片段形成分詞片段集合的過程類似建立分詞詞庫的過程。例如,對(duì)于每條用戶歷史點(diǎn)擊日志,可以對(duì)該用戶歷史點(diǎn)擊日志進(jìn)行分詞處理,以獲得候選分詞片段;計(jì)算候選分詞片段的語義特征,語義特征用于表達(dá)候選分詞片段在語法語義上的獨(dú)立表達(dá)能力;根據(jù)候選分詞片段的語義特征,確定候選分詞片段中具有獨(dú)立語義的分詞片段,將具有獨(dú)立語義的分詞片段加入分詞片段集合。
值得說明的是,關(guān)于上述形成分詞片段集合過程中各步驟的詳細(xì)描述,具體可參見建立分詞詞庫中的相應(yīng)步驟,在此不再贅述。
基于上述處理,可以獲得日志語料庫中各用戶歷史點(diǎn)擊日志對(duì)應(yīng)的分詞片段集合。對(duì)每個(gè)分詞片段集合,要建立該分詞片段集合中各分詞片段之間的修飾關(guān)系。具體的,對(duì)每個(gè)分詞片段集合,確定該分詞片段集合中的核心分詞片段和修飾分詞片段;然后,將該分詞片段集合中的核心分詞片段分別與該分詞片段集合中的修飾分詞片段進(jìn)行組合,以獲得該分詞片段集合包含的分詞片段對(duì),并生成該分詞片段集合包含的分詞片段對(duì)對(duì)應(yīng)的修飾信息。
可選的,可以采用現(xiàn)有基于詞性標(biāo)注的核心詞識(shí)別方法,識(shí)別出每個(gè)分詞片段集合中的核心分詞片段。值得說明的是,在初始階段,可以采用現(xiàn)有基于詞性標(biāo)注的核心詞識(shí)別方法,識(shí)別出每個(gè)分詞片段集合中的核心分詞片 段,但是隨著分詞修飾詞典的不斷豐富,可以采用本實(shí)施例提供的核心詞識(shí)別方法來識(shí)別出每個(gè)分詞片段集合中的核心分詞片段,從而形成循環(huán)迭代的處理邏輯。對(duì)于每個(gè)分詞片段集合,除了核心分詞片段之外的分詞片段稱為修飾分詞片段。例如,假設(shè)一分詞片段集合包括分詞片段a、b和c,若確定b為核心分詞片段,則a和c為修飾分詞片段。
可選的,對(duì)每個(gè)分詞片段集合中的每個(gè)分詞片段,判斷該分詞片段是否在該分詞片段集合對(duì)應(yīng)的用戶歷史點(diǎn)擊日志包含的搜索詞和用戶點(diǎn)擊的文檔中共現(xiàn),若該分詞片段在用戶歷史點(diǎn)擊日志包含的搜索詞和用戶點(diǎn)擊的文檔中共現(xiàn),則確定該分詞片段為核心分詞片段,若該分詞片段在用戶歷史點(diǎn)擊日志包含的搜索詞和用戶點(diǎn)擊的文檔中不共現(xiàn),則確定該分詞片段為修飾分詞片段。
對(duì)于每個(gè)分詞片段集合,在確定該分詞片段集合中的核心分詞片段和修飾分詞片段之后,將該分詞片段集合中的核心分詞片段分別與該分詞片段集合中的修飾分詞片段進(jìn)行組合,以獲得該分詞片段集合包含的分詞片段對(duì)。例如,假設(shè)一分詞片段集合包括分詞片段a、b和c,確定b為核心分詞片段,a和c為修飾分詞片段,則可以將a和b形成一個(gè)分詞片段對(duì),b和c形成一個(gè)分詞片段對(duì)。值得說明的是,這里的分詞片段對(duì)僅限定包含的分詞片段,并不限定分詞片段在用戶歷史點(diǎn)擊日志中出現(xiàn)位置的先后順序,也不限定分詞片段在分詞片段對(duì)中的先后順序。
在獲得分詞片段對(duì)之后,需要生成分詞片段對(duì)對(duì)應(yīng)的修飾信息,該修飾信息用于描述分詞片段對(duì),主要描述分詞片段對(duì)之間修飾關(guān)系的方向以及修飾程度等。以a和b形成的分詞片段對(duì)為例,可以表示為:a|b(+/-)修飾程度得分。其中,修飾程度得分用于表示a和b兩個(gè)分詞片段之間的修飾程度,修飾程度得分前面的+或-為修飾關(guān)系指向信息,用于指示a和b之間的修飾方向。如果是+,則表示b是核心分詞片段,a是修飾分詞片段,a修飾b,b被a修飾;如果是-,則表示a是核心分詞片段,b是修飾分詞片段,b修飾a,a被b修飾。
可選的,修飾程度得分可以用分詞片段對(duì)中兩個(gè)分詞片段之間的共現(xiàn)度來表示,或者也可以用兩個(gè)分詞片段的行為分?jǐn)?shù)的加權(quán)平均值來表示。其中,分詞片段的行為分?jǐn)?shù)可以是在用戶歷史點(diǎn)擊日志中針對(duì)該分詞片段產(chǎn)生的各行為權(quán)重與時(shí)間衰減函數(shù)乘積的累加,用戶針對(duì)該分詞片段產(chǎn)生的行為(簡(jiǎn)稱為用戶行為)主要包括點(diǎn)擊,收藏或下單等行為,其中不同用戶行為可以設(shè)置不同的權(quán)重。例如,分詞片段的行為分?jǐn)?shù)可以表示為下述公式(4):
在上述公式(4)中,actionscore表示分詞片段的行為分?jǐn)?shù),
在獲得每個(gè)分詞片段集合包含的分詞片段對(duì)及分詞片段對(duì)對(duì)應(yīng)的修飾信息之后,可以對(duì)所有分詞片段集合包含的分詞片段對(duì)進(jìn)行合并處理,然后將合并后的分詞片段對(duì)以及合并后的分詞片段對(duì)對(duì)應(yīng)的修飾信息加入分詞修飾詞典中。
可選的,若上述修飾信息包括修飾程度得分,則對(duì)所有分詞片段集合包含的分詞片段對(duì)進(jìn)行合并處理,具體包括:將所有分詞片段集合包含的分詞片段對(duì)中的相同分詞片段對(duì)的修飾程度得分進(jìn)行累加,以作為相同分詞片段對(duì)的修飾程度得分,并保留相同分詞片段對(duì)中的一個(gè)。
假設(shè),第一分詞片段集合包括分詞片段對(duì)a|b+2,b|c-13.1,第二分詞片段集合包括分詞片段對(duì)a|b+1.5,b|c-10,則合并后的分詞片段對(duì)為a|b+3.5,b|c-23.1。
可選的,在獲得分詞修飾詞典之后,可以對(duì)分詞修飾詞典中的各分詞片段進(jìn)行預(yù)處理,例如大小寫統(tǒng)一,去掉亂碼,去掉特殊的標(biāo)點(diǎn)符號(hào)以及英文的去詞干等,以提高分詞修飾詞典的質(zhì)量,為后續(xù)查詢分詞修飾詞典打下基礎(chǔ)。
可選的,在獲得分詞修飾詞典之后,還可以利用triebuild將分詞修飾詞典建成鍵值對(duì)(kv)形式,以便于線上查詢使用。其中,鍵值對(duì)中的k 是分詞片段對(duì),v是分詞片段對(duì)對(duì)應(yīng)的修飾信息。
在上述分詞修飾詞典中,包括存在修飾關(guān)系的分詞片段對(duì)以及分詞片段對(duì)對(duì)應(yīng)的修飾信息,該修飾信息包括修飾關(guān)系指向信息和修飾程度得分中的至少一個(gè)。
基于上述分詞修飾詞典,一種查詢預(yù)先建立的分詞修飾詞典,以確定待處理文本包含的分詞片段之間的修飾關(guān)系的實(shí)施方式包括:
將待處理文本包含的分詞片段進(jìn)行兩兩組合,以形成待處理分詞片段對(duì);
將待處理分詞片段對(duì)作為查詢條件,在分詞修飾詞典中進(jìn)行查詢;
若在分詞修飾詞典中查詢到待處理分詞片段對(duì),確定待處理分詞片段對(duì)之間存在修飾關(guān)系;
若未在分詞修飾詞典中查詢到所述待處理分詞片段對(duì),確定待處理分詞片段對(duì)之間不存在修飾關(guān)系。
經(jīng)過上述查詢判斷,即可確定待處理文本包含的分詞片段之間的修飾關(guān)系。
進(jìn)一步,除了獲得待處理分詞片段對(duì)之間是否存在修飾關(guān)系之外,還可以在待處理分詞片段對(duì)之間存在修飾關(guān)系時(shí),獲取待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息。
返回繼續(xù)參考圖1,在獲得待處理文本包含的分詞片段之間的修飾關(guān)系之后,可以根據(jù)待處理文本包含的分詞片段之間的修飾關(guān)系,確定待處理文本中的核心詞。
在一可選實(shí)施方式中,核心詞識(shí)別裝置可以從分詞修飾詞典中獲取上述存在修飾關(guān)系的待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息,該修飾信息包括修飾關(guān)系指向信息和修飾程度得分中的至少一個(gè);然后,對(duì)待處理文本包含的每個(gè)分詞片段,根據(jù)上述存在修飾關(guān)系的待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息,統(tǒng)計(jì)該分詞片段被修飾的次數(shù)和修飾得分中的至少一個(gè),并根據(jù)該分詞片段被修飾的次數(shù)和修飾得分中的至少一個(gè),確定該分詞片段是否為待處理文本中的核心詞。
可選的,關(guān)于分詞片段的修飾得分,可以根據(jù)包含該分詞片段的待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息中的修飾程度得分計(jì)算獲得。例如,可以將包含該分詞片段的待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息中的修飾程度得分直接相加作為該分詞片段的修飾得分。又例如,可以對(duì)包含該分詞片段的待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息中的修飾程度得分進(jìn)行加權(quán)平均作為該分詞片段的修飾得分。
例如,根據(jù)分詞片段被修飾的次數(shù),判斷該分詞片段是否是待處理文本包含的分詞片段中被修飾次數(shù)最多的一個(gè)分詞片段,若判斷結(jié)果為是,則確定該分詞片段為待處理文本的核心詞。
又例如,判斷分詞片段被修飾的次數(shù)是否大于指定次數(shù)閾值,若判斷結(jié)果為是,則確定該分詞片段為待處理文本的核心詞。
又例如,判斷分詞片段的修飾得分是否大于指定得分閾值,若判斷結(jié)果為是,則確定該分詞片段為待處理文本的核心詞。
又例如,判斷分詞片段被修飾的次數(shù)是否大于指定次數(shù)閾值,并判斷分詞片段的修飾得分是否大于指定得分閾值,若兩個(gè)判斷操作的判斷結(jié)果均為是,則確定該分詞片段為待處理文本的核心詞。
由上述分析可知,本申請(qǐng)實(shí)施例基于分詞片段之間的修飾關(guān)系確定核心詞,由于分詞片段之間的修飾關(guān)系并不受文本中詞語之間先后順序的限定,所以能夠解決現(xiàn)有技術(shù)方案中詞性標(biāo)注規(guī)則對(duì)正常語言模型順序嚴(yán)重依賴的問題,有利于提高核心詞識(shí)別的精準(zhǔn)度。
例如,在電商網(wǎng)站搜索召回產(chǎn)品的流程中,需要識(shí)別和理解用戶輸入的搜索詞中的核心詞,即搜索意圖,另外,在搜索召回的產(chǎn)品中,為了精選與用戶搜索意圖最相關(guān)的文檔或產(chǎn)品,也需要識(shí)別文檔或產(chǎn)品標(biāo)題的核心詞。其中,可以采用本申請(qǐng)實(shí)施例提供的核心詞識(shí)別方法來識(shí)別搜索詞中的核心詞以及文檔或產(chǎn)品標(biāo)題中的核心詞,之后將搜索詞中的核心詞與文檔或產(chǎn)品標(biāo)題中的核心詞進(jìn)行匹配,從而快速發(fā)現(xiàn)與用戶搜索意圖最相關(guān)的文檔或產(chǎn)品。由于本申請(qǐng)實(shí)施例提供的核心詞識(shí)別方法能夠更加精準(zhǔn)的識(shí)別核心詞, 因此基于識(shí)別出的核心詞進(jìn)行文檔或產(chǎn)品匹配,有利于提高匹配效率,提高匹配結(jié)果的精準(zhǔn)度,便于用戶快速獲取所需文檔或產(chǎn)品。
需要說明的是,對(duì)于前述的各方法實(shí)施例,為了簡(jiǎn)單描述,故將其都表述為一系列的動(dòng)作組合,但是本領(lǐng)域技術(shù)人員應(yīng)該知悉,本申請(qǐng)并不受所描述的動(dòng)作順序的限制,因?yàn)橐罁?jù)本申請(qǐng),某些步驟可以采用其他順序或者同時(shí)進(jìn)行。其次,本領(lǐng)域技術(shù)人員也應(yīng)該知悉,說明書中所描述的實(shí)施例均屬于優(yōu)選實(shí)施例,所涉及的動(dòng)作和模塊并不一定是本申請(qǐng)所必須的。
在上述實(shí)施例中,對(duì)各個(gè)實(shí)施例的描述都各有側(cè)重,某個(gè)實(shí)施例中沒有詳述的部分,可以參見其他實(shí)施例的相關(guān)描述。
圖4為本申請(qǐng)又一實(shí)施例提供的核心詞識(shí)別裝置的結(jié)構(gòu)示意圖。如圖4所示,該裝置包括:分詞處理模塊41、關(guān)系確定模塊42和短語確定模塊43。
分詞處理模塊41,用于對(duì)待處理文本進(jìn)行分詞處理,以獲得待處理文本包含的分詞片段。
關(guān)系確定模塊42,用于查詢預(yù)先建立的分詞修飾詞典,以確定待處理文本包含的分詞片段之間的修飾關(guān)系。
短語確定模塊43,用于根據(jù)待處理文本包含的分詞片段之間的修飾關(guān)系,確定待處理文本中的核心詞。
在一可選實(shí)施方式中,分詞處理模塊41具體用于:
以短語為粒度,對(duì)待處理文本進(jìn)行分詞處理,以獲得待處理文本包含的分詞片段。
在一可選實(shí)施方式中,分詞處理模塊41具體用于:
根據(jù)預(yù)先建立的分詞詞庫,對(duì)待處理文本進(jìn)行分詞處理,以獲得待處理文本包含的分詞片段。
在一可選實(shí)施方式中,如圖5所示,該裝置還包括:用于預(yù)先建立分詞詞庫的分詞詞庫建立模塊44。
如圖5,分詞詞庫建立模塊44的一種實(shí)現(xiàn)結(jié)構(gòu)包括:分詞處理單元441、特征計(jì)算單元442、短語確定單元443以及短語添加單元444。
分詞處理單元441,用于對(duì)日志語料庫中的用戶歷史點(diǎn)擊日志進(jìn)行分詞處理,以獲得候選分詞片段。
特征計(jì)算單元442,用于計(jì)算候選分詞片段的語義特征,語義特征用于表達(dá)候選分詞片段在語法語義上的獨(dú)立表達(dá)能力。
短語確定單元443,用于根據(jù)候選分詞片段的語義特征,確定候選分詞片段中具有獨(dú)立語義的分詞片段。
短語添加單元444,用于將具有獨(dú)立語義的分詞片段加入分詞詞庫。
在一可選實(shí)施方式中,特征計(jì)算單元442具體用于執(zhí)行以下至少一種計(jì)算操作:
根據(jù)候選分詞片段在日志語料庫中的出現(xiàn)概率、左鄰分詞片段在日志語料庫中的出現(xiàn)概率以及右鄰分詞片段在日志語料庫中的出現(xiàn)概率,計(jì)算候選分詞片段的點(diǎn)間互信息特征;
根據(jù)候選分詞片段在日志語料庫中的出現(xiàn)概率、左鄰分詞片段在日志語料庫中的出現(xiàn)概率以及右鄰分詞片段在日志語料庫中的出現(xiàn)概率,計(jì)算候選分詞片段的點(diǎn)間相對(duì)熵特征;
根據(jù)預(yù)先指定的質(zhì)量因素與質(zhì)量得分之間的對(duì)應(yīng)關(guān)系,計(jì)算候選分詞片段的表達(dá)質(zhì)量特征;
其中,左鄰分詞片段是指日志語料庫中位于候選分詞片段左側(cè)且與所述候選分詞片段相鄰的分詞片段,右鄰分詞片段是指日志語料庫中位于候選分詞片段右側(cè)且與所述候選分詞片段相鄰的分詞片段。
在一可選實(shí)施方式中,關(guān)系確定模塊42具體用于:
將待處理文本包含的分詞片段進(jìn)行兩兩組合,以形成待處理分詞片段對(duì);
將待處理分詞片段對(duì)作為查詢條件,在分詞修飾詞典中進(jìn)行查詢;
若在分詞修飾詞典中查詢到待處理分詞片段對(duì),確定待處理分詞片段對(duì)之間存在修飾關(guān)系;
若未在分詞修飾詞典中查詢到待處理分詞片段對(duì),確定待處理分詞片段對(duì)之間不存在修飾關(guān)系。
在一可選實(shí)施方式中,短語確定模塊43具體用于:
從分詞修飾詞典中獲取存在修飾關(guān)系的待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息,修飾信息包括修飾關(guān)系指向信息和修飾程度得分中的至少一個(gè);
對(duì)待處理文本包含的每個(gè)分詞片段,根據(jù)存在修飾關(guān)系的待處理分詞片段對(duì)對(duì)應(yīng)的修飾信息,統(tǒng)計(jì)分詞片段被修飾的次數(shù)和修飾得分中的至少一個(gè),并根據(jù)分詞片段被修飾的次數(shù)和修飾得分中的至少一個(gè),確定分詞片段是否為待處理文本中的核心詞。
在一可選實(shí)施方式中,如圖5所示,該裝置還包括:修飾詞典建立模塊45。
如圖5,修飾詞典建立模塊45的一種實(shí)現(xiàn)結(jié)構(gòu)包括:短語提取單元451、分詞片段對(duì)處理單元452以及合并處理單元453。
短語提取單元451,用于對(duì)日志語料庫中的每條用戶歷史點(diǎn)擊日志,從用戶歷史點(diǎn)擊日志中提取具有獨(dú)立語義的分詞片段形成分詞片段集合;
分詞片段對(duì)處理單元452,用于對(duì)每個(gè)分詞片段集合,確定分詞片段集合中的核心分詞片段和修飾分詞片段,將分詞片段集合中的核心分詞片段分別與分詞片段集合中的修飾分詞片段進(jìn)行組合,以獲得分詞片段集合包含的分詞片段對(duì),生成分詞片段集合包含的分詞片段對(duì)對(duì)應(yīng)的修飾信息,修飾信息包括修飾關(guān)系指向信息和修飾程度得分中的至少一個(gè);
合并處理單元453,用于對(duì)所有分詞片段集合包含的分詞片段對(duì)進(jìn)行合并處理,并將合并后的分詞片段對(duì)以及合并后的分詞片段對(duì)對(duì)應(yīng)的修飾信息加入分詞修飾詞典中。
在一可選實(shí)施方式中,合并處理單元453具體用于:
若修飾信息包括修飾程度得分,將所有分詞片段集合包含的分詞片段對(duì)中的相同分詞片段對(duì)的修飾程度得分進(jìn)行累加,以作為相同分詞片段對(duì)的修飾程度得分,并保留相同分詞片段對(duì)中的一個(gè)。
在一可選實(shí)施方式中,上述待處理文本為用戶輸入的搜索詞,或待搜索網(wǎng)絡(luò)對(duì)象的描述信息。
本實(shí)施例提供的核心詞識(shí)別裝置,對(duì)待處理文本進(jìn)行分詞處理,獲得待處理文本包含的分詞片段,之后,查詢預(yù)先建立的分詞修飾詞典,確定待處理文本包含的分詞片段之間的修飾關(guān)系,根據(jù)待處理文本包含的分詞片段之間的修飾關(guān)系,確定待處理文本中的核心詞。本實(shí)施例提供的核心詞識(shí)別裝置,基于分詞片段之間的修飾關(guān)系確定核心詞,由于分詞片段之間的修飾關(guān)系并不受文本中詞語之間先后順序的限定,所以能夠解決現(xiàn)有技術(shù)方案中詞性標(biāo)注規(guī)則對(duì)正常語言模型順序嚴(yán)重依賴的問題,有利于提高核心詞識(shí)別的精準(zhǔn)度。
進(jìn)一步,本實(shí)施例提供的核心詞識(shí)別裝置,以短語為粒度,對(duì)待處理文本進(jìn)行分詞處理,切分粒度相對(duì)較粗,語義表達(dá)更加準(zhǔn)確,基于切分出的短語進(jìn)行核心詞識(shí)別,所識(shí)別出的核心詞為短語,有利于提高識(shí)別核心詞的精準(zhǔn)度。
所屬領(lǐng)域的技術(shù)人員可以清楚地了解到,為描述的方便和簡(jiǎn)潔,上述描述的系統(tǒng),裝置和單元的具體工作過程,可以參考前述方法實(shí)施例中的對(duì)應(yīng)過程,在此不再贅述。
在本申請(qǐng)所提供的幾個(gè)實(shí)施例中,應(yīng)該理解到,所揭露的系統(tǒng),裝置和方法,可以通過其它的方式實(shí)現(xiàn)。例如,以上所描述的裝置實(shí)施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實(shí)際實(shí)現(xiàn)時(shí)可以有另外的劃分方式,例如多個(gè)單元或組件可以結(jié)合或者可以集成到另一個(gè)系統(tǒng),或一些特征可以忽略,或不執(zhí)行。另一點(diǎn),所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機(jī)械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位于一個(gè)地方,或者也可以分布到多個(gè)網(wǎng)絡(luò)單元上。可以根據(jù)實(shí)際的需要選擇其中的部分或者全部單元來實(shí)現(xiàn)本實(shí)施例方案的目的。
另外,在本申請(qǐng)各個(gè)實(shí)施例中的各功能單元可以集成在一個(gè)處理單元 中,也可以是各個(gè)單元單獨(dú)物理存在,也可以兩個(gè)或兩個(gè)以上單元集成在一個(gè)單元中。上述集成的單元既可以采用硬件的形式實(shí)現(xiàn),也可以采用硬件加軟件功能單元的形式實(shí)現(xiàn)。
上述以軟件功能單元的形式實(shí)現(xiàn)的集成的單元,可以存儲(chǔ)在一個(gè)計(jì)算機(jī)可讀取存儲(chǔ)介質(zhì)中。上述軟件功能單元存儲(chǔ)在一個(gè)存儲(chǔ)介質(zhì)中,包括若干指令用以使得一臺(tái)計(jì)算機(jī)設(shè)備(可以是個(gè)人計(jì)算機(jī),服務(wù)器,或者網(wǎng)絡(luò)設(shè)備等)或處理器(processor)執(zhí)行本申請(qǐng)各個(gè)實(shí)施例所述方法的部分步驟。而前述的存儲(chǔ)介質(zhì)包括:u盤、移動(dòng)硬盤、只讀存儲(chǔ)器(read-onlymemory,rom)、隨機(jī)存取存儲(chǔ)器(randomaccessmemory,ram)、磁碟或者光盤等各種可以存儲(chǔ)程序代碼的介質(zhì)。
最后應(yīng)說明的是:以上實(shí)施例僅用以說明本申請(qǐng)的技術(shù)方案,而非對(duì)其限制;盡管參照前述實(shí)施例對(duì)本申請(qǐng)進(jìn)行了詳細(xì)的說明,本領(lǐng)域的普通技術(shù)人員應(yīng)當(dāng)理解:其依然可以對(duì)前述各實(shí)施例所記載的技術(shù)方案進(jìn)行修改,或者對(duì)其中部分技術(shù)特征進(jìn)行等同替換;而這些修改或者替換,并不使相應(yīng)技術(shù)方案的本質(zhì)脫離本申請(qǐng)各實(shí)施例技術(shù)方案的精神和范圍。
- 還沒有人留言評(píng)論。精彩留言會(huì)獲得點(diǎn)贊!
- 一種I/O特征識(shí)別方法以及裝置與流程
- 作弊賬號(hào)的識(shí)別方法及裝置與流程
- 一種計(jì)算機(jī)識(shí)別水生動(dòng)物的裝置的制造方法
- 一種便攜式識(shí)別水生動(dòng)物的裝置的制造方法
- 關(guān)鍵幀識(shí)別方法及裝置與流程
- 防偽標(biāo)簽識(shí)別裝置、防偽標(biāo)簽識(shí)別方法和防偽標(biāo)簽與流程
- 行人重識(shí)別數(shù)據(jù)標(biāo)注方法和裝置與流程
- 一種識(shí)別用戶所屬地區(qū)的方法及裝置與流程
- 設(shè)備識(shí)別方法及裝置與流程
- 一種金屬材料的初步識(shí)別裝置的制造方法
- 溶洞大小的隨鉆識(shí)別方法及裝置與流程
- 一種I/O特征識(shí)別方法以及裝置與流程
- 應(yīng)用于高海拔環(huán)境的射頻裝置的制造方法
- 一種射頻感應(yīng)家庭式垃圾裝置的制造方法
- 作弊賬號(hào)的識(shí)別方法及裝置與流程
- 一種計(jì)算機(jī)識(shí)別水生動(dòng)物的裝置的制造方法
- 關(guān)鍵幀識(shí)別方法及裝置與流程
- 防偽標(biāo)簽識(shí)別裝置、防偽標(biāo)簽識(shí)別方法和防偽標(biāo)簽與流程
- 行人重識(shí)別數(shù)據(jù)標(biāo)注方法和裝置與流程
- 射頻干擾的處理方法、裝置、存儲(chǔ)介質(zhì)及終端與流程
- 關(guān)鍵幀識(shí)別方法及裝置與流程
- 防偽標(biāo)簽識(shí)別裝置、防偽標(biāo)簽識(shí)別方法和防偽標(biāo)簽與流程
- 行人重識(shí)別數(shù)據(jù)標(biāo)注方法和裝置與流程
- 一種識(shí)別用戶所屬地區(qū)的方法及裝置與流程
- 設(shè)備識(shí)別方法及裝置與流程
- 一種金屬材料的初步識(shí)別裝置的制造方法
- 竄貨識(shí)別方法和裝置與流程
- 識(shí)別定位點(diǎn)的方法和裝置與流程
- 一種圖片識(shí)別方法、裝置、電子設(shè)備及可讀存儲(chǔ)介質(zhì)與流程
- 識(shí)別惡意網(wǎng)站的方法及裝置與流程
- 識(shí)別定位點(diǎn)的方法和裝置與流程
- 保險(xiǎn)受理信息的風(fēng)險(xiǎn)監(jiān)控方法和裝置與流程
- 一種圖片識(shí)別方法、裝置、電子設(shè)備及可讀存儲(chǔ)介質(zhì)與流程
- 識(shí)別惡意網(wǎng)站的方法及裝置與流程
- 年齡段識(shí)別方法及裝置與流程
- 核心詞識(shí)別方法及裝置與流程
- 一種電源適配器的識(shí)別方法及裝置與流程
- 一種汽車換擋提前識(shí)別裝置的制造方法
- OCR識(shí)別結(jié)果的糾正方法和裝置與流程
- 一種風(fēng)險(xiǎn)信息輸出、風(fēng)險(xiǎn)信息構(gòu)建方法及裝置與流程