行人重識別數據標注方法和裝置與流程
本發明涉及視頻分析技術,特別涉及行人重識別數據標注方法和裝置。
背景技術:
行人重識別技術旨在識別不同視角的非重疊監控場景下的行人身份,特別在監控視頻的應用中,有較大的應用前景。由于不同監控場景下行人圖像受背景,光照,朝向等影響較大,因此行人重識別一直是圖像識別中難度較大的一方面。
目前,行人標識一般通過人手工標注。人手工標注的流程是:從不同視角的非重疊場景中找出同一個人,并把包含該行人的坐標限定框對應的像素截取出來,并且為每個人分配不同的id。從不同視角的非重疊場景中找出同一個人,找的過程會耗費很多精力,并且出錯概率大。
也有一些基于人臉檢測、多目標分類技術來標注的。但是此類標注方法只能應用于單目攝像頭場景。而行人重識別需要匹配多攝像頭下的人,目前沒有這種類型的自動標注方法。
技術實現要素:
為了克服現有技術的不足,本發明的目的在于提供行人重識別數據標注方法和裝置,其能解決現有的人手工標注過程會耗費很多精力,并且出錯概率大,基于人臉檢測、多目標分類技術來標注只能應用于單目攝像頭場景的問題。
本發明的目的采用以下技術方案實現:
行人重識別數據標注方法,包括以下步驟:
獲取待標注的圖片序列,所述圖片序列包括待標圖片;
從所述待標圖片獲取行人圖片;
抽取所述行人圖片的特征;
根據所述特征對所述行人圖片進行聚類,得到結果類;
計算所述結果類與目標類的距離;
將與所述目標類的距離符合匹配條件的結果類作為匹配類。
進一步地,在所述獲取待標注的圖片序列時,還包括以下子步驟:
獲取所述待標圖片的標識號,所述標識號包括視角碼和順序碼;
在所述從所述待標圖片獲取行人圖片時,還包括以下子步驟:
分別將所述行人圖片與一編碼號相關聯,所述編碼號包括相應的所述待標圖片的標識號和所述行人圖片的序號。
進一步地,在所述計算所述結果類與目標類的距離之前,還包括以下步驟:
根據相應的所述編碼號中的標識號對所述結果類進行篩選;
或者,在所述將與所述目標類的距離符合匹配條件的結果類作為匹配類之后,還包括以下步驟:
根據相應的所述編碼號中的標識號對所述匹配類進行篩選。
進一步地,所述抽取所述行人圖片的特征,具體為通過行人重識別深度神經網絡抽取所述行人圖片的特征。
進一步地,所述行人重識別數據標注方法還包括以下步驟:
根據所述匹配類對所述行人重識別深度神經網絡進行再訓練。
進一步地,所述行人重識別深度神經網絡包括:輸入層、卷積層、規范化層、非線性映射層、池化層、全連接層和分類層;其中,所述輸入層用于對所述行人圖片預處理,增加樣本數量。
進一步地,在所述抽取所述行人圖片的特征之前,還包括以下步驟:
計算所述行人圖片的前景比例或高寬比;
刪去所述前景比例或高寬比不滿足閾值條件的行人圖片。
進一步地,所述獲取待標注的圖片序列,具體為獲取根據視頻位置、視頻時間、人流量或行人相似度中的至少一種篩選后的視頻數據。
行人重識別數據標注裝置,包括:
第一獲取模塊,用于獲取待標注的圖片序列,所述圖片序列包括待標圖片;
第二獲取模塊,用于從所述待標圖片獲取行人圖片;
特征模塊,用于抽取所述行人圖片的特征;
聚類模塊,用于根據所述特征對所述行人圖片進行聚類,得到結果類;
計算模塊,用于計算所述結果類與目標類的距離;
匹配模塊,用于將與所述目標類的距離符合匹配條件的結果類作為匹配類。
進一步地,所述特征模塊包括:
行人重識別深度神經網絡單元,用于抽取所述行人圖片的特征;
再訓練網絡單元,用于根據所述匹配類對所述行人重識別深度神經網絡進行再訓練。
行人重識別數據標注裝置,包括:
處理器以及用于存儲處理器可執行的指令的存儲器;
所述處理器被配置為:
獲取待標注的圖片序列,所述圖片序列包括待標圖片;
從所述待標圖片獲取行人圖片;
抽取所述行人圖片的特征;
根據所述特征對所述行人圖片進行聚類,得到結果類;
計算所述結果類與目標類的距離;
將與所述目標類的距離符合匹配條件的結果類作為匹配類。
相比現有技術,本發明的有益效果在于:通過首先從待標圖片獲取行人圖片,然后抽取行人圖片的特征,再根據特征對行人圖片進行聚類,得到結果類;然后根據結果類與目標類的距離篩選出匹配類。匹配類中的行人圖片與目標類中的行人圖片有較大可能是同一個人,至此完成行人重識別數據的標注。行人重識別準確率較高,可以用于多攝像頭的多視角影像的行人重識別。
附圖說明
圖1是本發明實施例一提供的行人重識別數據標注方法的流程示意圖。
圖2是本發明實施例二提供的行人重識別數據標注方法的流程示意圖。
圖3是本發明實施例三提供的行人重識別數據標注裝置的結構示意圖。
圖4是本發明實施例四提供的行人重識別數據標注裝置的結構示意圖。
具體實施方式
下面,結合附圖以及具體實施方式,對本發明做進一步描述,需要說明的是,在不相沖突的前提下,以下描述的各實施例之間或各技術特征之間可以任意組合形成新的實施例:
實施例一:
如圖1所示的行人重識別數據標注方法,包括以下步驟:
步驟s110,獲取待標注的圖片序列,所述圖片序列包括待標圖片;在另一實施例中,圖片序列包含不同攝像機在不同視角下拍攝的影像。
步驟s120,從所述待標圖片獲取行人圖片;
進一步地,所述從所述待標圖片獲取行人圖片,具體為通過行人檢測深度神經網絡,根據行人檢測深度神經網絡輸出的包含行人的坐標信息分別摳出對應的所有行人圖片。行人檢測深度神經網絡是專門用于找出檢測圖片中的行人坐標位置的一種深度神經網絡模型,其搭建、訓練和使用均屬于現有技術,不再贅述。
步驟s130,抽取所述行人圖片的特征;
具體的,行人圖片特征的抽取可以通過現有的圖像識別算法實現,屬于現有技術。
作為本發明的進一步改進,所述抽取所述行人圖片的特征,具體為通過行人重識別深度神經網絡抽取所述行人圖片的特征。
優選的,所述行人重識別深度神經網絡包括:輸入層、卷積層、規范化層、非線性映射層、池化層、全連接層和分類層。
行人重識別深度神經網絡模型訓練過程如下:
1、準備訓練數據;行人重識別的訓練數據是同一個人的不同形態的行人圖片。
2、構建行人重識別的深度神經網絡;該深度神經網絡包括輸入層,卷積層,規范化層,非線性映射層,池化層,全連接層以及分類層。
其中,輸入層輸入為行人圖片,輸入層可以用于對行人圖片進行預處理,如鏡像,隨機剪裁等操作,旨在增加訓練樣本數量。該深度神經網絡包括多個卷積層,第一個卷積層的輸入是經過輸入層處理過的行人圖片,輸出為圖像特征;后面的卷積層輸入與輸出都是圖像特征。每個卷積層輸出都帶了一個規范化層,規范化層優化了訓練,在非線性映射層之前對數據做了規范化,易化網絡訓練,加快收斂速度。最后一個規范化層的輸出作為非線性映射層的輸入,非線性映射層通過非線性函數,對卷積層輸出的特征進行非線性變換,使得其輸出的特征有較強的表達能力。池化層可以進行多對一的映射操作,該層可進一步強化所學習特征的非線性,同時還可以減小輸出特征的大小,降低網絡參數。全連接層是對輸入的特征做線性變換,將學習的特征投影到更利于預測的子空間。最后為分類層,可以采用softmax損耗層,用于計算預測類別和標簽類別的誤差。
3、利用梯度下降法,迭代更新上一步中所述各層的參數,使得模型的預測類別和標簽類別的誤差小于設定好的閾值。
步驟s140,根據所述特征對所述行人圖片進行聚類,得到結果類;
進一步地,所述根據所述特征對所述行人圖片進行聚類,具體為采用dbscan(density-basedspatialclusteringofapplicationswithnoise)等聚類算法,把所述行人圖片的特征作為輸入,為行人圖片聚類,某一結果類里可以包含一個或多個相似的行人圖片。
dbscan聚類算法是一種基于密度的空間聚類算法。該算法將具有足夠密度的區域劃分為簇,并在具有噪聲的空間數據庫中發現任意形狀的簇,它將簇定義為密度相連的點的最大集合。
步驟s150,計算所述結果類與目標類的距離;
目標類可以為某一個結果類,也可以是一張或多張指定的行人圖片構成的類。具體的,所述結果類與目標類的距離為來自于結果類與目標類中的圖片相互之間行人重識別特征距離的最小值。如果某結果類中有10張行人圖片,目標類中有6張行人圖片,則該結果類與目標類中的圖片相互之間行人重識別特征距離有10*6=60個,這60個距離里的最小值為結果類與目標類的距離。
距離可以是歐氏距離、余弦距離等,通過現有技術可以計算。
步驟s160,將與所述目標類的距離符合匹配條件的結果類作為匹配類。
如果某結果類與目標類之間的距離小于預設值,即認為該結果類符合匹配條件,可以作為匹配類。預設值可以根據經驗和有限次的實驗確定。匹配類中的行人圖片與目標類中的行人圖片有較大可能是同一個人,至此完成行人重識別數據的標注。
本發明通過首先從待標圖片獲取行人圖片,然后抽取行人圖片的特征,再根據特征對行人圖片進行聚類,得到結果類;然后根據結果類與目標類的距離篩選出匹配類。匹配類中的行人圖片與目標類中的行人圖片有較大可能是同一個人,至此完成行人重識別數據的標注。行人重識別準確率較高,可以用于多攝像頭的多視角影像的行人重識別,在用于多視角行人重識別數據標注時,只需要分別對不同視角下的圖片序列執行上述步驟即可。
在另一實施例中,作為本發明的進一步改進,所述行人重識別數據標注方法中,在步驟s130抽取所述行人圖片的特征之前,還包括以下步驟:
步驟s121,計算所述行人圖片的前景比例或高寬比;
行人圖片的前景可以表示人體;人體占行人圖片的比例或行人圖片的高寬比也需要落在閾值區間才能更好地抽取特征,提高準確率。
步驟s122,刪去所述前景比例或高寬比不滿足閾值條件的行人圖片。
閾值條件具體為前景比例或高寬比位于一定的閾值區間,該閾值區間可以通過經驗或者有限次的試驗得到。
在攝像機采集待標圖片時,難免有一些圖片中背景占比過大,或有物體遮擋行人,此時行人圖片可能沒有利用價值。通過刪去這部分不符合要求的行人圖片以減小計算量,防止誤標注。
具體的,行人圖片的前景可以通過現有的算法分割出來。在本實施例中,使用背景分割深度神經網絡模型來實現,背景分割深度神經網絡模型是專門用于去除輸入圖片中的背景的一種深度神經網絡模型。計算每張行人圖片的前景面積占整張行人圖片面積的比例,如果該比例小于預設閾值,就刪去該行人圖片或者不對該行人圖片進行下一步處理。預設閾值可以通過經驗或者有限次的實驗得到。
在本實施例中,背景分割深度神經網絡模型構建和訓練過程如下:
1、準備訓練數據;該模型的訓練數據是行人圖片以及對應的去除過背景后的行人圖片。
2、構建深度神經網絡模型;在現有技術公開的深度神經網絡的基礎上做了如下改進:在池化層后沒有接全連接層,而是接了反卷積層,在反卷積層后接的是交叉熵損失函數層(sigmoidcrossentropylosslayer)。反卷積層的操作和卷積層的操作剛好相反,目的在于得到更大的特征圖;交叉熵損失函數層用于計算模型輸出的特征圖與標簽圖的誤差。
3、利用梯度下降法,迭代更新深度神經網絡模型各層參數,使得深度神經網絡模型輸出的特征圖與標簽圖的誤差小于設定好的閾值。
在另一實施例中,還過濾掉了高寬比大于某個閾值的行人圖片,這個閾值可以通過行人身高與體寬的比值計算得到,可以進一步縮小標注數據的規模,節省標注時間。
實施例二:
如圖2所示的行人重識別數據標注方法,包括以下步驟:
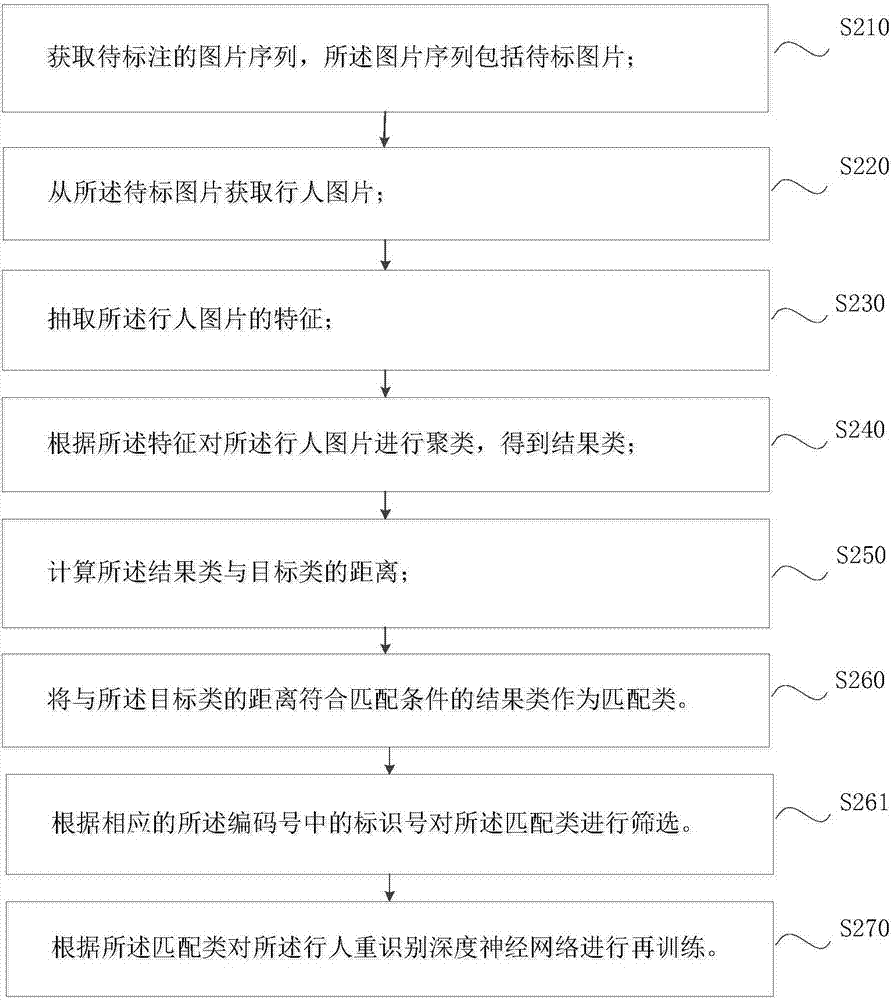
步驟s210,獲取待標注的圖片序列,所述圖片序列包括待標圖片;
步驟s210還包括子步驟s211,獲取所述待標圖片的標識號,所述標識號包括視角碼和順序碼;
步驟s210獲取的圖片序列v中,包括若干待標圖片vi,j;其中,下標i為視角碼,表示待標圖片vi,j來自第i個視角;j為順序碼,表示待標圖片vi,j為這個視角下的j號圖片;視角碼和順序碼組成了待標圖片的標識號。標識號與待標圖片一一對應,通過待標圖片的標識號可以得知該待標圖片采集的地點、時間等信息。
步驟s220,從所述待標圖片獲取行人圖片;
步驟s220還包括子步驟s221,分別將所述行人圖片與一編碼號相關聯,所述編碼號包括相應的所述待標圖片的標識號和所述行人圖片的序號。
步驟s220中從所述待標圖片vi,j獲取的行人圖片可能有多個,相應的給行人圖片也標上號。如行人圖片pi,j,k,表示該行人圖片來自待標圖片vi,j,為待標圖片vi,j中的第k個行人。即行人圖片與一編碼號相關聯。
步驟s230,抽取所述行人圖片的特征;
步驟s240,根據所述特征對所述行人圖片進行聚類,得到結果類;
步驟s250,計算所述結果類與目標類的距離;
步驟s260,將與所述目標類的距離符合匹配條件的結果類作為匹配類。
步驟s210-s260,分別對應實施例一中的s110-s160,不再贅述。
在本實施例中,經過步驟s240對i視角下的行人圖片進行聚類,聚類出的結果包括結果類ci,s,其中i代表第幾個視角,s代表第幾個結果類。
如果選中m視角下的第n個結果類cm,n為目標類,依次計算i視角下的各結果類與結果類cm,n之間的距離,并判斷距離是否符合匹配條件。在本實施例中,匹配條件可以是i視角下該結果類與結果類cm,n之間的距離最近;在另一實施例中,可以是i視角下所有結果類與結果類cm,n之間的距離由近至遠排列的前幾個結果類,然后進一步篩選出這幾個結果類中哪個結果類與目標類最匹配,最匹配的結果類作為匹配類。例如,可以目視判斷結果類中的行人圖片與目標類中行人圖片的相似程度,然后確定匹配類。
匹配類中包含有行人圖片,由于行人圖片與編碼號相關聯,通過該編碼號即可得到與目標類匹配的行人于何時何地出現在哪一個視角中,達到視頻點位配對的目的。
依次對不同視角下的圖片序列執行步驟s210-步驟s221,即可得到所有視角下的匹配類,實現多視角情景下的行人重識別數據標注。
依次設置i視角下各結果類為目標類,即可實現針對于i視角下行人的多視角行人重識別數據標注。
進一步地,在步驟s260將與所述目標類的距離符合匹配條件的結果類作為匹配類之后,還包括以下步驟:
步驟s261,根據相應的所述編碼號中的標識號對所述匹配類進行篩選。
在另一實施例中,行人重識別數據標注方法在步驟s250計算所述結果類與目標類的距離之前,還包括以下步驟:
步驟s241,根據相應的所述編碼號中的標識號對所述結果類進行篩選。
由于一個人不可能在同一張圖片里出現在不同的位置,可以根據行人圖片的編碼號把沒有正確聚類的結果類或匹配類去掉。如果某個結果類中兩個行人圖片的編碼號的標識號部分相同,即表示該結果類沒有正確聚類。
作為本發明的進一步改進,行人重識別數據標注方法還包括:
步驟s270,根據所述匹配類對所述行人重識別深度神經網絡進行再訓練。
本發明得到的行人重識別標注數據可以用來再訓練行人重識別深度神經網絡。訓練數據包括匹配類和/或目標類中的行人圖片,深度神經網絡訓練的方法屬于現有技術,不再贅述。由于訓練數據增多,樣本準確度提高,新的行人重識別深度神經網絡模型在抽取行人圖片的特征和行人重識別上的能力增強。再訓練后的的模型替換步驟s230中的行人重識別深度神經網絡模型,可以進一步得到更好的標注效果。
作為本發明的進一步改進,步驟s210所述獲取待標注的圖片序列,具體為獲取根據視頻位置或視頻時間或人流量篩選后的視頻數據。
一般情況下,用于行人重識別的視頻數據是海量的視頻,如果能對海量視頻進行篩選,根據視頻位置或視頻時間或人流量選出有針對性的視頻數據作為待標注的圖片序列,可以大大減少工作量,提高標注準確率。具體的,篩選可以包括以下四種手段中的至少一種:
1.基于位置的篩選。在大部分公安視頻監控系統以及大規模,寬領域的監控系統中,都提供了視頻點位的經緯度或者經過轉換的坐標信息。由于距離遠的視頻不滿足篩選條件,故可剔除距離在設定閾值之外的視頻數據。
2.根據時間的篩選。只有在時間段符合要求的情況下進行標注才有意義。一般所采集的視頻都有時間信息,可以根據時間信息去除不滿足時間段條件的視頻數據。
3.基于人流量的篩選。在海量的視頻中,位于工業區,荒郊等地方的點位人流量稀少,這類視頻對行人數據的貢獻率低,性價比低,故可以剔除這類視頻。具體的,通過預先訓練好的行人檢測模型對視頻進行人流量檢測,當一定時間段內檢測到的行人數量小于設定閾值時,剔除該視頻數據,留下滿足人流量條件的視頻數據。
4.基于行人相似度的篩選。根據預先訓練好的行人重識別深度神經網絡對海量視頻進行篩選,將從不同視角的視頻中檢測到的行人進行比對,當比對的行人的相似度達到設定閾值并且相似度達到設定閾值的行人的數量超過一定數量的時候,認為該視頻數據可以作為待標注的圖片序列。
實施例三:
如圖3所示的行人重識別數據標注裝置,包括:
第一獲取模塊110,用于獲取待標注的圖片序列,所述圖片序列包括待標圖片;
第二獲取模塊120,用于從所述待標圖片獲取行人圖片;
特征模塊130,用于抽取所述行人圖片的特征;
聚類模塊140,用于根據所述特征對所述行人圖片進行聚類,得到結果類;
計算模塊150,用于計算所述結果類與目標類的距離;
匹配模塊160,用于將與所述目標類的距離符合匹配條件的結果類作為匹配類。
進一步地,所述特征模塊130包括:
行人重識別深度神經網絡單元,用于抽取所述行人圖片的特征;
再訓練單元,用于根據所述匹配類對所述行人重識別深度神經網絡進行再訓練。
本實施例中的裝置與前述實施例中的方法是基于同一發明構思下的兩個方面,在前面已經對方法實施過程作了詳細的描述,所以本領域技術人員可根據前述描述清楚地了解本實施中的系統的結構及實施過程,為了說明書的簡潔,在此就不再贅述。
為了描述的方便,描述以上裝置時以功能分為各種模塊分別描述。當然,在實施本發明時可以把各模塊的功能在同一個或多個軟件和/或硬件中實現。
通過以上的實施方式的描述可知,本領域的技術人員可以清楚地了解到本發明可借助軟件加必需的通用硬件平臺的方式來實現。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分可以以軟件產品的形式體現出來,該計算機軟件產品可以存儲在存儲介質中,如rom/ram、磁碟、光盤等,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例或者實施例的某些部分所述的方法。
描述的裝置實施例僅僅是示意性的,其中所述作為分離部件說明的模塊或單元可以是或者也可以不是物理上分開的,作為模塊或單元示意的部件可以是或者也可以不是物理模塊,既可以位于一個地方,或者也可以分布到多個網絡模塊上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。本領域普通技術人員在不付出創造性勞動的情況下,即可以理解并實施。
本發明可用于眾多通用或專用的計算系統環境或配置中。例如:個人計算機、服務器計算機、手持設備或便攜式設備、平板型設備、多處理器系統、基于微處理器的系統、機頂盒、可編程的消費電子設備、網絡pc、小型計算機、大型計算機、包括以上任何系統或設備的分布式計算環境等等,如實施例四。
實施例四:
如圖4所示的行人重識別數據標注裝置,包括:處理器200以及用于存儲處理器200可執行的指令的存儲器300;
所述處理器200被配置為:
獲取待標注的圖片序列,所述圖片序列包括待標圖片;
從所述待標圖片獲取行人圖片;
抽取所述行人圖片的特征;
根據所述特征對所述行人圖片進行聚類,得到結果類;
計算所述結果類與目標類的距離;
將與所述目標類的距離符合匹配條件的結果類作為匹配類。
本實施例中的裝置與前述實施例中的方法是基于同一發明構思下的兩個方面,在前面已經對方法實施過程作了詳細的描述,所以本領域技術人員可根據前述描述清楚地了解本實施中的系統的結構及實施過程,為了說明書的簡潔,在此就不再贅述。
本發明實施例提供的行人重識別數據標注裝置,通過首先從待標圖片獲取行人圖片,然后抽取行人圖片的特征,再根據特征對行人圖片進行聚類,得到結果類;然后根據結果類與目標類的距離篩選出匹配類。匹配類中的行人圖片與目標類中的行人圖片有較大可能是同一個人,至此完成行人重識別數據的標注。行人重識別準確率較高,可以用于多攝像頭的多視角影像的行人重識別。
對于本領域的技術人員來說,可根據以上描述的技術方案以及構思,做出其它各種相應的改變以及變形,而所有的這些改變以及變形都應該屬于本發明權利要求的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!